Karena pengelompokan tidak diawasi, tidak ada “kebenaran” yang tersedia untuk memverifikasi hasil. Ketiadaan kebenaran mempersulit penilaian kualitas. Selanjutnya, set data dunia nyata biasanya tidak termasuk dalam kumpulan contoh yang jelas seperti set data yang ditampilkan dalam Gambar 1.
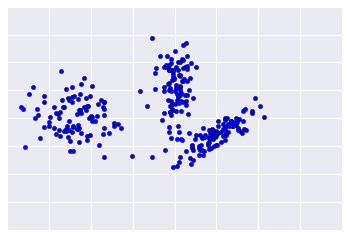
Sayangnya, data dunia nyata lebih mirip dengan Gambar 2, sehingga sulit untuk menilai kualitas pengelompokan secara visual.
Diagram alir di bawah merangkum cara memeriksa kualitas pengelompokan Anda. Kami akan memperluas ringkasan di bagian berikut.

Langkah Satu: Kualitas Pengelompokan
Memeriksa kualitas pengelompokan bukanlah proses yang ketat karena pengelompokan tersebut tidak memiliki "kebenaran". Berikut adalah pedoman yang dapat Anda terapkan secara berulang untuk meningkatkan kualitas pengelompokan Anda.
Pertama, lakukan pemeriksaan visual agar cluster terlihat seperti yang diharapkan, dan contoh yang Anda anggap serupa muncul di cluster yang sama. Kemudian, periksa metrik yang biasa digunakan ini seperti yang dijelaskan di bagian berikut:
- Kardinalitas cluster
- Magnitudo cluster
- Performa sistem downstream
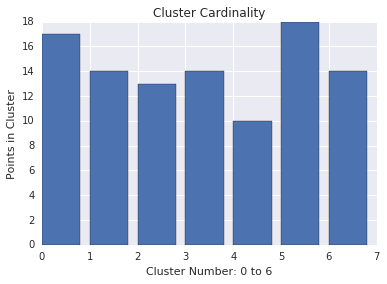
Kardinalitas cluster
Kardinalitas cluster adalah jumlah contoh per cluster. Rencanakan kardinalitas cluster untuk semua cluster dan selidiki cluster yang merupakan pencilan utama. Misalnya, pada Gambar 2, selidiki cluster nomor 5.
Magnitudo cluster
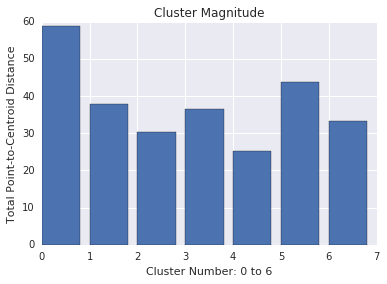
Magnitudo cluster adalah jumlah jarak dari semua contoh ke sentroid cluster. Serupa dengan kardinalitas, periksa bagaimana besarnya bervariasi di seluruh cluster, dan selidiki anomali. Misalnya, pada Gambar 3, selidiki cluster nomor 0.
Magnitudo vs. Kardinalitas
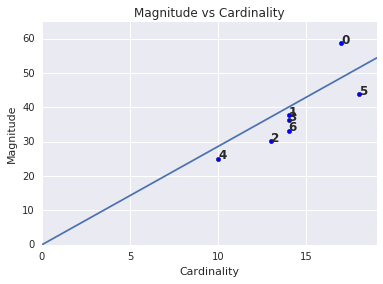
Perhatikan bahwa kardinalitas cluster yang lebih tinggi cenderung menghasilkan magnitudo cluster yang lebih tinggi, yang secara intuitif masuk akal. Cluster akan dianggap sebagai anomali jika kardinalitas tidak berkorelasi dengan besarnya relatif terhadap cluster lainnya. Temukan cluster yang tidak wajar dengan memetakan magnitudo terhadap kardinalitas. Misalnya, dalam Gambar 4, pencocokan garis ke metrik cluster akan menunjukkan bahwa nomor cluster 0 tidak wajar.
Performa Sistem Downstream
Karena output pengelompokan sering digunakan dalam sistem ML downstream, periksa apakah performa sistem downstream meningkat saat proses pengelompokan Anda berubah. Dampak pada performa downstream Anda menyediakan pengujian sungguhan untuk kualitas clustering Anda. Kekurangannya adalah pemeriksaan ini rumit untuk dilakukan.
Pertanyaan untuk Menyelidiki Jika Masalah Ditemukan
Jika Anda menemukan masalah, periksa persiapan data dan langkah kemiripan Anda, dengan mengajukan pertanyaan berikut kepada diri sendiri:
- Apakah data Anda diskalakan?
- Apakah kesamaan Anda dalam hal ini sudah benar?
- Apakah algoritme Anda melakukan operasi yang bermakna secara semantik pada data?
- Apakah asumsi algoritme Anda cocok dengan data?
Langkah Dua: Performa Pengukuran Kesamaan
Algoritme pengelompokan Anda akan sama baiknya dengan ukuran kesamaan Anda. Pastikan ukuran kesamaan Anda menampilkan hasil yang masuk akal. Pemeriksaan paling sederhana adalah mengidentifikasi pasangan contoh yang diketahui kurang lebih mirip dengan pasangan lain. Kemudian, hitung ukuran kesamaan untuk setiap pasangan contoh. Pastikan ukuran kesamaan untuk contoh yang lebih mirip lebih tinggi daripada ukuran kesamaan untuk contoh yang kurang mirip.
Contoh yang Anda gunakan untuk melihat kecocokan ukuran Anda harus mewakili set data. Pastikan kesamaan ukuran Anda berlaku untuk semua contoh. Verifikasi yang cermat memastikan bahwa ukuran kesamaan Anda, baik secara manual maupun yang diawasi, konsisten di seluruh set data. Jika ukuran kemiripan Anda tidak konsisten untuk beberapa contoh, contoh tersebut tidak akan dikelompokkan dengan contoh yang serupa.
Jika Anda menemukan contoh dengan kesamaan yang tidak akurat, pengukuran kemiripan Anda mungkin tidak menangkap data fitur yang membedakan contoh tersebut. Lakukan eksperimen dengan pengukuran kesamaan dan tentukan apakah Anda mendapatkan tingkat kemiripan yang lebih akurat.
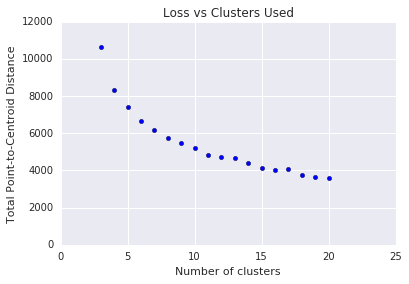
Langkah Tiga: Jumlah Cluster yang Optimal
k-berarti mengharuskan Anda untuk memutuskan jumlah kelompok \(k\) terlebih dahulu. Bagaimana Anda menentukan nilai optimal \(k\)? Coba jalankan algoritme untuk meningkatkan \(k\) dan perhatikan jumlah magnitudo cluster. Seiring meningkatnya \(k\), cluster akan menjadi lebih kecil dan jarak totalnya menurun. Gambarkan jarak ini terhadap jumlah cluster.
Seperti yang ditunjukkan pada Gambar 4, pada \(k\)tertentu, pengurangan kerugian akan menjadi marginal dengan meningkatnya \(k\). Secara matematis, itu kira-kira \(k\) dengan kemiringan yang melintasi di atas -1 (\(\theta > 135^{\circ}\)). Pedoman ini tidak menentukan nilai pasti untuk yang optimal \(k\) tetapi hanya nilai perkiraan. Untuk plot yang ditampilkan, jumlah optimal \(k\) adalah sekitar 11. Jika Anda lebih memilih cluster yang lebih terperinci, Anda dapat memilih \(k\) yang lebih tinggi menggunakan plot ini sebagai panduan.