একটি নতুন প্রযুক্তি, বৃহৎ ভাষা মডেল ( LLMs ) একটি টোকেন বা টোকেনের ক্রম ভবিষ্যদ্বাণী করে, কখনও কখনও অনেক অনুচ্ছেদের ভবিষ্যদ্বাণী করা টোকেনের মূল্য। মনে রাখবেন যে একটি টোকেন একটি শব্দ, একটি উপশব্দ (একটি শব্দের একটি উপসেট), এমনকি একটি একক অক্ষরও হতে পারে। LLMs N-গ্রাম ভাষা মডেল বা পুনরাবৃত্ত নিউরাল নেটওয়ার্কের তুলনায় অনেক ভালো ভবিষ্যদ্বাণী করে কারণ:
- পুনরাবৃত্ত মডেলের তুলনায় LLM-এ অনেক বেশি পরামিতি থাকে।
- এলএলএম অনেক বেশি প্রসঙ্গ সংগ্রহ করে।
এই বিভাগটি LLM নির্মাণের জন্য সবচেয়ে সফল এবং বহুল ব্যবহৃত স্থাপত্যের সাথে পরিচয় করিয়ে দেয়: ট্রান্সফরমার।
ট্রান্সফরমার কী?
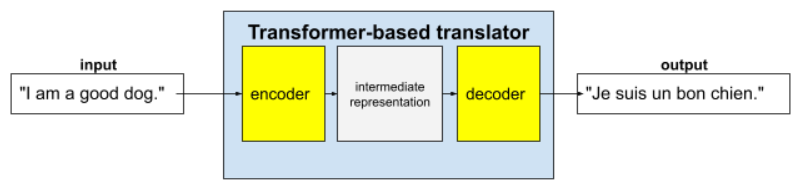
ট্রান্সফরমার হল অনুবাদের মতো বিভিন্ন ধরণের ভাষা মডেল অ্যাপ্লিকেশনের জন্য অত্যাধুনিক স্থাপত্য:

সম্পূর্ণ ট্রান্সফরমারগুলিতে একটি এনকোডার এবং একটি ডিকোডার থাকে:
- একটি এনকোডার ইনপুট টেক্সটকে একটি মধ্যবর্তী উপস্থাপনায় রূপান্তর করে। একটি এনকোডার হল একটি বিশাল নিউরাল নেট ।
- একটি ডিকোডার সেই মধ্যবর্তী উপস্থাপনাকে দরকারী টেক্সটে রূপান্তরিত করে। একটি ডিকোডারও একটি বিশাল স্নায়ু জাল।
উদাহরণস্বরূপ, একজন অনুবাদকের ক্ষেত্রে:
- এনকোডার ইনপুট টেক্সট (উদাহরণস্বরূপ, একটি ইংরেজি বাক্য) কিছু মধ্যবর্তী উপস্থাপনায় প্রক্রিয়া করে।
- ডিকোডার সেই মধ্যবর্তী উপস্থাপনাটিকে আউটপুট টেক্সটে রূপান্তর করে (উদাহরণস্বরূপ, সমতুল্য ফরাসি বাক্য)।
আত্ম-মনোযোগ কী?
প্রেক্ষাপট উন্নত করার জন্য, ট্রান্সফরমারগুলি স্ব-মনোযোগ নামক একটি ধারণার উপর ব্যাপকভাবে নির্ভর করে। কার্যকরভাবে, প্রতিটি ইনপুটের টোকেনের পক্ষে, স্ব-মনোযোগ নিম্নলিখিত প্রশ্ন জিজ্ঞাসা করে:
"এই টোকেনের ব্যাখ্যায় একে অপরের টোকেন অফ ইনপুট কতটা প্রভাব ফেলে?"
"আত্ম-মনোযোগ"-এ "স্ব" বলতে ইনপুট ক্রমকে বোঝায়। কিছু মনোযোগ প্রক্রিয়া ইনপুট টোকেনের সম্পর্ককে আউটপুট ক্রমানুসারে টোকেনের সাথে তুলনা করে, যেমন অনুবাদ বা অন্য কোনও ক্রমানুসারে টোকেনের সাথে। কিন্তু স্ব -মনোযোগ কেবল ইনপুট ক্রমানুসারে টোকেনের মধ্যে সম্পর্কের গুরুত্বকে মূল্যায়ন করে।
বিষয়গুলো সহজ করার জন্য, ধরে নিই যে প্রতিটি টোকেন একটি শব্দ এবং সম্পূর্ণ প্রসঙ্গটি কেবল একটি বাক্য। নিম্নলিখিত বাক্যটি বিবেচনা করুন:
The animal didn't cross the street because it was too tired.
পূর্ববর্তী বাক্যটিতে এগারোটি শব্দ রয়েছে। এগারোটি শব্দের প্রত্যেকটি অন্য দশটির দিকে মনোযোগ দিচ্ছে, ভাবছে যে এই দশটি শব্দের প্রতিটির নিজস্ব গুরুত্ব কত। উদাহরণস্বরূপ, লক্ষ্য করুন যে বাক্যটিতে সর্বনাম " it" রয়েছে। সর্বনামগুলি প্রায়শই অস্পষ্ট হয়। সর্বনাম " it" সাধারণত একটি সাম্প্রতিক বিশেষ্য বা বিশেষ্য বাক্যাংশকে বোঝায়, কিন্তু উদাহরণ বাক্যে, কোন সাম্প্রতিক বিশেষ্যটি বোঝায় - প্রাণী নাকি রাস্তা?
স্ব-মনোযোগ প্রক্রিয়াটি সর্বনাম it এর সাথে প্রতিটি কাছাকাছি শব্দের প্রাসঙ্গিকতা নির্ধারণ করে। চিত্র 3 ফলাফল দেখায় - লাইনটি যত নীল হবে, শব্দটি সর্বনাম it এর কাছে তত বেশি গুরুত্বপূর্ণ। অর্থাৎ, সর্বনাম it এর কাছে রাস্তার চেয়ে প্রাণী বেশি গুরুত্বপূর্ণ।

বিপরীতভাবে, ধরুন বাক্যের শেষ শব্দটি নিম্নরূপ পরিবর্তিত হয়েছে:
The animal didn't cross the street because it was too wide.
এই সংশোধিত বাক্যে, আত্ম-মনোযোগ আশা করি সর্বনামের সাথে "it" শব্দটির তুলনায় "animal " শব্দটির তুলনায় "street" শব্দটিকে বেশি প্রাসঙ্গিক হিসেবে মূল্যায়ন করবে।
কিছু স্ব-মনোযোগ প্রক্রিয়া দ্বিমুখী , যার অর্থ হল তারা যে শব্দের সাথে মনোযোগ দেওয়া হচ্ছে তার পূর্ববর্তী এবং পরবর্তী টোকেনের জন্য প্রাসঙ্গিকতার স্কোর গণনা করে। উদাহরণস্বরূপ, চিত্র 3-এ লক্ষ্য করুন যে এর উভয় পাশের শব্দগুলি পরীক্ষা করা হয়েছে। সুতরাং, একটি দ্বিমুখী স্ব-মনোযোগ প্রক্রিয়া শব্দের উভয় পাশের শব্দ থেকে প্রসঙ্গ সংগ্রহ করতে পারে। বিপরীতে, একটি একমুখী স্ব-মনোযোগ প্রক্রিয়া কেবল সেই শব্দের একপাশের শব্দ থেকে প্রসঙ্গ সংগ্রহ করতে পারে যা মনোযোগ দেওয়া হচ্ছে। দ্বিমুখী স্ব-মনোযোগ সম্পূর্ণ ক্রমগুলির উপস্থাপনা তৈরি করার জন্য বিশেষভাবে কার্যকর, যেখানে টোকেন-বাই-টোকেন ক্রম তৈরি করে এমন অ্যাপ্লিকেশনগুলির জন্য একমুখী স্ব-মনোযোগ প্রয়োজন। এই কারণে, এনকোডারগুলি দ্বিমুখী স্ব-মনোযোগ ব্যবহার করে, যখন ডিকোডারগুলি একমুখী ব্যবহার করে।
মাল্টি-হেড মাল্টি-লেয়ার সেলফ-অ্যাটেন্স কী?
প্রতিটি স্ব-মনোযোগ স্তর সাধারণত একাধিক স্ব-মনোযোগ মাথা নিয়ে গঠিত। একটি স্তরের আউটপুট হল বিভিন্ন মাথার আউটপুটের একটি গাণিতিক ক্রিয়াকলাপ (উদাহরণস্বরূপ, ওজনযুক্ত গড় বা বিন্দু গুণফল)।
যেহেতু প্রতিটি শিরোনামের প্যারামিটারগুলি এলোমেলো মানের সাথে শুরু করা হয়, তাই বিভিন্ন শিরোনাম প্রতিটি শব্দের সাথে সম্পর্কিত এবং কাছাকাছি শব্দের মধ্যে বিভিন্ন সম্পর্ক শিখতে পারে। উদাহরণস্বরূপ, পূর্ববর্তী বিভাগে বর্ণিত স্ব-মনোযোগী শিরোনামটি কোন বিশেষ্য সর্বনামটিকে নির্দেশ করেছে তা নির্ধারণের উপর দৃষ্টি নিবদ্ধ করে। তবে, একই স্তরের অন্যান্য স্ব-মনোযোগী শিরোনামগুলি প্রতিটি শব্দের সাথে অন্য প্রতিটি শব্দের ব্যাকরণগত প্রাসঙ্গিকতা শিখতে পারে, অথবা অন্যান্য মিথস্ক্রিয়া শিখতে পারে।
একটি সম্পূর্ণ ট্রান্সফরমার মডেল একাধিক স্ব-মনোযোগ স্তরকে একটির উপরে আরেকটি স্তরে স্তূপীকৃত করে। পূর্ববর্তী স্তর থেকে প্রাপ্ত আউটপুট পরবর্তী স্তরের জন্য ইনপুট হয়ে ওঠে। এই স্ট্যাকিং মডেলটিকে পাঠ্যের ক্রমশ জটিল এবং বিমূর্ত বোধগম্যতা তৈরি করতে সাহায্য করে। যদিও পূর্ববর্তী স্তরগুলি মৌলিক বাক্য গঠনের উপর ফোকাস করতে পারে, গভীর স্তরগুলি সেই তথ্যকে একত্রিত করতে পারে যাতে সমগ্র ইনপুট জুড়ে অনুভূতি, প্রসঙ্গ এবং বিষয়ভিত্তিক লিঙ্কগুলির মতো আরও সূক্ষ্ম ধারণাগুলি উপলব্ধি করা যায়।
ট্রান্সফরমারগুলো এত বড় কেন?
ট্রান্সফরমারগুলিতে শত শত বিলিয়ন বা এমনকি ট্রিলিয়ন প্যারামিটার থাকে। এই কোর্সে সাধারণত বেশি সংখ্যক প্যারামিটারের তুলনায় কম সংখ্যক প্যারামিটারের মডেল তৈরির সুপারিশ করা হয়েছে। সর্বোপরি, কম সংখ্যক প্যারামিটারের মডেল বেশি সংখ্যক প্যারামিটারের মডেলের তুলনায় ভবিষ্যদ্বাণী করতে কম সম্পদ ব্যবহার করে। যাইহোক, গবেষণায় দেখা গেছে যে বেশি প্যারামিটারের ট্রান্সফরমারগুলি ধারাবাহিকভাবে কম প্যারামিটারের ট্রান্সফরমারগুলিকে ছাড়িয়ে যায়।
কিন্তু একজন LLM কিভাবে টেক্সট তৈরি করে ?
আপনি দেখেছেন কিভাবে গবেষকরা LLM-দের একটি বা দুটি অনুপস্থিত শব্দের ভবিষ্যদ্বাণী করার প্রশিক্ষণ দেন, এবং আপনি হয়তো মুগ্ধ হবেন না। সর্বোপরি, একটি বা দুটি শব্দের ভবিষ্যদ্বাণী করা মূলত বিভিন্ন টেক্সট, ইমেল এবং লেখার সফ্টওয়্যারে তৈরি একটি স্বয়ংক্রিয়-সম্পূর্ণ বৈশিষ্ট্য। আপনি হয়তো ভাবছেন যে LLM কীভাবে সালিসি সম্পর্কে বাক্য, অনুচ্ছেদ বা হাইকু তৈরি করতে পারে।
আসলে, LLM মূলত স্বয়ংক্রিয়ভাবে সম্পন্ন হওয়া প্রক্রিয়া যা স্বয়ংক্রিয়ভাবে হাজার হাজার টোকেনের পূর্বাভাস (সম্পূর্ণ) দিতে পারে। উদাহরণস্বরূপ, একটি বাক্যের পরে একটি মুখোশযুক্ত বাক্য বিবেচনা করুন:
My dog, Max, knows how to perform many traditional dog tricks. ___ (masked sentence)
একটি LLM মুখোশযুক্ত বাক্যের জন্য সম্ভাব্যতা তৈরি করতে পারে, যার মধ্যে রয়েছে:
| সম্ভাবনা | শব্দ(গুলি) |
|---|---|
| ৩.১% | উদাহরণস্বরূপ, সে বসতে পারে, থাকতে পারে এবং গড়িয়ে পড়তে পারে। |
| ২.৯% | উদাহরণস্বরূপ, সে জানে কিভাবে বসতে হয়, থাকতে হয় এবং গড়িয়ে পড়তে হয়। |
একটি যথেষ্ট বড় LLM অনুচ্ছেদ এবং সম্পূর্ণ প্রবন্ধের জন্য সম্ভাব্যতা তৈরি করতে পারে। আপনি একজন LLM-এর কাছে ব্যবহারকারীর প্রশ্নগুলিকে "প্রদত্ত" বাক্য হিসাবে ভাবতে পারেন যার পরে একটি কাল্পনিক মুখোশ থাকে। উদাহরণস্বরূপ:
User's question: What is the easiest trick to teach a dog? LLM's response: ___
LLM বিভিন্ন সম্ভাব্য প্রতিক্রিয়ার জন্য সম্ভাব্যতা তৈরি করে।
আরেকটি উদাহরণ হিসেবে বলা যায়, বিপুল সংখ্যক গাণিতিক "শব্দ সমস্যা" সম্পর্কে প্রশিক্ষিত একজন এলএলএম-এর শিক্ষার্থীকে পরিশীলিত গাণিতিক যুক্তি করার মতো চেহারা দেওয়া যেতে পারে। তবে, সেই এলএলএম-গুলি মূলত কেবল একটি শব্দ সমস্যা প্রম্পট স্বয়ংক্রিয়ভাবে সম্পন্ন করে।
এলএলএম এর সুবিধা
এলএলএমরা বিভিন্ন ধরণের লক্ষ্য দর্শকদের জন্য স্পষ্ট, সহজে বোধগম্য লেখা তৈরি করতে পারে। এলএলএমরা তাদের স্পষ্টভাবে প্রশিক্ষিত কাজের উপর ভবিষ্যদ্বাণী করতে পারে। কিছু গবেষক দাবি করেন যে এলএলএমরা এমন ইনপুটগুলির জন্যও ভবিষ্যদ্বাণী করতে পারে যার উপর তারা স্পষ্টভাবে প্রশিক্ষিত ছিল না , তবে অন্যান্য গবেষকরা এই দাবি অস্বীকার করেছেন।
এলএলএম সংক্রান্ত সমস্যা
এলএলএম প্রশিক্ষণের ক্ষেত্রে অনেক সমস্যা দেখা দেয়, যার মধ্যে রয়েছে:
- বিশাল প্রশিক্ষণের সেট সংগ্রহ করা হচ্ছে।
- কয়েক মাস ধরে খরচ, প্রচুর গণনামূলক সম্পদ এবং বিদ্যুৎ।
- সমান্তরালতার চ্যালেঞ্জ সমাধান করা।
ভবিষ্যদ্বাণী অনুমান করার জন্য LLM ব্যবহার করলে নিম্নলিখিত সমস্যাগুলি দেখা দেয়:
- এলএলএমরা হ্যালুসিনেট করে , অর্থাৎ তাদের ভবিষ্যদ্বাণীতে প্রায়শই ভুল থাকে।
- LLM গুলি প্রচুর পরিমাণে গণনামূলক সম্পদ এবং বিদ্যুৎ খরচ করে। বৃহত্তর ডেটাসেটে LLM গুলিকে প্রশিক্ষণ দেওয়ার ফলে সাধারণত অনুমানের জন্য প্রয়োজনীয় সম্পদের পরিমাণ হ্রাস পায়, যদিও বৃহত্তর প্রশিক্ষণ সেটগুলিতে আরও প্রশিক্ষণ সম্পদ ব্যয় হয়।
- সমস্ত এমএল মডেলের মতো, এলএলএমগুলিও সকল ধরণের পক্ষপাত প্রদর্শন করতে পারে।