
Cloud Vision API memungkinkan Anda memahami konten gambar dengan mengenkapsulasi model machine learning yang canggih dalam REST API sederhana.
Di lab ini, kita akan mengirim gambar ke Vision API dan melihat objek, wajah, dan tempat terkenal dideteksi.
Yang akan Anda pelajari
- Membuat permintaan Vision API dan memanggil API menggunakan curl
- Menggunakan metode deteksi label, web, wajah, dan tempat terkenal dari Vision API
Yang akan Anda butuhkan
Bagaimana Anda akan menggunakan tutorial ini?
Bagaimana penilaian Anda terhadap pengalaman dengan Google Cloud Platform?
Penyiapan lingkungan mandiri
Jika belum memiliki Akun Google (Gmail atau Google Apps), Anda harus membuatnya. Login ke Google Cloud Platform console (console.cloud.google.com) dan buat project baru:



Ingat project ID, nama unik di semua project Google Cloud (maaf, nama di atas telah digunakan dan tidak akan berfungsi untuk Anda!) Project ID tersebut selanjutnya akan dirujuk di codelab ini sebagai PROJECT_ID.
Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource Google Cloud.
Menjalankan melalui codelab ini tidak akan menghabiskan biaya lebih dari beberapa dolar, tetapi bisa lebih jika Anda memutuskan untuk menggunakan lebih banyak resource atau jika Anda membiarkannya berjalan (lihat bagian "pembersihan" di akhir dokumen ini).
Pengguna baru Google Cloud Platform memenuhi syarat untuk mendapatkan uji coba gratis senilai$300.
Klik ikon menu di kiri atas layar.

Pilih APIs & services dari drop-down, lalu klik Dashboard
Klik Enable APIs and services.
Kemudian, telusuri "vision" di kotak penelusuran. Klik Google Cloud Vision API:

Klik Enable untuk mengaktifkan Cloud Vision API:

Tunggu beberapa detik hingga tombol diaktifkan. Anda akan melihat ini setelah diaktifkan:
Google Cloud Shell adalah lingkungan command line yang berjalan di Cloud. Mesin virtual berbasis Debian ini dilengkapi dengan semua alat pengembangan yang akan Anda perlukan (gcloud, bq, git, dan lainnya) serta menawarkan direktori beranda persisten sebesar 5 GB. Kita akan menggunakan Cloud Shell untuk membuat permintaan ke Speech API.
Untuk mulai menggunakan Cloud Shell, klik ikon "Activate Google Cloud Shell"  di pojok kanan atas header bar
di pojok kanan atas header bar

Sesi Cloud Shell akan terbuka di dalam frame baru di bagian bawah konsol dan menampilkan perintah command-line. Tunggu hingga perintah user@project:~$ muncul
Karena kita akan menggunakan curl untuk mengirim permintaan ke Vision API, kita perlu membuat kunci API untuk meneruskan URL permintaan kita. Untuk membuat kunci API, buka bagian Kredensial di APIs & services di Konsol Cloud Anda:
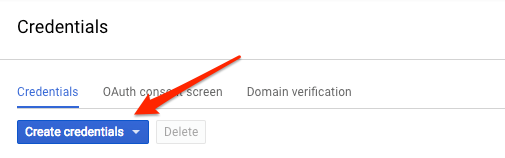
Pada menu drop-down, pilih Kunci API:
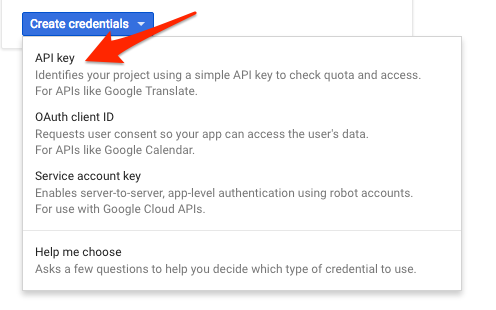
Selanjutnya, salin kunci yang baru saja Anda buat.
Setelah memiliki kunci API, simpan kunci tersebut ke variabel lingkungan agar Anda tidak perlu memasukkan nilai kunci API Anda dalam setiap permintaan. Anda dapat melakukannya di Cloud Shell. Pastikan untuk mengganti <your_api_key> dengan kunci yang baru saja Anda salin.
export API_KEY=<YOUR_API_KEY>Membuat bucket Cloud Storage
Ada dua cara untuk mengirim gambar ke Vision API untuk deteksi gambar: dengan mengirimkan string gambar berenkode base64 ke API, atau meneruskan URL file yang disimpan di Google Cloud Storage. Kita akan menggunakan URL Cloud Storage. Kita akan membuat bucket Google Cloud Storage untuk menyimpan gambar.
Buka browser Storage di konsol Cloud untuk project Anda:
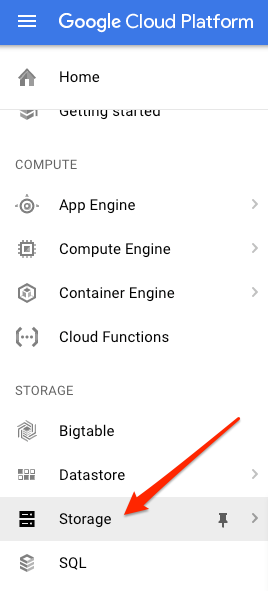
Kemudian, klik Buat bucket. Beri nama unik untuk bucket Anda (seperti Project ID Anda), lalu klik Create.
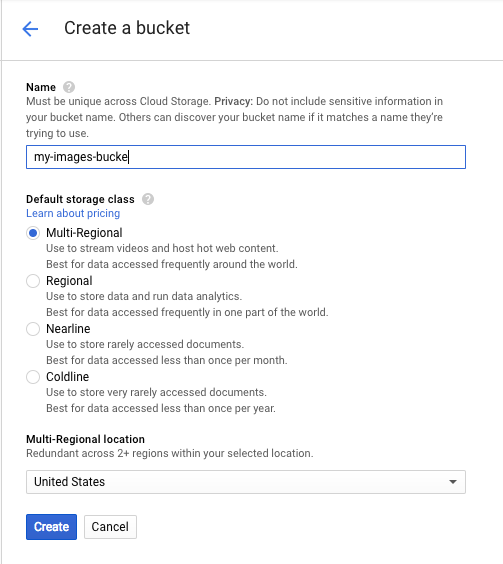
Mengupload gambar ke bucket Anda
Klik kanan gambar donat berikut, lalu klik Simpan gambar sebagai dan simpan ke folder Download Anda sebagai donuts.png.

Buka bucket yang baru saja Anda buat di browser penyimpanan, lalu klik Upload file. Kemudian, pilih donuts.png.
Anda akan melihat file di bucket Anda:

Selanjutnya, edit izin gambar.
Klik Tambahkan Item.
Tambahkan Entity baru Group, dan Name allUsers:
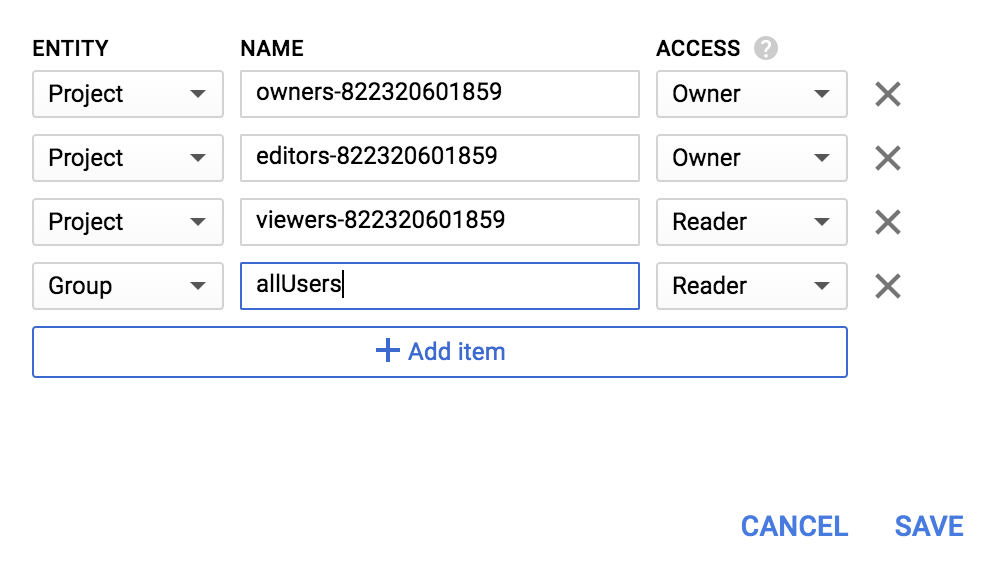
Klik Simpan.
Setelah memiliki file di bucket, Anda siap membuat permintaan Vision API, dengan meneruskan URL gambar donat ini.
Di lingkungan Cloud Shell, buat file request.json dengan kode di bawah, pastikan untuk mengganti my-bucket-name dengan nama bucket Cloud Storage yang Anda buat. Anda dapat membuat file menggunakan salah satu editor command line pilihan Anda (nano, vim, emacs) atau menggunakan editor Orion bawaan di Cloud Shell:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}Fitur Cloud Vision API pertama yang akan kita pelajari adalah deteksi label. Metode ini akan menampilkan daftar label (kata) tentang apa yang ada dalam gambar Anda.
Sekarang kita siap memanggil Vision API dengan curl:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Respons Anda akan terlihat seperti berikut:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}API dapat mengidentifikasi jenis donat ini (beignet), keren! Untuk setiap label yang ditemukan Vision API, API ini akan menampilkan description dengan nama item. Respons ini juga menampilkan score, angka dari 0 - 100 yang menunjukkan seberapa yakinnya bahwa deskripsi cocok dengan isi gambar. Nilai mid dipetakan ke mid item di Grafik Pengetahuan Google. Anda dapat menggunakan mid saat memanggil Knowledge Graph API untuk mendapatkan informasi selengkapnya tentang item.
Selain mendapatkan label tentang isi gambar, Vision API juga dapat menelusuri Internet untuk mendapatkan detail tambahan tentang gambar kita. Melalui metode webDetection API, kita mendapatkan banyak data menarik:
- Daftar entitas yang ditemukan dalam gambar kami, berdasarkan konten dari halaman dengan gambar serupa
- URL gambar yang cocok persis dan sebagian yang ditemukan di seluruh web, beserta URL halaman tersebut
- URL gambar serupa, seperti melakukan penelusuran balik gambar
Untuk mencoba deteksi web, kita akan menggunakan gambar beignet yang sama dari atas, jadi yang perlu kita ubah hanyalah satu baris dalam file request.json (Anda juga dapat mencoba hal yang tidak diketahui dan menggunakan gambar yang sama sekali berbeda). Di bagian daftar fitur, cukup ubah jenis dari LABEL_DETECTION menjadi WEB_DETECTION. request.json sekarang akan terlihat seperti ini:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}Untuk mengirimkannya ke Vision API, Anda dapat menggunakan perintah curl yang sama seperti sebelumnya (cukup tekan tombol panah atas di Cloud Shell):
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Mari kita bahas responsnya, dimulai dengan webEntities. Berikut beberapa entity yang ditampilkan gambar ini:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
Gambar ini telah digunakan kembali dalam banyak presentasi tentang Cloud ML API kami, itulah sebabnya API menemukan entitas "Machine learning", "Google Cloud Platform", dan "Cloud computing".
Jika kita memeriksa URL di bagian fullMatchingImages, partialMatchingImages, dan pagesWithMatchingImages, kita akan melihat bahwa banyak URL mengarah ke situs codelab ini (sangat meta!).
Misalnya, kita ingin menemukan gambar beignet lainnya, tetapi bukan gambar yang sama persis. Di sinilah bagian visuallySimilarImages dari respons API akan berguna. Berikut beberapa gambar yang mirip secara visual yang ditemukan:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]Kita dapat membuka URL tersebut untuk melihat gambar serupa:




Keren! Sekarang Anda mungkin benar-benar ingin beignet (maaf). Hal ini serupa dengan menelusuri berdasarkan gambar di Google Gambar:
Namun, dengan Cloud Vision, kita dapat mengakses fungsi ini dengan REST API yang mudah digunakan dan mengintegrasikannya ke dalam aplikasi kita.
Selanjutnya, kita akan mempelajari metode deteksi wajah dan tempat terkenal Vision API. Metode deteksi wajah menampilkan data tentang wajah yang ditemukan dalam gambar, termasuk emosi wajah dan lokasinya dalam gambar. Deteksi tempat terkenal dapat mengidentifikasi tempat terkenal umum (dan tidak jelas) - API ini menampilkan nama tempat terkenal, koordinat lintang bujurnya, dan lokasi tempat terkenal tersebut diidentifikasi dalam gambar.
Mengupload gambar baru
Untuk menggunakan dua metode baru ini, mari kita upload gambar baru dengan wajah dan penanda ke bucket Cloud Storage kita. Klik kanan gambar berikut, lalu klik Simpan gambar sebagai dan simpan ke folder Download Anda sebagai selfie.png.

Kemudian, upload ke bucket Cloud Storage dengan cara yang sama seperti yang Anda lakukan di langkah sebelumnya, pastikan untuk mencentang kotak "Bagikan secara publik".
Memperbarui permintaan kami
Selanjutnya, kita akan memperbarui file request.json untuk menyertakan URL gambar baru, dan menggunakan deteksi wajah dan penanda, bukan deteksi label. Pastikan untuk mengganti my-bucket-name dengan nama bucket Cloud Storage kita:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Memanggil Vision API dan mengurai respons
Sekarang Anda siap memanggil Vision API menggunakan perintah curl yang sama seperti yang Anda gunakan di atas:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}Mari kita lihat objek faceAnnotations dalam respons kita terlebih dahulu. Anda akan melihat bahwa API menampilkan objek untuk setiap wajah yang ditemukan dalam gambar - dalam hal ini, tiga. Berikut adalah versi singkat dari respons kami:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly memberi kita koordinat x,y di sekitar wajah dalam gambar. fdBoundingPoly adalah kotak yang lebih kecil daripada boundingPoly, yang mencakup bagian kulit wajah. landmarks adalah array objek untuk setiap fitur wajah (beberapa di antaranya mungkin belum Anda ketahui). Hal ini memberi tahu kita jenis penanda, beserta posisi 3D fitur tersebut (koordinat x,y,z) dengan koordinat z adalah kedalaman. Nilai yang tersisa memberi kita lebih banyak detail tentang wajah, termasuk kemungkinan ekspresi gembira, sedih, marah, dan terkejut. Objek di atas adalah untuk orang yang paling jauh di dalam gambar - Anda dapat melihat bahwa dia membuat ekspresi wajah yang agak konyol yang menjelaskan joyLikelihood dari POSSIBLE.
Selanjutnya, mari kita lihat bagian landmarkAnnotations dari respons kita:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]Di sini, Vision API dapat mengetahui bahwa foto ini diambil di Petra. Hal ini cukup mengesankan mengingat petunjuk visual dalam gambar ini sangat minim. Nilai dalam respons ini akan terlihat mirip dengan respons labelAnnotations di atas.
Kita mendapatkan mid tempat terkenal, namanya (description), beserta score keyakinan. boundingPoly menunjukkan region dalam gambar tempat tempat terkenal diidentifikasi. Kunci locations memberi tahu kita koordinat garis lintang dan bujur landmark ini.
Kita telah melihat metode deteksi label, wajah, dan bangunan terkenal Vision API, tetapi ada tiga metode lain yang belum kita pelajari. Pelajari dokumentasi untuk mempelajari tiga lainnya:
- Deteksi logo: mengidentifikasi logo umum dan lokasinya dalam gambar.
- Deteksi penelusuran aman: menentukan apakah gambar berisi konten vulgar atau tidak. Hal ini berguna untuk aplikasi apa pun yang memiliki konten buatan pengguna. Anda dapat memfilter gambar berdasarkan empat faktor: konten dewasa, medis, kekerasan, dan spoof.
- Deteksi teks: jalankan OCR untuk mengekstrak teks dari gambar. Metode ini bahkan dapat mengidentifikasi bahasa teks yang ada dalam gambar.
Anda telah mempelajari cara menganalisis gambar dengan Vision API. Dalam contoh ini, Anda meneruskan URL Google Cloud Storage gambar Anda ke API. Sebagai alternatif, Anda dapat meneruskan string berenkode base64 dari gambar Anda.
Yang telah kita bahas
- Memanggil Vision API dengan curl dengan meneruskan URL gambar di bucket Cloud Storage
- Menggunakan metode deteksi label, web, wajah, dan tempat terkenal Vision API
Langkah Berikutnya
- Lihat tutorial Vision API dalam dokumentasi
- Temukan contoh Vision API dalam bahasa favorit Anda
- Coba codelab Speech API dan Natural Language API.