
高度な ML モデルがシンプルな REST API にカプセル化した形で提供され、これを使って画像の内容を把握できます。
このラボでは画像を Vision API に送信し、物体、顔、ランドマークが検出されることを確認します。
学習内容
- Vision API リクエストを作成し、curl で API を呼び出す
- Vision API のラベル、ウェブ、顔、ランドマークの検出メソッドを使用する
必要なもの
このチュートリアルをどのように使用されますか?
Google Cloud Platform のご利用経験について、いずれに該当されますか?
セルフペース型の環境設定
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。Google Cloud Platform のコンソール(console.cloud.google.com)にログインし、新しいプロジェクトを作成します。



プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、このコードラボでは PROJECT_ID と呼びます。
次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
この Codelab の操作をすべて行っても、費用は数ドル程度です。ただし、その他のリソースを使いたい場合や、実行したままにしておきたいステップがある場合は、追加コストがかかる可能性があります(このドキュメントの最後にある「クリーンアップ」セクションをご覧ください)。
Google Cloud Platform の新規ユーザーは、300 ドル分の無料トライアルをご利用いただけます。
画面の左上にあるメニュー アイコンをクリックします。

プルダウンから [API とサービス] を選択し、[ダッシュボード] をクリックします。
[API とサービスを有効化] をクリックします。
検索ボックスで「vision」を検索します。[Google Cloud Vision API] をクリックします。

[有効にする] をクリックして、Cloud Vision API を有効にします。

有効になるまで数秒待ちます。有効にすると、次のように表示されます。
Google Cloud Shell は、 Cloud 上で動作するコマンドライン環境です。この Debian ベースの仮想マシンには、必要な開発ツール(gcloud、bq、git など)がすべて用意され、永続的な 5 GB のホーム ディレクトリが提供されています。Cloud Shell を使用して Speech API へのリクエストを作成します。
Cloud Shell を始めるには、ヘッダーバーの右上にある [Google Cloud Shell をアクティブにする]  アイコンをクリックします。
アイコンをクリックします。

コンソールの下部の新しいフレーム内で Cloud Shell セッションが開き、コマンドライン プロンプトが表示されます。user@project:~$ プロンプトが表示されるまで待ちます。
curl を使用して Vision API にリクエストを送信するため、リクエスト URL で渡す API キーを生成する必要があります。API キーを作成するには、Cloud コンソールの [API とサービス] の [認証情報] セクションに移動します。
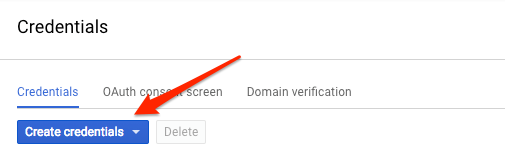
プルダウン メニューで [API キー] を選択します。
生成された API キーをコピーし、
これで API キーができました。各リクエストに API キーの値を挿入せずに済むように、環境変数に API キーを保存します。環境変数にキーを保存するには、Cloud Shell で次のように入力します。<your_api_key> の部分は、コピーしたキーに置き換えてください。
export API_KEY=<YOUR_API_KEY>Cloud Storage バケットを作成する
画像検出のために Vision API に画像を送信する方法は 2 つあります。base64 でエンコードされた画像文字列を API に送信する方法と、Google Cloud Storage に保存されたファイルの URL を渡す方法です。ここでは Cloud Storage の URL を使用します。画像を保存するための Google Cloud Storage バケットを作成します。
プロジェクトの Cloud コンソールで Storage ブラウザに移動します。
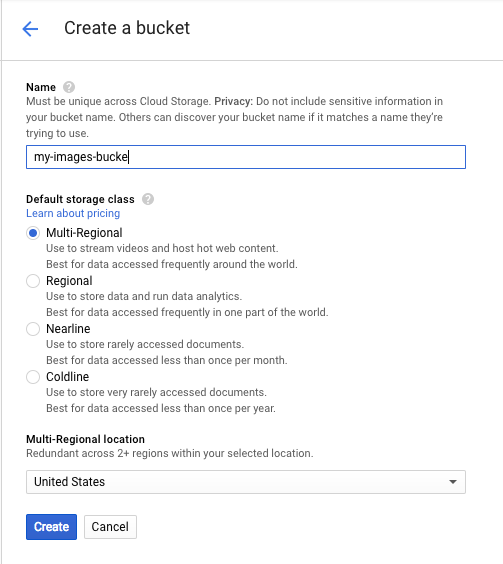
[バケットを作成] をクリックします。バケットに一意の名前(プロジェクト ID など)を付けて、[作成] をクリックします。
バケットに画像をアップロードする
次のドーナツの画像を右クリックし、[名前を付けて画像を保存] をクリックして、donuts.png という名前でダウンロード フォルダに保存します。

Cloud Storage ブラウザで、先ほど作成したバケットに移動し、[ファイルをアップロード] をクリックします。次に、donuts.png を選択します。
バケットにファイルが表示されます。

次に、画像の権限を編集します。
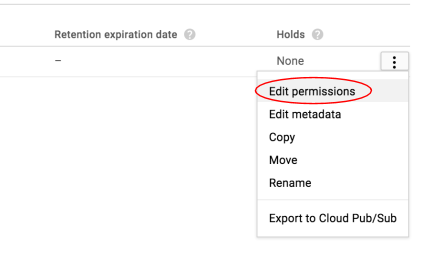
[変数を追加] をクリックします。
Group の新しいエンティティと allUsers の名前を追加します。
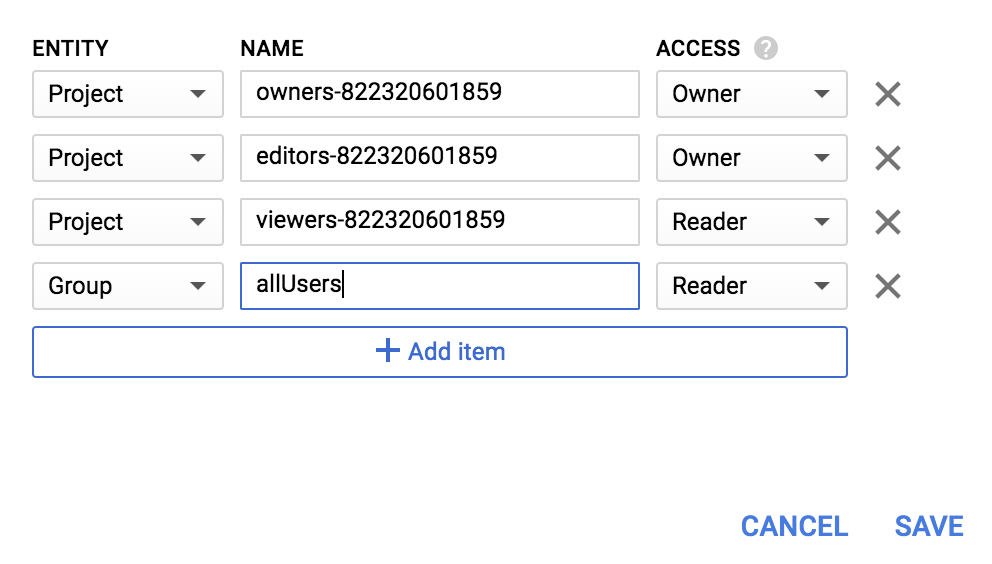
[保存] をクリックします。
これで、ファイルをバケットに保存できました。次は Vision API リクエストを作成し、Vision API にこのドーナッツの画像の URL を渡します。
Cloud Shell 環境で、次のコードを使用して request.json ファイルを作成します。my-bucket-name は、作成した Cloud Storage バケットの名前に置き換えてください。Cloud Shell の組み込み Orion エディタ以外のコマンドライン エディタ(nano、vim、emacs)を使用してもかまいません。
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}最初に、Cloud Vision API のラベル検出機能について見てみましょう。このメソッドは、画像に含まれるラベル(単語)のリストを返します。
これで、curl を使用して Vision API を呼び出す準備ができました。
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}次のようなレスポンスが表示されます。
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}API によって、ドーナツの具体的な種類(ベニエ)が特定されました。Vision API で検出されたラベルごとに、アイテムの名前を含む description が返されます。また、説明と画像の内容がどの程度一致しているかの信頼度を示す 0 ~ 100 の数字である score も返します。mid 値は、Google のナレッジグラフのアイテムの mid にマッピングされます。Knowledge Graph API を呼び出すときに mid を使用すると、アイテムに関する詳細情報を取得できます。
Vision API を使うと、画像の内容に関するラベルを取得することができます。また、特定の画像の詳細情報をインターネットで検索することもできます。API の webDetection メソッドを使用することで、以下のようなさまざまな興味深いデータを取得できます。
- 画像に含まれるエンティティのリスト(類似画像を含むページのコンテンツに基づく)
- ウェブ上で見つかった完全一致画像と部分一致画像の URL、およびそれらの画像を含むページの URL
- 画像を使用した検索などで得られた、類似画像の URL
ウェブ検出を試すには、上記のベニエの画像を使用します。変更する必要があるのは request.json ファイルの 1 行だけです(まったく異なる画像を使用することもできます)。features リストの下で、type を LABEL_DETECTION から WEB_DETECTION に変更します。request.json は次のようになります。
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}これを Vision API に送信するには、前と同じように curl コマンドを使用します(Cloud Shell で ↑ キーを押すだけです)。
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}次は、webEntities で始まるレスポンスを調べてみましょう。以下は、この画像が返したエンティティの一部です。
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
この画像は Cloud ML API の多くのプレゼンテーションで再利用されているため、API は「Machine learning」、「Google Cloud Platform」、「Cloud computing」といったエンティティを検出しました。
fullMatchingImages、partialMatchingImages、pagesWithMatchingImages の下の URL を調べると、多くの URL がこの Codelab サイトを参照していることがわかります。
他のベニエの画像が必要であるものの、まったく同じ画像は必要ではないものとします。その場合は、API レスポンスの visuallySimilarImages 部分が役に立ちます。次のような視覚的に類似した画像が検出されます。
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]これらの URL にアクセスすれば、類似の画像を確認できます。




分析がうまくいったようです。本物のベニエが食べたくなりますね。これは、Google 画像検索の画像による検索と似ています。
Cloud Vision を使用すると、使いやすい REST API で画像検索機能にアクセスし、それをアプリケーションに統合できます。
次に、Vision API の顔とランドマークの検出メソッドについて説明します。顔の検出メソッドは、画像内で検出された顔に関するデータを返します。返されるデータには、その顔の感情や画像内での位置も含まれます。ランドマークの検出メソッドを使うと、一般的なランドマークで不明瞭なものを識別することができます。ランドマークの名前、その緯度と経度の座標、ランドマークが識別された画像内の位置が返されます。
新しい画像をアップロードする
この 2 つの新しいメソッドを使用するため、顔とランドマークを含む新しい画像を Cloud Storage バケットにアップロードします。次の画像を右クリックし、[名前を付けて画像を保存] をクリックして、selfie.png という名前でダウンロード フォルダに保存します。

次に、前の手順と同じ方法で Cloud Storage バケットにアップロードします。このとき、[一般公開して誰でも利用できるようにする] チェックボックスをオンにしてください。
リクエストの更新
次に、request.json ファイルを更新して、新しい画像の URL を含め、ラベル検出ではなく顔検出とランドマーク検出を使用するようにします。my-bucket-name の部分は、Cloud Storage バケットの名前に置き換えてください。
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Vision API を呼び出してレスポンスを解析する
これで、先ほどと同じ curl コマンドを使用して Vision API を呼び出す準備ができました。
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}まず、レスポンスの faceAnnotations オブジェクトを見てみましょう。画像内に見つかったそれぞれの顔(この場合は 3 つ)に関して、API がオブジェクトを 1 つ返していることがわかります。以下は、レスポンスの一部を抜粋したものです。
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly は、画像内の顔の周囲の x 座標と y 座標を示します。fdBoundingPoly は顔の肌部分にフォーカスした、boundingPoly よりも小さなボックスです。landmarks は、それぞれの顔の特徴を表すオブジェクトの配列です(聞き慣れないものも含まれているかもしれません)。この値から、ランドマークの種類と、その特徴の 3 次元の位置(x, y, z 座標)がわかります。z 座標は奥行きを示しています。残りの値からは、喜びや悲しみ、怒り、驚きの感情の尤度など、顔に関する情報がわかります。上記のオブジェクトは、画像の最も奥に立っている人物のものです。彼はおどけた表情をしていますが、それが joyLikelihood の POSSIBLE という値に表れています。
次に、レスポンスの landmarkAnnotations 部分を見てみましょう。
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]ここで Vision API は、この写真がペトラ遺跡で撮影されたことを認識することができました。この画像に含まれる視覚的な手掛かりがほとんどないことを踏まえると、実に見事といえます。このレスポンスに含まれる値は、上記の labelAnnotations のレスポンスに似ています。
ランドマークの mid、名前(description)、信頼度 score を取得します。boundingPoly: ランドマークが特定された画像内の領域。locations キー: このランドマークの緯度と経度の座標。
Vision API のラベル、顔、ランドマークの検出メソッドを見てきましたが、他にもまだ取り上げていないメソッドが 3 つあります。他の 3 つの検出メソッドについて詳しくは、こちらの資料をご確認ください。
- ロゴの検出: 画像に含まれる一般的なロゴとその位置を特定します。
- セーフサーチ検出: 画像に不適切コンテンツが含まれているかどうかを検出します。このメソッドは、ユーザー作成コンテンツを扱うすべてのアプリケーションで役立ちます。アダルト、医療、暴力、なりすましの 4 つの要因に基づいて画像をフィルタします。
- テキスト検出: OCR を実行して画像からテキストを抽出します。画像内に含まれているテキストの言語を識別することもできます。
このラボでは、Vision API を使って画像を分析する方法について学びました。この例では、API に対象画像の URL(Google Cloud Storage のもの)を渡しました。別の方法として、base64 でエンコードされた画像文字列を渡すこともできます。
学習した内容
- Cloud Storage バケット内の画像の URL を Vision API に渡し、curl を使用して Vision API を呼び出す
- Vision API のラベル、ウェブ、顔、ランドマークの検出メソッドを使用する
次のステップ
- ドキュメントで Vision API のチュートリアルを確認する
- お好きな言語の Vision API サンプルを見つける
- Speech API と Natural Language API の Codelab をお試しください。