Après avoir examiné vos données à l'aide de techniques statistiques et de visualisation, vous devez les transformer de manière à ce que votre modèle puisse s'entraîner plus efficacement. L'objectif de la normalisation est de transformer les caractéristiques pour qu'elles soient à la même échelle. Prenons par exemple les deux fonctionnalités suivantes :
- La caractéristique
Xcouvre la plage de valeurs allant de 154 à 24 917 482. - La caractéristique
Ycouvre la plage de 5 à 22.
Ces deux fonctionnalités couvrent des plages très différentes. La normalisation peut manipuler X et Y afin qu'elles couvrent une plage similaire, par exemple de 0 à 1.
La normalisation offre les avantages suivants :
- Elle permet aux modèles de converger plus rapidement pendant l'entraînement. Lorsque différentes caractéristiques ont des plages différentes, la descente de gradient peut "rebondir" et ralentir la convergence. Cela dit, les optimiseurs plus avancés comme Adagrad et Adam protègent contre ce problème en modifiant le taux d'apprentissage effectif au fil du temps.
- Aide les modèles à inférer de meilleures prédictions. Lorsque différentes caractéristiques ont des plages différentes, le modèle obtenu peut générer des prédictions moins utiles.
- Permet d'éviter le "piège NaN" lorsque les valeurs des caractéristiques sont très élevées.
NaN est l'abréviation de not a number (ce n'est pas un nombre). Lorsqu'une valeur dans un modèle dépasse la limite de précision en virgule flottante, le système définit la valeur sur
NaNau lieu d'un nombre. Lorsqu'un nombre du modèle devient un NaN, d'autres nombres du modèle finissent également par devenir des NaN. - Elle permet au modèle d'apprendre les pondérations appropriées pour chaque caractéristique. Sans mise à l'échelle des caractéristiques, le modèle accorde une attention trop importante aux caractéristiques présentant les plages les plus larges et pas assez d'attention à celles présentant les plages les plus étroites.
Nous vous recommandons de normaliser les caractéristiques numériques couvrant des plages distinctes (par exemple, l'âge et le revenu).
Nous vous recommandons également de normaliser une seule caractéristique numérique qui couvre une large plage, comme city population..
Prenons les deux caractéristiques suivantes :
- La valeur la plus faible de la caractéristique
Aest de -0,5 et la plus élevée est de +0,5. - La valeur la plus faible de la caractéristique
Best de -5,0 et la plus élevée est de +5,0.
Les caractéristiques A et B ont des étendues relativement étroites. Toutefois, la portée de la fonctionnalité B est 10 fois plus large que celle de la fonctionnalité A. Par conséquent :
- Au début de l'entraînement, le modèle suppose que la caractéristique
Best dix fois plus "importante" que la caractéristiqueA. - L'entraînement prendra plus de temps que prévu.
- Le modèle obtenu peut être sous-optimal.
Les dommages globaux causés par la non-normalisation seront relativement faibles. Toutefois, nous vous recommandons tout de même de normaliser les caractéristiques A et B sur la même échelle, par exemple de -1,0 à +1,0.
Prenons maintenant deux caractéristiques avec une plus grande disparité de plages :
- La valeur la plus faible de la caractéristique
Cest -1 et la plus élevée est +1. - La valeur la plus faible de la caractéristique
Dest de +5 000 et la plus élevée de +1 000 000 000.
Si vous ne normalisez pas les caractéristiques C et D, votre modèle sera probablement sous-optimal. De plus, l'entraînement prendra beaucoup plus de temps pour converger, voire ne convergera jamais.
Cette section présente trois méthodes de normalisation courantes :
- mise à l'échelle linéaire
- Mise à l'échelle du score Z
- mise à l'échelle logarithmique
Cette section aborde également le clipping. Bien qu'il ne s'agisse pas d'une véritable technique de normalisation, le clipping permet de maîtriser les caractéristiques numériques indisciplinées en les limitant à des plages qui produisent de meilleurs modèles.
Mise à l'échelle linéaire
La mise à l'échelle linéaire (plus souvent abrégée en mise à l'échelle) consiste à convertir les valeurs à virgule flottante de leur plage naturelle en une plage standard, généralement de 0 à 1 ou de -1 à +1.
Le scaling linéaire est un bon choix lorsque toutes les conditions suivantes sont remplies :
- Les limites inférieure et supérieure de vos données ne changent pas beaucoup au fil du temps.
- La caractéristique contient peu ou pas de valeurs aberrantes, et celles-ci ne sont pas extrêmes.
- La caractéristique est distribuée de manière approximativement uniforme sur sa plage. Autrement dit, un histogramme afficherait des barres à peu près égales pour la plupart des valeurs.
Supposons que age humain soit une caractéristique. La mise à l'échelle linéaire est une bonne technique de normalisation pour age, car :
- Les limites inférieure et supérieure approximatives sont comprises entre 0 et 100.
agecontient un pourcentage relativement faible de valeurs aberrantes. Seulement 0,3 % environ de la population a plus de 100 ans.- Bien que certains âges soient un peu mieux représentés que d'autres, un grand ensemble de données devrait contenir suffisamment d'exemples de tous les âges.
Exercice : Vérifier que vous avez bien compris
Supposons que votre modèle comporte une caractéristique nomméenet_worth qui contient la valeur nette de différentes personnes. La mise à l'échelle linéaire serait-elle une bonne technique de normalisation pour net_worth ? Pourquoi ?
Mise à l'échelle du score Z
Un score Z correspond au nombre d'écarts types d'une valeur par rapport à la moyenne. Par exemple, une valeur qui est supérieure à la moyenne de deux écarts types a un score Z de +2,0. Une valeur qui est 1,5 écart type inférieure à la moyenne a un score Z de -1,5.
Représenter une caractéristique avec la mise à l'échelle du score Z signifie stocker le score Z de cette caractéristique dans le vecteur de caractéristiques. Par exemple, la figure suivante montre deux histogrammes :
- À gauche, une distribution normale classique.
- À droite, la même distribution est normalisée par mise à l'échelle du score Z.

La mise à l'échelle du score Z est également un bon choix pour les données telles que celles illustrées dans la figure suivante, qui ne présentent qu'une distribution vaguement normale.

Le score Z est un bon choix lorsque les données suivent une distribution normale ou une distribution qui s'en rapproche.
Notez que certaines distributions peuvent être normales dans la majeure partie de leur plage, mais contenir tout de même des valeurs aberrantes extrêmes. Par exemple, la quasi-totalité des points d'une caractéristique net_worth peuvent s'intégrer parfaitement dans 3 écarts-types, mais quelques exemples de cette caractéristique peuvent se trouver à des centaines d'écarts-types de la moyenne. Dans ce cas, vous pouvez combiner la mise à l'échelle du score Z avec une autre forme de normalisation (généralement le clipping) pour gérer cette situation.
Exercice : Vérifier que vous avez bien compris
Supposons que votre modèle s'entraîne sur une caractéristique nomméeheight qui contient les tailles adultes de dix millions de femmes. La mise à l'échelle du score Z serait-elle une bonne technique de normalisation pour height ? Pourquoi ?
Mise à l'échelle logarithmique
La mise à l'échelle logarithmique calcule le logarithme de la valeur brute. En théorie, le logarithme peut être n'importe quelle base. En pratique, la mise à l'échelle logarithmique calcule généralement le logarithme naturel (ln).
La mise à l'échelle logarithmique est utile lorsque les données suivent une distribution de loi de puissance. En termes simples, une distribution de loi de puissance se présente comme suit :
- Les valeurs faibles de
Xcorrespondent à des valeurs très élevées deY. - À mesure que les valeurs de
Xaugmentent, celles deYdiminuent rapidement. Par conséquent, les valeurs élevées deXcorrespondent à des valeurs très faibles deY.
Les notes de films sont un bon exemple de distribution de loi de puissance. Dans la figure suivante, notez les points suivants :
- Certains films ont reçu de nombreuses notes d'utilisateurs. (Les valeurs faibles de
Xcorrespondent à des valeurs élevées deY.) - La plupart des films ont très peu de notes d'utilisateurs. (Les valeurs élevées de
Xsont associées à des valeurs faibles deY.)
La mise à l'échelle logarithmique modifie la distribution, ce qui permet d'entraîner un modèle qui fera de meilleures prédictions.

Voici un autre exemple : les ventes de livres suivent une loi de puissance, car :
- La plupart des livres publiés se vendent à un très petit nombre d'exemplaires, peut-être une ou deux centaines.
- Certains livres se vendent à un nombre modéré d'exemplaires, soit plusieurs milliers.
- Seuls quelques best-sellers se vendent à plus d'un million d'exemplaires.
Supposons que vous entraîniez un modèle linéaire pour trouver la relation entre, par exemple, les couvertures de livres et les ventes de livres. Un modèle linéaire entraîné sur des valeurs brutes devrait trouver quelque chose sur les couvertures de livres qui se vendent à un million d'exemplaires,qui est 10 000 fois plus puissant que les couvertures de livres qui ne se vendent qu'à 100 exemplaires. Toutefois, la mise à l'échelle logarithmique de tous les chiffres de vente rend la tâche beaucoup plus réalisable. Par exemple, le logarithme de 100 est le suivant :
~4.6 = ln(100)
alors que le logarithme de 1 000 000 est le suivant :
~13.8 = ln(1,000,000)
Ainsi, le logarithme de 1 000 000 n'est que trois fois plus grand que celui de 100. Vous pouvez probablement imaginer qu'une couverture de livre à succès est environ trois fois plus efficace (d'une manière ou d'une autre) qu'une couverture de livre qui se vend très peu.
Bornement
Le bornement est une technique permettant de minimiser l'influence des anomalies extrêmes. En bref, le clipping consiste généralement à plafonner (réduire) la valeur des valeurs aberrantes à une valeur maximale spécifique. Le clipping est une idée étrange, mais il peut être très efficace.
Par exemple, imaginons un ensemble de données contenant une caractéristique nommée roomsPerPerson, qui représente le nombre de pièces (nombre total de pièces divisé par le nombre d'occupants) pour différentes maisons. Le graphique suivant montre que plus de 99 % des valeurs de caractéristiques suivent une distribution normale (avec une moyenne d'environ 1,8 et un écart-type de 0,7). Toutefois, la fonctionnalité contient quelques valeurs aberrantes, dont certaines sont extrêmes :

Comment minimiser l'impact de ces anomalies extrêmes ? L'histogramme n'est pas une distribution uniforme, une distribution normale ni une distribution de loi de puissance. Que se passe-t-il si vous limitez ou tronquez simplement la valeur maximale de roomsPerPerson à une valeur arbitraire, par exemple 4,0 ?

Le fait de limiter la valeur de la caractéristique à 4,0 ne signifie pas que votre modèle ignore toutes les valeurs supérieures à 4,0. Cela signifie plutôt que toutes les valeurs supérieures à 4,0 deviennent 4,0. Cela explique la forme particulière de la colline à 4.0. Malgré cette difficulté, l'ensemble de caractéristiques mis à l'échelle est désormais plus utile que les données d'origine.
Attends une seconde ! Pouvez-vous vraiment réduire chaque valeur aberrante à un seuil supérieur arbitraire ? Oui, lorsque vous entraînez un modèle.
Vous pouvez également écrêter les valeurs après avoir appliqué d'autres formes de normalisation. Par exemple, supposons que vous utilisiez la mise à l'échelle du score Z, mais que quelques valeurs aberrantes aient des valeurs absolues bien supérieures à 3. Dans ce cas, vous pouvez :
- Borner les scores Z supérieurs à 3 pour obtenir exactement 3.
- Borner les scores Z inférieurs à -3 pour obtenir exactement -3.
Le clipping empêche votre modèle de surindexer les données sans importance. Cependant, certains outliers sont en fait importants. Veillez donc à définir des valeurs limites avec précaution.
Résumé des techniques de normalisation
| Technique de normalisation | Formule | Quand les utiliser ? |
|---|---|---|
| Mise à l'échelle linéaire | $$ x' = \frac{x - x_{min}}{x_{max} - x_{min}} $$ | Lorsque la fonctionnalité est distribuée de manière relativement uniforme dans la plage. Forme plate |
| Mise à l'échelle du score Z | $$ x' = \frac{x - μ}{σ}$$ | Lorsque la fonctionnalité est normalement distribuée (pic proche de la moyenne). En forme de cloche |
| Mise à l'échelle logarithmique | $$ x' = log(x)$$ | Lorsque la distribution des caractéristiques est fortement asymétrique sur au moins l'un des côtés de la queue. Forme en queue de distribution lourde |
| Bornement | Si $x > max$, définissez $x' = max$ Si $x < min$, définissez $x' = min$ |
Lorsque la fonctionnalité contient des valeurs aberrantes extrêmes. |
Exercice : Testez vos connaissances
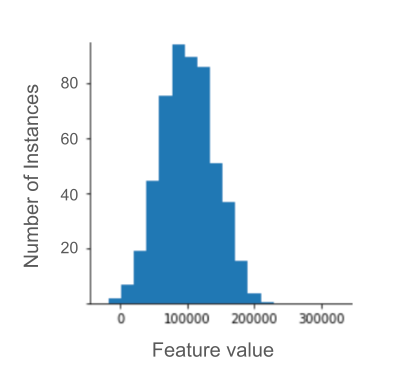
Supposons que vous développiez un modèle qui prédit la productivité d'un centre de données en fonction de la température mesurée à l'intérieur du centre de données.
Presque toutes les valeurs temperature de votre ensemble de données se situent entre 15 et 30 °C, à l'exception des suivantes :
- Une ou deux fois par an, lors de journées extrêmement chaudes, quelques valeurs comprises entre 31 et 45 sont enregistrées dans
temperature. - Chaque millième point de
temperatureest défini sur 1 000 au lieu de la température réelle.
Quelle serait une technique de normalisation raisonnable pour temperature ?
Les valeurs de 1 000 sont des erreurs et doivent être supprimées plutôt que tronquées.
Les valeurs comprises entre 31 et 45 sont des points de données légitimes. Il serait probablement judicieux de définir des limites pour ces valeurs, en supposant que l'ensemble de données ne contienne pas suffisamment d'exemples dans cette plage de températures pour entraîner le modèle à faire de bonnes prédictions. Toutefois, lors de l'inférence, notez que le modèle écrêté ferait donc la même prédiction pour une température de 45 °C que pour une température de 35 °C.