
L'API Cloud Vision ti consente di comprendere i contenuti di un'immagine integrando efficaci modelli di machine learning in un'API REST semplice.
In questo lab invieremo immagini all'API Vision per rilevare oggetti, volti e punti di riferimento.
Cosa imparerai a fare
- Creare una richiesta API Vision e chiamare l'API con curl
- Utilizzo dei metodi di rilevamento di etichette, web, volti e punti di riferimento dell'API Vision
Cosa ti serve
Come utilizzerai questo tutorial?
Come valuteresti la tua esperienza con Google Cloud Platform?
Configurazione dell'ambiente autonoma
Se non hai ancora un Account Google (Gmail o Google Apps), devi crearne uno. Accedi alla console di Google Cloud (console.cloud.google.com) e crea un nuovo progetto:



Ricorda l'ID progetto, un nome univoco per tutti i progetti Google Cloud (il nome riportato sopra è già stato utilizzato e non funzionerà per te, mi dispiace). In questo codelab verrà chiamato PROJECT_ID.
Successivamente, dovrai abilitare la fatturazione nella console Cloud per utilizzare le risorse Google Cloud.
L'esecuzione di questo codelab non dovrebbe costarti più di qualche dollaro, ma potrebbe essere più cara se decidi di utilizzare più risorse o se le lasci in esecuzione (vedi la sezione "Pulizia" alla fine di questo documento).
I nuovi utenti di Google Cloud Platform possono beneficiare di una prova senza costi di 300$.
Fai clic sull'icona del menu nella parte superiore sinistra dello schermo.

Seleziona API e servizi dal menu a discesa e fai clic su Dashboard.
Fai clic su Abilita API e servizi.
Cerca "visione" nella casella di ricerca. Fai clic su API Google Cloud Vision:

Fai clic su Abilita per abilitare l'API Cloud Vision:

Attendi qualche secondo affinché venga attivato. Una volta attivata, vedrai questo:
Google Cloud Shell è un ambiente a riga di comando in esecuzione nel cloud. Questa macchina virtuale basata su Debian viene caricata con tutti gli strumenti di sviluppo di cui avrai bisogno (gcloud, bq, git e altri) e mette a tua disposizione una home directory permanente di 5 GB. Utilizzeremo Cloud Shell per creare la nostra richiesta all'API Speech.
Per iniziare a utilizzare Cloud Shell, fai clic sull'icona "Attiva Google Cloud Shell"  nell'angolo in alto a destra della barra dell'intestazione.
nell'angolo in alto a destra della barra dell'intestazione.

All'interno di un nuovo frame nella parte inferiore della console si apre una sessione di Cloud Shell e viene visualizzato un prompt della riga di comando. Attendi finché non viene visualizzato il prompt user@project:~$
Poiché utilizzeremo curl per inviare una richiesta all'API Vision, dobbiamo generare una chiave API da passare nell'URL della richiesta. Per creare una chiave API, vai alla sezione Credenziali di API e servizi nella console Cloud:
Seleziona Chiave API dal menu a discesa:
Copia la chiave appena generata.
Ora che hai una chiave API, salvala come variabile di ambiente per evitare di doverne inserirne il valore in ogni richiesta. Puoi farlo in Cloud Shell. Assicurati di sostituire <your_api_key> con la chiave che hai appena copiato.
export API_KEY=<YOUR_API_KEY>Creazione di un bucket Cloud Storage
Esistono due modi per inviare un'immagine all'API Vision per il rilevamento delle immagini: inviando all'API una stringa di immagine codificata in base64 o trasmettendo l'URL di un file archiviato in Google Cloud Storage. Utilizzeremo un URL Cloud Storage. Creeremo un bucket Google Cloud Storage per archiviare le nostre immagini.
Vai al browser Storage nella console Cloud per il tuo progetto:
Quindi, fai clic su Crea bucket. Assegna al bucket un nome univoco (ad esempio l'ID progetto) e fai clic su Crea.
Caricare un'immagine nel bucket
Fai clic con il tasto destro del mouse sull'immagine seguente di ciambelle, poi fai clic su Salva immagine con nome e salvala nella cartella Download come donuts.png.

Vai al bucket appena creato nel browser di archiviazione e fai clic su Carica file. Poi seleziona donuts.png.
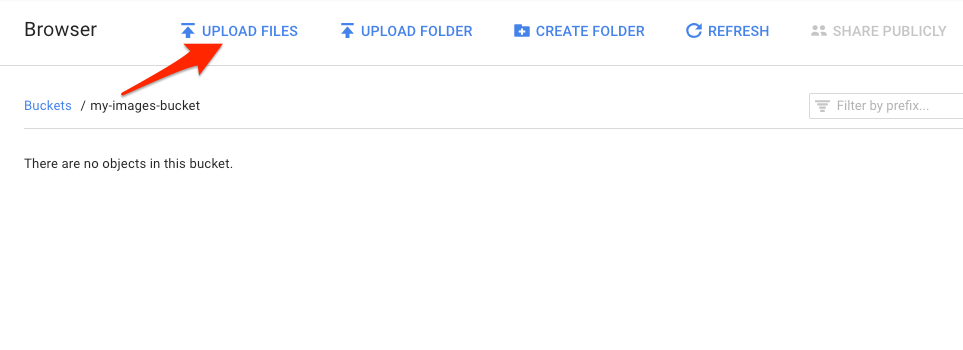
Dovresti vedere il file nel bucket:

Successivamente, modifica l'autorizzazione dell'immagine.
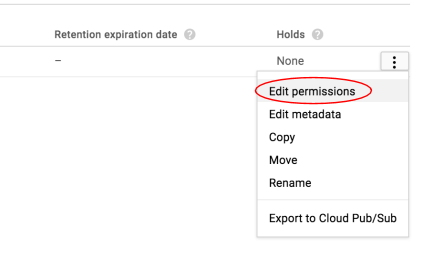
Fai clic su Aggiungi elemento.
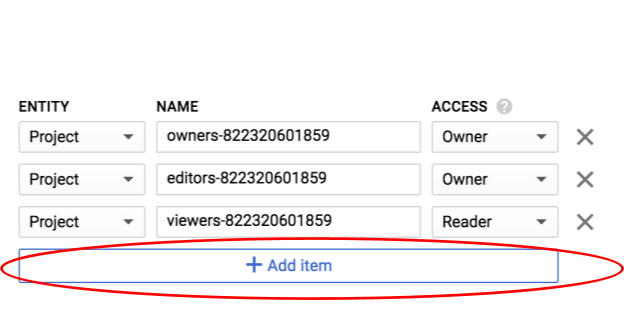
Aggiungi una nuova Entità di Group e un Nome di allUsers:
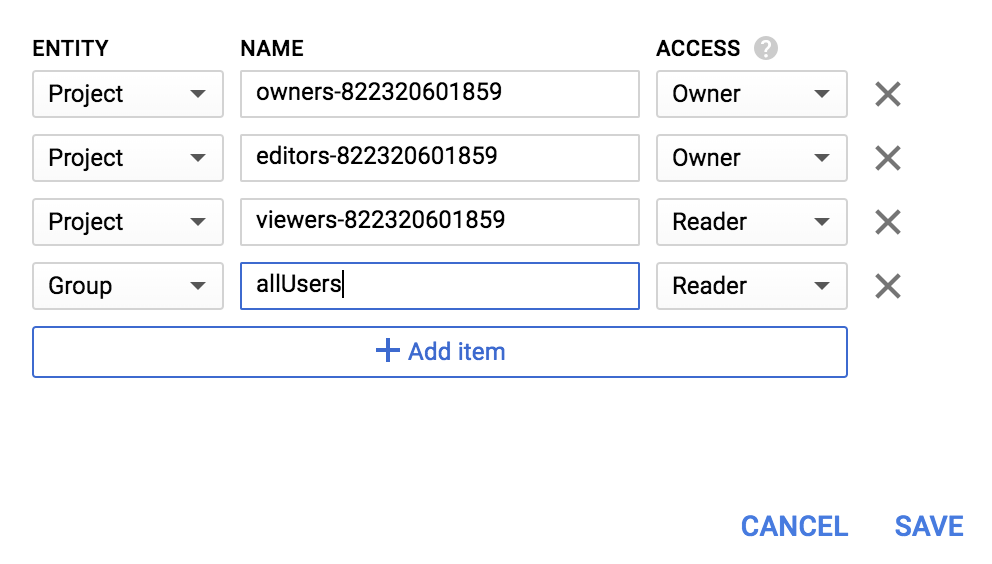
Fai clic su Salva.
Ora che hai il file nel bucket, puoi creare una richiesta dell'API Vision, passando l'URL di questa immagine di ciambelle.
Nell'ambiente Cloud Shell, crea un file request.json con il codice riportato di seguito, assicurandoti di sostituire my-bucket-name con il nome del bucket Cloud Storage che hai creato. Puoi creare il file utilizzando uno dei tuoi editor di riga di comando preferiti (nano, vim, emacs) oppure utilizzare l'editor Orion integrato in Cloud Shell:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}La prima funzionalità dell'API Cloud Vision che esploreremo è il rilevamento etichette. Questo metodo restituirà un elenco di etichette (parole) che descrivono il contenuto dell'immagine.
Ora possiamo chiamare l'API Vision con curl:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}La risposta dovrebbe essere simile alla seguente:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}L'API è riuscita a identificare il tipo specifico di ciambelle (frittelle), fantastico. Per ogni etichetta trovata dall'API Vision, restituisce un description con il nome dell'elemento. Restituisce anche un score, un numero compreso tra 0 e 100 che indica il livello di confidenza che la descrizione corrisponde a ciò che è presente nell'immagine. Il valore mid viene mappato al mid dell'elemento nel Knowledge Graph di Google. Puoi utilizzare mid quando chiami l'API Knowledge Graph per ottenere maggiori informazioni sull'elemento.
Oltre a ottenere etichette su ciò che è presente nell'immagine, l'API Vision può anche cercare su internet ulteriori dettagli sull'immagine. Tramite il metodo webDetection dell'API, riceviamo molti dati interessanti:
- Un elenco di entità trovate nella nostra immagine, in base ai contenuti delle pagine con immagini simili
- URL delle immagini con corrispondenza esatta e parziale trovate sul web, insieme agli URL di queste pagine
- URL di immagini simili, come una ricerca inversa delle immagini
Per provare il rilevamento web, utilizzeremo la stessa immagine di frittelle di prima, quindi dobbiamo modificare solo una riga nel nostro file request.json (puoi anche avventurarti nell'ignoto e utilizzare un'immagine completamente diversa). Nell'elenco delle funzionalità, cambia il tipo da LABEL_DETECTION a WEB_DETECTION. request.json ora dovrebbe avere il seguente aspetto:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Per inviarlo all'API Vision, puoi utilizzare lo stesso comando curl di prima (basta premere la freccia su in Cloud Shell):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Analizziamo la risposta, a partire da webEntities. Ecco alcune delle entità restituite da questa immagine:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Questa immagine è stata riutilizzata in molte presentazioni sulle nostre API Cloud ML, motivo per cui l'API ha trovato le entità "Machine learning", "Google Cloud Platform" e "Cloud computing".
Se esaminiamo gli URL in fullMatchingImages, partialMatchingImages e pagesWithMatchingImages, noteremo che molti puntano a questo sito di codelab (super meta!).
Supponiamo di voler trovare altre immagini di frittelle, ma non le stesse. È qui che entra in gioco la parte visuallySimilarImages della risposta dell'API. Ecco alcune delle immagini visivamente simili che ha trovato:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]Possiamo andare a questi URL per visualizzare le immagini simili:




Interessante! E ora probabilmente hai davvero voglia di un beignet (scusa). Questa funzionalità è simile alla ricerca per immagine su Google Immagini:
Con Cloud Vision, invece, possiamo accedere a questa funzionalità con un'API REST facile da usare e integrarla nelle nostre applicazioni.
Successivamente, esploreremo i metodi di rilevamento di volti e punti di riferimento dell'API Vision. Il metodo di rilevamento dei volti restituisce dati sui volti trovati in un'immagine, incluse le emozioni dei volti e la loro posizione nell'immagine. Il rilevamento dei punti di riferimento può identificare punti di riferimento comuni (e oscuri). Restituisce il nome del punto di riferimento, le coordinate di latitudine e longitudine e la posizione in cui è stato identificato in un'immagine.
Caricare una nuova immagine
Per utilizzare questi due nuovi metodi, carichiamo una nuova immagine con volti e punti di riferimento nel nostro bucket Cloud Storage. Fai clic con il tasto destro del mouse sull'immagine seguente, poi fai clic su Salva immagine con nome e salvala nella cartella Download come selfie.png.

Quindi, caricalo nel bucket Cloud Storage nello stesso modo in cui hai fatto nel passaggio precedente, assicurandoti di selezionare la casella di controllo "Condividi pubblicamente".
Aggiornamento della nostra richiesta
Successivamente, aggiorneremo il file request.json per includere l'URL della nuova immagine e per utilizzare il rilevamento di volti e punti di riferimento anziché il rilevamento delle etichette. Assicurati di sostituire my-bucket-name con il nome del tuo bucket Cloud Storage:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Chiamare l'API Vision e analizzare la risposta
Ora puoi chiamare l'API Vision utilizzando lo stesso comando curl che hai utilizzato sopra:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Diamo prima un'occhiata all'oggetto faceAnnotations nella nostra risposta. Noterai che l'API restituisce un oggetto per ogni volto trovato nell'immagine, in questo caso tre. Ecco una versione troncata della nostra risposta:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly ci fornisce le coordinate x,y intorno al volto nell'immagine. fdBoundingPoly è un riquadro più piccolo di boundingPoly, che codifica la parte della pelle del viso. landmarks è un array di oggetti per ogni tratto del viso (alcuni che forse non conoscevi nemmeno). Indica il tipo di punto di riferimento, insieme alla posizione 3D della funzionalità (coordinate x, y, z), dove la coordinata z è la profondità. I valori rimanenti forniscono maggiori dettagli sul volto, inclusa la probabilità di gioia, tristezza, rabbia e sorpresa. L'oggetto sopra è per la persona più indietro nell'immagine. Puoi vedere che sta facendo una faccia buffa, il che spiega il joyLikelihood di POSSIBLE.
Ora esaminiamo la parte landmarkAnnotations della nostra risposta:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]In questo caso, l'API Vision è riuscita a capire che la foto è stata scattata a Petra, il che è piuttosto impressionante dato che gli indizi visivi nell'immagine sono minimi. I valori in questa risposta dovrebbero essere simili alla risposta labelAnnotations riportata sopra.
Riceviamo le mid del punto di riferimento, il suo nome (description) e un valore di confidenza score. boundingPoly mostra la regione dell'immagine in cui è stato identificato il punto di riferimento. Il tasto locations indica le coordinate di latitudine e longitudine di questo punto di riferimento.
Abbiamo esaminato i metodi di rilevamento di etichette, volti e punti di riferimento dell'API Vision, ma ne esistono altri tre che non abbiamo esplorato. Consulta la documentazione per scoprire gli altri tre:
- Rilevamento loghi: identifica i loghi comuni e la loro posizione in un'immagine.
- Rilevamento della ricerca sicura: determina se un'immagine contiene contenuti espliciti. Ciò è utile per qualsiasi applicazione con contenuti generati dagli utenti. Puoi filtrare le immagini in base a quattro fattori: contenuti per adulti, medici, violenti e falsi.
- Rilevamento del testo: esegui l'OCR per estrarre il testo dalle immagini. Questo metodo può persino identificare la lingua del testo presente in un'immagine.
Hai imparato ad analizzare le immagini con l'API Vision. In questo esempio hai trasmesso all'API l'URL Google Cloud Storage della tua immagine. In alternativa, puoi trasmettere una stringa codificata in base64 della tua immagine.
Argomenti trattati
- Chiamare l'API Vision con curl passando l'URL di un'immagine in un bucket Cloud Storage
- Utilizzo dei metodi di rilevamento di etichette, web, volti e punti di riferimento dell'API Vision
Passaggi successivi
- Consulta i tutorial sull'API Vision nella documentazione.
- Trova un esempio dell'API Vision nella tua lingua preferita
- Prova i codelab dell'API Speech e dell'API Natural Language.