งานที่ได้จากการเรียนรู้แบบควบคุมดูแลจะกําหนดไว้อย่างชัดเจนและนําไปใช้กับสถานการณ์ต่างๆ ได้ เช่น การระบุจดหมายขยะหรือการคาดการณ์ปริมาณน้ำฝน
แนวคิดพื้นฐานเกี่ยวกับการเรียนรู้ที่มีการควบคุมดูแล
แมชชีนเลิร์นนิงที่มีการควบคุมดูแลจะอิงตามแนวคิดหลักต่อไปนี้
- ข้อมูล
- รุ่น
- การฝึกอบรม
- กำลังประเมินผล
- การอนุมาน
ข้อมูล
ข้อมูลคือแรงขับเคลื่อนของ ML ข้อมูลอยู่ในรูปแบบของคำและตัวเลขที่จัดเก็บไว้ในตาราง หรือเป็นค่าของพิกเซลและรูปแบบคลื่นที่บันทึกไว้ในรูปภาพและไฟล์เสียง เราจัดเก็บข้อมูลที่เกี่ยวข้องไว้ในชุดข้อมูล ตัวอย่างเช่น เราอาจมีชุดข้อมูลต่อไปนี้
- ภาพของแมว
- ราคาที่อยู่อาศัย
- ข้อมูลสภาพอากาศ
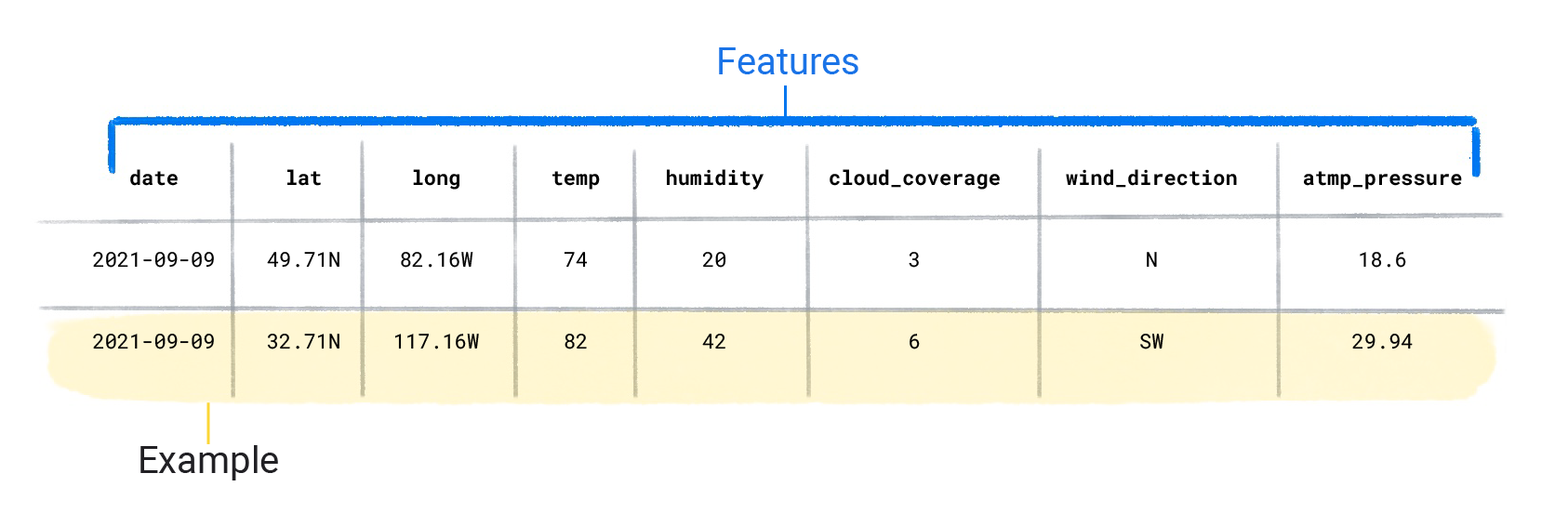
ชุดข้อมูลประกอบด้วยตัวอย่างแต่ละรายการซึ่งมีฟีเจอร์และป้ายกํากับ คุณอาจคิดว่าตัวอย่างนี้คล้ายกับแถวเดียวในสเปรดชีต ฟีเจอร์คือค่าที่โมเดลที่มีการควบคุมดูแลใช้เพื่อคาดการณ์ป้ายกํากับ ป้ายกํากับคือ "คําตอบ" หรือค่าที่เราต้องการให้โมเดลคาดการณ์ ในโมเดลสภาพอากาศที่คาดการณ์ปริมาณน้ำฝน ฟีเจอร์อาจเป็นละติจูด ลองจิจูด อุณหภูมิ ความชื้น ความครอบคลุมของเมฆ ทิศทางลม และความดันบรรยากาศ ป้ายกำกับจะเป็น ปริมาณน้ำฝน
ตัวอย่างที่มีทั้งฟีเจอร์และป้ายกำกับเรียกว่าตัวอย่างที่มีป้ายกำกับ
ตัวอย่างที่มีป้ายกำกับ 2 รายการ

ในทางตรงกันข้าม ตัวอย่างที่ไม่มีป้ายกำกับจะมีฟีเจอร์แต่ไม่มีป้ายกำกับ หลังจากสร้างโมเดลแล้ว โมเดลจะคาดการณ์ป้ายกำกับจากฟีเจอร์
ตัวอย่างที่ไม่มีป้ายกำกับ 2 รายการ
ลักษณะชุดข้อมูล
ชุดข้อมูลมีลักษณะเฉพาะตามขนาดและความหลากหลาย ขนาดจะระบุจํานวนตัวอย่าง ความหลากหลายบ่งบอกถึงช่วงของตัวอย่างเหล่านั้น ชุดข้อมูลที่ดีจะต้องมีทั้งขนาดใหญ่และมีความหลากหลายสูง
ชุดข้อมูลอาจมีขนาดใหญ่และหลากหลาย หรือขนาดใหญ่แต่ไม่หลากหลาย หรือมีขนาดเล็กแต่มีความหลากหลายสูง กล่าวคือ ชุดข้อมูลขนาดใหญ่ไม่ได้รับประกันความหลากหลายที่เพียงพอ และชุดข้อมูลที่มีความหลากหลายสูงไม่ได้รับประกันตัวอย่างที่เพียงพอ
ตัวอย่างเช่น ชุดข้อมูลหนึ่งอาจมีข้อมูล 100 ปี แต่มีเฉพาะข้อมูลเดือนกรกฎาคม การใช้ชุดข้อมูลนี้เพื่อคาดการณ์ปริมาณน้ำฝนในเดือนมกราคมจะให้การคาดการณ์ที่ไม่ดี ในทางกลับกัน ชุดข้อมูลอาจครอบคลุมเพียง 2-3 ปี แต่มีข้อมูลทุกเดือน ชุดข้อมูลนี้อาจทําให้การคาดการณ์ไม่ดีเนื่องจากมีปีไม่เพียงพอที่จะอธิบายความแปรปรวน
ทดสอบความเข้าใจ
ชุดข้อมูลยังมีลักษณะตามจํานวนองค์ประกอบได้ด้วย ตัวอย่างเช่น ชุดข้อมูลสภาพอากาศบางชุดอาจมีองค์ประกอบหลายร้อยรายการ ตั้งแต่ภาพถ่ายจากดาวเทียมไปจนถึงค่าความครอบคลุมของเมฆ ชุดข้อมูลอื่นๆ อาจมีเพียง 3 หรือ 4 องค์ประกอบ เช่น ความชื้น ความดันบรรยากาศ และอุณหภูมิ ชุดข้อมูลที่มีฟีเจอร์มากขึ้นจะช่วยให้โมเดลค้นพบรูปแบบเพิ่มเติมและทําการคาดการณ์ได้ดียิ่งขึ้น อย่างไรก็ตาม ชุดข้อมูลที่มีฟีเจอร์มากขึ้นไม่ได้เสมอไปที่จะสร้างโมเดลที่คาดการณ์ได้ดีขึ้น เนื่องจากฟีเจอร์บางรายการอาจไม่มีความสัมพันธ์เชิงสาเหตุกับป้ายกํากับ
รุ่น
ในการเรียนรู้แบบควบคุม โมเดลคือชุดตัวเลขที่ซับซ้อนซึ่งกําหนดความสัมพันธ์ทางคณิตศาสตร์จากรูปแบบฟีเจอร์อินพุตที่เฉพาะเจาะจงไปยังค่าป้ายกำกับเอาต์พุตที่เฉพาะเจาะจง โมเดลจะค้นพบรูปแบบเหล่านี้ผ่านการฝึก
การฝึกอบรม
โมเดลที่มีการควบคุมดูแลต้องได้รับการฝึกก่อนจึงจะทําการคาดการณ์ได้ ในการฝึกโมเดล เราจะให้ชุดข้อมูลที่มีตัวอย่างที่ติดป้ายกำกับแก่โมเดล เป้าหมายของโมเดลคือการหาวิธีที่ดีที่สุดในการคาดคะเนป้ายกำกับจากฟีเจอร์ โมเดลจะค้นหาวิธีแก้ปัญหาที่ดีที่สุดโดยการเปรียบเทียบค่าที่คาดการณ์กับค่าจริงของป้ายกํากับ โดยอิงตามความแตกต่างระหว่างค่าที่คาดการณ์และค่าจริง ซึ่งเรียกว่าการสูญเสีย โมเดลจะค่อยๆ อัปเดตโซลูชัน กล่าวคือ โมเดลจะเรียนรู้ความสัมพันธ์ทางคณิตศาสตร์ระหว่างฟีเจอร์กับป้ายกำกับเพื่อให้คาดการณ์ข้อมูลใหม่ได้ดีที่สุด
ตัวอย่างเช่น หากโมเดลคาดการณ์ว่าจะมีฝนตก 1.15 inches แต่ค่าจริงคือ .75 inches โมเดลจะแก้ไขคำตอบเพื่อให้การคาดการณ์ใกล้เคียงกับ .75 inches มากขึ้น หลังจากโมเดลได้ดูตัวอย่างแต่ละรายการในชุดข้อมูลแล้ว (ในบางกรณีอาจดูหลายครั้ง) โมเดลจะหาวิธีแก้ปัญหาที่คาดการณ์ได้ดีที่สุดโดยเฉลี่ยสำหรับแต่ละตัวอย่าง
ตัวอย่างต่อไปนี้แสดงการฝึกโมเดล
โมเดลจะรับตัวอย่างที่มีป้ายกำกับรายการเดียวและให้คําคาดการณ์
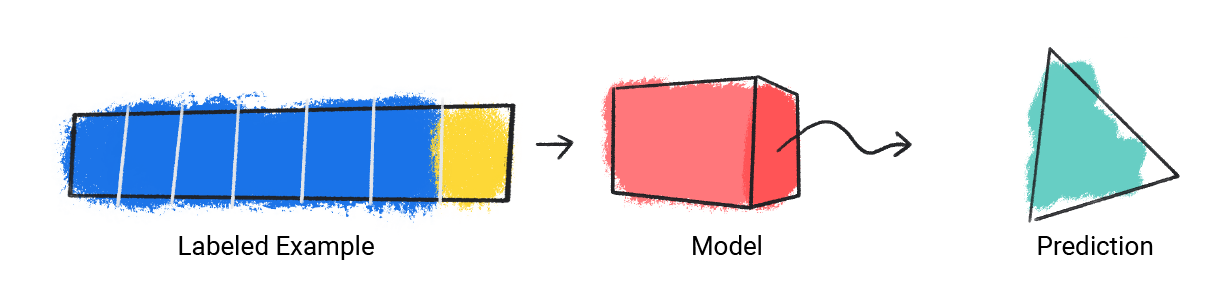
รูปที่ 1 โมเดล ML ที่ทำนายจากตัวอย่างที่ติดป้ายกำกับ
โมเดลจะเปรียบเทียบค่าที่คาดการณ์กับค่าจริงและอัปเดตโซลูชัน
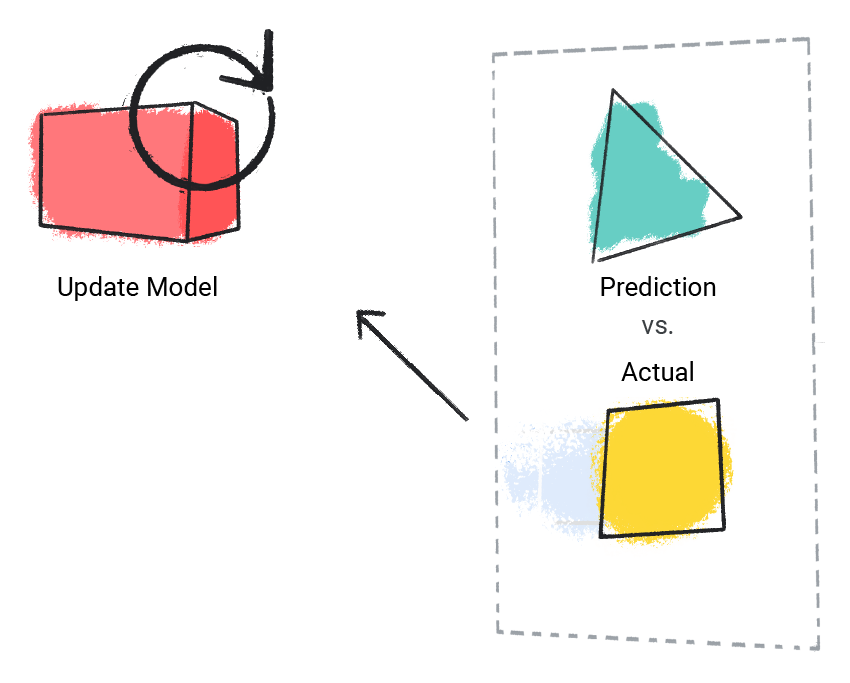
รูปที่ 2 โมเดล ML ที่อัปเดตค่าที่คาดการณ์
โมเดลจะทําขั้นตอนนี้ซ้ำสําหรับตัวอย่างที่ติดป้ายกํากับแต่ละรายการในชุดข้อมูล
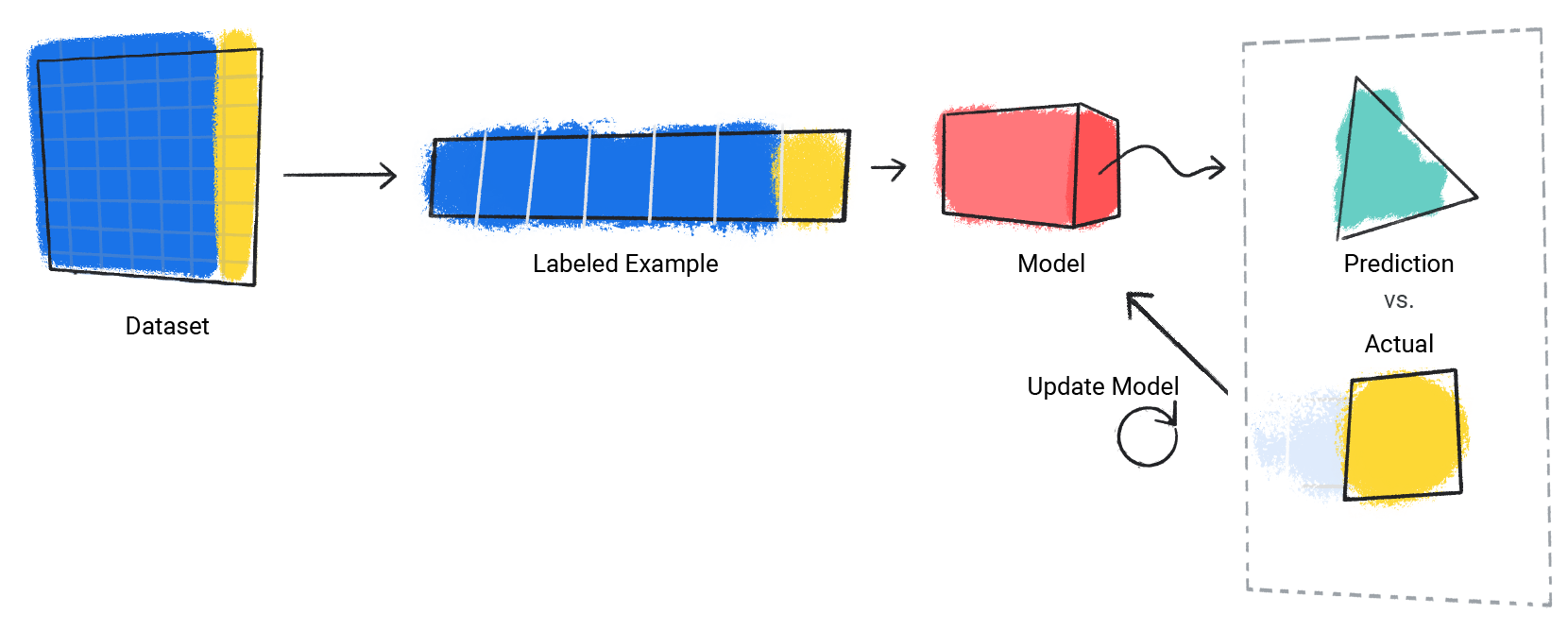
รูปที่ 3 โมเดล ML ที่อัปเดตการคาดการณ์สำหรับตัวอย่างที่ติดป้ายกำกับแต่ละรายการในชุดข้อมูลการฝึก
วิธีนี้จะช่วยให้โมเดลค่อยๆ เรียนรู้ความสัมพันธ์ที่ถูกต้องระหว่างฟีเจอร์กับป้ายกำกับ ความเข้าใจที่ค่อยเป็นค่อยไปนี้ยังเป็นเหตุผลที่ชุดข้อมูลขนาดใหญ่และหลากหลายสร้างโมเดลที่ดีขึ้นด้วย โมเดลได้เห็นข้อมูลมากขึ้นซึ่งมีค่าที่หลากหลายมากขึ้น และปรับความเข้าใจเกี่ยวกับความสัมพันธ์ระหว่างฟีเจอร์กับป้ายกํากับ
ในระหว่างการฝึก ผู้ปฏิบัติงาน ML สามารถปรับเปลี่ยนการกําหนดค่าและฟีเจอร์ที่โมเดลใช้ทําการคาดการณ์ได้ เช่น ฟีเจอร์บางอย่างมีความแม่นยำในการคาดการณ์มากกว่าฟีเจอร์อื่นๆ ดังนั้น ผู้ปฏิบัติงานด้าน ML จึงสามารถเลือกฟีเจอร์ที่โมเดลจะใช้ในระหว่างการฝึกได้ ตัวอย่างเช่น สมมติว่าชุดข้อมูลสภาพอากาศมีtime_of_dayเป็นฟีเจอร์ ในกรณีนี้ ผู้ปฏิบัติงาน ML สามารถเพิ่มหรือนํา time_of_day ออกในระหว่างการฝึกเพื่อดูว่าโมเดลคาดการณ์ได้ดีขึ้นหรือไม่เมื่อมีหรือไม่มี time_of_day
กำลังประเมินผล
เราประเมินโมเดลที่ผ่านการฝึกเพื่อดูว่าโมเดลเรียนรู้ได้ดีเพียงใด เมื่อประเมินโมเดล เราจะใช้ชุดข้อมูลที่มีป้ายกำกับ แต่จะให้เฉพาะฟีเจอร์ของชุดข้อมูลแก่โมเดล จากนั้นเราจะเปรียบเทียบการคาดการณ์ของโมเดลกับค่าจริงของป้ายกำกับ
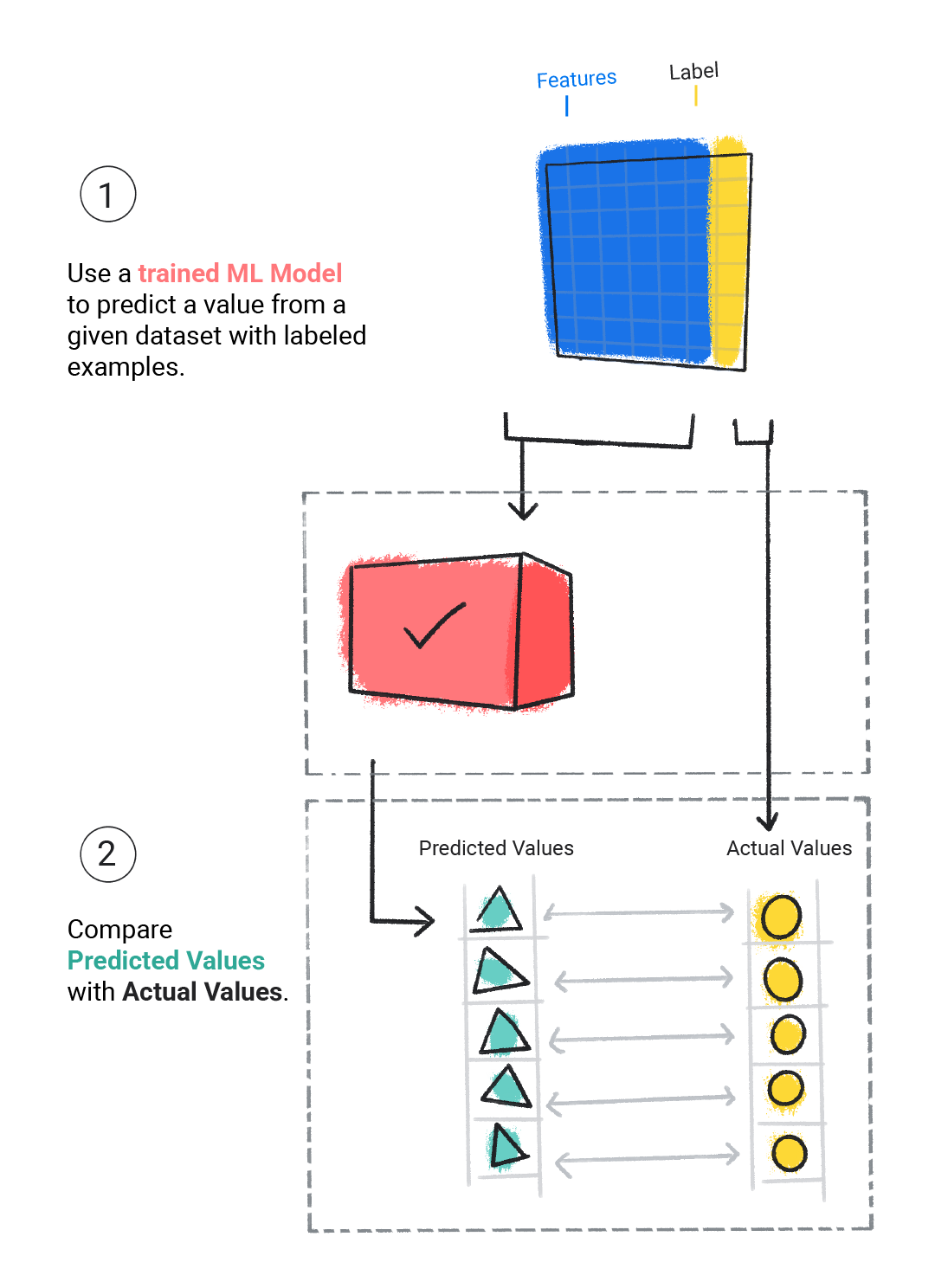
รูปที่ 4 การประเมินโมเดล ML โดยเปรียบเทียบการคาดการณ์กับค่าจริง
เราอาจต้องฝึกและประเมินเพิ่มเติมก่อนนำโมเดลไปใช้งานจริง ทั้งนี้ขึ้นอยู่กับการคาดการณ์ของโมเดล
ทดสอบความเข้าใจ
การอนุมาน
เมื่อพอใจกับผลลัพธ์จากการประเมินโมเดลแล้ว เราจะใช้โมเดลเพื่อทำนายสิ่งที่เรียกว่าการอนุมานในตัวอย่างที่ไม่มีป้ายกำกับ ในตัวอย่างแอปสภาพอากาศ เราจะให้ข้อมูลสภาพอากาศปัจจุบัน เช่น อุณหภูมิ ความดันบรรยากาศ และความชื้นสัมพัทธ์แก่โมเดล แล้วโมเดลจะคาดการณ์ปริมาณฝน