O AlphaEarth Foundations do Google é um modelo de incorporação geoespacial treinado em vários conjuntos de dados de observação da Terra (EO, na sigla em inglês). O modelo foi executado em séries temporais anuais de imagens, e os embeddings resultantes estão disponíveis como um conjunto de dados pronto para análise no Earth Engine. Com esse conjunto de dados, os usuários podem criar qualquer número de aplicativos de ajuste refinado ou outras tarefas sem executar modelos de aprendizado profundo computacionalmente caros. O resultado é um conjunto de dados de uso geral que pode ser usado para várias tarefas downstream diferentes, como
- Classificação
- Regressão
- Detecção de mudanças
- Pesquisa por similaridade
Neste tutorial, vamos entender como os embeddings funcionam e aprender a acessar e visualizar o conjunto de dados de embeddings de satélite.
Noções básicas sobre embeddings
Os embeddings são uma forma de compactar grandes quantidades de informações em um conjunto menor de recursos que representam semânticas significativas. O modelo AlphaEarth Foundations usa séries temporais de imagens de sensores, incluindo Sentinel-2, Sentinel-1 e Landsat, e aprende a representar de maneira exclusiva as informações mútuas entre fontes e destinos com apenas 64 números. Saiba mais no artigo aqui. O fluxo de dados de entrada contém milhares de bandas de imagens de vários sensores, e o modelo transforma essa entrada de alta dimensão em uma representação de baixa dimensão.
Um bom modelo mental para entender como o AlphaEarth Foundations funciona é uma técnica chamada análise de componentes principais (PCA, na sigla em inglês). A PCA também ajuda a reduzir a dimensionalidade dos dados para aplicativos de aprendizado de máquina. Embora a PCA seja uma técnica estatística e possa compactar dezenas de bandas de entrada em alguns componentes principais, o AlphaEarth Foundations é um modelo de aprendizado profundo que pode usar milhares de dimensões de entrada de conjuntos de dados de séries temporais multissensor e aprender a criar uma representação de 64 bandas que captura de maneira exclusiva a variabilidade espacial e temporal desse pixel.
Um campo de embedding é a matriz contínua ou "campo" de embeddings aprendidos. As imagens nas coleções de campos de embedding representam trajetórias espaço-tempo que abrangem um ano inteiro e têm 64 bandas (uma para cada dimensão de embedding).
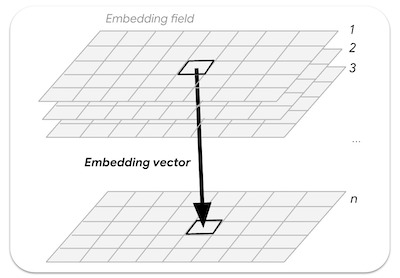
Figura: vetor de embedding n-dimensional extraído de um campo de embedding
Acessar o conjunto de dados de embedding de satélite
O conjunto de dados de incorporação de satélite é uma coleção de imagens com imagens anuais de 2017 em diante (por exemplo, 2017, 2018, 2019…). Cada imagem tem 64 bandas em que cada pixel é o vetor de incorporação que representa a série temporal multissensorial para o ano em questão.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
Selecione uma região
Vamos começar definindo uma região de interesse. Para este tutorial, vamos escolher uma região ao redor do reservatório de Krishna Raja Sagara (KRS) na Índia e definir um polígono como a variável de geometria. Se preferir, use as ferramentas de desenho no editor de código para desenhar um polígono ao redor da região de interesse, que será salva como a variável geometry nas importações.
// Use the satellite basemap
Map.setOptions('SATELLITE');
var geometry = ee.Geometry.Polygon([[
[76.3978, 12.5521],
[76.3978, 12.3550],
[76.6519, 12.3550],
[76.6519, 12.5521]
]]);
Map.centerObject(geometry, 12);

Figura: seleção da região de interesse
Preparar o conjunto de dados de embedding de satélite
As imagens de cada ano são divididas em blocos para facilitar o acesso. Aplicamos filtros e encontramos as imagens do ano e da região escolhidos.
var year = 2024;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredEmbeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
As imagens de incorporação de satélite são divididas em blocos de até 163.840 m x 163.840 m cada e veiculadas na projeção das zonas UTM do bloco. Como resultado, recebemos vários blocos de incorporação de satélite que cobrem a região de interesse. Podemos usar a função mosaic() para combinar vários blocos em uma única imagem. Vamos imprimir a imagem resultante para ver as bandas.
var embeddingsImage = filteredEmbeddings.mosaic();
print('Satellite Embedding Image', embeddingsImage);
A imagem tem 64 bandas, chamadas A00, A01, … , A63. Cada faixa contém o valor do vetor de incorporação para o ano especificado nessa dimensão ou eixo. Ao contrário das bandas ou índices espectrais, as bandas individuais não têm significado independente. Cada banda representa um eixo do espaço de incorporação. Você usaria todas as 64 bandas como entradas para seus aplicativos downstream.

Figura: 64 bandas da imagem de incorporação do satélite
Visualizar o conjunto de dados de embedding de satélite
Como acabamos de ver, nossa imagem contém 64 bandas. Não há uma maneira fácil de visualizar todas as informações contidas em todas as bandas, já que só é possível ver uma combinação de três bandas por vez.
Podemos escolher três bandas para visualizar três eixos do espaço de incorporação como uma imagem RGB.
var visParams = {min: -0.3, max: 0.3, bands: ['A01', 'A16', 'A09']};
Map.addLayer(embeddingsImage.clip(geometry), visParams, 'Embeddings Image');

Figura: visualização RGB de três eixos do espaço de embedding
Uma maneira alternativa de visualizar essas informações é usá-las para agrupar pixels com embeddings semelhantes e usar esses agrupamentos para entender como o modelo aprendeu a variabilidade espacial e temporal de uma paisagem.
Podemos usar técnicas de clusterização não supervisionada para agrupar os pixels em um espaço de 64 dimensões em grupos ou "clusters" de valores semelhantes. Para isso, primeiro fazemos uma amostragem de alguns valores de pixel e treinamos um ee.Clusterer.
var nSamples = 1000;
var training = embeddingsImage.sample({
region: geometry,
scale: 10,
numPixels: nSamples,
seed: 100
});
print(training.first());
Se você imprimir os valores da primeira amostra, vai notar que ela tem 64 valores de banda que definem o vetor de embedding desse pixel. O vetor de embedding foi projetado para ter um comprimento unitário. Ou seja, o comprimento do vetor da origem (0,0,....0) até os valores do vetor será 1.

Figura: vetor de embedding extraído
Agora podemos treinar um modelo não supervisionado para agrupar as amostras no número desejado de clusters. Cada cluster representaria pixels de incorporações semelhantes.
// Function to train a model for desired number of clusters
var getClusters = function(nClusters) {
var clusterer = ee.Clusterer.wekaKMeans({nClusters: nClusters})
.train(training);
// Cluster the image
var clustered = embeddingsImage.cluster(clusterer);
return clustered;
};
Agora podemos agrupar a imagem de embedding maior para ver grupos de pixels com embeddings semelhantes. Antes disso, é importante entender que o modelo capturou a trajetória temporal completa de cada pixel durante o ano. Isso significa que, se dois pixels tiverem valores espectrais semelhantes em todas as imagens, mas em momentos diferentes, eles poderão ser separados.
Abaixo, você confere uma visualização da nossa área de interesse capturada por imagens do Sentinel-2 com máscara de nuvem para o ano de 2024. Todas as imagens (junto com as do Sentinel-2, Landsat 8/9 e muitos outros sensores) foram usadas para aprender as incorporações finais.

Figura: série temporal anual do Sentinel-2 para nossa região
Vamos visualizar as imagens de incorporação de satélite segmentando a paisagem em três clusters.
var cluster3 = getClusters(3);
Map.addLayer(cluster3.randomVisualizer().clip(geometry), {}, '3 clusters');

Figura: imagem de embedding de satélite com três clusters
Você vai notar que os clusters resultantes têm limites muito claros. Isso acontece porque os embeddings incluem contexto espacial. Espera-se que pixels dentro do mesmo objeto tenham vetores de embedding relativamente semelhantes. Além disso, um dos clusters inclui áreas com água sazonal ao redor do reservatório principal. Isso ocorre devido ao contexto temporal capturado no vetor de incorporação, que permite detectar esses pixels com padrões temporais semelhantes.
Vamos ver se podemos refinar ainda mais os clusters agrupando os pixels em cinco clusters.
var cluster5 = getClusters(5);
Map.addLayer(cluster5.randomVisualizer().clip(geometry), {}, '5 clusters');

Figura: imagem de incorporação de satélite com cinco clusters
Podemos continuar e refinar as imagens em grupos mais especializados aumentando o número de clusters. Veja como a imagem fica com 10 clusters.
var cluster10 = getClusters(10);
Map.addLayer(cluster10.randomVisualizer().clip(geometry), {}, '10 clusters');

Figura: imagem de embedding de satélite com 10 clusters
Há muitos detalhes surgindo, e podemos ver diferentes tipos de plantações sendo agrupados em diferentes clusters. Como o embedding de satélite captura a fenologia da cultura e as variáveis climáticas, ele é adequado para o mapeamento de tipos de culturas. No próximo tutorial (classificação não supervisionada), vamos mostrar como criar um mapa de tipo de cultura com dados de incorporação de satélite com poucos ou nenhum rótulo no nível do campo.
Teste o script completo deste tutorial no editor de código do Earth Engine.