Поскольку кластеризация не контролируется, «истина» недоступна для проверки результатов. Отсутствие правды усложняет оценку качества. Кроме того, реальные наборы данных обычно не попадают в очевидные кластеры примеров, подобных набору данных, показанному на рисунке 1.
К сожалению, реальные данные больше похожи на рисунок 2, что затрудняет визуальную оценку качества кластеризации.
На приведенной ниже блок-схеме показано, как проверить качество кластеризации. Мы расширим сводку в следующих разделах.

Шаг первый: качество кластеризации
Проверка качества кластеризации не является строгим процессом, потому что кластеризации не хватает «правды». Вот рекомендации, которые вы можете последовательно применять для улучшения качества вашей кластеризации.
Во-первых, выполните визуальную проверку того, что кластеры выглядят так, как ожидалось, и что примеры, которые вы считаете похожими, действительно появляются в одном и том же кластере. Затем проверьте эти часто используемые показатели, как описано в следующих разделах:
- Мощность кластера
- Величина кластера
- Производительность нижестоящей системы
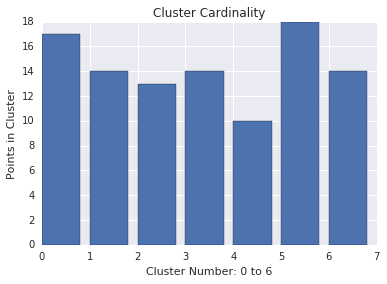
Мощность кластера
Мощность кластера — это количество примеров в кластере. Постройте мощность кластера для всех кластеров и исследуйте кластеры, которые являются основными выбросами. Например, на рисунке 2 исследуйте кластер номер 5.
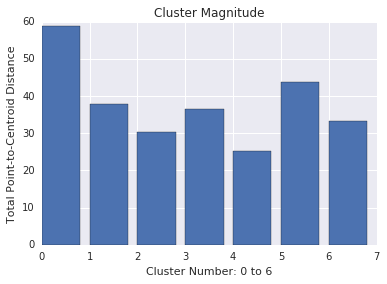
Величина кластера
Величина кластера представляет собой сумму расстояний от всех примеров до центроида кластера. Как и в случае с кардинальностью, проверьте, как меняется величина в кластерах, и исследуйте аномалии. Например, на рисунке 3 исследуйте кластер номер 0.
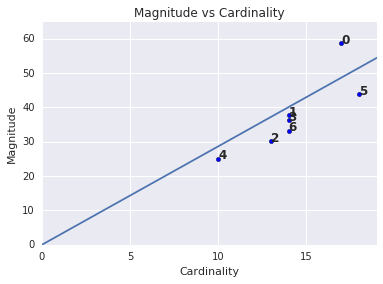
Величина против кардинальности
Обратите внимание, что более высокая мощность кластера имеет тенденцию приводить к более высокой величине кластера, что интуитивно понятно. Кластеры являются аномальными, когда мощность не коррелирует с величиной относительно других кластеров. Найдите аномальные кластеры, построив зависимость величины от мощности. Например, на рис. 4 подгонка линии к показателям кластера показывает, что кластер номер 0 является аномальным.
Производительность нисходящей системы
Поскольку выходные данные кластеризации часто используются в нижестоящих системах машинного обучения, проверьте, улучшается ли производительность нижестоящих систем при изменении процесса кластеризации. Влияние на производительность нижестоящего потока представляет собой реальную проверку качества вашей кластеризации. Недостатком является сложность выполнения этой проверки.
Вопросы для изучения в случае обнаружения проблем
Если вы обнаружите проблемы, проверьте подготовку данных и меру подобия, задав себе следующие вопросы:
- Ваши данные масштабируются?
- Верна ли ваша мера сходства?
- Выполняет ли ваш алгоритм семантически значимые операции с данными?
- Соответствуют ли предположения вашего алгоритма данным?
Шаг второй: выполнение меры подобия
Ваш алгоритм кластеризации настолько хорош, насколько хороша ваша мера сходства. Убедитесь, что ваша мера подобия дает разумные результаты. Простейшая проверка состоит в том, чтобы идентифицировать пары примеров, которые, как известно, более или менее похожи, чем другие пары. Затем вычислите меру сходства для каждой пары примеров. Убедитесь, что мера сходства для более похожих примеров выше, чем мера сходства для менее похожих примеров.
Примеры, которые вы используете для выборочной проверки меры подобия, должны быть репрезентативными для набора данных. Убедитесь, что ваша мера сходства верна для всех ваших примеров. Тщательная проверка гарантирует, что ваша мера сходства, будь то ручная или контролируемая, непротиворечива в вашем наборе данных. Если ваша мера сходства несовместима для некоторых примеров, эти примеры не будут объединены в кластеры с похожими примерами.
Если вы обнаружите примеры с неточным сходством, то ваша мера сходства, вероятно, не отражает данные о функциях, которые отличают эти примеры. Поэкспериментируйте с мерой сходства и определите, получаете ли вы более точное сходство.
Шаг третий: оптимальное количество кластеров
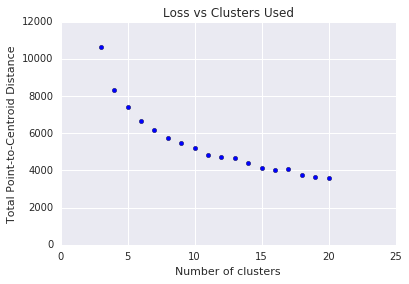
k-means требует, чтобы вы заранее определили количество кластеров \(k\) . Как определить оптимальное значение \(k\)? Попробуйте запустить алгоритм увеличения \(k\) и обратите внимание на сумму величин кластера. По мере увеличения \(k\)кластеры становятся меньше, а общее расстояние уменьшается. Постройте это расстояние против числа кластеров.
Как показано на рисунке 4, при определенном \(k\)снижение потерь становится незначительным при увеличении \(k\). Математически это примерно \(k\), где наклон превышает -1 (\(\theta > 135^{\circ}\)). Это руководство не определяет точное значение оптимального \(k\) , а дает лишь приблизительное значение. Для показанного графика оптимальное значение \(k\) равно примерно 11. Если вы предпочитаете более детализированные кластеры, вы можете выбрать более высокое значение \(k\) используя этот график в качестве ориентира.