No tutorial anterior (Introdução), vimos como os embeddings de satélite capturam trajetórias anuais de observações de satélite e variáveis climáticas. Isso torna o conjunto de dados facilmente utilizável para mapear plantações sem precisar modelar a fenologia delas. O mapeamento de tipos de cultura é uma tarefa complexa que normalmente exige a modelagem da fenologia da cultura e a coleta de amostras de campo de todas as culturas cultivadas na região.
Neste tutorial, vamos usar uma abordagem de classificação não supervisionada para o mapeamento de plantações, o que nos permite realizar essa tarefa complexa sem depender de rótulos de campo. Esse método usa o conhecimento local da região e estatísticas agregadas de plantações, que estão disponíveis para muitas partes do mundo.
Selecione uma região
Neste tutorial, vamos criar um mapa de tipo de plantação para o condado de Cerro Gordo, Iowa. Esse condado fica no cinturão do milho dos Estados Unidos, que tem duas culturas principais: milho e soja. Esse conhecimento local é importante e nos ajuda a decidir sobre os parâmetros principais do nosso modelo.
Vamos começar obtendo o limite do município escolhido.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

Figura: região selecionada
Preparar o conjunto de dados de embedding de satélite
Em seguida, carregamos o conjunto de dados de incorporação de satélite, filtramos as imagens do ano escolhido e criamos um mosaico.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
Criar uma máscara de área cultivada
Para nossa modelagem, precisamos excluir áreas que não são de cultivo. Há muitos conjuntos de dados globais e regionais que podem ser usados para criar uma máscara de corte. ESA WorldCover ou GFSAD Global Cropland Extent Product são boas opções para conjuntos de dados globais de terras agrícolas. Uma adição mais recente é o produto ESA WorldCereal Active Cropland, que tem mapeamento sazonal de terras agrícolas ativas. Como nossa região fica nos EUA, podemos usar um conjunto de dados regional mais preciso, as Camadas de dados de área cultivada da NASS do USDA (CDL, na sigla em inglês), para obter uma máscara de cultura.
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
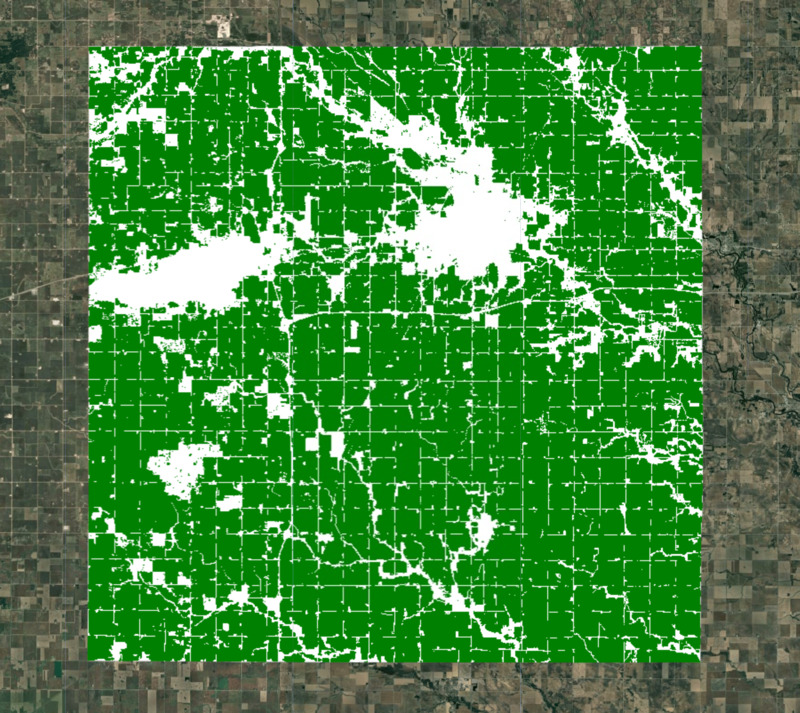
Figura: região selecionada com máscara de lavoura
Extrair exemplos de treinamento
Aplicamos a máscara de área cultivada ao mosaico de incorporação. Agora temos todos os pixels que representam as terras agrícolas cultivadas no município.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
Precisamos pegar a imagem de incorporação de satélite e extrair amostras aleatórias para treinar um modelo de clusterização. Como nossa região de interesse contém muitos pixels mascarados, uma amostragem aleatória simples pode resultar em amostras com valores nulos. Para garantir que podemos extrair o número desejado de amostras não nulas, usamos a amostragem estratificada para obter o número desejado de amostras em áreas não mascaradas.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
Exportar amostra para um recurso (opcional)
A extração de amostras é uma operação computacionalmente cara. Por isso, é uma prática recomendada exportar as amostras de treinamento extraídas como recursos e usá-los nas etapas subsequentes. Isso ajuda a superar os erros tempo limite de computação excedido ou memória do usuário excedida ao trabalhar com regiões grandes.
Inicie a tarefa de exportação e aguarde a conclusão antes de continuar.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
Depois que a tarefa de exportação for concluída, poderemos ler as amostras extraídas de volta no nosso código como uma coleção de recursos.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
Visualizar as amostras
Se você executou a amostra de forma interativa ou exportou para uma coleção de recursos, agora terá uma variável de treinamento com os pontos de amostra. Vamos imprimir a primeira amostra para inspecionar e adicionar nossos pontos de treinamento ao Map.
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

Figura: amostras aleatórias extraídas para clustering
Realizar clustering não supervisionado
Agora podemos treinar um clusterizador e agrupar os vetores de embedding 64D em um número escolhido de clusters distintos. Com base no nosso conhecimento local, há dois tipos principais de plantações que representam a maioria da área, e várias outras plantações cobrem a fração restante. Podemos realizar o agrupamento não supervisionado no encadeamento do Satellite para obter clusters de pixels com trajetórias e padrões temporais semelhantes. Pixels com características espectrais e espaciais semelhantes, além de fenologia parecida, serão agrupados no mesmo cluster.
O ee.Clusterer.wekaCascadeKMeans() permite especificar um número mínimo e máximo de clusters e encontrar o número ideal com base nos dados de treinamento. Nesse caso, o conhecimento local é útil para decidir o número mínimo e máximo de clusters. Como esperamos alguns tipos distintos de clusters (milho, soja e várias outras culturas), podemos usar 4 como o número mínimo de clusters e 5 como o número máximo. Talvez seja necessário testar esses números para descobrir o que funciona melhor na sua região.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');

Figura: clusters obtidos da classificação não supervisionada
Atribuir rótulos a clusters
Após a inspeção visual, os clusters obtidos nas etapas anteriores correspondem de perto aos limites da fazenda vistos na imagem de alta resolução. Sabemos, por conhecimento local, que os dois maiores grupos seriam milho e soja. Vamos calcular as áreas de cada cluster na nossa imagem.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
Escolhemos os dois clusters com a maior área.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
Mas ainda não sabemos qual cluster é qual cultura. Se você tivesse algumas amostras de campo de milho ou soja, poderia sobrepor os clusters para descobrir os respectivos rótulos. Na ausência de amostras de campo, podemos usar estatísticas agregadas de colheitas. Em muitas partes do mundo, as estatísticas agregadas de colheitas são coletadas e publicadas regularmente. Nos EUA, o Serviço Nacional de Estatísticas Agrícolas (NASS, na sigla em inglês) tem estatísticas detalhadas de cada condado e das principais plantações. Em 2022, o Condado de Cerro Gordo, Iowa, tinha uma área plantada de milho de 653.500 m² e uma área plantada de soja de 447.200 m².
Com essas informações, sabemos que, entre os dois principais clusters, o que tem a maior área provavelmente é de milho e o outro de soja. Vamos atribuir esses rótulos e comparar as áreas calculadas com as estatísticas publicadas.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
Criar um mapa de corte
Agora sabemos os rótulos de cada cluster e podemos extrair os pixels de cada tipo de cultura e mesclá-los para criar o mapa final.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
Para ajudar a interpretar os resultados, também podemos usar elementos da interface para criar e adicionar uma legenda ao mapa.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));

Figura: mapa de corte detectado com plantações de milho e soja
validar os resultados
Conseguimos obter um mapa de tipo de cultura com o conjunto de dados de incorporação de satélite sem rótulos de campo usando apenas as estatísticas agregadas e o conhecimento local da região. Vamos comparar nossos resultados com o mapa oficial de tipo de cultura das camadas de dados de área cultivada (CDL, na sigla em inglês) do NASS (Serviço Nacional de Estatísticas Agrícolas) do USDA (Departamento de Agricultura dos EUA).
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

Figura: (esquerda) mapa de corte de incorporações de satélite (direita) mapa de corte de CDL
Embora haja discrepâncias entre nossos resultados e o mapa oficial, você vai notar que conseguimos obter resultados muito bons com o mínimo de esforço. Ao aplicar etapas de pós-processamento aos resultados, podemos remover alguns ruídos e preencher lacunas na saída.
Teste o script completo deste tutorial no editor de código do Earth Engine.