W poprzednim samouczku (Wprowadzenie) pokazaliśmy, jak osadzanie danych satelitarnych rejestruje roczne trajektorie obserwacji satelitarnych i zmiennych klimatycznych. Dzięki temu zbiór danych jest gotowy do użycia w mapowaniu upraw bez konieczności modelowania ich fenologii. Mapowanie typów upraw to trudne zadanie, które zwykle wymaga modelowania fenologii upraw i zbierania próbek polowych wszystkich upraw w regionie.
W tym samouczku zastosujemy podejście klasyfikacji bez nadzoru do mapowania upraw, które umożliwia wykonanie tego złożonego zadania bez polegania na etykietach pól. Ta metoda wykorzystuje lokalną wiedzę o regionie oraz zbiorcze statystyki dotyczące upraw, które są łatwo dostępne w wielu częściach świata.
Wybierz region
W tym samouczku utworzymy mapę typów upraw dla hrabstwa Cerro Gordo w stanie Iowa. Ten hrabstwo znajduje się w pasie kukurydzianym Stanów Zjednoczonych, gdzie uprawia się głównie kukurydzę i soję. Ta lokalna wiedza jest ważna i pomoże nam określić kluczowe parametry naszego modelu.
Zacznijmy od uzyskania granic wybranego hrabstwa.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

Ilustracja: wybrany region
Przygotowywanie zbioru danych osadzania satelitarnego
Następnie wczytujemy zbiór danych Satellite Embedding, filtrujemy obrazy z wybranego roku i tworzymy mozaikę.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
Tworzenie maski gruntów ornych
W naszym modelowaniu musimy wykluczyć obszary nieużytków rolnych. Do utworzenia maski upraw można użyć wielu globalnych i regionalnych zbiorów danych. ESA WorldCover lub GFSAD Global Cropland Extent Product to dobre wybory w przypadku globalnych zbiorów danych o gruntach uprawnych. Ostatnio dodanym produktem jest ESA WorldCereal Active Cropland, który zawiera sezonowe mapowanie aktywnych gruntów uprawnych. Ponieważ nasz region znajduje się w Stanach Zjednoczonych, możemy użyć dokładniejszego regionalnego zbioru danych USDA NASS Cropland Data Layers (CDL), aby uzyskać maskę upraw.
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
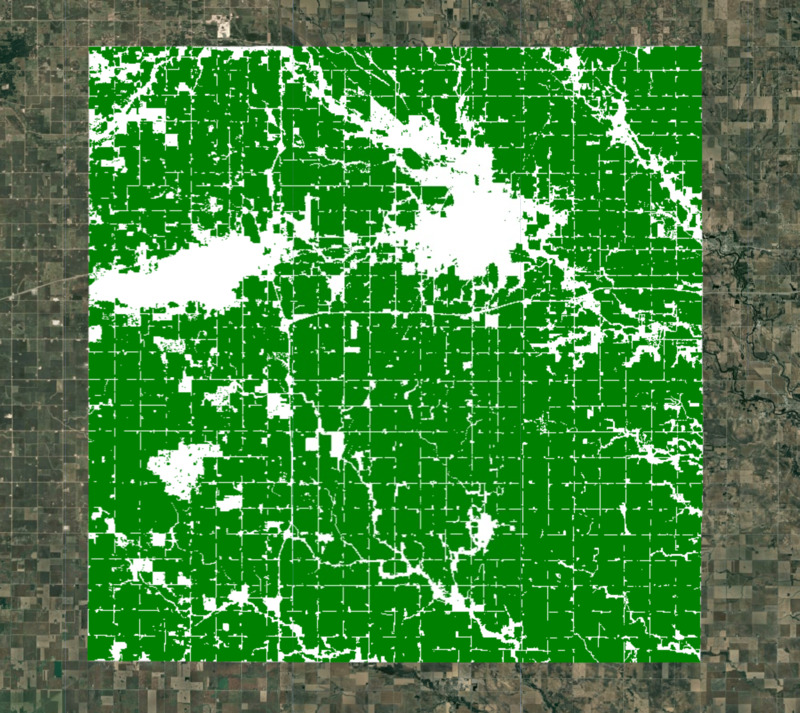
Ilustracja: wybrany region z maską gruntów ornych
Wyodrębnianie próbek treningowych
Do mozaiki osadzania stosujemy maskę pól uprawnych. Pozostały nam wszystkie piksele reprezentujące uprawne grunty rolne w tym powiecie.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
Musimy pobrać obraz wektora dystrybucyjnego z satelity i uzyskać losowe próbki, aby wytrenować model klastrowania. Ponieważ nasz obszar zainteresowania zawiera wiele zamaskowanych pikseli, proste losowe próbkowanie może skutkować próbkami o wartościach zerowych. Aby mieć pewność, że możemy wyodrębnić żądaną liczbę próbek niezerowych, stosujemy próbkowanie warstwowe, aby uzyskać żądaną liczbę próbek w niezamaskowanych obszarach.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
Eksportowanie próbki do komponentu (opcjonalnie)
Wyodrębnianie próbek jest operacją wymagającą dużej mocy obliczeniowej, dlatego warto wyeksportować wyodrębnione próbki trenujące jako komponenty i używać ich w kolejnych krokach. Pomoże to uniknąć błędu przekroczenia limitu czasu obliczeń lub błędu przekroczenia pamięci użytkownika podczas pracy z dużymi regionami.
Rozpocznij eksportowanie i poczekaj na jego zakończenie, zanim przejdziesz dalej.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
Po zakończeniu zadania eksportu możemy odczytać wyodrębnione próbki z powrotem do naszego kodu jako kolekcję obiektów.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
Wizualizacja próbek
Niezależnie od tego, czy próbkę uruchomiono interaktywnie, czy wyeksportowano do zbioru obiektów, będziesz mieć teraz zmienną treningową z punktami próbki. Wydrukujmy pierwszy próbny wydruk, aby go sprawdzić i dodać punkty szkoleniowe do Map.
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

Ilustracja: wyodrębnione losowe próbki do klastrowania
Przeprowadzanie nienadzorowanego grupowania
Możemy teraz wytrenować klasteryzator i pogrupować 64-wymiarowe wektory reprezentacji właściwościowych w wybraną liczbę odrębnych klastrów. Z naszej wiedzy wynika, że na tym obszarze występują 2 główne rodzaje upraw, które zajmują większość powierzchni, a pozostałą część stanowią inne uprawy. Możemy przeprowadzić bez nadzoru grupowanie osadzania satelitarnego, aby uzyskać klastry pikseli o podobnych trajektoriach i wzorcach czasowych. Piksele o podobnych charakterystykach spektralnych i przestrzennych oraz podobnej fenologii zostaną zgrupowane w tym samym klastrze.
Symbol ee.Clusterer.wekaCascadeKMeans() umożliwia określenie minimalnej i maksymalnej liczby klastrów oraz znalezienie optymalnej liczby klastrów na podstawie danych treningowych. W tym przypadku przydaje się nasza wiedza lokalna, która pomaga określić minimalną i maksymalną liczbę klastrów. Spodziewamy się kilku różnych typów klastrów – kukurydzy, soi i kilku innych upraw – dlatego możemy użyć 4 jako minimalnej liczby klastrów i 5 jako maksymalnej liczby klastrów. Aby dowiedzieć się, co najlepiej sprawdza się w Twoim regionie, musisz poeksperymentować z tymi liczbami.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
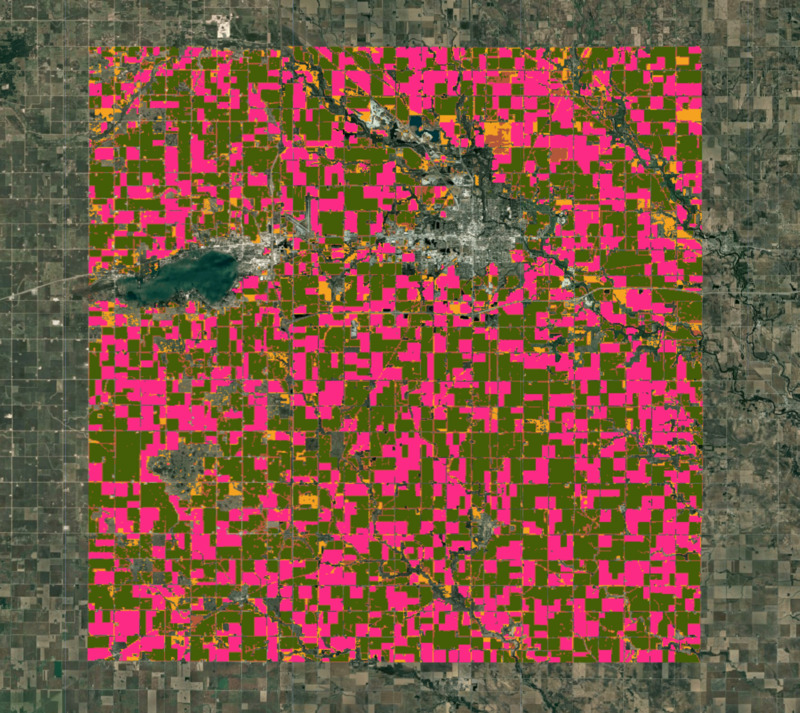
Rysunek: klastry uzyskane w wyniku klasyfikacji bez nadzoru
Przypisywanie etykiet do klastrów
Po wizualnej weryfikacji klastry uzyskane w poprzednich krokach są bardzo podobne do granic gospodarstwa widocznych na obrazie o wysokiej rozdzielczości. Z lokalnych informacji wiemy, że 2 największe skupiska to kukurydza i soja. Obliczmy obszary każdego klastra na obrazie.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
Wybieramy 2 klastry o największej powierzchni.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
Nie wiemy jednak, który klaster odpowiada którym uprawom. Jeśli masz kilka próbek pól kukurydzy lub soi, możesz nałożyć je na klastry, aby określić ich etykiety. W przypadku braku próbek z pola możemy wykorzystać zbiorcze statystyki dotyczące upraw. W wielu częściach świata regularnie gromadzi się i publikuje zbiorcze statystyki dotyczące upraw. W Stanach Zjednoczonych szczegółowe statystyki dotyczące upraw w poszczególnych hrabstwach i w przypadku najważniejszych upraw są dostępne w National Agricultural Statistics Service (NASS). W 2022 r. w hrabstwie Cerro Gordo w stanie Iowa powierzchnia upraw kukurydzy wynosiła 65 350 ha, a powierzchnia upraw soi – 44 710 ha.
Na podstawie tych informacji wiemy, że spośród 2 największych klastrów ten o największej powierzchni to najprawdopodobniej kukurydza, a drugi to soja. Przypiszmy te etykiety i porównajmy obliczone obszary z opublikowanymi statystykami.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
Tworzenie mapy upraw
Znamy już etykiety poszczególnych klastrów, więc możemy wyodrębnić piksele dla każdego rodzaju upraw i połączyć je, aby utworzyć ostateczną mapę upraw.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
Aby ułatwić interpretację wyników, możemy też użyć elementów interfejsu, aby utworzyć i dodać legendę do mapy.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
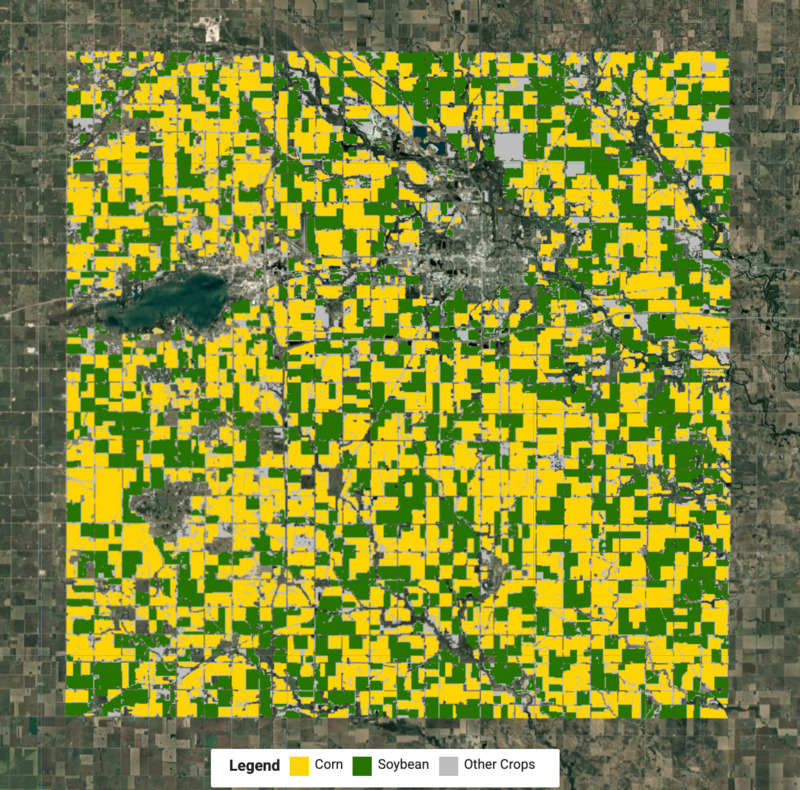
Ilustracja: wykryta mapa upraw z kukurydzą i soją
Weryfikowanie wyników
Korzystając ze zbioru danych Satellite Embedding, udało nam się uzyskać mapę typów upraw bez etykiet pól, używając tylko statystyk zbiorczych i lokalnej wiedzy o regionie. Porównajmy nasze wyniki z oficjalną mapą typów upraw z bazy danych USDA NASS Cropland Data Layers (CDL).
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

Ilustracja: (po lewej) wycinek mapy z osadzonych danych satelitarnych, (po prawej) wycinek mapy z danych CDL
Chociaż między naszymi wynikami a oficjalną mapą występują rozbieżności, zauważysz, że udało nam się uzyskać całkiem dobre wyniki przy minimalnym wysiłku. Stosując kroki przetwarzania końcowego, możemy usunąć część szumów i wypełnić luki w wynikach.
Wypróbuj pełny skrypt z tego samouczka w edytorze kodu Earth Engine