Dans le tutoriel précédent (Introduction), nous avons vu comment les embeddings satellite capturent les trajectoires annuelles des observations satellite et des variables climatiques. L'ensemble de données est ainsi facilement utilisable pour cartographier les cultures sans avoir besoin de modéliser leur phénologie. La cartographie des types de cultures est une tâche difficile qui nécessite généralement de modéliser la phénologie des cultures et de collecter des échantillons sur le terrain pour toutes les cultures cultivées dans la région.
Dans ce tutoriel, nous allons adopter une approche de classification non supervisée pour la cartographie des cultures, ce qui nous permettra d'effectuer cette tâche complexe sans nous appuyer sur des libellés de champs. Cette méthode s'appuie sur les connaissances locales de la région ainsi que sur les statistiques agrégées sur les cultures, qui sont facilement disponibles pour de nombreuses régions du monde.
Sélectionnez une région
Pour ce tutoriel, nous allons créer une carte des types de cultures pour le comté de Cerro Gordo, dans l'Iowa. Ce comté se trouve dans la ceinture de maïs des États-Unis, qui compte deux cultures principales : le maïs et le soja. Ces connaissances locales sont importantes et nous aideront à décider des paramètres clés de notre modèle.
Commençons par obtenir les limites du comté choisi.
// Select the region
// Cerro Gordo County, Iowa
var counties = ee.FeatureCollection('TIGER/2018/Counties');
var selected = counties
.filter(ee.Filter.eq('GEOID', '19033'));
var geometry = selected.geometry();
Map.centerObject(geometry, 12);
Map.addLayer(geometry, {color: 'red'}, 'Selected Region', false);

Figure : Région sélectionnée
Préparer l'ensemble de données d'embeddings satellite
Nous chargeons ensuite l'ensemble de données Satellite Embedding, filtrons les images pour l'année choisie et créons une mosaïque.
var embeddings = ee.ImageCollection('GOOGLE/SATELLITE_EMBEDDING/V1/ANNUAL');
var year = 2022;
var startDate = ee.Date.fromYMD(year, 1, 1);
var endDate = startDate.advance(1, 'year');
var filteredembeddings = embeddings
.filter(ee.Filter.date(startDate, endDate))
.filter(ee.Filter.bounds(geometry));
var embeddingsImage = filteredembeddings.mosaic();
Créer un masque de terres cultivées
Pour notre modélisation, nous devons exclure les zones non cultivables. De nombreux ensembles de données mondiaux et régionaux peuvent être utilisés pour créer un masque de recadrage. ESA WorldCover ou GFSAD Global Cropland Extent Product sont de bons choix pour les ensembles de données mondiaux sur les terres cultivées. Le produit ESA WorldCereal Active Cropland, qui cartographie les terres cultivées actives de manière saisonnière, a été ajouté plus récemment. Étant donné que notre région se trouve aux États-Unis, nous pouvons utiliser un ensemble de données régionales plus précis, USDA NASS Cropland Data Layers (CDL), pour obtenir un masque de culture.
// Use Cropland Data Layers (CDL) to obtain cultivated cropland
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var croplandMask = cdl.select('cultivated').eq(2).rename('cropmask');
// Visualize the crop mask
var croplandMaskVis = {min: 0, max: 1, palette: ['white', 'green']};
Map.addLayer(croplandMask.clip(geometry), croplandMaskVis, 'Crop Mask');
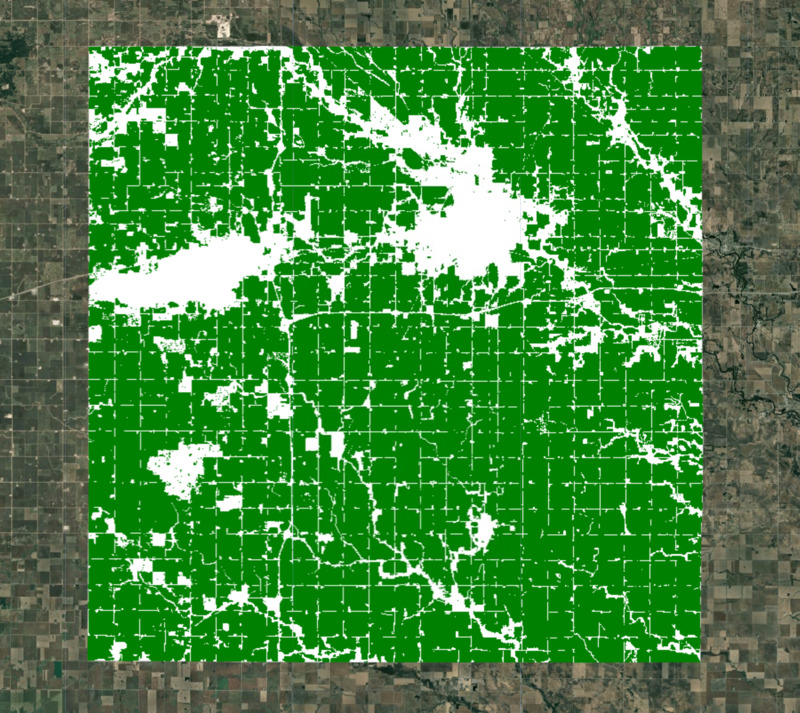
Figure : Région sélectionnée avec masque de terres cultivées
Extraire des exemples d'entraînement
Nous appliquons le masque de terres cultivées à la mosaïque d'intégration. Il ne nous reste plus que les pixels représentant les terres cultivées dans le comté.
// Mask all non-cropland pixels
var clusterImage = embeddingsImage.updateMask(croplandMask);
Nous devons prendre l'image d'embedding satellite et obtenir des échantillons aléatoires pour entraîner un modèle de clustering. Étant donné que notre région d'intérêt contient de nombreux pixels masqués, un simple échantillonnage aléatoire peut entraîner des échantillons avec des valeurs nulles. Pour nous assurer de pouvoir extraire le nombre souhaité d'échantillons non nuls, nous utilisons un échantillonnage stratifié afin d'obtenir le nombre souhaité d'échantillons dans les zones non masquées.
// Stratified random sampling
var training = clusterImage.addBands(croplandMask).stratifiedSample({
numPoints: 1000,
classBand: 'cropmask',
region: geometry,
scale: 10,
tileScale: 16,
seed: 100,
dropNulls: true,
geometries: true
});
Exporter un échantillon vers un élément (facultatif)
L'extraction d'échantillons est une opération coûteuse en termes de calcul. Il est conseillé d'exporter les échantillons d'entraînement extraits en tant qu'éléments et d'utiliser les éléments exportés lors des étapes suivantes. Cela vous aidera à surmonter les erreurs Délai de calcul dépassé ou Mémoire utilisateur dépassée lorsque vous travaillez avec de grandes régions.
Lancez la tâche d'exportation et attendez qu'elle soit terminée avant de continuer.
// Replace this with your asset folder
// The folder must exist before exporting
var exportFolder = 'projects/spatialthoughts/assets/satellite_embedding/';
var samplesExportFc = 'cluster_training_samples';
var samplesExportFcPath = exportFolder + samplesExportFc;
Export.table.toAsset({
collection: training,
description: 'Cluster_Training_Samples',
assetId: samplesExportFcPath
});
Une fois la tâche d'exportation terminée, nous pouvons relire les échantillons extraits dans notre code en tant que collection d'entités.
// Use the exported asset
var training = ee.FeatureCollection(samplesExportFcPath);
Visualiser les exemples
Que vous ayez exécuté votre échantillon de manière interactive ou que vous l'ayez exporté vers une collection d'entités, vous disposerez désormais d'une variable d'entraînement avec vos points d'échantillon. Imprimons le premier échantillon pour l'inspecter et ajoutons nos points d'entraînement à Map.
print('Extracted sample', training.first());
Map.addLayer(training, {color: 'blue'}, 'Extracted Samples', false);

Figure : Échantillons aléatoires extraits pour le clustering
Effectuer un clustering non supervisé
Nous pouvons maintenant entraîner un clusterer et regrouper les vecteurs d'embedding 64D dans un nombre choisi de clusters distincts. D'après nos connaissances locales, deux principaux types de cultures représentent la majorité de la zone, plusieurs autres cultures couvrant la fraction restante. Nous pouvons effectuer un clustering non supervisé sur l'intégration satellite pour obtenir des clusters de pixels ayant des trajectoires et des modèles temporels similaires. Les pixels présentant des caractéristiques spectrales et spatiales similaires, ainsi qu'une phénologie semblable, seront regroupés dans le même cluster.
ee.Clusterer.wekaCascadeKMeans() nous permet de spécifier un nombre minimal et maximal de clusters, et de trouver le nombre optimal de clusters en fonction des données d'entraînement. Nos connaissances locales nous sont utiles pour déterminer le nombre minimal et maximal de clusters. Comme nous nous attendons à quelques types de clusters distincts (maïs, soja et plusieurs autres cultures), nous pouvons utiliser 4 comme nombre minimal de clusters et 5 comme nombre maximal de clusters. Vous devrez peut-être tester ces chiffres pour déterminer ce qui fonctionne le mieux dans votre région.
// Cluster the Satellite Embedding Image
var minClusters = 4;
var maxClusters = 5;
var clusterer = ee.Clusterer.wekaCascadeKMeans({
minClusters: minClusters, maxClusters: maxClusters}).train({
features: training,
inputProperties: clusterImage.bandNames()
});
var clustered = clusterImage.cluster(clusterer);
Map.addLayer(clustered.randomVisualizer().clip(geometry), {}, 'Clusters');
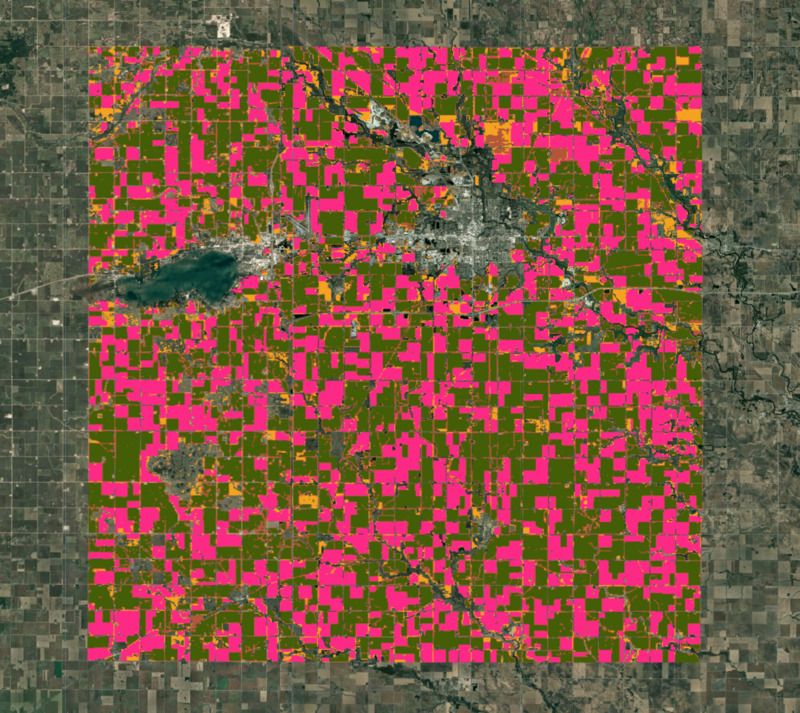
Figure : Clusters obtenus à partir de la classification non supervisée
Attribuer des libellés aux clusters
Après inspection visuelle, les clusters obtenus lors des étapes précédentes correspondent étroitement aux limites de la ferme visibles sur l'image haute résolution. Grâce à nos connaissances locales, nous savons que les deux plus grands clusters sont ceux du maïs et du soja. Calculons les zones de chaque cluster dans notre image.
// Calculate Cluster Areas
// 1 Acre = 4046.86 Sq. Meters
var areaImage = ee.Image.pixelArea().divide(4046.86).addBands(clustered);
var areas = areaImage.reduceRegion({
reducer: ee.Reducer.sum().group({
groupField: 1,
groupName: 'cluster',
}),
geometry: geometry,
scale: 10,
maxPixels: 1e10
});
var clusterAreas = ee.List(areas.get('groups'));
// Process results to extract the areas and create a FeatureCollection
var clusterAreas = clusterAreas.map(function(item) {
var areaDict = ee.Dictionary(item);
var clusterNumber = areaDict.getNumber('cluster').format();
var area = areaDict.getNumber('sum');
return ee.Feature(null, {cluster: clusterNumber, area: area});
});
var clusterAreaFc = ee.FeatureCollection(clusterAreas);
print('Cluster Areas', clusterAreaFc);
Nous sélectionnons les deux clusters dont la zone est la plus grande.
var selectedFc = clusterAreaFc.sort('area', false).limit(2);
print('Top 2 Clusters by Area', selectedFc);
Mais nous ne savons toujours pas à quelle culture correspond chaque cluster. Si vous disposiez de quelques échantillons de maïs ou de soja, vous pourriez les superposer aux clusters pour déterminer leurs libellés respectifs. En l'absence d'échantillons de champs, nous pouvons exploiter les statistiques agrégées sur les cultures. Dans de nombreuses régions du monde, des statistiques agrégées sur les cultures sont collectées et publiées régulièrement. Aux États-Unis, le National Agricultural Statistics Service (NASS) fournit des statistiques détaillées sur les cultures pour chaque comté et chaque culture principale. En 2022, le comté de Cerro Gordo, dans l'Iowa, a enregistré une superficie plantée en maïs de 65 350 hectares et une superficie plantée en soja de 44 720 hectares.
Grâce à ces informations, nous savons désormais que parmi les deux principaux clusters, celui qui couvre la plus grande superficie sera très probablement du maïs et l'autre du soja. Attribuons ces libellés et comparons les zones calculées avec les statistiques publiées.
var cornFeature = selectedFc.sort('area', false).first();
var soybeanFeature = selectedFc.sort('area').first();
var cornCluster = cornFeature.get('cluster');
var soybeanCluster = soybeanFeature.get('cluster');
print('Corn Area (Detected)', cornFeature.getNumber('area').round());
print('Corn Area (From Crop Statistics)', 163500);
print('Soybean Area (Detected)', soybeanFeature.getNumber('area').round());
print('Soybean Area (From Crop Statistics)', 110500);
Créer une carte des cultures
Nous connaissons désormais les libellés de chaque cluster et pouvons extraire les pixels pour chaque type de culture et les fusionner pour créer la carte des cultures finale.
// Select the clusters to create the crop map
var corn = clustered.eq(ee.Number.parse(cornCluster));
var soybean = clustered.eq(ee.Number.parse(soybeanCluster));
var merged = corn.add(soybean.multiply(2));
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(merged.clip(geometry), cropVis, 'Crop Map (Detected)');
Pour interpréter les résultats, nous pouvons également utiliser des éléments d'UI pour créer et ajouter une légende à la carte.
// Add a Legend
var legend = ui.Panel({
layout: ui.Panel.Layout.Flow('horizontal'),
style: {position: 'bottom-center', padding: '8px 15px'}});
var addItem = function(color, name) {
var colorBox = ui.Label({
style: {color: '#ffffff',
backgroundColor: color,
padding: '10px',
margin: '0 4px 4px 0',
}
});
var description = ui.Label({
value: name,
style: {
margin: '0px 10px 0px 2px',
}
});
return ui.Panel({
widgets: [colorBox, description],
layout: ui.Panel.Layout.Flow('horizontal')
});
};
var title = ui.Label({
value: 'Legend',
style: {
fontWeight: 'bold',
fontSize: '16px',
margin: '0px 10px 0px 4px'
}
});
legend.add(title);
legend.add(addItem('#ffd400', 'Corn'));
legend.add(addItem('#267300', 'Soybean'));
legend.add(addItem('#bdbdbd', 'Other Crops'));
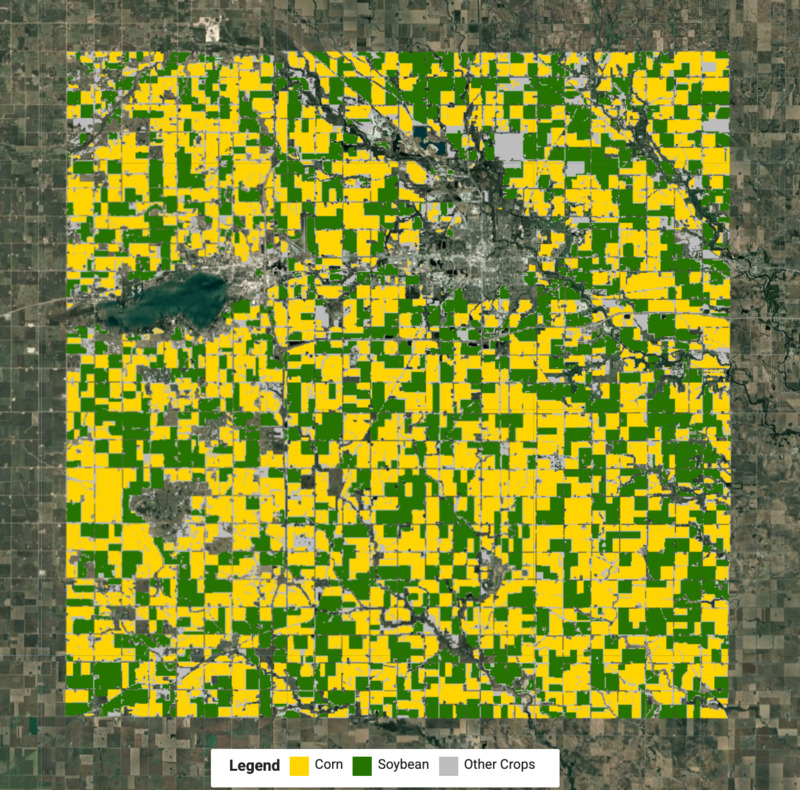
Figure : Carte de cultures détectées avec des cultures de maïs et de soja
Valider les résultats
Nous avons pu obtenir une carte des types de cultures avec l'ensemble de données Satellite Embedding sans aucun libellé de champ, en utilisant uniquement les statistiques agrégées et les connaissances locales de la région. Comparons nos résultats avec la carte officielle des types de cultures des couches de données sur les terres cultivées (CDL) de l'USDA NASS.
var cdl = ee.ImageCollection('USDA/NASS/CDL')
.filter(ee.Filter.date(startDate, endDate))
.first();
var cropLandcover = cdl.select('cropland');
var cropMap = cropLandcover.updateMask(croplandMask).rename('crops');
// Original data has unique values for each crop ranging from 0 to 254
var cropClasses = ee.List.sequence(0, 254);
// We remap all values as following
// Crop | Source Value | Target Value
// Corn | 1 | 1
// Soybean | 5 | 2
// All other| 0-255 | 0
var targetClasses = ee.List.repeat(0, 255).set(1, 1).set(5, 2);
var cropMapReclass = cropMap.remap(cropClasses, targetClasses).rename('crops');
var cropVis = {min: 0, max: 2, palette: ['#bdbdbd', '#ffd400', '#267300']};
Map.addLayer(cropMapReclass.clip(geometry), cropVis, 'Crop Landcover (CDL)');

Figure : (à gauche) carte recadrée à partir d'intégrations satellite, (à droite) carte recadrée à partir de CDL
Bien qu'il existe des différences entre nos résultats et la carte officielle, vous remarquerez que nous avons pu obtenir de très bons résultats avec un minimum d'efforts. En appliquant des étapes de post-traitement aux résultats, nous pouvons supprimer une partie du bruit et combler les lacunes de la sortie.
Essayez le script complet de ce tutoriel dans l'éditeur de code Earth Engine.