
Cloud Vision API की मदद से, इमेज के कॉन्टेंट को समझा जा सकता है. इसके लिए, यह एक आसान REST API में पावरफ़ुल मशीन लर्निंग मॉडल को शामिल करता है.
इस लैब में, हम Vision API को इमेज भेजेंगे. साथ ही, देखेंगे कि यह ऑब्जेक्ट, चेहरों, और लैंडमार्क की पहचान कैसे करता है.
आपको क्या सीखने को मिलेगा
- Vision API का अनुरोध बनाना और curl की मदद से एपीआई को कॉल करना
- Vision API के लेबल, वेब, चेहरे, और लैंडमार्क की पहचान करने के तरीकों का इस्तेमाल करना
आपको इन चीज़ों की ज़रूरत होगी
इस ट्यूटोरियल का इस्तेमाल कैसे किया जाएगा?
Google Cloud Platform इस्तेमाल करने के अपने अनुभव को आप क्या रेटिंग देंगे?
अपने हिसाब से एनवायरमेंट सेट अप करना
अगर आपके पास पहले से कोई Google खाता (Gmail या Google Apps) नहीं है, तो आपको एक खाता बनाना होगा. Google Cloud Platform Console (console.cloud.google.com) में साइन इन करें और एक नया प्रोजेक्ट बनाएं:



प्रोजेक्ट आईडी याद रखें. यह सभी Google Cloud प्रोजेक्ट के लिए एक यूनीक नाम होता है. ऊपर दिया गया नाम पहले ही इस्तेमाल किया जा चुका है. इसलिए, यह आपके लिए काम नहीं करेगा. माफ़ करें! इस कोड लैब में इसे बाद में PROJECT_ID के तौर पर दिखाया जाएगा.
इसके बाद, Google Cloud संसाधनों का इस्तेमाल करने के लिए, आपको Cloud Console में बिलिंग चालू करनी होगी.
इस कोडलैब को पूरा करने में आपको कुछ डॉलर से ज़्यादा खर्च नहीं करने पड़ेंगे. हालांकि, अगर आपको ज़्यादा संसाधनों का इस्तेमाल करना है या उन्हें चालू रखना है, तो यह खर्च बढ़ सकता है. इस दस्तावेज़ के आखिर में "सफ़ाई" सेक्शन देखें.
Google Cloud Platform के नए उपयोगकर्ता, 300 डॉलर के क्रेडिट के साथ मुफ़्त में आज़माने की सुविधा पा सकते हैं.
स्क्रीन पर सबसे ऊपर बाईं ओर मौजूद, मेन्यू आइकॉन पर क्लिक करें.

ड्रॉप-डाउन मेन्यू से एपीआई और सेवाएं चुनें. इसके बाद, डैशबोर्ड पर क्लिक करें
एपीआई और सेवाएं चालू करें पर क्लिक करें.
इसके बाद, खोज बॉक्स में "vision" खोजें. Google Cloud Vision API पर क्लिक करें:

Cloud Vision API को चालू करने के लिए, चालू करें पर क्लिक करें:

इसे चालू होने में कुछ सेकंड लगेंगे. इस सुविधा के चालू होने पर, आपको यह दिखेगा:
Google Cloud Shell, क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है. Debian पर आधारित इस वर्चुअल मशीन में, आपको ज़रूरी सभी डेवलपमेंट टूल (gcloud, bq, git वगैरह) मिलेंगे. साथ ही, इसमें 5 जीबी की होम डायरेक्ट्री भी मिलती है. हम Speech API को अनुरोध भेजने के लिए, Cloud Shell का इस्तेमाल करेंगे.
Cloud Shell का इस्तेमाल शुरू करने के लिए, हेडर बार में सबसे ऊपर दाएं कोने में मौजूद "Google Cloud Shell चालू करें"  आइकॉन पर क्लिक करें
आइकॉन पर क्लिक करें

Cloud Shell सेशन, कंसोल में सबसे नीचे मौजूद नए फ़्रेम में खुलता है. इसमें कमांड-लाइन प्रॉम्प्ट दिखता है. जब तक user@project:~$ प्रॉम्प्ट न दिखे, तब तक इंतज़ार करें
हम Vision API को अनुरोध भेजने के लिए curl का इस्तेमाल करेंगे. इसलिए, हमें एक एपीआई पासकोड जनरेट करना होगा, ताकि हम उसे अपने अनुरोध वाले यूआरएल में पास कर सकें. एपीआई पासकोड बनाने के लिए, अपने Cloud Console में एपीआई और सेवाओं के क्रेडेंशियल सेक्शन पर जाएं:
ड्रॉप-डाउन मेन्यू में, एपीआई पासकोड चुनें:
इसके बाद, अभी जनरेट की गई कुंजी को कॉपी करें.
अब आपके पास एपीआई पासकोड है. इसे एनवायरमेंट वैरिएबल में सेव करें, ताकि आपको हर अनुरोध में एपीआई पासकोड की वैल्यू न डालनी पड़े. यह काम Cloud Shell में किया जा सकता है. <your_api_key> की जगह, अभी कॉपी की गई कुंजी का इस्तेमाल करना न भूलें.
export API_KEY=<YOUR_API_KEY>Cloud Storage बकेट बनाना
इमेज का पता लगाने के लिए, Vision API को इमेज भेजने के दो तरीके हैं: एपीआई को base64 एन्कोड की गई इमेज स्ट्रिंग भेजकर या Google Cloud Storage में सेव की गई फ़ाइल का यूआरएल पास करके. हम Cloud Storage यूआरएल का इस्तेमाल करेंगे. हम अपनी इमेज सेव करने के लिए, Google Cloud Storage बकेट बनाएंगे.
अपने प्रोजेक्ट के लिए, Cloud Console में स्टोरेज ब्राउज़र पर जाएं:
इसके बाद, बकेट बनाएं पर क्लिक करें. अपने बकेट को कोई यूनीक नाम दें. जैसे, प्रोजेक्ट आईडी. इसके बाद, बनाएं पर क्लिक करें.
अपनी बकेट में कोई इमेज अपलोड करना
डोनट की इस इमेज पर राइट क्लिक करें. इसके बाद, इमेज को इस तरह सेव करें पर क्लिक करें. अब इसे अपने डाउनलोड फ़ोल्डर में donuts.png के तौर पर सेव करें.

स्टोरेज ब्राउज़र में, अभी-अभी बनाए गए बकेट पर जाएं. इसके बाद, फ़ाइलें अपलोड करें पर क्लिक करें. इसके बाद, donuts.png चुनें.
आपको अपनी फ़ाइल, बकेट में दिखनी चाहिए:

इसके बाद, इमेज की अनुमति में बदलाव करें.
आइटम जोड़ें पर क्लिक करें.
Group की नई इकाई और allUsers का नाम जोड़ें:
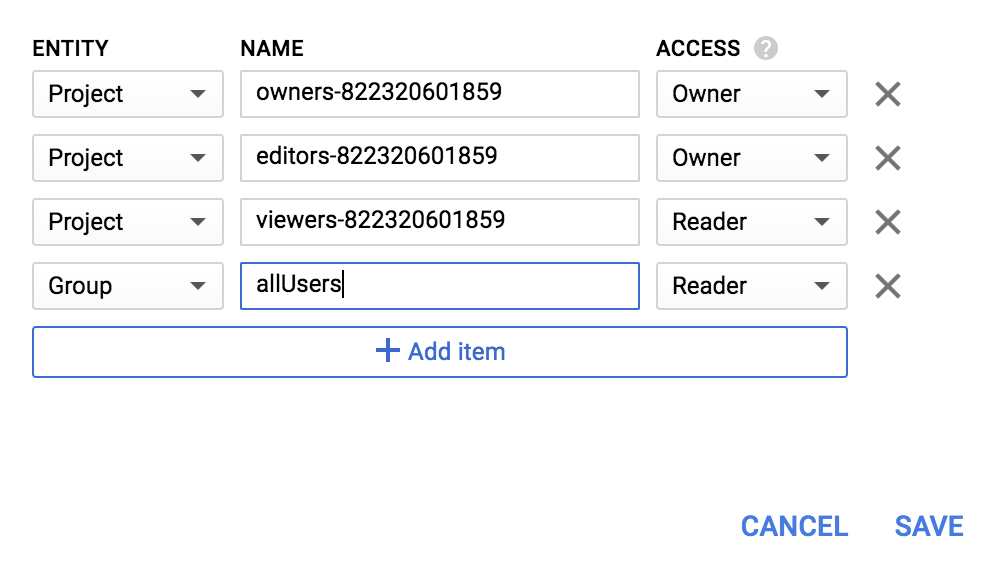
सेव करें पर क्लिक करें.
अब आपके पास फ़ाइल आपके बकेट में है. अब Vision API का अनुरोध किया जा सकता है. इसके लिए, आपको इस डोनट की तस्वीर का यूआरएल पास करना होगा.
अपने Cloud Shell एनवायरमेंट में, नीचे दिए गए कोड के साथ एक request.json फ़ाइल बनाएं. साथ ही, यह पक्का करें कि आपने my-bucket-name को उस Cloud Storage बकेट के नाम से बदल दिया हो जिसे आपने बनाया है. फ़ाइल बनाने के लिए, अपनी पसंद के कमांड लाइन एडिटर (nano, vim, emacs) में से किसी एक का इस्तेमाल करें. इसके अलावा, Cloud Shell में मौजूद Orion एडिटर का भी इस्तेमाल किया जा सकता है:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "LABEL_DETECTION",
"maxResults": 10
}
]
}
]
}Cloud Vision API की जिस सुविधा के बारे में हम सबसे पहले जानेंगे वह है लेबल का पता लगाना. इस तरीके से, आपको इमेज में मौजूद चीज़ों के लेबल (शब्द) की सूची मिलेगी.
अब हम curl की मदद से Vision API को कॉल करने के लिए तैयार हैं:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}आपका जवाब कुछ ऐसा दिखना चाहिए:
{
"responses": [
{
"labelAnnotations": [
{
"mid": "/m/01dk8s",
"description": "powdered sugar",
"score": 0.9436922
},
{
"mid": "/m/01wydv",
"description": "beignet",
"score": 0.7160288
},
{
"mid": "/m/06_dn",
"description": "snow",
"score": 0.71219236
},
{
"mid": "/m/02wvn_6",
"mid": "/m/0bp3f6m",
"description": "fried food",
"score": 0.7075312
},
{
"mid": "/m/02wvn_6",
"description": "ricciarelli",
"score": 0.5625
},
{
"mid": "/m/052lwg6",
"description": "baked goods",
"score": 0.53270763
}
]
}
]
}एपीआई ने यह पहचान कर ली कि ये किस तरह के डोनट हैं (बेग्नेट), बहुत बढ़िया! Vision API को मिले हर लेबल के लिए, यह आइटम के नाम के साथ description दिखाता है. यह score भी दिखाता है. यह 0 से 100 तक की एक संख्या होती है. इससे पता चलता है कि इमेज में मौजूद कॉन्टेंट से ब्यौरा कितना मेल खाता है. mid वैल्यू, Google के नॉलेज ग्राफ़ में मौजूद आइटम के मिड से मैप होती है. किसी आइटम के बारे में ज़्यादा जानकारी पाने के लिए, Knowledge Graph API को कॉल करते समय mid का इस्तेमाल किया जा सकता है.
Vision API, हमारी इमेज में मौजूद चीज़ों के बारे में लेबल पाने के साथ-साथ, इंटरनेट पर हमारी इमेज के बारे में ज़्यादा जानकारी भी खोज सकता है. एपीआई के webDetection तरीके से, हमें कई तरह का दिलचस्प डेटा मिलता है:
- हमारी इमेज में मिली इकाइयों की सूची. यह सूची, मिलती-जुलती इमेज वाले पेजों के कॉन्टेंट के आधार पर बनाई जाती है
- वेब पर मिली, पूरी तरह और कुछ हद तक मिलती-जुलती इमेज के यूआरएल. साथ ही, उन पेजों के यूआरएल
- मिलती-जुलती इमेज के यूआरएल. जैसे, इमेज के ज़रिए मिलती-जुलती इमेज की खोज करना
वेब पर मौजूद कॉन्टेंट का पता लगाने की सुविधा को आज़माने के लिए, हम ऊपर दी गई बेन्ये की इमेज का इस्तेमाल करेंगे. इसलिए, हमें अपनी request.json फ़ाइल में सिर्फ़ एक लाइन बदलनी होगी. आपके पास यह विकल्प भी है कि आप कोई दूसरी इमेज इस्तेमाल करें. सुविधाओं की सूची में जाकर, टाइप को LABEL_DETECTION से बदलकर WEB_DETECTION करें. request.json अब ऐसा दिखना चाहिए:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/donuts.png"
}
},
"features": [
{
"type": "WEB_DETECTION",
"maxResults": 10
}
]
}
]
}इसे Vision API पर भेजने के लिए, पहले वाली curl कमांड का इस्तेमाल किया जा सकता है. इसके लिए, Cloud Shell में सिर्फ़ ऊपर वाले ऐरो को दबाएं:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}चलिए, webEntities से शुरू करके जवाब के बारे में जानते हैं. इस इमेज से मिली कुछ इकाइयां यहां दी गई हैं:
"webEntities": [
{
"entityId": "/m/01hyh_",
"score": 0.7155,
"description": "Machine learning"
},
{
"entityId": "/m/01wydv",
"score": 0.48758492,
"description": "Beignet"
},
{
"entityId": "/m/0105pbj4",
"score": 0.3976,
"description": "Google Cloud Platform"
},
{
"entityId": "/m/02y_9m3",
"score": 0.3782,
"description": "Cloud computing"
},
...
]
इस इमेज का फिर से इस्तेमाल, Cloud ML API से जुड़े कई प्रज़ेंटेशन में किया गया है. इसलिए, एपीआई को "मशीन लर्निंग", "Google Cloud Platform", और "क्लाउड कंप्यूटिंग" जैसी इकाइयां मिलीं.
अगर हम fullMatchingImages, partialMatchingImages, और pagesWithMatchingImages में दिए गए यूआरएल की जांच करें, तो हमें पता चलेगा कि इनमें से कई यूआरएल, इस कोडलैब साइट पर ले जाते हैं (सुपर मेटा!).
मान लें कि हमें बेन्ये की अन्य इमेज ढूंढनी हैं, लेकिन हमें ठीक वैसी ही इमेज नहीं चाहिए. ऐसे में, एपीआई से मिले जवाब का visuallySimilarImages हिस्सा काम आता है. यहाँ मिलती-जुलती कुछ इमेज दी गई हैं:
"visuallySimilarImages": [
{
"url": "https://igx.4sqi.net/img/general/558x200/21646809_fe8K-bZGnLLqWQeWruymGEhDGfyl-6HSouI2BFPGh8o.jpg"
},
{
"url": "https://spoilednyc.com//2016/02/16/beignetszzzzzz-852.jpg"
},
{
"url": "https://img-global.cpcdn.com/001_recipes/a66a9a6fc2696648/1200x630cq70/photo.jpg"
},
...
]हम मिलती-जुलती इमेज देखने के लिए, इन यूआरएल पर जा सकते हैं:




कूल! अब शायद आपको बेन्ये खाने का मन कर रहा होगा (माफ़ करें). यह Google Images पर इमेज की मदद से खोजने जैसा है:
हालांकि, Cloud Vision की मदद से, हम इस सुविधा को आसानी से इस्तेमाल किए जा सकने वाले REST API के ज़रिए ऐक्सेस कर सकते हैं. साथ ही, इसे अपने ऐप्लिकेशन में इंटिग्रेट कर सकते हैं.
इसके बाद, हम Vision API के चेहरे और लैंडमार्क का पता लगाने के तरीकों के बारे में जानेंगे. चेहरे की पहचान करने की सुविधा, किसी इमेज में मौजूद चेहरों का डेटा दिखाती है. इसमें चेहरों के भाव और इमेज में उनकी जगह की जानकारी शामिल होती है. लैंडमार्क की पहचान करने की सुविधा, सामान्य और कम जाने-पहचाने लैंडमार्क की पहचान कर सकती है. यह लैंडमार्क का नाम, उसके अक्षांश और देशांतर के निर्देशांक, और इमेज में लैंडमार्क की पहचान की गई जगह की जानकारी देती है.
नई इमेज अपलोड करना
इन दोनों नए तरीकों का इस्तेमाल करने के लिए, आइए हम अपने Cloud Storage बकेट में चेहरों और लैंडमार्क वाली एक नई इमेज अपलोड करें. नीचे दी गई इमेज पर राइट क्लिक करें. इसके बाद, इमेज इस रूप में सेव करें पर क्लिक करें और इसे अपने डाउनलोड फ़ोल्डर में selfie.png के तौर पर सेव करें.

इसके बाद, इसे Cloud Storage बकेट में उसी तरह अपलोड करें जिस तरह आपने पिछले चरण में किया था. साथ ही, यह पक्का करें कि आपने "सार्वजनिक तौर पर शेयर करें" चेकबॉक्स पर सही का निशान लगाया हो.
अनुरोध अपडेट करना
इसके बाद, हम अपनी request.json फ़ाइल को अपडेट करेंगे, ताकि नई इमेज का यूआरएल शामिल किया जा सके. साथ ही, लेबल की पहचान करने के बजाय चेहरे और लैंडमार्क की पहचान करने की सुविधा का इस्तेमाल किया जा सके. my-bucket-name की जगह, Cloud Storage बकेट का नाम डालना न भूलें:
request.json
{
"requests": [
{
"image": {
"source": {
"gcsImageUri": "gs://my-bucket-name/selfie.png"
}
},
"features": [
{
"type": "FACE_DETECTION"
},
{
"type": "LANDMARK_DETECTION"
}
]
}
]
}Vision API को कॉल करना और रिस्पॉन्स को पार्स करना
अब ऊपर इस्तेमाल की गई curl कमांड का इस्तेमाल करके, Vision API को कॉल किया जा सकता है:
curl -s -X POST -H "Content-Type: application/json" --data-binary @request.json https://vision.googleapis.com/v1/images:annotate?key=${API_KEY}आइए, सबसे पहले जवाब में मौजूद faceAnnotations ऑब्जेक्ट पर एक नज़र डालें. आपको दिखेगा कि एपीआई, इमेज में मिले हर चेहरे के लिए एक ऑब्जेक्ट दिखाता है. इस मामले में, तीन ऑब्जेक्ट दिखाए गए हैं. हमारे जवाब का छोटा वर्शन यहां दिया गया है:
{
"faceAnnotations": [
{
"boundingPoly": {
"vertices": [
{
"x": 669,
"y": 324
},
...
]
},
"fdBoundingPoly": {
...
},
"landmarks": [
{
"type": "LEFT_EYE",
"position": {
"x": 692.05646,
"y": 372.95868,
"z": -0.00025268539
}
},
...
],
"rollAngle": 0.21619819,
"panAngle": -23.027969,
"tiltAngle": -1.5531756,
"detectionConfidence": 0.72354823,
"landmarkingConfidence": 0.20047489,
"joyLikelihood": "POSSIBLE",
"sorrowLikelihood": "VERY_UNLIKELY",
"angerLikelihood": "VERY_UNLIKELY",
"surpriseLikelihood": "VERY_UNLIKELY",
"underExposedLikelihood": "VERY_UNLIKELY",
"blurredLikelihood": "VERY_UNLIKELY",
"headwearLikelihood": "VERY_LIKELY"
}
...
}
}boundingPoly हमें इमेज में चेहरे के आस-पास के x,y कोऑर्डिनेट देता है. fdBoundingPoly, boundingPoly से छोटा बॉक्स है. यह चेहरे की त्वचा वाले हिस्से पर दिखता है. landmarks, चेहरे की हर सुविधा के लिए ऑब्जेक्ट का एक कलेक्शन है. इनमें से कुछ के बारे में आपको शायद पता भी न हो! इससे हमें लैंडमार्क के टाइप के साथ-साथ, उस सुविधा की 3D पोज़िशन (x,y,z कोऑर्डिनेट) के बारे में पता चलता है. इसमें z कोऑर्डिनेट गहराई होती है. बची हुई वैल्यू से हमें चेहरे के बारे में ज़्यादा जानकारी मिलती है. जैसे, खुशी, दुख, गुस्सा, और हैरानी की संभावना. ऊपर दिया गया ऑब्जेक्ट, इमेज में सबसे पीछे खड़े व्यक्ति के लिए है. आप देख सकते हैं कि वह कुछ अजीब सा चेहरा बना रहा है. इससे POSSIBLE के joyLikelihood के बारे में पता चलता है.
अब हम अपने जवाब के landmarkAnnotations हिस्से को देखते हैं:
"landmarkAnnotations": [
{
"mid": "/m/0c7zy",
"description": "Petra",
"score": 0.5403372,
"boundingPoly": {
"vertices": [
{
"x": 153,
"y": 64
},
...
]
},
"locations": [
{
"latLng": {
"latitude": 30.323975,
"longitude": 35.449361
}
}
]यहां Vision API ने यह पता लगा लिया कि यह फ़ोटो पेट्रा में ली गई है. इस इमेज में विज़ुअल क्लू बहुत कम हैं. इसलिए, यह काफ़ी शानदार है. इस जवाब में दी गई वैल्यू, ऊपर दिए गए labelAnnotations जवाब में दी गई वैल्यू से मिलती-जुलती होनी चाहिए.
हमें लैंडमार्क की mid, उसका नाम (description), और कॉन्फ़िडेंस score मिलता है. boundingPoly इमेज में उस जगह को दिखाता है जहां लैंडमार्क की पहचान की गई थी. locations कुंजी से हमें इस लैंडमार्क के अक्षांश और देशांतर निर्देशांकों के बारे में पता चलता है.
हमने Vision API के लेबल, चेहरे, और लैंडमार्क की पहचान करने के तरीकों की जांच की है. हालांकि, तीन अन्य तरीकों की जांच नहीं की गई है. अन्य तीन के बारे में जानने के लिए, दस्तावेज़ पढ़ें:
- लोगो का पता लगाना: किसी इमेज में मौजूद सामान्य लोगो और उनकी जगह का पता लगाना.
- सेफ़ सर्च की सुविधा: यह पता लगाना कि किसी इमेज में अश्लील कॉन्टेंट है या नहीं. यह यूज़र जनरेटेड कॉन्टेंट वाले किसी भी ऐप्लिकेशन के लिए फ़ायदेमंद है. इमेज को चार आधार पर फ़िल्टर किया जा सकता है: वयस्कों के लिए बना कॉन्टेंट, मेडिकल कॉन्टेंट, हिंसक कॉन्टेंट, और नकली कॉन्टेंट.
- टेक्स्ट का पता लगाना: इमेज से टेक्स्ट निकालने के लिए, ओसीआर चलाएं. इस तरीके से, किसी इमेज में मौजूद टेक्स्ट की भाषा का भी पता लगाया जा सकता है.
आपने Vision API की मदद से इमेज का विश्लेषण करने का तरीका जान लिया है. इस उदाहरण में, आपने एपीआई को अपनी इमेज का Google Cloud Storage यूआरएल दिया है. इसके अलावा, आपके पास अपनी इमेज की base64 कोड में बदली गई स्ट्रिंग पास करने का विकल्प भी है.
हमने क्या-क्या बताया
- Cloud Storage बकेट में मौजूद किसी इमेज का यूआरएल पास करके, कर्ल की मदद से Vision API को कॉल करना
- Vision API के लेबल, वेब, चेहरे, और लैंडमार्क की पहचान करने के तरीकों का इस्तेमाल करना
अगले चरण
- दस्तावेज़ में, Vision API के ट्यूटोरियल देखें
- अपनी पसंदीदा भाषा में Vision API का सैंपल ढूंढना
- Speech API और Natural Language API कोडलैब आज़माएं!