Cette page contient des termes du glossaire de l'IA générative. Pour consulter tous les termes du glossaire, cliquez ici.
A
adaptation
Synonyme d'optimisation ou d'affinage.
agent
Logiciel capable de raisonner sur les entrées utilisateur afin de planifier et d'exécuter des actions pour le compte de l'utilisateur.
Dans l'apprentissage par renforcement, un agent est l'entité qui utilise une stratégie pour maximiser le rendement attendu obtenu en passant d'un état à un autre de l'environnement.
mouton
Forme adjective de agent. Le terme "agentif" fait référence aux qualités que possèdent les agents (comme l'autonomie).
workflow agentif
Processus dynamique dans lequel un agent planifie et exécute de manière autonome des actions pour atteindre un objectif. Ce processus peut impliquer un raisonnement, l'appel d'outils externes et l'autocorrection de son plan.
Slop IA
Résultat d'un système d'IA générative qui privilégie la quantité à la qualité. Par exemple, une page Web contenant de la bouillie d'IA est remplie de contenus de mauvaise qualité, générés par IA et produits à bas prix.
évaluation automatique
Utilisation d'un logiciel pour évaluer la qualité de la sortie d'un modèle.
Lorsque la sortie du modèle est relativement simple, un script ou un programme peut comparer la sortie du modèle à une réponse de référence. Ce type d'évaluation automatique est parfois appelé évaluation programmatique. Les métriques telles que ROUGE ou BLEU sont souvent utiles pour l'évaluation programmatique.
Lorsque la sortie du modèle est complexe ou qu'il n'y a pas de bonne réponse, un programme de ML distinct appelé évaluateur automatique effectue parfois l'évaluation automatique.
À comparer à l'évaluation humaine.
Évaluation de l'outil d'évaluation automatique
Mécanisme hybride permettant de juger de la qualité de la sortie d'un modèle d'IA générative, qui combine l'évaluation humaine et l'évaluation automatique. Un évaluateur automatique est un modèle de ML entraîné sur des données créées par l'évaluation humaine. Idéalement, un évaluateur automatique apprend à imiter un évaluateur humain.Des évaluateurs automatiques prédéfinis sont disponibles, mais les meilleurs sont affinés spécifiquement pour la tâche que vous évaluez.
modèle autorégressif
Un modèle qui déduit une prédiction à partir de ses propres prédictions précédentes. Par exemple, les modèles de langage autorégressifs prédisent le prochain jeton en fonction des jetons prédits précédemment. Tous les grands modèles de langage basés sur Transformer sont autorégressifs.
En revanche, les modèles d'images basés sur les GAN ne sont généralement pas autorégressifs, car ils génèrent une image en une seule passe avant, et non de manière itérative par étapes. Cependant, certains modèles de génération d'images sont autorégressifs, car ils génèrent une image par étapes.
B
modèle de base
Un modèle pré-entraîné qui peut servir de point de départ pour l'affinage afin de répondre à des tâches ou applications spécifiques.
Voir aussi modèle pré-entraîné et modèle de fondation.
C
prompting par chaîne de pensée
Technique de prompt engineering qui encourage un grand modèle de langage (LLM) à expliquer son raisonnement, étape par étape. Par exemple, examinez l'invite suivante, en prêtant une attention particulière à la deuxième phrase :
Combien de forces G un conducteur ressentirait-il dans une voiture qui passe de 0 à 100 km/h en 7 secondes ? Dans la réponse, indique tous les calculs pertinents.
La réponse du LLM serait probablement :
- Affiche une séquence de formules de physique, en insérant les valeurs 0, 60 et 7 aux endroits appropriés.
- Explique pourquoi il a choisi ces formules et ce que signifient les différentes variables.
Les requêtes en chaîne de pensée forcent le LLM à effectuer tous les calculs, ce qui peut conduire à une réponse plus correcte. De plus, l'incitation à la réflexion en chaîne permet à l'utilisateur d'examiner les étapes du LLM pour déterminer si la réponse est logique ou non.
chat
Contenu d'un dialogue avec un système de ML, généralement un grand modèle de langage. L'interaction précédente dans une discussion (ce que vous avez écrit et la réponse du grand modèle de langage) devient le contexte pour les parties suivantes de la discussion.
Un chatbot est une application d'un grand modèle de langage.
embedding de langage contextualisé
Un embedding qui s'approche de la "compréhension" des mots et des expressions comme le font les locuteurs humains. Les embeddings de langage contextualisés peuvent comprendre la syntaxe, la sémantique et le contexte complexes.
Prenons l'exemple des embeddings du mot anglais cow (vache). Les anciens embeddings, tels que word2vec, peuvent représenter des mots anglais de sorte que la distance dans l'espace d'embedding entre cow (vache) et bull (taureau) soit semblable à la distance entre ewe (brebis) et ram (bélier), ou entre female (femme) et male (homme). Les embeddings de langage contextualisés peuvent aller plus loin en reconnaissant que les anglophones utilisent parfois le mot cow (vache) pour désigner une vache ou un taureau.
fenêtre de contexte
Nombre de jetons qu'un modèle peut traiter dans une requête donnée. Plus la fenêtre de contexte est grande, plus le modèle peut utiliser d'informations pour fournir des réponses cohérentes à la requête.
codage conversationnel
Dialogue itératif entre vous et un modèle d'IA générative dans le but de créer un logiciel. Vous émettez une requête décrivant un logiciel. Le modèle utilise ensuite cette description pour générer du code. Ensuite, vous émettez une nouvelle requête pour corriger les défauts de la requête précédente ou du code généré, et le modèle génère un code mis à jour. Vous deux continuez à échanger jusqu'à ce que le logiciel généré soit suffisamment bon.
Le codage des conversations est essentiellement la signification d'origine du vibe coding.
À comparer au codage spécificationnel.
D
le prompting direct ;
Synonyme de requête zero-shot.
distillation
Processus de réduction de la taille d'un modèle (appelé modèle enseignant) en un modèle plus petit (appelé modèle élève) qui imite les prédictions du modèle d'origine aussi fidèlement que possible. La distillation est utile, car le modèle plus petit présente deux avantages clés par rapport au modèle plus grand (l'enseignant) :
- Temps d'inférence plus rapide
- Réduction de l'utilisation de la mémoire et de l'énergie
Toutefois, les prédictions de l'élève ne sont généralement pas aussi bonnes que celles de l'enseignant.
La distillation entraîne le modèle élève à minimiser une fonction de perte basée sur la différence entre les sorties des prédictions des modèles élève et enseignant.
Comparez et opposez la distillation aux termes suivants :
Pour en savoir plus, consultez LLM : affinage, distillation et ingénierie des prompts dans le cours d'initiation au machine learning.
E
evals
Principalement utilisé comme abréviation pour évaluations LLM. Plus généralement, evals est l'abréviation de toute forme d'évaluation.
hors connexion
Processus de mesure de la qualité d'un modèle ou de comparaison de différents modèles.
Pour évaluer un modèle de machine learning supervisé, vous le comparez généralement à un ensemble de validation et à un ensemble de test. L'évaluation d'un LLM implique généralement des évaluations plus larges de la qualité et de la sécurité.
F
factualité
Dans le monde du ML, il s'agit d'une propriété décrivant un modèle dont la sortie est basée sur la réalité. La factualité est un concept plutôt qu'une métrique. Par exemple, supposons que vous envoyez la requête suivante à un grand modèle de langage :
Quelle est la formule chimique du sel de table ?
Un modèle qui optimise la factualité répondrait :
NaCl
Il est tentant de supposer que tous les modèles doivent être basés sur la factualité. Toutefois, certains prompts, tels que ceux ci-dessous, devraient inciter un modèle d'IA générative à optimiser la créativité plutôt que la factualité.
Raconte-moi un limerick sur un astronaute et une chenille.
Il est peu probable que le limerick obtenu soit basé sur la réalité.
À comparer à l'ancrage.
régression rapide
Technique d'entraînement permettant d'améliorer les performances des LLM. La décroissance rapide consiste à diminuer rapidement le taux d'apprentissage pendant l'entraînement. Cette stratégie permet d'éviter le surapprentissage du modèle par rapport aux données d'entraînement et d'améliorer la généralisation.
prompting few-shot
Une requête contenant plusieurs exemples ("few-shot") montrant comment le grand modèle de langage doit répondre. Par exemple, l'invite longue suivante contient deux exemples montrant à un grand modèle de langage comment répondre à une requête.
| Composantes d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | La question à laquelle vous souhaitez que le LLM réponde. |
| France : EUR | Voici un exemple. |
| Royaume-Uni : GBP | Autre exemple. |
| Inde : | Requête réelle. |
Le prompting few-shot produit généralement des résultats plus intéressants que le prompting zero-shot et le prompting one-shot. Toutefois, le prompting few-shot nécessite un prompt plus long.
Le prompting few-shot est une forme d'apprentissage few-shot appliquée à l'apprentissage basé sur les requêtes.
Pour en savoir plus, consultez Ingénierie des requêtes dans le Cours d'initiation au machine learning.
affinage
Deuxième passe d'entraînement spécifique à une tâche effectuée sur un modèle pré-entraîné pour affiner ses paramètres pour un cas d'utilisation spécifique. Par exemple, la séquence d'entraînement complète de certains grands modèles de langage est la suivante :
- Pré-entraînement : entraînez un grand modèle de langage sur un vaste ensemble de données générales, comme toutes les pages Wikipédia en anglais.
- Affinage : entraînez le modèle pré-entraîné à effectuer une tâche spécifique, comme répondre à des questions médicales. L'affinage implique généralement des centaines ou des milliers d'exemples axés sur la tâche spécifique.
Autre exemple : la séquence d'entraînement complète pour un grand modèle d'image est la suivante :
- Pré-entraînement : entraînez un grand modèle d'image sur un vaste ensemble de données d'images générales, comme toutes les images de Wikimedia Commons.
- Affinage : entraînez le modèle pré-entraîné pour qu'il effectue une tâche spécifique, comme générer des images d'épaulards.
L'affinage peut impliquer n'importe quelle combinaison des stratégies suivantes :
- Modification de tous les paramètres existants du modèle pré-entraîné. On parle parfois d'affinage complet.
- Modification de certains paramètres existants du modèle pré-entraîné (généralement, les couches les plus proches de la couche de sortie), tout en conservant les autres paramètres existants (généralement, les couches les plus proches de la couche d'entrée). Consultez la section Affinage d'un sous-ensemble de paramètres.
- Ajouter des calques, généralement au-dessus des calques existants les plus proches du calque de sortie.
L'optimisation est une forme d'apprentissage par transfert. Par conséquent, l'affinage peut utiliser une fonction de perte ou un type de modèle différents de ceux utilisés pour entraîner le modèle pré-entraîné. Par exemple, vous pouvez affiner un grand modèle d'image pré-entraîné pour produire un modèle de régression qui renvoie le nombre d'oiseaux dans une image d'entrée.
Comparez et opposez le fine-tuning aux termes suivants :
Pour en savoir plus, consultez Finetuning dans le cours d'initiation au machine learning.
Modèle Flash
Une famille de modèles Gemini relativement petits, optimisés pour la vitesse et la faible latence. Les modèles Flash sont conçus pour un large éventail d'applications où des réponses rapides et un débit élevé sont essentiels.
modèle de fondation
Un modèle pré-entraîné très volumineux, entraîné sur un ensemble d'entraînement énorme et diversifié. Un modèle de fondation peut effectuer les deux opérations suivantes :
- répondre correctement à un large éventail de requêtes ;
- Servir de modèle de base pour un affinage supplémentaire ou d'autres personnalisations.
En d'autres termes, un modèle de fondation est déjà très performant de manière générale, mais il peut être personnalisé davantage pour devenir encore plus utile pour une tâche spécifique.
fraction de succès
Métrique permettant d'évaluer le texte généré par un modèle de ML. La fraction de succès correspond au nombre de résultats textuels générés "réussis" divisé par le nombre total de résultats textuels générés. Par exemple, si un grand modèle de langage a généré 10 blocs de code, dont cinq ont réussi, la fraction de succès serait de 50 %.
Bien que la fraction de succès soit largement utile dans les statistiques, dans le ML, cette métrique est principalement utile pour mesurer les tâches vérifiables telles que la génération de code ou les problèmes mathématiques.
G
Gemini
Écosystème comprenant l'IA la plus avancée de Google. Voici quelques éléments de cet écosystème :
- Différents modèles Gemini.
- Interface de conversation interactive avec un modèle Gemini. Les utilisateurs saisissent des requêtes et Gemini y répond.
- Diverses API Gemini.
- Divers produits professionnels basés sur les modèles Gemini, par exemple Gemini pour Google Cloud.
Modèles Gemini
Modèles multimodaux de pointe de Google basés sur Transformer. Les modèles Gemini sont spécifiquement conçus pour s'intégrer aux agents.
Les utilisateurs peuvent interagir avec les modèles Gemini de différentes manières, y compris via une interface de dialogue interactive et des SDK.
Gemma
Une famille de modèles ouverts et légers basés sur les mêmes recherches et technologies que celles utilisées pour créer les modèles Gemini. Plusieurs modèles Gemma sont disponibles, chacun offrant des fonctionnalités différentes, telles que la vision, le code et le suivi d'instructions. Pour en savoir plus, consultez Gemma.
IA générative
Abréviation de IA générative.
texte généré
Texte généré par un modèle de ML. Lors de l'évaluation de grands modèles de langage, certaines métriques comparent le texte généré au texte de référence. Par exemple, supposons que vous essayiez de déterminer l'efficacité d'un modèle de ML pour traduire du français vers le néerlandais. Dans ce cas :
- Le texte généré est la traduction en néerlandais fournie par le modèle de ML.
- Le texte de référence est la traduction en néerlandais créée par un traducteur humain (ou un logiciel).
Notez que certaines stratégies d'évaluation n'impliquent pas de texte de référence.
IA générative
Il s'agit d'un domaine de transformation émergent sans définition formelle. Cela dit, la plupart des experts s'accordent à dire que les modèles d'IA générative peuvent créer ("générer") des contenus qui sont à la fois :
- complexe
- cohérent
- originale
Voici quelques exemples d'IA générative :
- Les grands modèles de langage, qui peuvent générer du texte original sophistiqué et répondre à des questions.
- Modèle de génération d'images, qui peut produire des images uniques.
- Modèles de génération audio et musicale, qui peuvent composer de la musique originale ou générer des voix réalistes.
- Les modèles de génération de vidéos, qui peuvent générer des vidéos originales.
Certaines technologies plus anciennes, y compris les LSTM et les RNN, peuvent également générer des contenus originaux et cohérents. Certains experts considèrent ces technologies antérieures comme de l'IA générative, tandis que d'autres estiment que la véritable IA générative nécessite des résultats plus complexes que ceux que ces technologies antérieures peuvent produire.
À comparer au ML prédictif.
réponse optimale
Une réponse reconnue comme étant de bonne qualité. Par exemple, prenons le prompt suivant :
2 + 2
La réponse idéale est la suivante :
4
GPT (Generative Pre-trained Transformer)
Une famille de grands modèles de langage basés sur Transformer développés par OpenAI.
Les variantes GPT peuvent s'appliquer à plusieurs modalités, y compris :
- la génération d'images (par exemple, ImageGPT) ;
- génération d'images à partir de texte (par exemple, DALL-E).
H
hallucination
Production de résultats qui semblent plausibles, mais qui sont factuellement incorrects, par un modèle d'IA générative qui prétend faire une affirmation sur le monde réel. Par exemple, un modèle d'IA générative qui affirme que Barack Obama est décédé en 1865 hallucine.
évaluation humaine
Processus dans lequel des personnes évaluent la qualité de la sortie d'un modèle de ML. Par exemple, des personnes bilingues peuvent évaluer la qualité d'un modèle de traduction de ML. L'évaluation humaine est particulièrement utile pour juger les modèles qui n'ont pas de réponse unique.
À comparer à l'évaluation automatique et à l'évaluation par un évaluateur automatique.
human-in-the-loop (avec intervention humaine)
Expression idiomatique mal définie qui peut signifier l'une des deux choses suivantes :
- Une règle qui consiste à examiner de manière critique ou sceptique les résultats de l'IA générative.
- Stratégie ou système permettant de s'assurer que les utilisateurs contribuent à façonner, évaluer et affiner le comportement d'un modèle. Le fait de garder un humain dans la boucle permet à une IA de bénéficier à la fois de l'intelligence artificielle et de l'intelligence humaine. Par exemple, un système dans lequel une IA génère du code que des ingénieurs logiciels examinent ensuite est un système avec supervision humaine.
I
apprentissage en contexte
Synonyme de requête few-shot.
inférence
Dans le machine learning traditionnel, processus consistant à effectuer des prédictions en appliquant un modèle entraîné à des exemples sans étiquette. Pour en savoir plus, consultez Apprentissage supervisé dans le cours d'introduction au ML.
Dans les grands modèles de langage, l'inférence est le processus d'utilisation d'un modèle entraîné pour générer une réponse à une requête d'entrée.
L'inférence a une signification quelque peu différente en statistiques. Pour en savoir plus, consultez l' article Wikipédia sur l'inférence statistique.
réglage des instructions
Forme d'affinage qui améliore la capacité d'un modèle d'IA générative à suivre des instructions. L'affinage des instructions consiste à entraîner un modèle sur une série de requêtes d'instructions, couvrant généralement un large éventail de tâches. Le modèle affiné par instruction qui en résulte a ensuite tendance à générer des réponses utiles aux requêtes zero-shot pour diverses tâches.
Comparer et différencier :
L
grand modèle de langage
Au minimum, un modèle de langage comportant un très grand nombre de paramètres. Plus précisément, tout modèle de langage basé sur Transformer, comme Gemini ou GPT.
Pour en savoir plus, consultez Grands modèles de langage (LLM) dans le Cours d'initiation au Machine Learning.
latence
Temps nécessaire à un modèle pour traiter une entrée et générer une réponse. Une réponse à latence élevée prend plus de temps à générer qu'une réponse à latence faible.
Voici quelques facteurs qui influencent la latence des grands modèles de langage :
- Longueurs des jetons d'entrée et de sortie
- Complexité des modèles
- Infrastructure sur laquelle le modèle s'exécute
L'optimisation de la latence est essentielle pour créer des applications réactives et conviviales.
LLM
Abréviation de grand modèle de langage.
Évaluations de LLM
Ensemble de métriques et de benchmarks permettant d'évaluer les performances des grands modèles de langage (LLM). De manière générale, les évaluations de LLM :
- Aider les chercheurs à identifier les domaines dans lesquels les LLM doivent être améliorés
- Elles sont utiles pour comparer différents LLM et identifier le meilleur LLM pour une tâche spécifique.
- Contribuer à garantir que les LLM sont sûrs et éthiques à utiliser.
Pour en savoir plus, consultez Grands modèles de langage (LLM) dans le cours d'initiation au Machine Learning.
LoRA
Abréviation de Low-Rank Adaptability (adaptabilité de rang faible).
Adaptabilité à faible rang (LoRA)
Il s'agit d'une technique efficace en termes de paramètres pour l'affinage qui "fige" les pondérations pré-entraînées du modèle (de sorte qu'elles ne peuvent plus être modifiées), puis insère un petit ensemble de pondérations entraînables dans le modèle. Cet ensemble de pondérations entraînables (également appelées "matrices de mise à jour") est considérablement plus petit que le modèle de base et est donc beaucoup plus rapide à entraîner.
LoRA offre les avantages suivants :
- Améliore la qualité des prédictions d'un modèle pour le domaine dans lequel l'affinage est appliqué.
- Il s'affine plus rapidement que les techniques qui nécessitent d'affiner tous les paramètres d'un modèle.
- Réduit les coûts de calcul de l'inférence en permettant la diffusion simultanée de plusieurs modèles spécialisés partageant le même modèle de base.
M
traduction automatique
Utilisation d'un logiciel (généralement un modèle de machine learning) pour convertir du texte d'une langue humaine à une autre, par exemple de l'anglais vers le japonais.
Précision moyenne à k (mAP@k)
Moyenne statistique de tous les scores précision moyenne à k dans un ensemble de données de validation. La précision moyenne à k permet d'évaluer la qualité des recommandations générées par un système de recommandation.
Bien que l'expression "moyenne moyenne" semble redondante, le nom de la métrique est approprié. En effet, cette métrique trouve la moyenne de plusieurs valeurs précision moyenne à k.
mixture of experts
Schéma permettant d'accroître l'efficacité d'un réseau de neurones en n'utilisant qu'un sous-ensemble de ses paramètres (appelé expert) pour traiter un jeton ou un exemple d'entrée donné. Un réseau de gating achemine chaque jeton ou exemple d'entrée vers le ou les experts appropriés.
Pour en savoir plus, consultez l'un des articles suivants :
- Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer
- Mixture-of-Experts avec routage Expert Choice
MMIT
Abréviation de multimodal instruction-tuned (multimodal adapté aux instructions).
mise en cascade de modèles
Système qui sélectionne le modèle idéal pour une requête d'inférence spécifique.
Imaginez un groupe de modèles, allant de très grands (avec de nombreux paramètres) à beaucoup plus petits (avec beaucoup moins de paramètres). Les très grands modèles consomment plus de ressources de calcul au moment de l'inférence que les modèles plus petits. Toutefois, les très grands modèles peuvent généralement inférer des requêtes plus complexes que les modèles plus petits. La mise en cascade des modèles détermine la complexité de la requête d'inférence, puis sélectionne le modèle approprié pour effectuer l'inférence. La principale motivation de la mise en cascade des modèles est de réduire les coûts d'inférence en sélectionnant généralement des modèles plus petits et en ne sélectionnant un modèle plus grand que pour les requêtes plus complexes.
Imaginez qu'un petit modèle s'exécute sur un téléphone et qu'une version plus grande de ce modèle s'exécute sur un serveur distant. Une bonne mise en cascade des modèles réduit les coûts et la latence en permettant au modèle plus petit de traiter les requêtes simples et en n'appelant le modèle distant que pour les requêtes complexes.
Voir aussi routeur de modèle.
routeur de modèle
Algorithme qui détermine le modèle idéal pour l'inférence dans la mise en cascade de modèles. Un routeur de modèle est lui-même généralement un modèle de machine learning qui apprend progressivement à choisir le meilleur modèle pour une entrée donnée. Toutefois, un routeur de modèle peut parfois être un algorithme plus simple, non basé sur le machine learning.
ME
Abréviation de mixture of experts (mélange d'experts).
MT
Abréviation de traduction automatique.
N
Nano
Un modèle Gemini relativement petit, conçu pour une utilisation sur l'appareil. Pour en savoir plus, consultez Gemini Nano.
aucune réponse unique (NORA, no one right answer)
Une requête ayant plusieurs réponses correctes. Par exemple, la requête suivante n'a pas qu'une seule bonne réponse :
Raconte-moi une blague amusante sur les éléphants.
Évaluer les réponses aux requêtes sans réponse unique est généralement beaucoup plus subjectif que d'évaluer les requêtes avec une réponse unique. Par exemple, pour évaluer une blague sur un éléphant, il faut une méthode systématique pour déterminer son degré d'humour.
NORA
Abréviation de no one right answer (pas de bonne réponse).
NotebookLM
Outil basé sur Gemini qui permet aux utilisateurs d'importer des documents, puis d'utiliser des requêtes pour poser des questions sur ces documents, les résumer ou les organiser. Par exemple, un auteur peut importer plusieurs nouvelles et demander à NotebookLM de trouver leurs thèmes communs ou d'identifier celle qui ferait le meilleur film.
O
une seule bonne réponse (ORA, one right answer)
Une requête ayant une seule réponse correcte. Par exemple, prenons la requête suivante :
Vrai ou faux : Saturne est plus grande que Mars.
La seule réponse correcte est vrai.
À comparer à il n'y a pas qu'une seule bonne réponse.
prompting one-shot
Une requête contenant un exemple montrant comment le grand modèle de langage doit répondre. Par exemple, l'invite suivante contient un exemple montrant à un grand modèle de langage comment répondre à une requête.
| Composantes d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | La question à laquelle vous souhaitez que le LLM réponde. |
| France : EUR | Voici un exemple. |
| Inde : | Requête réelle. |
Indiquer les points communs et les différences entre l'incitation one-shot et les termes suivants :
ORA
Abréviation de une seule bonne réponse.
P
optimisation du réglage des paramètres
Ensemble de techniques permettant d'affiner un grand modèle de langage préentraîné (PLM) plus efficacement que l'affinage complet. Le réglage des paramètres avec optimisation affine généralement beaucoup moins de paramètres que l'affinage complet, mais produit généralement un grand modèle de langage aussi performant (ou presque) qu'un grand modèle de langage créé à partir d'un affinage complet.
Comparez et opposez l'optimisation du réglage des paramètres avec :
Le réglage des paramètres avec optimisation est également appelé affinage d'un sous-ensemble de paramètres.
Pax
Framework de programmation conçu pour entraîner des modèles de réseaux de neurones à grande échelle, si grands qu'ils s'étendent sur plusieurs tranches ou pods de puces d'accélérateur TPU.
Pax est basé sur Flax, qui est basé sur JAX.
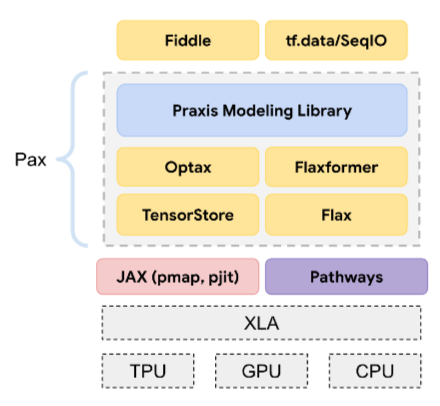
PLM
Abréviation de modèle de langage pré-entraîné.
modèle post-entraîné
Terme mal défini qui fait généralement référence à un modèle pré-entraîné qui a subi un post-traitement, par exemple un ou plusieurs des éléments suivants :
modèle pré-entraîné
Bien que ce terme puisse faire référence à n'importe quel modèle ou vecteur d'embedding entraîné, le terme "modèle pré-entraîné" fait désormais généralement référence à un grand modèle de langage entraîné ou à une autre forme de modèle d'IA générative entraîné.
Voir aussi modèle de base et modèle de fondation.
auto-supervisé
Entraînement initial d'un modèle sur un grand ensemble de données. Certains modèles pré-entraînés sont des géants maladroits et doivent généralement être affinés par un entraînement supplémentaire. Par exemple, les experts en ML peuvent pré-entraîner un grand modèle de langage sur un vaste ensemble de données textuelles, comme toutes les pages en anglais de Wikipédia. Après le pré-entraînement, le modèle obtenu peut être affiné à l'aide de l'une des techniques suivantes :
- distillation
- fine-tuning
- Réglage des instructions
- Optimisation efficace en termes de paramètres
- prompt-tuning
Pro
Un modèle Gemini avec moins de paramètres que Ultra, mais plus que Nano. Pour en savoir plus, consultez Gemini Pro.
prompt
Tout texte saisi en entrée dans un grand modèle de langage pour conditionner le modèle à se comporter d'une certaine manière. Les requêtes peuvent être aussi courtes qu'une phrase ou arbitrairement longues (par exemple, le texte complet d'un roman). Les requêtes sont classées dans plusieurs catégories, y compris celles indiquées dans le tableau suivant :
| Catégorie de requête | Exemple | Remarques |
|---|---|---|
| Question | À quelle vitesse un pigeon peut-il voler ? | |
| Instruction | Écris un poème amusant sur l'arbitrage. | Requête qui demande au grand modèle de langage de faire quelque chose. |
| Exemple | Traduisez le code Markdown en HTML. Par exemple :
Markdown : * list item HTML : <ul> <li>list item</li> </ul> |
La première phrase de cet exemple de requête est une instruction. Le reste de la requête est l'exemple. |
| Rôle | Explique à un docteur en physique pourquoi la descente de gradient est utilisée dans l'entraînement du machine learning. | La première partie de la phrase est une instruction, tandis que l'expression "à un doctorat en physique" correspond à la partie du rôle. |
| Entrée partielle à compléter par le modèle | Le Premier ministre du Royaume-Uni vit au | Une invite d'entrée partielle peut se terminer brusquement (comme dans cet exemple) ou par un trait de soulignement. |
Un modèle d'IA générative peut répondre à une requête avec du texte, du code, des images, des représentations vectorielles continues, des vidéos… presque tout.
apprentissage basé sur les requêtes
Capacité de certains modèles qui leur permet d'adapter leur comportement en réponse à une entrée de texte arbitraire (requêtes). Dans un paradigme d'apprentissage basé sur les requêtes, un grand modèle de langage répond à une requête en générant du texte. Par exemple, supposons qu'un utilisateur saisisse la requête suivante :
Résume la troisième loi du mouvement de Newton.
Un modèle capable d'apprendre à partir de requêtes n'est pas spécifiquement entraîné pour répondre à la requête précédente. Le modèle "connaît" de nombreux faits sur la physique, de nombreuses règles générales de langage et de nombreuses informations sur ce qui constitue des réponses généralement utiles. Ces connaissances suffisent à fournir une réponse (espérons-le) utile. Le feedback humain supplémentaire ("Cette réponse était trop compliquée" ou "Qu'est-ce qu'une réaction ?") permet à certains systèmes d'apprentissage basés sur les requêtes d'améliorer progressivement l'utilité de leurs réponses.
conception de prompts
Synonyme de prompt engineering.
prompt engineering
L'art de créer des requêtes qui déclenchent les réponses souhaitées d'un grand modèle de langage. Les humains effectuent l'ingénierie des requêtes. Pour obtenir des réponses utiles d'un grand modèle de langage, il est essentiel de rédiger des requêtes bien structurées. L'ingénierie des requêtes dépend de nombreux facteurs, y compris :
- Ensemble de données utilisé pour le pré-entraînement et éventuellement l'affinage du grand modèle de langage.
- Le paramètre temperature et d'autres paramètres de décodage que le modèle utilise pour générer des réponses.
La conception de requêtes est un synonyme de l'ingénierie des requêtes.
Pour en savoir plus sur la rédaction de requêtes utiles, consultez Présentation de la conception de requêtes.
ensemble de requêtes
Un groupe de requêtes pour évaluer un grand modèle de langage. Par exemple, l'illustration suivante montre un ensemble de requêtes composé de trois requêtes :
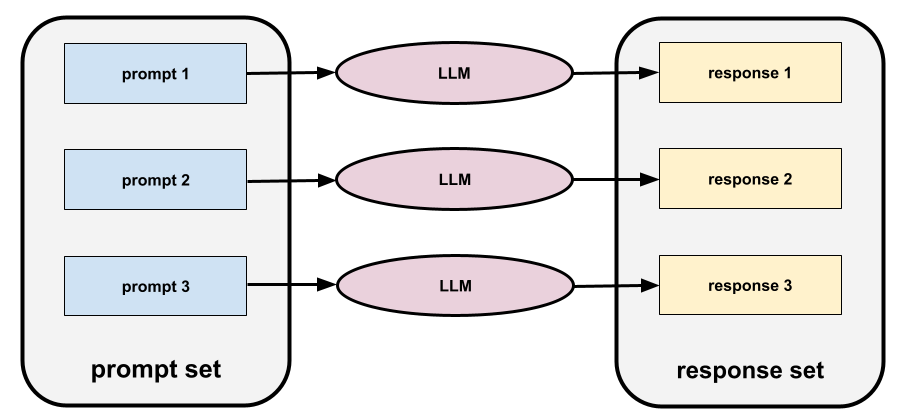
Les bons ensembles de requêtes se composent d'une collection de requêtes suffisamment "large" pour évaluer en profondeur la sécurité et l'utilité d'un grand modèle de langage.
Voir aussi ensemble de réponses.
réglage des prompts
Mécanisme d'optimisation du réglage des paramètres qui apprend un "préfixe" que le système ajoute au prompt.
Une variante du réglage des requêtes, parfois appelée réglage des préfixes, consiste à ajouter le préfixe à chaque couche. En revanche, la plupart des ajustements d'invite n'ajoutent qu'un préfixe à la couche d'entrée.
R
texte de référence
Réponse d'un expert à une requête. Par exemple, prenons la requête suivante :
Traduis la question "What is your name?" de l'anglais vers le français.
Voici un exemple de réponse d'un expert :
Comment vous appelez-vous ?
Diverses métriques (telles que ROUGE) mesurent le degré de correspondance entre le texte de référence et le texte généré par un modèle de ML.
réflexion
Stratégie permettant d'améliorer la qualité d'un workflow agentique en examinant (en réfléchissant à) le résultat d'une étape avant de le transmettre à l'étape suivante.
L'examinateur est souvent le même LLM que celui qui a généré la réponse (mais il peut s'agir d'un autre LLM). Comment le même LLM qui a généré une réponse peut-il être un juge impartial de sa propre réponse ? L'astuce consiste à mettre le LLM dans un état d'esprit critique (réflexif). Ce processus est analogue à celui d'un écrivain qui utilise un état d'esprit créatif pour rédiger un premier brouillon, puis passe à un état d'esprit critique pour le modifier.
Par exemple, imaginez un workflow agentique dont la première étape consiste à créer du texte pour des tasses à café. Le prompt pour cette étape pourrait être :
Vous êtes un créateur. Génère un texte humoristique et original de moins de 50 caractères pour une tasse à café.
Imaginons maintenant le prompt de réflexion suivant :
Vous buvez du café. Trouvez-vous la réponse précédente amusante ?
Le workflow ne transmettra ensuite à l'étape suivante que le texte ayant obtenu un score de réflexion élevé.
Apprentissage automatique par renforcement qui utilise le feedback humain (RLHF)
Utilisation des commentaires d'évaluateurs humains pour améliorer la qualité des réponses d'un modèle. Par exemple, un mécanisme RLHF peut demander aux utilisateurs d'évaluer la qualité de la réponse d'un modèle à l'aide d'un emoji 👍 ou 👎. Le système peut ensuite ajuster ses futures réponses en fonction de ces commentaires.
réponse
Texte, images, éléments audio ou vidéo qu'un modèle d'IA générative déduit. En d'autres termes, un prompt est une entrée pour un modèle d'IA générative, et la réponse est la sortie.
ensemble de réponses
Ensemble de réponses qu'un grand modèle de langage renvoie à un ensemble de requêtes.
prompts de rôle
Un prompt, commençant généralement par le pronom vous, qui indique à un modèle d'IA générative de se faire passer pour une certaine personne ou un certain rôle lorsqu'il génère la réponse. L'incitation par rôle peut aider un modèle d'IA générative à adopter le bon "état d'esprit" pour générer une réponse plus utile. Par exemple, l'une des invites de rôle suivantes peut être appropriée en fonction du type de réponse que vous recherchez :
Vous êtes titulaire d'un doctorat en informatique.
Vous êtes un ingénieur logiciel qui aime expliquer patiemment Python aux nouveaux étudiants en programmation.
Vous êtes un héros de l'action doté de compétences en programmation très spécifiques. Assure-moi que tu trouveras un élément spécifique dans une liste Python.
S
Réglage des prompts logiciels
Technique permettant de régler un grand modèle de langage pour une tâche spécifique, sans affinage gourmand en ressources. Au lieu de réentraîner tous les poids du modèle, le réglage des soft prompts ajuste automatiquement un prompt pour atteindre le même objectif.
Étant donné un prompt textuel, le réglage des soft prompts ajoute généralement des embeddings de jetons supplémentaires au prompt et utilise la rétropropagation pour optimiser l'entrée.
Une requête "dure" contient des jetons réels au lieu d'embeddings de jetons.
codage spécificationnel
Processus d'écriture et de maintenance d'un fichier dans une langue humaine (par exemple, l'anglais) qui décrit un logiciel. Vous pouvez ensuite demander à un modèle d'IA générative ou à un autre ingénieur logiciel de créer le logiciel qui correspond à cette description.
Le code généré automatiquement nécessite généralement des itérations. Dans le codage spécificationnel, vous itérez sur le fichier de description. En revanche, dans le codage conversationnel, vous itérez dans la zone de requête. En pratique, la génération automatique de code implique parfois une combinaison de codage par spécification et de codage conversationnel.
T
température
Un hyperparamètre qui contrôle le degré de hasard de la sortie d'un modèle. Les températures plus élevées entraînent des résultats plus aléatoires, tandis que les températures plus basses entraînent des résultats moins aléatoires.
Le choix de la température optimale dépend de l'application spécifique et/ou des valeurs de chaîne.
U
Ultra
Le modèle Gemini avec le plus grand nombre de paramètres. Pour en savoir plus, consultez Gemini Ultra.
V
Vertex
Plate-forme Google Cloud pour l'IA et le machine learning. Vertex fournit des outils et une infrastructure pour créer, déployer et gérer des applications d'IA, y compris l'accès aux modèles Gemini.vibe coding
Demander à un modèle d'IA générative de créer un logiciel Autrement dit, vos requêtes décrivent l'objectif et les fonctionnalités du logiciel, qu'un modèle d'IA générative traduit en code source. Le code généré ne correspond pas toujours à vos intentions. Le vibe coding nécessite donc généralement des itérations.
Andrej Karpathy a inventé le terme "vibe coding" dans ce post sur X. Dans son post sur X, Karpathy le décrit comme "un nouveau type de programmation… où vous vous laissez complètement emporter par l'ambiance…" Le terme impliquait donc à l'origine une approche intentionnellement souple de la création de logiciels, dans laquelle vous n'examiniez peut-être même pas le code généré. Toutefois, le terme a rapidement évolué dans de nombreux cercles pour désigner désormais toute forme de codage généré par l'IA.
Pour une description plus détaillée du codage des ambiances, consultez Qu'est-ce que le vibe coding ?
Comparez également le vibe coding avec :
Z
prompting zero-shot
Une requête qui ne fournit pas d'exemple de réponse attendue du grand modèle de langage. Exemple :
| Composantes d'une requête | Remarques |
|---|---|
| Quelle est la devise officielle du pays spécifié ? | La question à laquelle vous souhaitez que le LLM réponde. |
| Inde : | Requête réelle. |
Le grand modèle de langage peut répondre de l'une des manières suivantes :
- Roupie
- INR
- ₹
- Roupie indienne
- La roupie
- Roupie indienne
Toutes les réponses sont correctes, mais vous pouvez préférer un format particulier.
Comparez et opposez l'incitation zero-shot aux termes suivants :