التخصيص المفرط يعني إنشاء نموذج يتطابق (يحفظ) مع مجموعة التدريب بشكلٍ قريب جدًا لدرجة أنّ النموذج لا يستطيع تقديم تنبؤات صحيحة بشأن البيانات الجديدة. يشبه النموذج المُعدَّل بشكل مفرط اختراعًا يحقّق أداءً جيدًا في المختبر ولكنه لا يُجدي نفعًا في العالم الواقعي.
في الشكل 11، تخيل أنّ كل شكل هندسي يمثّل موضع شجرة في غابة مربّعة. تشير الماسّات الزرقاء إلى مواقع الأشجار السليمة، بينما تشير الدوائر البرتقالية إلى مواقع الأشجار المريضة.

ارسم في ذهنك أي أشكال، مثل الخطوط والمنحنيات والأشكال البيضاوية...أي شيء، لفصل الأشجار السليمة عن الأشجار المريضة. بعد ذلك، وسِّع السطر التالي لفحص فاصلة محتملة.
وسِّع الصورة للاطّلاع على أحد الحلول المحتملة (الشكل 12).

نجحت الأشكال المعقّدة الموضّحة في الشكل 12 في تصنيف كل الأشجار باستثناء شجرتين. إذا اعتبرنا الأشكال نموذجًا، هذا نموذج رائع.
لكن، من يدري؟ نموذج ممتاز حقًا يصنف بنجاح الأمثلة الجديدة. يوضّح الرسم 13 ما يحدث عندما يقدّم النموذج نفسه توقّعات بشأن مثالين جديدين من مجموعة الاختبار:

وبالتالي، كان النموذج المعقّد المعروض في الشكل 12 فعّالاً بشكل كبير في مجموعة التدريب، ولكنه كان سيئًا جدًا في مجموعة الاختبار. هذه حالة نموذجية لحالة الملاءمة الزائدة لبيانات مجموعة التدريب.
التخصيص وفرط التخصيص وفرط التعميم
يجب أن يقدّم النموذج تنبؤات جيدة عن البيانات الجديدة. وهذا يعني أنّك تستهدف إنشاء نموذج "يناسب" البيانات الجديدة.
كما رأيت، يقدّم النموذج الذي تمّ تدريبه بشكل مفرط توقّعات ممتازة في مجموعة data training، ولكنّه يقدّم توقّعات سيئة في البيانات الجديدة. إنّ النموذج الذي يتسم بالتخصيص غير الكافي لا يقدّم حتى توقّعات جيدة لبيانات التدريب. إذا كان النموذج الذي تمّ تدريبه بشكلٍ مفرط يشبه منتجًا يحقّق أداءً جيدًا في المختبر ولكنّه يحقّق أداءً ضعيفًا في العالم الحقيقي، فإنّ النموذج الذي تمّ تدريبه بشكلٍ غير كافٍ يشبه منتجًا لا يحقّق أداءً جيدًا حتى في المختبر.

التعميم هو عكس فرط التكيّف. وهذا يعني أنّ النموذج الذي يُجري تعميمات بشكل جيد يقدّم تنبؤات جيدة بالبيانات الجديدة. هدفك هو إنشاء نموذج يُطبَّق بشكلٍ جيد على البيانات الجديدة.
رصد فرط التخصيص
تساعدك المنحنيات التالية في رصد حالات التكيّف المفرط:
- منحنيات الخسارة
- منحنيات التعميم
يوضِّح منحنى الخسارة خسارة النموذج مقارنةً بعدد تكرارات التدريب. يُعرف الرسم البياني الذي يعرض منحنيات خسارة أو أكثر باسم منحنى التعميم. يعرض منحنى التجميع التالي منحنى فقدانَين:
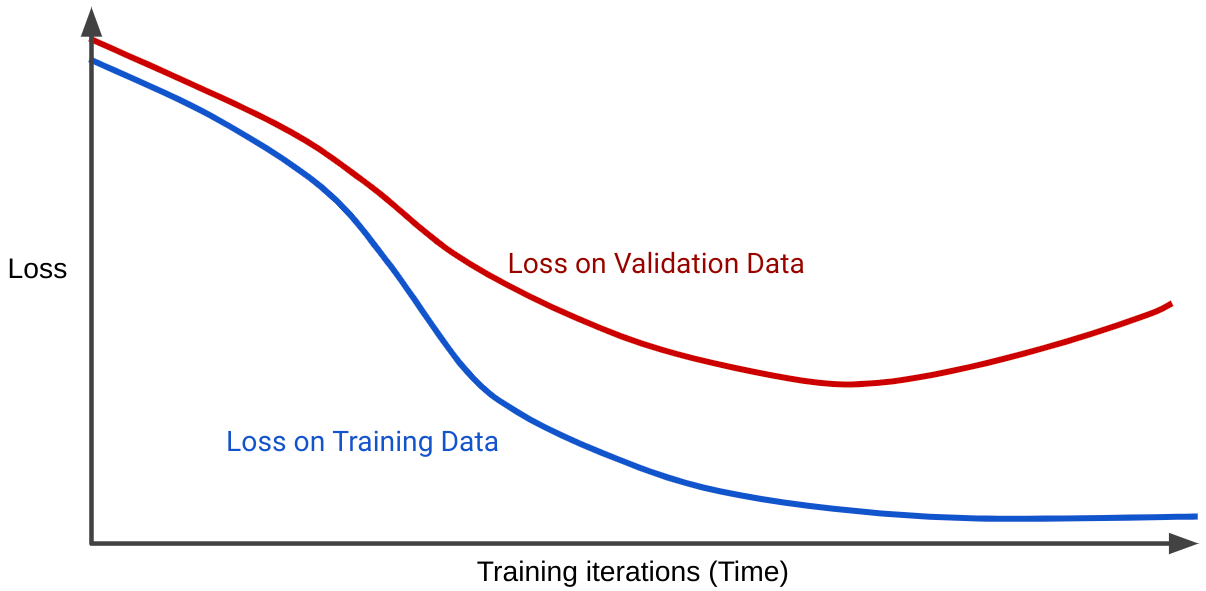
يُرجى ملاحظة أنّ منحنيات الخسارة تتصرف بشكلٍ مشابه في البداية ثمّ تتباعد. وهذا يعني أنّه بعد عدد معيّن من التكرارات، ينخفض الخسارة أو يبقى ثابتًا (يتقارب) لمجموعة التدريب، ولكن يزداد للمجموعة التحقّق. يشير ذلك إلى فرط التكيّف.
في المقابل، يعرض منحنى التعميم لنموذج ملائم منحنيات خسارة لها أشكال مشابهة.
ما هي أسباب فرط التوافق؟
بشكل عام، تحدث مشكلة التكيّف المفرط لأحد السببَين التاليَين أو كليهما:
- لا تمثّل مجموعة التدريب البيانات الواقعية بشكلٍ كافٍ (أو مجموعة التحقّق أو مجموعة الاختبار).
- النموذج معقّد للغاية.
شروط التعميم
يتم تدريب النموذج على مجموعة تدريب، ولكن الاختبار الحقيقي لقيمة النموذج هو مدى نجاحه في إجراء توقّعات بشأن أمثلة جديدة، لا سيما البيانات الواقعية. أثناء تطوير نموذج، تُستخدَم مجموعة الاختبار كبديل لبيانات العالم الواقعي. يشير تدريب نموذج يُعمِّم بشكلٍ جيد إلى شروط مجموعة البيانات التالية:
- يجب أن تكون الأمثلة موزَّعة بشكل مستقل ومتطابق، وهي طريقة أنيقة للقول بأنّه لا يمكن للأمثلة التأثير في بعضها.
- تكون مجموعة البيانات ثابتة، ما يعني أنّ مجموعة البيانات لا تتغيّر بشكل ملحوظ بمرور الوقت.
- تتضمّن أقسام مجموعة البيانات التوزيع نفسه. وهذا يعني أنّ الأمثلة في مجموعة التدريب مشابهة إحصائيًا لتلك المتوفّرة في مجموعة التحقّق ومجموعة الاختبار والبيانات الواقعية.
استكشِف الشروط السابقة من خلال التمارين التالية.
تمارين: التحقّق من فهمك

تمرين التحدّي
أنت بصدد إنشاء نموذج يتوقّع التاريخ المثالي للركاب لشراء تذكرة قطار لمسار معيّن. على سبيل المثال، قد يقترح النموذج على المستخدمين شراء تذكرتهم في 8 تموز (يوليو) لركوب قطار يغادر في 23 تموز (يوليو). تعدّل شركة القطارات الأسعار كل ساعة استنادًا إلى مجموعة متنوعة من العوامل، ولكن بشكل أساسي استنادًا إلى العدد الحالي للمقاعد المتاحة. والمقصود:
- إذا كانت هناك مقاعد كثيرة متاحة، تكون أسعار التذاكر عادةً منخفضة.
- إذا كانت المقاعد المتوفّرة قليلة جدًا، تكون أسعار التذاكر عادةً مرتفعة.
الإجابة: يواجه نموذج العالم الواقعي مشكلة في حلقة الملاحظات.
على سبيل المثال، لنفترض أنّ النموذج يقترح على المستخدمين شراء التذاكر في 8 تموز (يوليو). يشتري بعض الركاب الذين يستعينون باقتراحات النموذج تذاكرهم في الساعة 8:30 صباحًا في 8 تموز (يوليو). في الساعة 9:00، ترفع شركة القطارات الأسعار لأنّه لم يعُد هناك مقاعد متاحة. يحصل الركاب الذين يستخدِمون اقتراح النموذج على أسعار متغيّرة. وفي المساء، قد تكون أسعار التذاكر أعلى بكثير مما هي عليه في الصباح.