

この Codelab では、手書きの数字を認識するニューラル ネットワークを構築してトレーニングする方法を学びます。99% の精度を達成するためにニューラル ネットワークを強化する過程で、ディープ ラーニングの専門家がモデルを効率的にトレーニングするために使用するツールについても学びます。
この Codelab では、MNIST データセットを使用します。これは、60,000 個のラベル付き数字のコレクションで、20 年近くにわたって多くの博士課程の学生を忙しくさせてきました。この問題を 100 行未満の Python / TensorFlow コードで解決します。
学習内容
- ニューラル ネットワークとは何か、そのトレーニング方法
- tf.keras を使用して基本的な 1 レイヤのニューラル ネットワークを構築する方法
- レイヤを追加する方法
- 学習率のスケジュールを設定する方法
- 畳み込みニューラル ネットワークの構築方法
- 正則化手法(ドロップアウト、バッチ正規化)の使用方法
- 過学習とは
必要なもの
ブラウザだけです。このワークショップは、Google Colaboratory で完全に実行できます。
フィードバック
このラボで不具合が見つかった場合や、改善すべき点があると思われる場合は、お知らせください。フィードバックは GitHub の問題 [フィードバック リンク] を通じて処理されます。
このラボでは Google Colaboratory を使用するため、ユーザー側での設定は不要です。Chromebook から実行できます。以下のファイルを開き、セルを実行して Colab ノートブックに慣れてください。

以下の追加の手順をご確認ください。
GPU バックエンドを選択する

Colab のメニューで、[ランタイム] > [ランタイムのタイプを変更] を選択し、[GPU] を選択します。ランタイムへの接続は、初回実行時に自動的に行われます。右上にある [接続] ボタンを使用することもできます。
ノートブックの実行

セルを 1 つずつ実行するには、セルをクリックして Shift+Enter キーを押します。[ランタイム] > [すべて実行] を選択して、ノートブック全体を実行することもできます。
目次

すべてのノートブックに目次があります。左側の黒い矢印を使用して開くことができます。
非表示のセル

一部のセルにはタイトルのみが表示されます。これは Colab 固有のノートブック機能です。ダブルクリックすると内部のコードを確認できますが、通常はあまり興味深いものではありません。通常はサポート関数または可視化関数。内部の関数を定義するには、これらのセルを実行する必要があります。
まず、ニューラル ネットワークのトレーニングを見てみましょう。以下のノートブックを開き、すべてのセルを実行してください。コードについては、後で説明しますので、まだ気にしないでください。
ノートブックを実行するときは、可視化に注目してください。説明については、以下をご覧ください。
トレーニング データ
手書きの数字のデータセットがあり、各画像が何を表しているか(0 ~ 9 の数字)がわかるようにラベル付けされています。ノートブックに、次のような抜粋が表示されます。
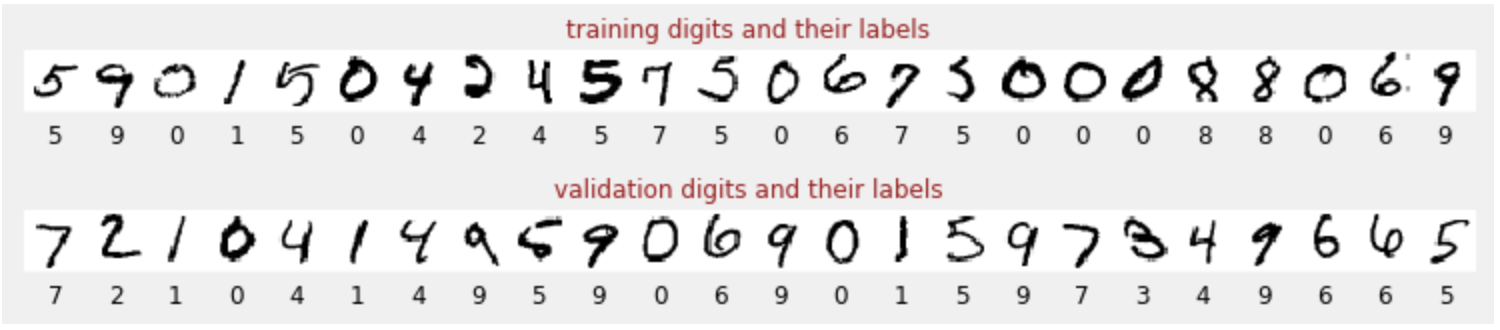
構築するニューラル ネットワークは、手書きの数字を 10 個のクラス(0 ~ 9)に分類します。これは、分類が適切に機能するために正しい値が必要な内部パラメータに基づいて行われます。この「正しい値」は、画像と関連する正解を含む「ラベル付きデータセット」を必要とするトレーニング プロセスを通じて学習されます。
トレーニング済みのニューラル ネットワークのパフォーマンスを評価するにはどうすればよいですか?トレーニング データセットを使用してネットワークをテストすることは不正行為になります。このデータセットはトレーニング中に何度も使用されているため、このデータセットに対するパフォーマンスは非常に高いはずです。ネットワークの「実環境」でのパフォーマンスを評価するには、トレーニング中に使用されていない別のラベル付きデータセットが必要です。これは「検証データセット」と呼ばれます。
トレーニング
トレーニングが進むにつれて、トレーニング データの 1 つのバッチずつ、内部モデル パラメータが更新され、モデルは手書きの数字を認識する能力が向上していきます。トレーニング グラフで確認できます。
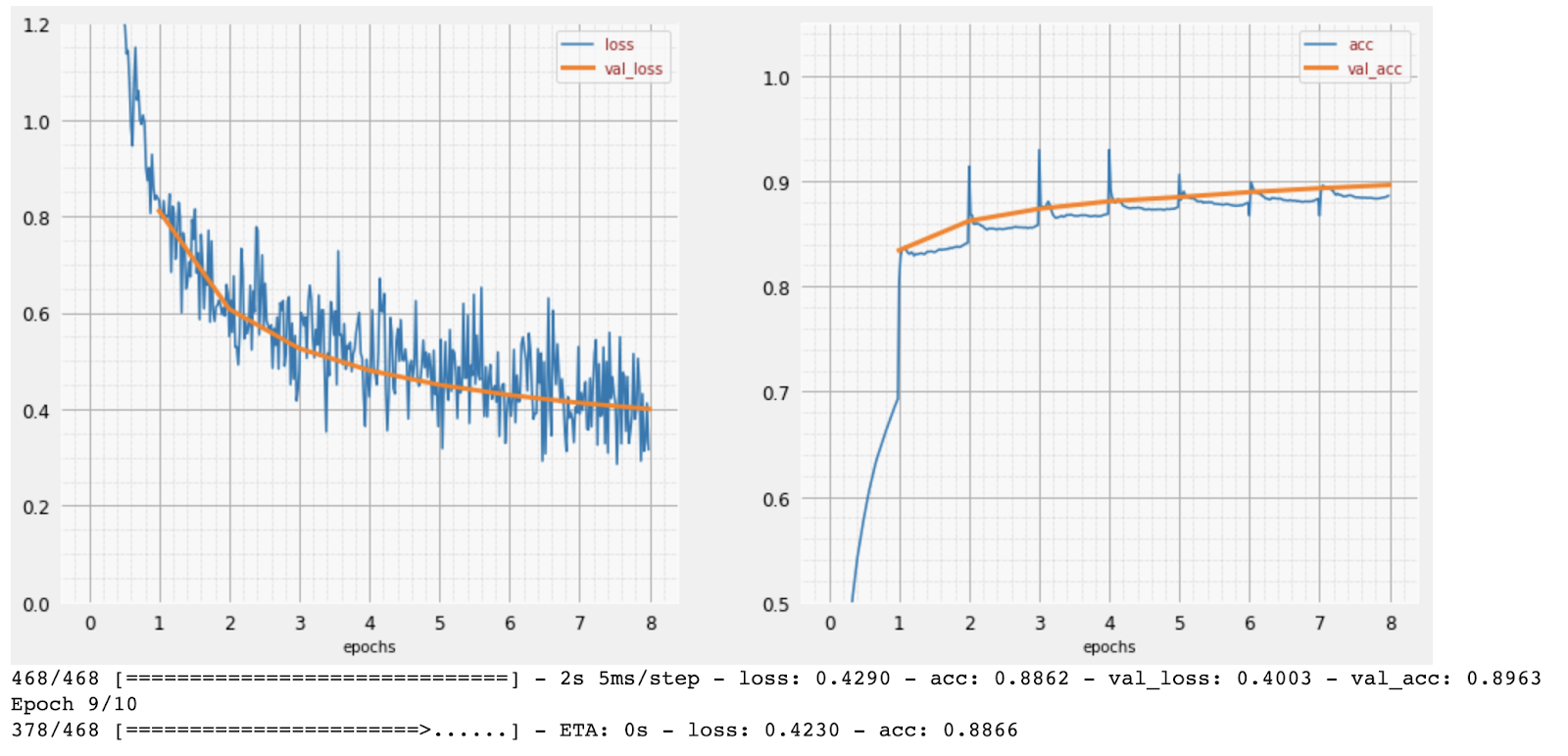
右側の「精度」は、正しく認識された数字の割合です。トレーニングが進むにつれて増加するため、これは望ましい傾向です。
左側には損失が表示されます。トレーニングを推進するために、「損失」関数を定義します。これは、システムが数字をどの程度認識しているかを表すもので、最小化を試みます。ここでわかるのは、トレーニングが進むにつれて、トレーニング データと検証データの両方で損失が減少していることです。これは良いことです。これは、ニューラル ネットワークが学習していることを意味します。
X 軸は、データセット全体に対する「エポック」または反復の数を表します。
予測
モデルのトレーニングが完了したら、そのモデルを使用して手書きの数字を認識できます。次の可視化は、ローカル フォントからレンダリングされた数桁(1 行目)と、検証データセットの 10,000 桁でどの程度パフォーマンスを発揮するかを示しています。予測されたクラスは各数字の下に表示されます。間違っていた場合は赤色で表示されます。

ご覧のとおり、この初期モデルはあまり優れていませんが、一部の数字は正しく認識しています。最終的な検証精度は約 90% です。これは、最初に作成した単純なモデルとしては悪くありませんが、10, 000 個の検証数字のうち 1,000 個が欠落していることを意味します。表示できる数よりもはるかに多いため、すべての回答が不正解(赤)に見えます。
テンソル
データは行列に保存されます。28 x 28 ピクセルのグレースケール画像は、28 x 28 の 2 次元行列に収まります。しかし、カラー画像の場合、より多くの次元が必要です。ピクセルごとに 3 つの色値(赤、緑、青)があるため、[28, 28, 3] の次元を持つ 3 次元テーブルが必要になります。128 個のカラー画像のバッチを保存するには、[128, 28, 28, 3] の 4 次元テーブルが必要です。
これらの多次元テーブルは「テンソル」と呼ばれ、ディメンションのリストは「シェイプ」と呼ばれます。
概要
次の段落の太字の用語をすべてご存知の場合は、次の演習に進んでください。ディープ ラーニングを始めたばかりの方は、ぜひこのままお読みください。

レイヤのシーケンスとして構築されたモデルの場合、Keras は Sequential API を提供します。たとえば、3 つの密なレイヤを使用する画像分類器は、Keras で次のように記述できます。
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
単一の密レイヤ
MNIST データセットの手書き数字は、28 x 28 ピクセルのグレースケール画像です。これらを分類する最も簡単な方法は、28×28=784 ピクセルを 1 層のニューラル ネットワークの入力として使用することです。
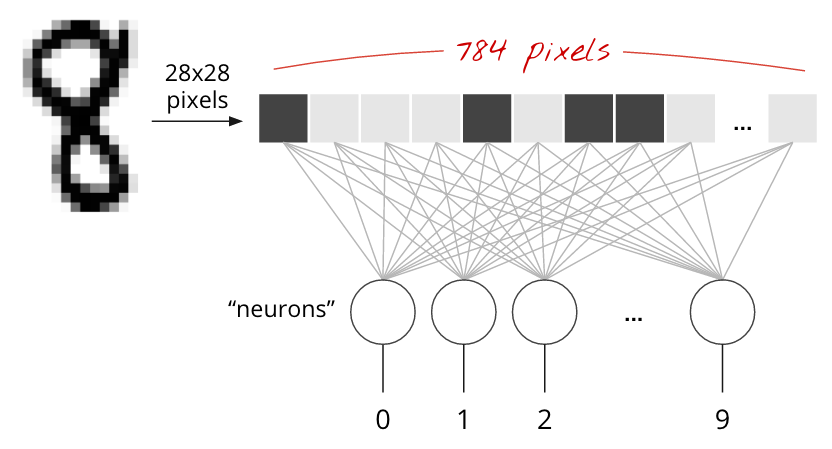
ニューラル ネットワークの各「ニューロン」は、すべての入力の加重和を計算し、「バイアス」と呼ばれる定数を追加して、非線形の「活性化関数」を介して結果を渡します。「重み」と「バイアス」は、トレーニングによって決定されるパラメータです。最初はランダムな値で初期化されます。
上の図は、数字を 10 個のクラス(0 ~ 9)に分類するため、10 個の出力ニューロンを持つ 1 層のニューラル ネットワークを表しています。
行列の乗算を使用する
一連の画像を処理するニューラル ネットワーク レイヤは、次のように行列乗算で表すことができます。
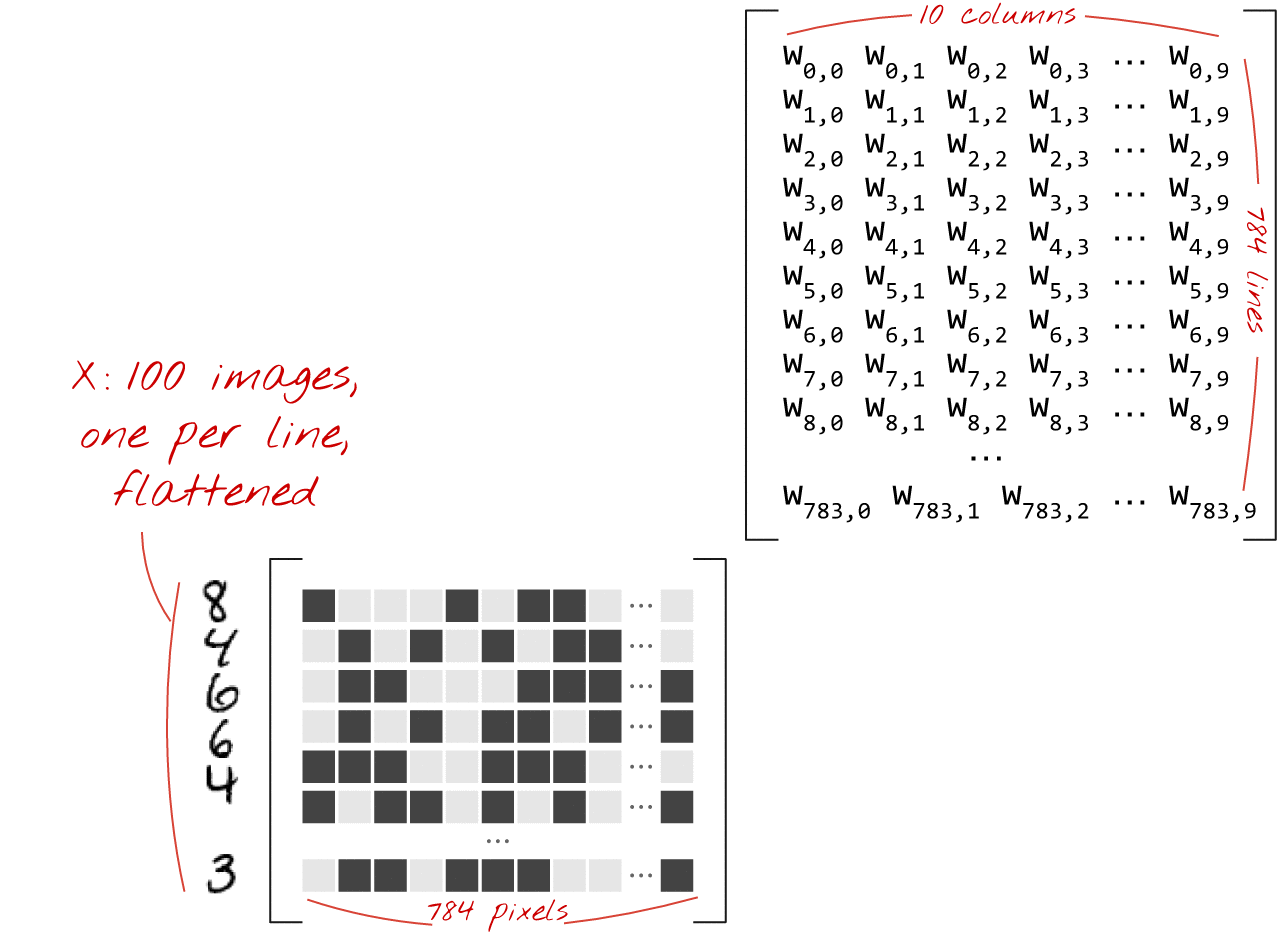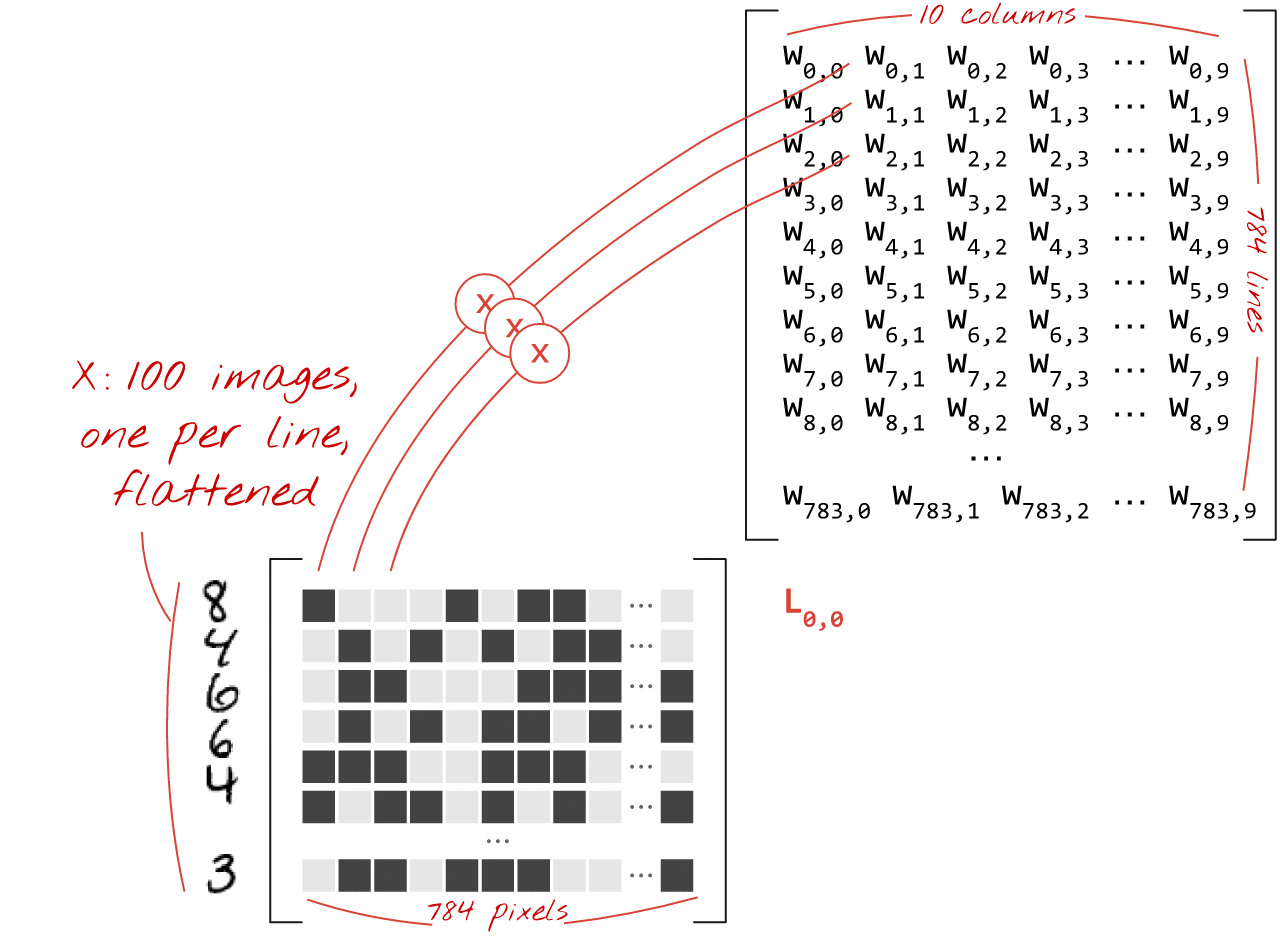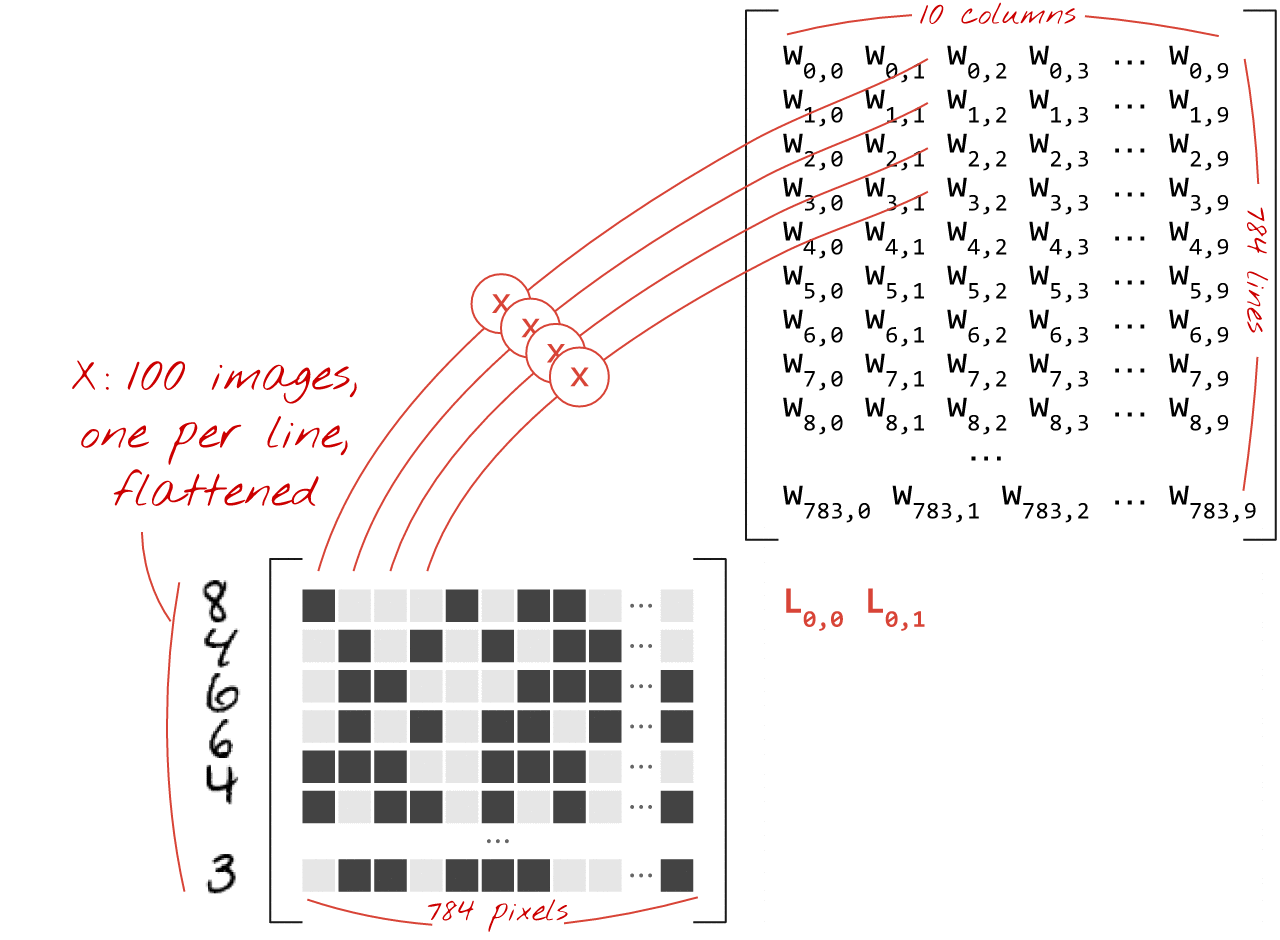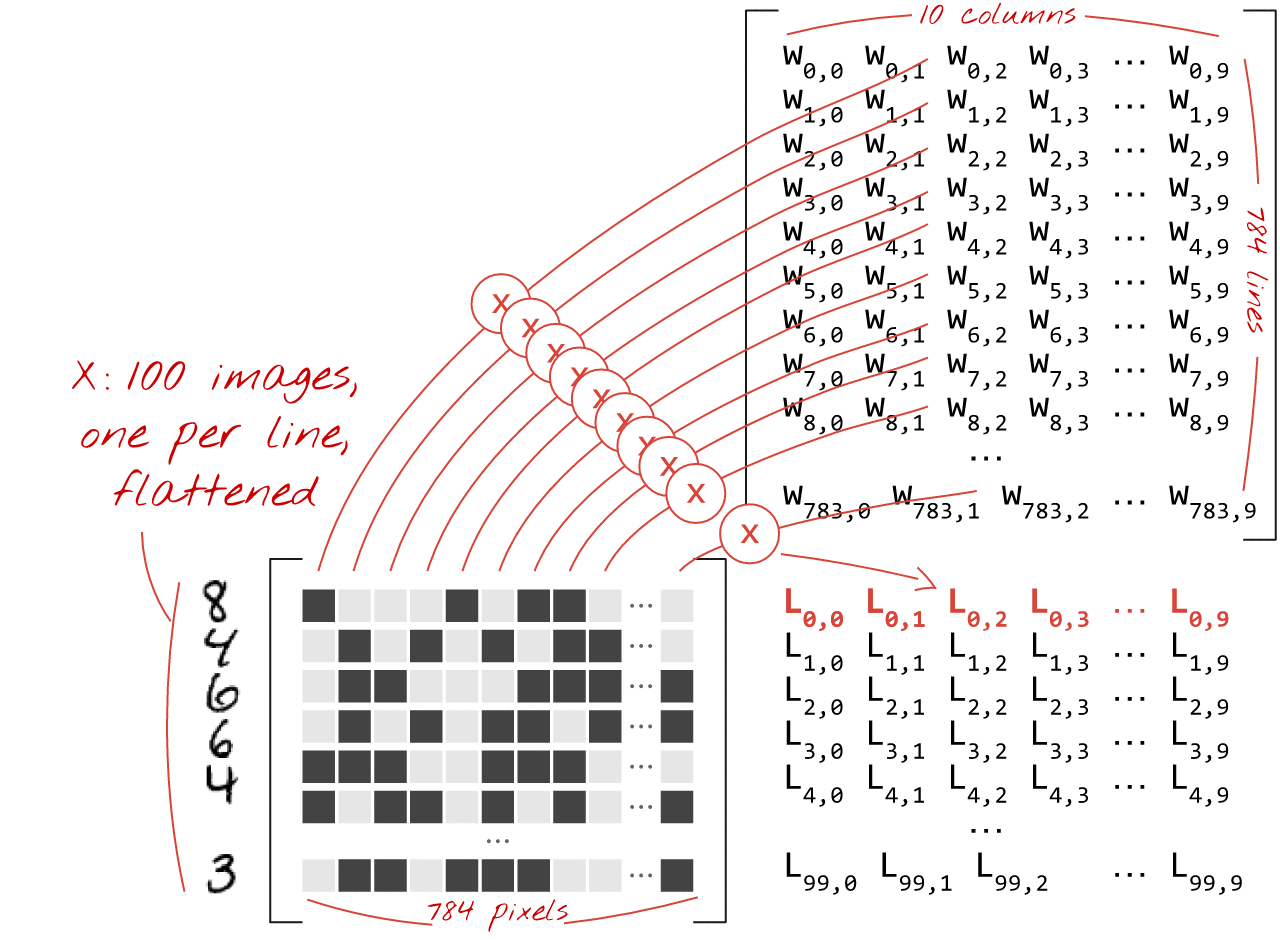
重み行列 W の最初の列の重みを使用して、最初の画像のすべてのピクセルの重み付き合計を計算します。この合計は最初のニューロンに対応します。重みの 2 番目の列を使用して、2 番目のニューロンについても同様の処理を行います。これを 10 番目のニューロンまで繰り返します。残りの 99 枚の画像についても同様の操作を繰り返します。100 個の画像を含む行列を X とすると、100 個の画像で計算された 10 個のニューロンのすべての重み付き合計は、単に行列乗算 X.W になります。
各ニューロンは、バイアス(定数)を追加する必要があります。ニューロンが 10 個あるため、バイアス定数は 10 個あります。この 10 個の値のベクトルを b と呼びます。これは、以前に計算された行列の各行に追加する必要があります。「ブロードキャスト」という魔法を使って、これを単純なプラス記号で記述します。
最後に、活性化関数(たとえば「softmax」(後述))を適用し、100 枚の画像に適用された 1 層のニューラル ネットワークを記述する数式を取得します。
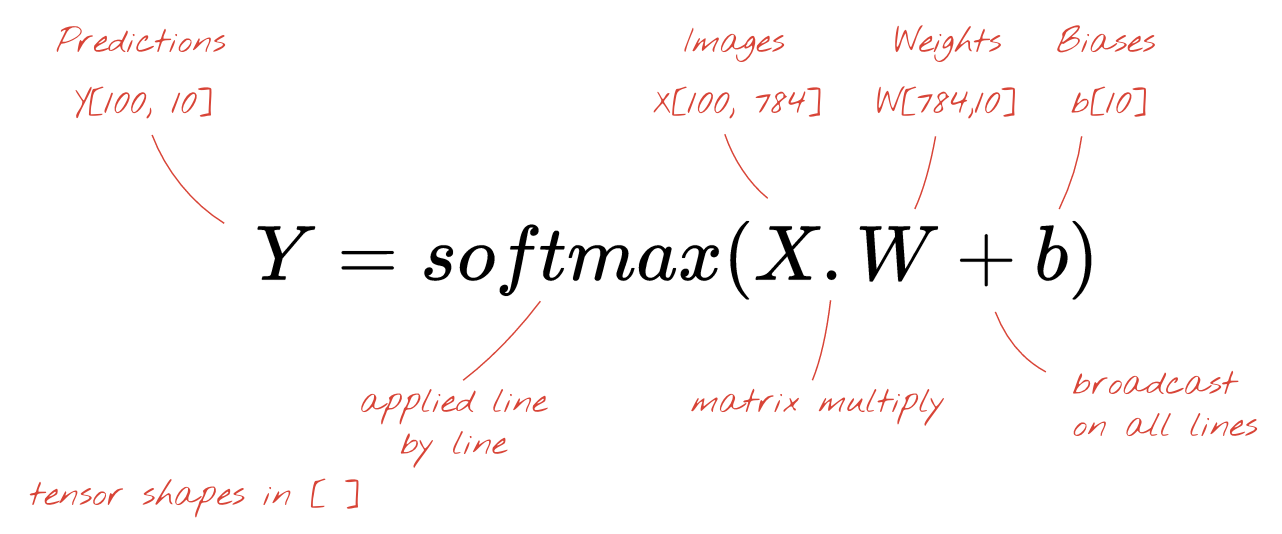
Keras の場合
Keras などのハイレベルのニューラル ネットワーク ライブラリを使用すると、この式を実装する必要はありません。ただし、ニューラル ネットワークのレイヤは単なる乗算と加算の集まりであることを理解しておくことが重要です。Keras では、密結合レイヤは次のように記述されます。
tf.keras.layers.Dense(10, activation='softmax')深く掘り下げる
ニューラル ネットワーク レイヤのチェーンは簡単です。最初のレイヤは、ピクセルの加重合計を計算します。後続のレイヤは、前のレイヤの出力の加重和を計算します。
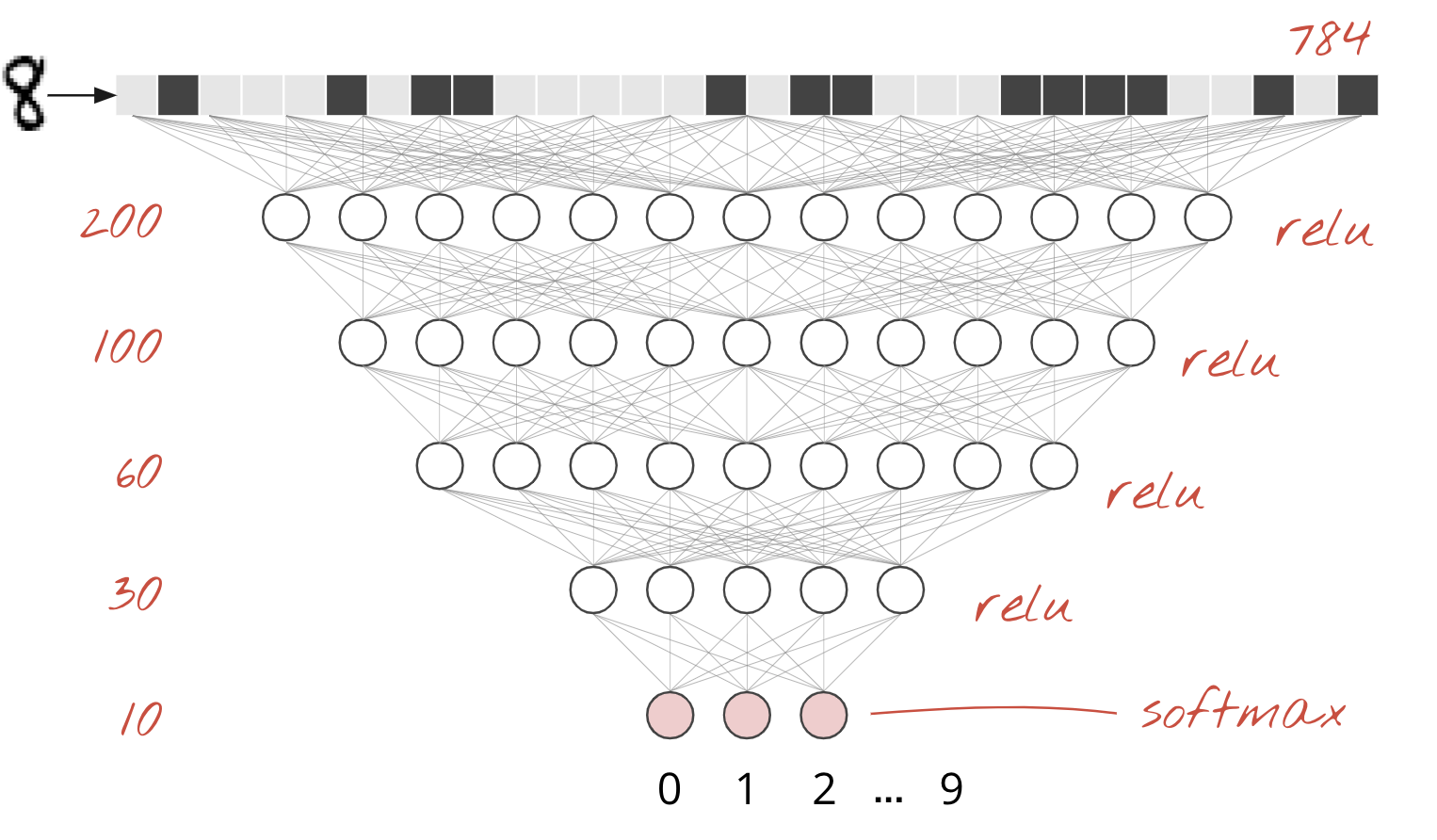
ニューロンの数を除いて、唯一の違いは活性化関数の選択です。
活性化関数: relu、softmax、sigmoid
通常は、最後のレイヤを除くすべてのレイヤに "relu" 活性化関数を使用します。分類器の最後のレイヤでは、"softmax" 活性化が使用されます。
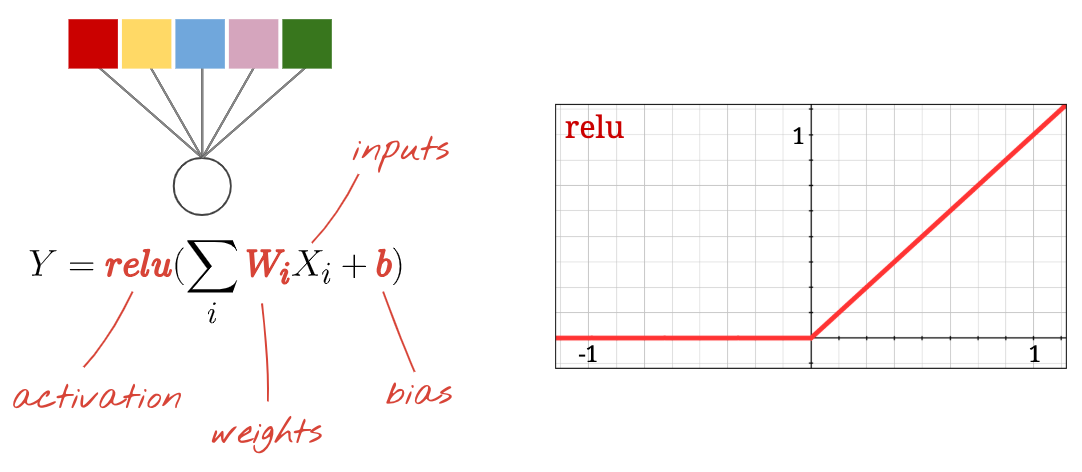
ここでも、「ニューロン」はすべての入力の加重和を計算し、「バイアス」と呼ばれる値を加えて、活性化関数を介して結果を渡します。
最も一般的な活性化関数は、正規化線形ユニットの「RELU」と呼ばれます。上のグラフでわかるように、非常にシンプルな関数です。
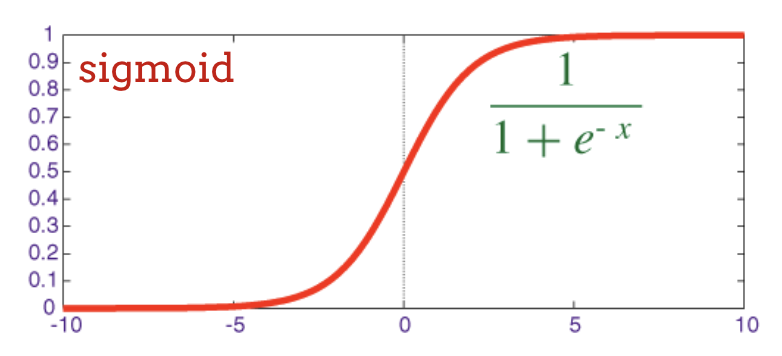
ニューラル ネットワークの従来の活性化関数は「シグモイド」でしたが、「relu」はほぼすべての場所で収束特性が優れていることが示され、現在では好まれています。
分類用のソフトマックス活性化関数
手書きの数字を 10 個のクラス(0 ~ 9)に分類するため、ニューラル ネットワークの最後のレイヤには 10 個のニューロンがあります。この数字が 0、1、2 などである確率を表す 0 ~ 1 の 10 個の数値を出力する必要があります。このため、最後のレイヤでは "softmax" という活性化関数を使用します。
ベクトルに softmax を適用するには、各要素の指数関数を取り、ベクトルを正規化します。通常は、正規化された値の合計が 1 になり、確率として解釈できるように、L1 ノルム(絶対値の合計)で除算します。
活性化前の最後のレイヤの出力は、「ロジット」と呼ばれることがあります。このベクトルが L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9] の場合、次のようになります。
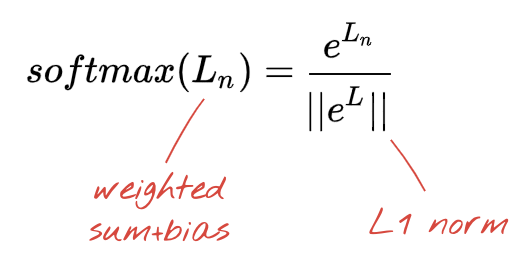
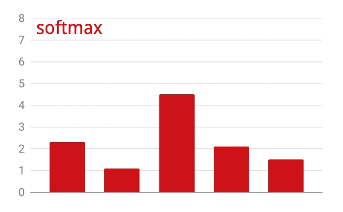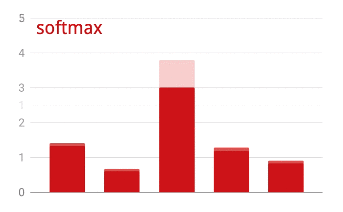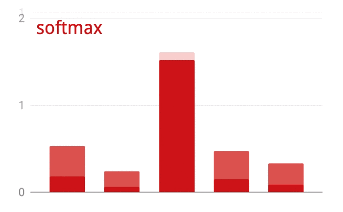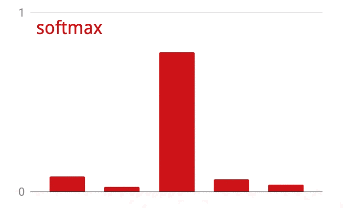
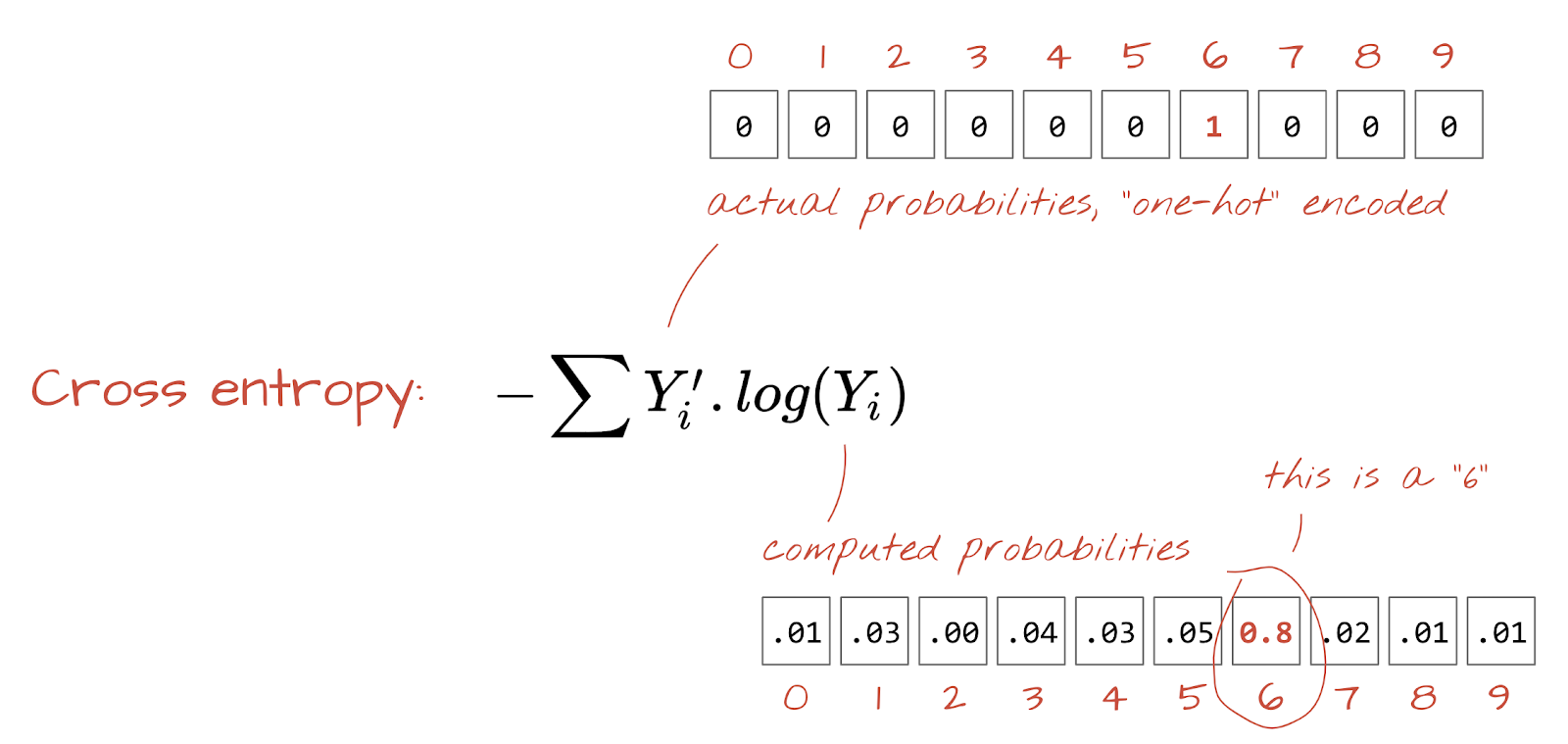
交差エントロピー損失
ニューラル ネットワークが入力画像から予測を生成するようになったので、その予測の精度を測定する必要があります。つまり、ネットワークが示す内容と正解(ラベルと呼ばれることが多い)との距離を測定します。データセット内のすべての画像に正しいラベルが付いていることを思い出してください。
どの距離でも機能しますが、分類問題では「交差エントロピー距離」が最も効果的です。これをエラー関数または損失関数と呼びます。
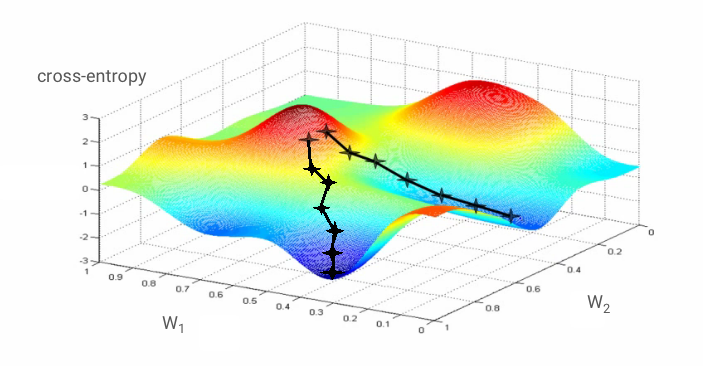
勾配降下法
ニューラル ネットワークの「トレーニング」とは、実際には、トレーニング画像とラベルを使用して、交差エントロピー損失関数を最小限に抑えるように重みとバイアスを調整することを意味します。仕組みは次のとおりです。
クロスエントロピーは、重み、バイアス、トレーニング画像のピクセル、既知のクラスの関数です。
交差エントロピーのすべての重みとすべてのバイアスに対する偏微分を計算すると、特定の画像、ラベル、重みとバイアスの現在の値に対して計算された「勾配」が得られます。重みとバイアスは数百万個になる可能性があるため、勾配の計算は大変な作業になります。幸いなことに、TensorFlow がこの処理を自動的に行ってくれます。グラデーションの数学的特性は、「上」を指すことです。交差エントロピーが低い方向に進みたいので、反対方向に進みます。重みとバイアスは、勾配の分数で更新します。次に、トレーニング ループで、次のバッチのトレーニング画像とラベルを使用して同じ処理を繰り返します。この最小値が一意であることは保証されていませんが、この最小値に収束することを期待します。
ミニバッチとモメンタム
1 つのサンプル画像でグラデーションを計算し、重みとバイアスをすぐに更新することもできますが、たとえば 128 枚の画像のバッチでグラデーションを計算すると、さまざまなサンプル画像によって課せられる制約をより適切に表すグラデーションが得られるため、解に収束する可能性が高くなります。ミニバッチのサイズは調整可能なパラメータです。
この手法は「確率的勾配降下法」と呼ばれることもありますが、より実用的なメリットもあります。バッチ処理を行うと、より大きな行列を扱うことになり、通常、GPU や TPU での最適化が容易になります。
ただし、収束はやや不安定になる可能性があり、勾配ベクトルがすべてゼロの場合には停止することもあります。これは最小値が見つかったことを意味しますか?必ずしも違反警告を受けるとは限りません。グラデーション コンポーネントは、最小値または最大値でゼロにできます。数百万の要素を持つ勾配ベクトルで、それらがすべてゼロの場合、すべてのゼロが最小値に対応し、最大値に対応するゼロがない確率はかなり小さくなります。多次元空間では鞍点が非常に一般的であり、鞍点で停止したくありません。
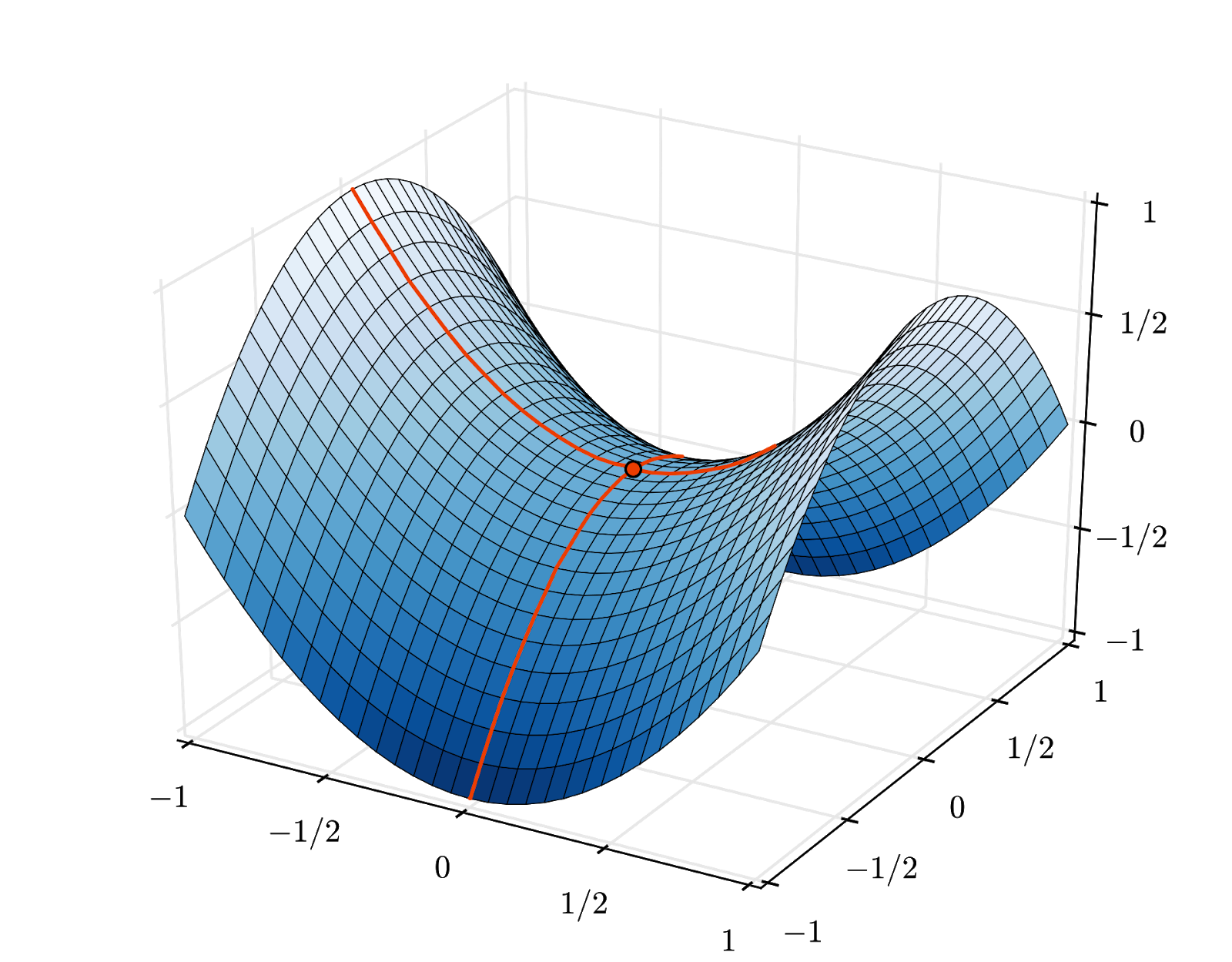
イラスト: 鞍点。勾配は 0 ですが、すべての方向で最小値ではありません。(画像帰属 Wikimedia: Nicoguaro 氏による作品、CC BY 3.0)
解決策は、最適化アルゴリズムに運動量を追加して、鞍点を停止せずに通過できるようにすることです。
用語集
バッチまたはミニバッチ: トレーニングは常にトレーニング データとラベルのバッチで実行されます。これにより、アルゴリズムの収束が促進されます。通常、バッチ ディメンションはデータ テンソルの最初のディメンションです。たとえば、シェイプ [100, 192, 192, 3] のテンソルには、192x192 ピクセルの画像が 100 枚含まれており、各ピクセルには 3 つの値(RGB)があります。
クロス エントロピー損失: 分類子でよく使用される特別な損失関数。
密結合層: 各ニューロンが前のレイヤのすべてのニューロンに接続されているニューロンのレイヤ。
特徴量: ニューラル ネットワークの入力は「特徴量」と呼ばれることがあります。優れた予測を得るために、データセットのどの部分(または部分の組み合わせ)をニューラル ネットワークにフィードするかを判断する技術は、「特徴エンジニアリング」と呼ばれます。
ラベル: 教師あり分類問題における「クラス」または正解の別名
学習率: トレーニング ループの各イテレーションで重みとバイアスが更新される勾配の割合。
ロジット: 活性化関数が適用される前のニューロン層の出力は「ロジット」と呼ばれます。この用語は、かつて最も一般的な活性化関数であった「ロジスティック関数」(「シグモイド関数」とも呼ばれます)に由来します。「Neuron outputs before logistic function」が「logits」に短縮されました。
損失: ニューラル ネットワークの出力を正解と比較する誤差関数
ニューロン: 入力の加重和を計算し、バイアスを追加して、活性化関数を通じて結果をフィードします。
ワンホット エンコーディング: 5 つのクラスのうちのクラス 3 は、5 つの要素のベクトルとしてエンコードされます。3 番目の要素を除いてすべてゼロです。
relu: 正規化線形ユニット。ニューロンでよく使用される活性化関数。
sigmoid: 以前はよく使用されていた別の活性化関数で、特殊なケースでは今でも有用です。
softmax: ベクトルに作用し、最大コンポーネントと他のすべてのコンポーネントの差を大きくする特別な活性化関数。また、確率のベクトルとして解釈できるように、ベクトルの合計が 1 になるように正規化します。分類子の最後のステップとして使用されます。
テンソル: テンソルは、任意の数の次元を持つ行列のようなものです。1 次元のテンソルはベクトルです。2 次元テンソルは行列です。3 次元、4 次元、5 次元以上のテンソルも使用できます。
学習用ノートブックに戻り、今回はコードを読みます。
このノートブックのすべてのセルを見ていきましょう。
セル「Parameters」
バッチサイズ、トレーニング エポック数、データファイルの場所がここで定義されます。データファイルは Google Cloud Storage(GCS)バケットでホストされているため、アドレスは gs:// で始まります。
セル「Imports」
ここでは、TensorFlow や可視化用の matplotlib など、必要な Python ライブラリがすべてインポートされます。
セル「visualization utilities [RUN ME]"
このセルには、興味深い視覚化コードは含まれていません。デフォルトでは折りたたまれていますが、ダブルクリックすると開いてコードを確認できます。
セル「tf.data.Dataset: ファイルを解析してトレーニング データセットと検証データセットを準備する」
このセルでは、tf.data.Dataset API を使用して、データファイルから MNIST データセットを読み込みました。このセルに時間をかけすぎる必要はありません。tf.data.Dataset API については、TPU スピードのデータ パイプラインのチュートリアルをご覧ください。現時点での基本は次のとおりです。
MNIST データセットの画像とラベル(正解)は、4 つのファイルに固定長のレコードとして保存されます。ファイルは、専用の固定レコード関数
を使用して読み込むことができます。
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)これで、画像バイトのデータセットが作成されました。これらは画像にデコードする必要があります。そのための関数を定義します。画像は圧縮されていないため、関数は何もデコードする必要はありません(decode_raw は基本的に何も行いません)。画像は 0 ~ 1 の範囲の浮動小数点値に変換されます。ここで 2D 画像として再形成することもできますが、実際には、初期の密なレイヤが想定している 28*28 のサイズのピクセルのフラットな配列として保持します。
def read_image(tf_bytestring):
image = tf.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return image.map を使用してこの関数をデータセットに適用し、画像のデータセットを取得します。
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)ラベルについても同様の読み取りとデコードを行い、画像とラベルを一緒に .zip します。
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))これで、ペア(画像、ラベル)のデータセットができました。これがモデルで想定されている形式です。トレーニング関数でまだ使用する準備が整っていません。
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)tf.data.Dataset API には、データセットの準備に必要なユーティリティ関数がすべて用意されています。
.cache はデータセットを RAM にキャッシュに保存します。これは小さなデータセットなので、機能します。.shuffle は、5,000 個の要素のバッファでシャッフルします。トレーニング データが適切にシャッフルされていることが重要です。.repeat はデータセットをループします。このデータセットで複数回(複数エポック)トレーニングを行います。.batch は、複数の画像とラベルをまとめてミニナッチに pull します。最後に、.prefetch は、現在のバッチが GPU でトレーニングされている間に、CPU を使用して次のバッチを準備できます。
検証データセットも同様に準備します。これで、モデルを定義し、このデータセットを使用してモデルをトレーニングする準備が整いました。
セル「Keras モデル」
すべてのモデルはレイヤの直線的なシーケンスになるため、tf.keras.Sequential スタイルを使用して作成できます。最初は、単一の密レイヤです。手書きの数字を 10 個のクラスに分類するため、10 個のニューロンがあります。分類器の最後のレイヤであるため、ソフトマックス活性化関数を使用します。
Keras モデルは、入力の形状も認識する必要があります。tf.keras.layers.Input を使用して定義できます。ここで、入力ベクトルは長さ 28*28 のピクセル値のフラット ベクトルです。
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)モデルの構成は、Keras で model.compile 関数を使用して行います。ここでは、基本的なオプティマイザー 'sgd'(確率的勾配降下法)を使用します。分類モデルには、Keras で 'categorical_crossentropy' と呼ばれる交差エントロピー損失関数が必要です。最後に、モデルに 'accuracy' 指標(正しく分類された画像の割合)を計算するよう求めます。
Keras には、作成したモデルの詳細を出力する便利な model.summary() ユーティリティが用意されています。親切な講師が、トレーニング中にさまざまなトレーニング曲線を表示する PlotTraining ユーティリティ(「可視化ユーティリティ」セルで定義)を追加しました。
セル「モデルのトレーニングと検証」
ここで、model.fit を呼び出し、トレーニング データセットと検証データセットの両方を渡すことで、トレーニングが行われます。デフォルトでは、Keras は各エポックの最後に検証ラウンドを実行します。
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])Keras では、コールバックを使用してトレーニング中にカスタム動作を追加できます。このワークショップでは、動的に更新されるトレーニング プロットがこのように実装されています。
[予測を可視化] セル
モデルのトレーニングが完了したら、model.predict() を呼び出してモデルから予測を取得できます。
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)ここでは、テストとして、ローカル フォントからレンダリングされた印刷された数字のセットを用意しました。ニューラル ネットワークは、最終的な「softmax」から 10 個の確率のベクトルを返します。ラベルを取得するには、どの確率が最も高いかを確認する必要があります。numpy ライブラリの np.argmax がそれを行います。
axis=1 パラメータが必要な理由を理解するには、128 個の画像のバッチを処理したため、モデルが 128 個の確率ベクトルを返すことを思い出してください。出力テンソルの形状は [128, 10] です。各画像に対して返された 10 個の確率の argmax を計算しているため、axis=1(最初の軸は 0)になります。
このシンプルなモデルでも、すでに 90% の数字を認識しています。悪くはありませんが、これから大幅に改善します。
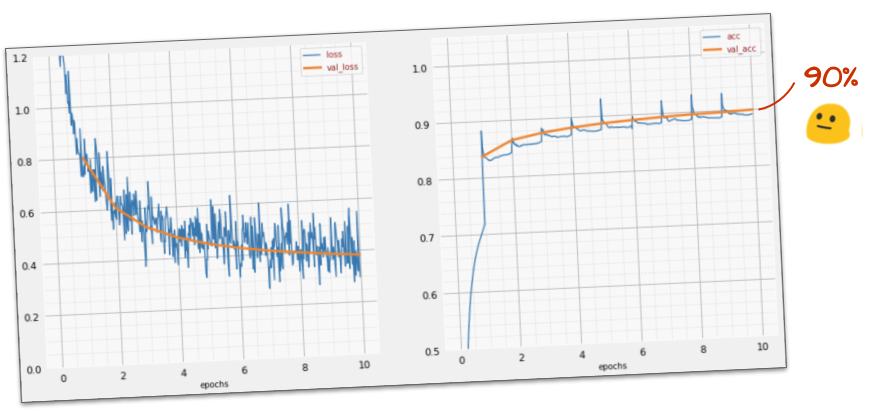

認識の精度を向上させるため、ニューラル ネットワークにレイヤを追加します。
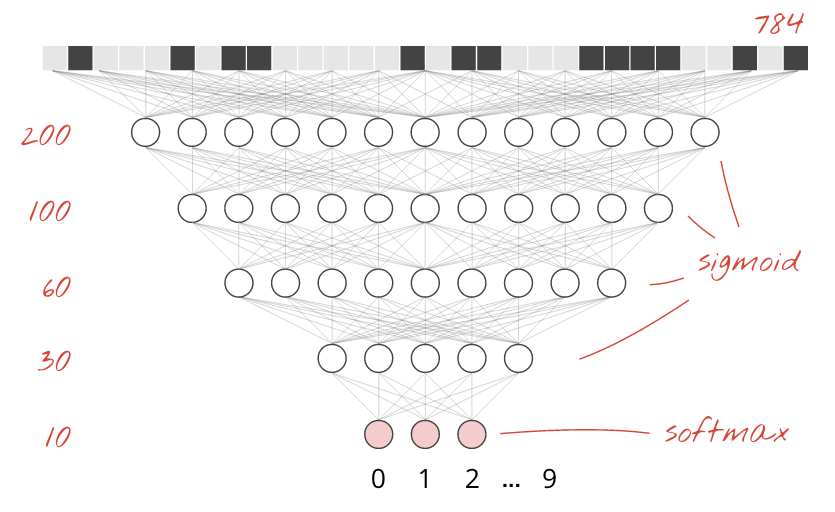
分類に最適なため、最後のレイヤの活性化関数としてソフトマックスを保持します。ただし、中間レイヤでは、最も古典的な活性化関数であるシグモイドを使用します。
たとえば、モデルは次のようになります(カンマを忘れないでください。tf.keras.Sequential はレイヤのカンマ区切りリストを受け取ります)。
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])モデルの「概要」を確認します。パラメータの数が 10 倍以上になりました。10 倍優れたものにする必要があります。しかし、なぜかそうならないことがあります。
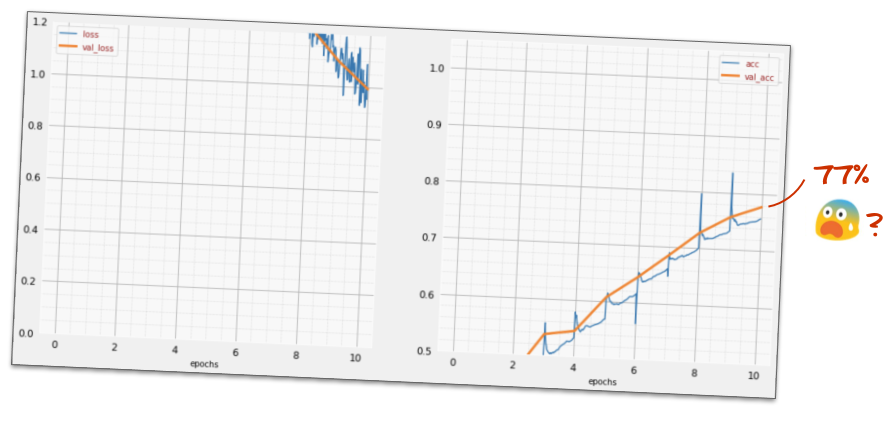
損失も急増しているようです。問題が発生しました。
これは、1980 年代から 1990 年代に設計されていたニューラル ネットワークです。このアイデアを放棄し、いわゆる「AI の冬」を迎えたのも当然です。実際、レイヤを追加すると、ニューラル ネットワークの収束がますます困難になります。
多くのレイヤ(現在では 20、50、100)を持つディープ ニューラル ネットワークは、収束させるための数学的な裏技をいくつか使えば、非常にうまく機能することがわかりました。このようなシンプルな手法の発見が、2010 年代にディープ ラーニングが復興した理由の一つです。
RELU 活性化

シグモイド活性化関数は、実際にはディープ ネットワークでかなり問題があります。0 ~ 1 のすべての値が圧縮され、これを繰り返すと、ニューロンの出力とその勾配が完全に消滅する可能性があります。これは歴史的な理由で言及されたものですが、最新のネットワークでは RELU(Rectified Linear Unit)が使用されています。これは次のようなものです。
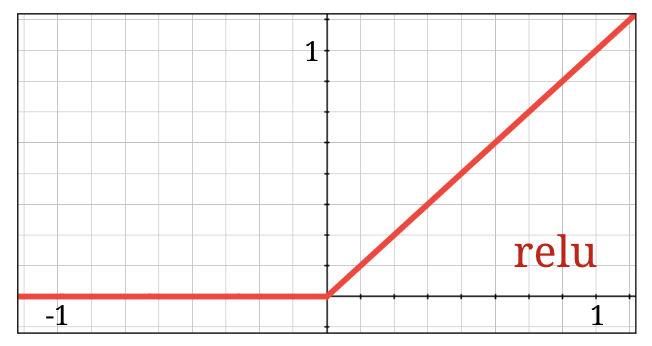
一方、relu の導関数は少なくとも右側では 1 です。ReLU 活性化では、一部のニューロンからの勾配がゼロになることがあっても、常に 0 ではない明確な勾配を生成するニューロンが存在するため、トレーニングは順調に進みます。
より優れたオプティマイザー
ここでは 1 万個の重みとバイアスがあるため、このような高次元空間では鞍点が頻繁に発生します。これらは、局所最小値ではないものの、勾配がゼロになり、勾配降下オプティマイザーがそこで動かなくなる点です。TensorFlow には、慣性量を使用して鞍点を安全に通過するオプティマイザーなど、さまざまなオプティマイザーが用意されています。
ランダムな初期化
トレーニング前に重みバイアスを初期化する技術は、それ自体が研究分野であり、このトピックに関する論文が多数発表されています。Keras で使用できるすべての初期化関数については、こちらをご覧ください。幸いなことに、Keras はデフォルトで適切な処理を行い、ほとんどの場合に最適な 'glorot_uniform' イニシャライザを使用します。
Keras はすでに正しい処理を行っているため、ユーザーが対応する必要はありません。
NaN ???
クロスエントロピーの式には対数が含まれており、log(0) は Not a Number(NaN、数値クラッシュ)です。交差エントロピーの入力は 0 にできますか?入力はソフトマックスから取得されます。ソフトマックスは基本的に指数関数であり、指数関数がゼロになることはありません。これで安全です。
本当にそうでしょうか数学の世界では安全ですが、コンピュータの世界では、float32 形式で表される exp(-150) はゼロに限りなく近く、クロス エントロピーがクラッシュします。
幸いなことに、Keras がこの処理を行い、数値の安定性を確保して NaN を回避するために、特に慎重な方法でソフトマックスとクロスエントロピーを計算するため、ここでも何もする必要はありません。
成功?
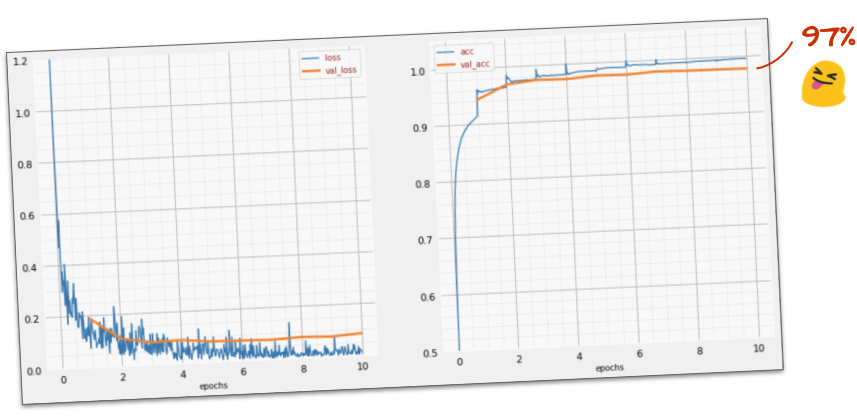
これで、97% の精度に達するはずです。このワークショップの目標は 99% を大幅に超えることなので、続行しましょう。
行き詰まった場合は、次の解決策をお試しください。
トレーニングを高速化してみましょうか?Adam オプティマイザーのデフォルトの学習率は 0.001 です。増やしてみましょう。
スピードを上げてもあまり効果がないようです。このノイズは何ですか?
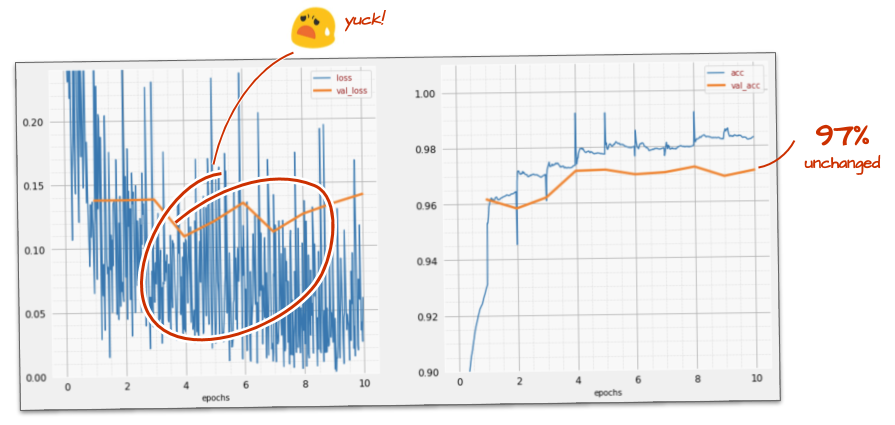
トレーニング曲線は非常にノイズが多く、両方の検証曲線が上下に変動しています。これは、ペースが速すぎることを意味します。前の速度に戻すこともできますが、もっと良い方法があります。

適切な解決策は、学習率を指数関数的に減衰させながら、高速で開始することです。Keras では、tf.keras.callbacks.LearningRateScheduler コールバックを使用してこれを行うことができます。
コピー&ペーストに便利なコード:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)作成した lr_decay_callback を使用することを忘れないでください。model.fit のコールバックのリストに追加します。
model.fit(..., callbacks=[plot_training, lr_decay_callback])この小さな変更がもたらす影響は驚くべきものです。ノイズのほとんどが除去され、テストの精度が 98% を超える状態が継続していることがわかります。
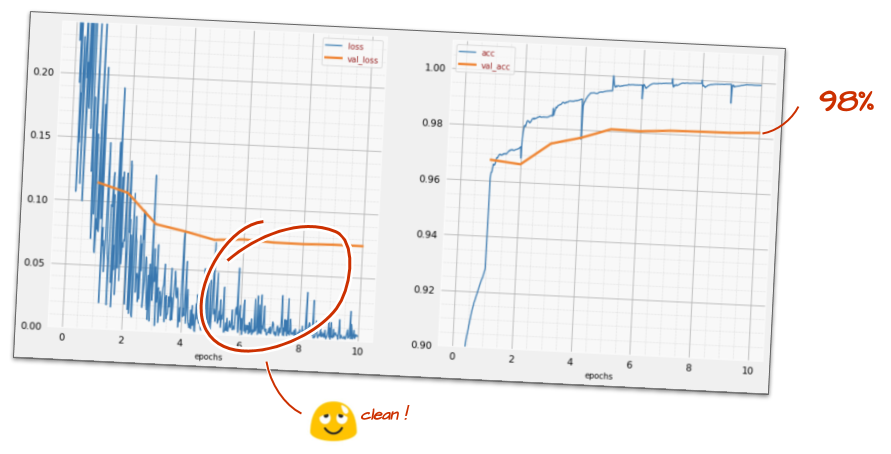
モデルはうまく収束しているようです。さらに詳しく見ていきましょう。
この情報は役に立ちましたか?
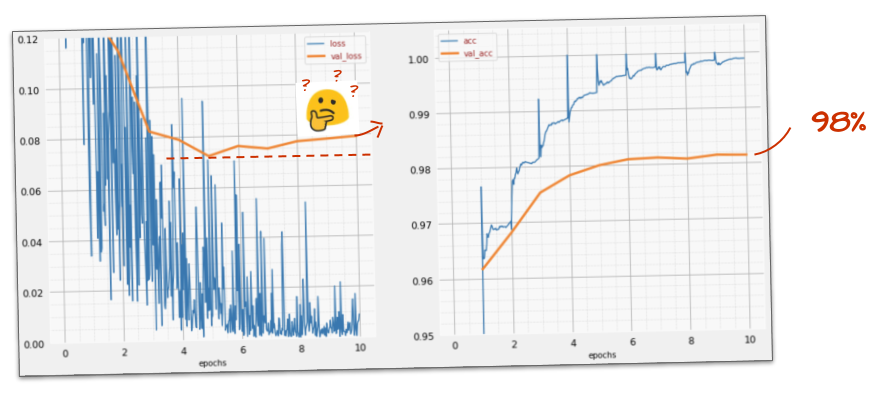
精度は 98% のままです。検証損失を見てみましょう。上昇しています。学習アルゴリズムはトレーニング データのみで動作し、トレーニング損失を最適化します。検証データがまったく表示されないため、しばらくすると検証損失に影響しなくなり、検証損失の減少が止まって、場合によっては跳ね返って増加することもあります。
これはモデルの実際の認識機能にすぐに影響するわけではありませんが、多くの反復処理を実行できなくなり、一般的にトレーニングがもはやプラスの効果をもたらしていないことを示しています。

この不一致は通常「過適合」と呼ばれます。この不一致が見られた場合は、「ドロップアウト」と呼ばれる正則化手法を適用してみてください。ドロップアウト手法では、各トレーニング イテレーションでランダムなニューロンが削除されます。
成果
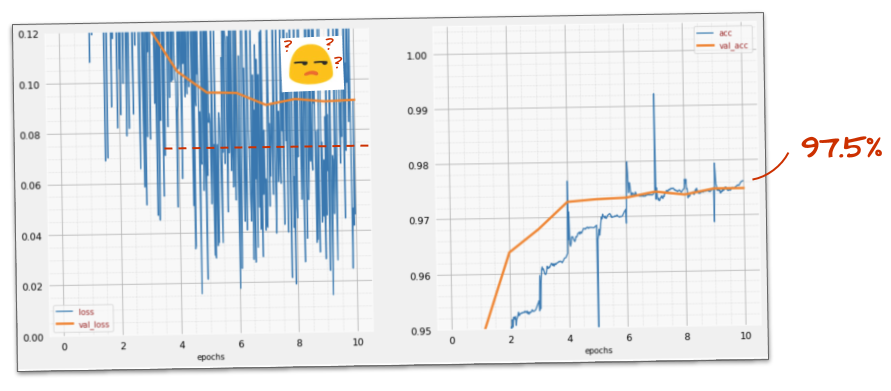
ノイズが再び発生します(ドロップアウトの仕組みを考えると、これは当然です)。検証損失はそれ以上増加していないようですが、全体的にドロップアウトなしの場合よりも高くなっています。検証精度は少し低下しました。これはかなり残念な結果です。
ドロップアウトは正しい解決策ではなかったようです。あるいは、「過剰適合」はより複雑な概念であり、その原因の一部は「ドロップアウト」による修正には適していないのでしょうか?
「過剰適合」とは何ですか?過学習は、ニューラル ネットワークが「悪い」学習をした場合に発生します。この場合、トレーニング サンプルではうまく機能しますが、実世界のデータではうまく機能しません。ドロップアウトなどの正則化手法を使用すると、より良い方法で学習を強制できますが、過学習にはより深い原因があります。

基本的な過適合は、ニューラル ネットワークの自由度が、手元の問題に対して大きすぎる場合に発生します。ネットワークにすべてのトレーニング画像を保存し、パターン マッチングで認識できるほど多くのニューロンがあるとします。実際のデータでは完全に失敗します。ニューラル ネットワークは、トレーニング中に学習した内容を一般化するように、ある程度制約する必要があります。
トレーニング データが非常に少ない場合、小さなネットワークでもそれを暗記してしまい、「過剰適合」が発生します。一般的に、ニューラル ネットワークをトレーニングするには大量のデータが必要です。
最後に、教科書どおりにすべてを行い、ネットワークの自由度が制約されていることを確認するためにさまざまなサイズのネットワークを試し、ドロップアウトを適用し、大量のデータでトレーニングしても、パフォーマンス レベルが改善されないことがあります。つまり、この例のように、現在の形状のニューラル ネットワークではデータからこれ以上の情報を抽出できません。
画像を 1 つのベクトルに平坦化して使用していることを思い出してください。それは本当に悪い考えでした。手書きの数字は形状で構成されていますが、ピクセルを平坦化する際に形状情報が破棄されました。ただし、形状情報を活用できるニューラル ネットワークの一種である畳み込みネットワークがあります。試してみましょう。
行き詰まった場合は、次の解決策をお試しください。
概要
次の段落の太字の用語をすべてご存知の場合は、次の演習に進んでください。畳み込みニューラル ネットワークを初めて使用する場合は、このままお読みください。
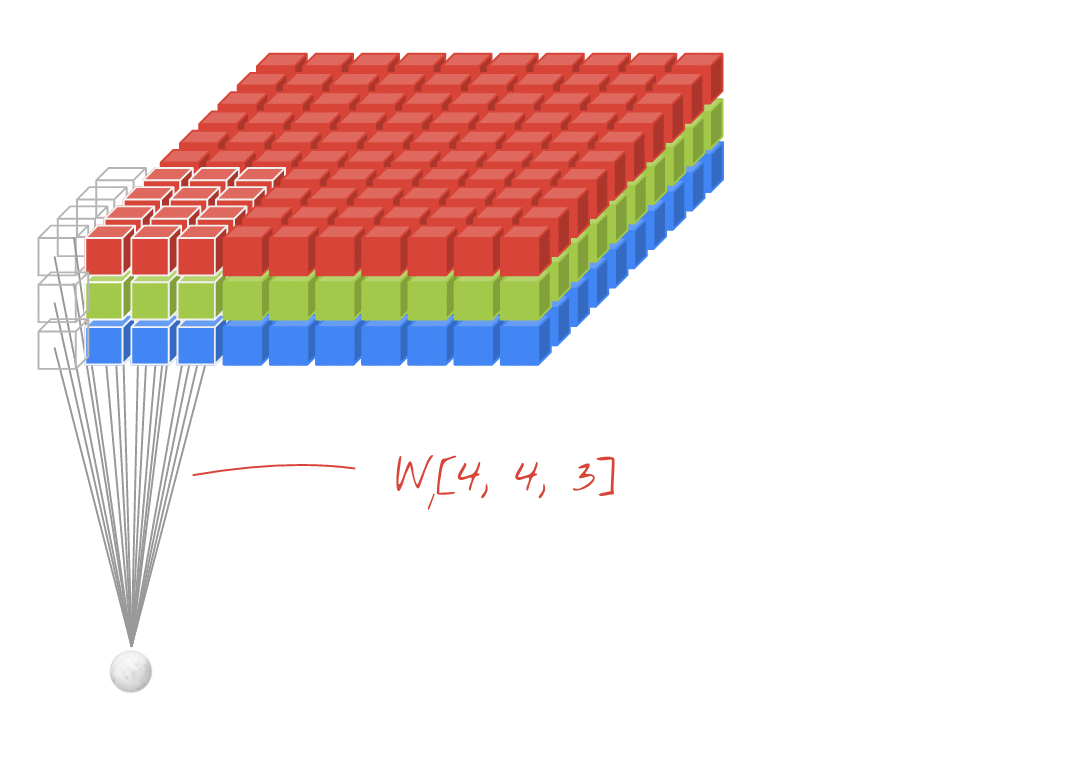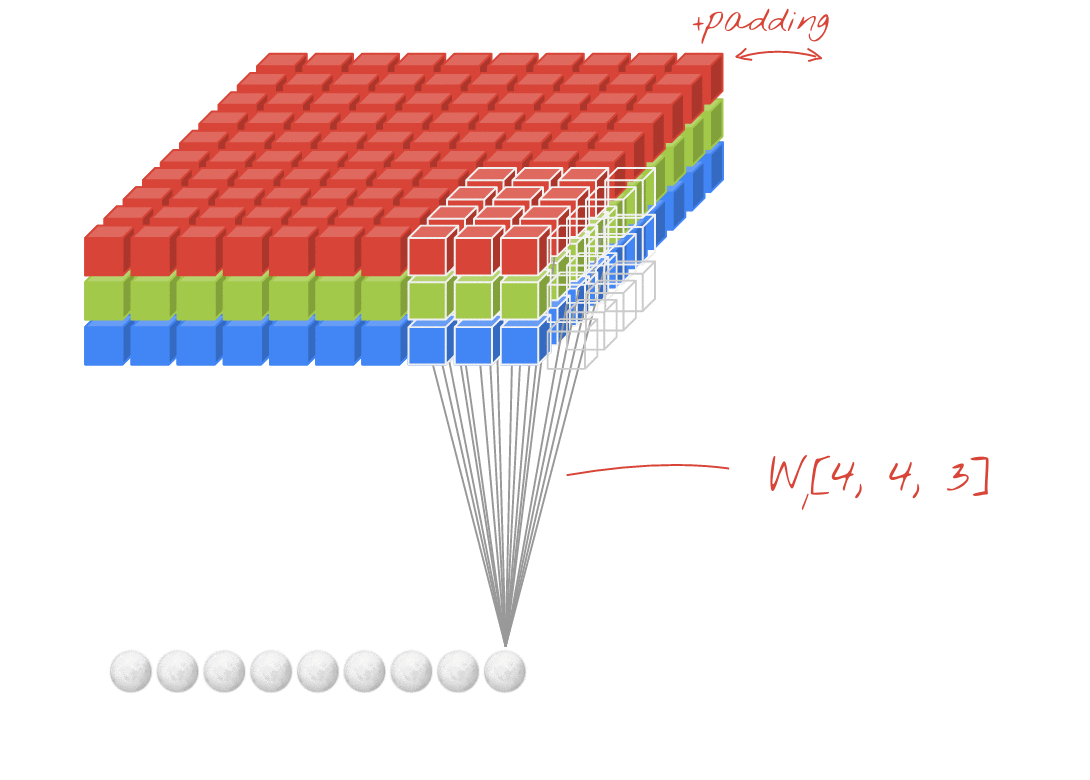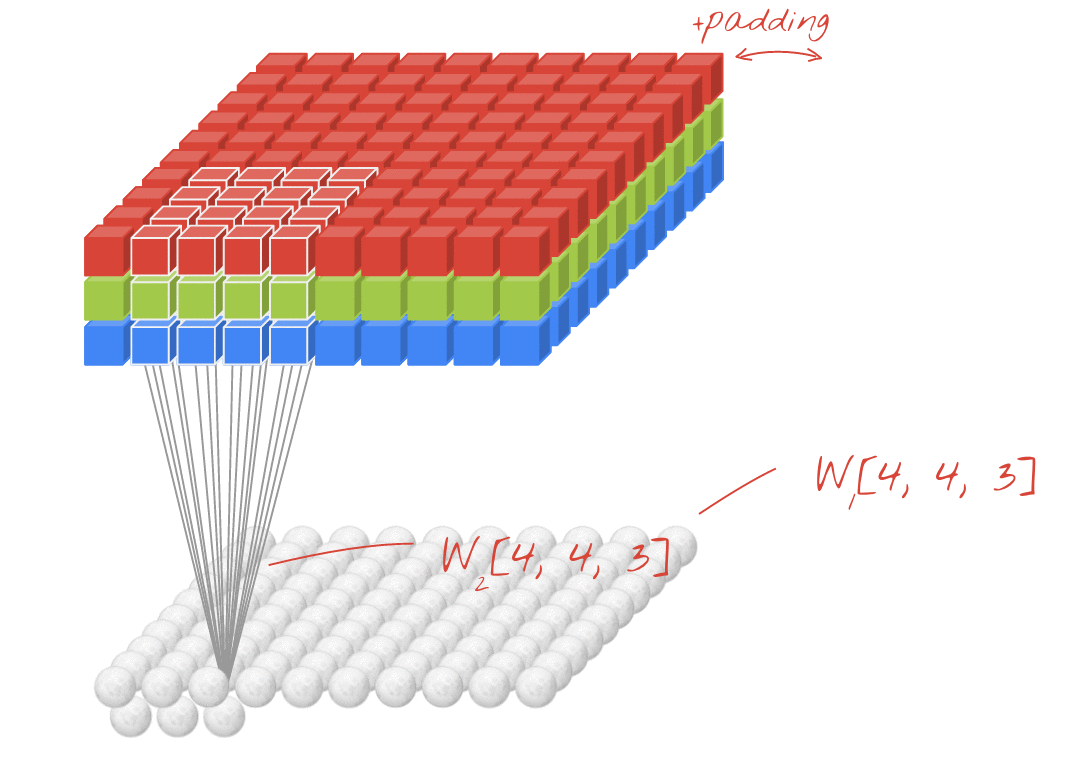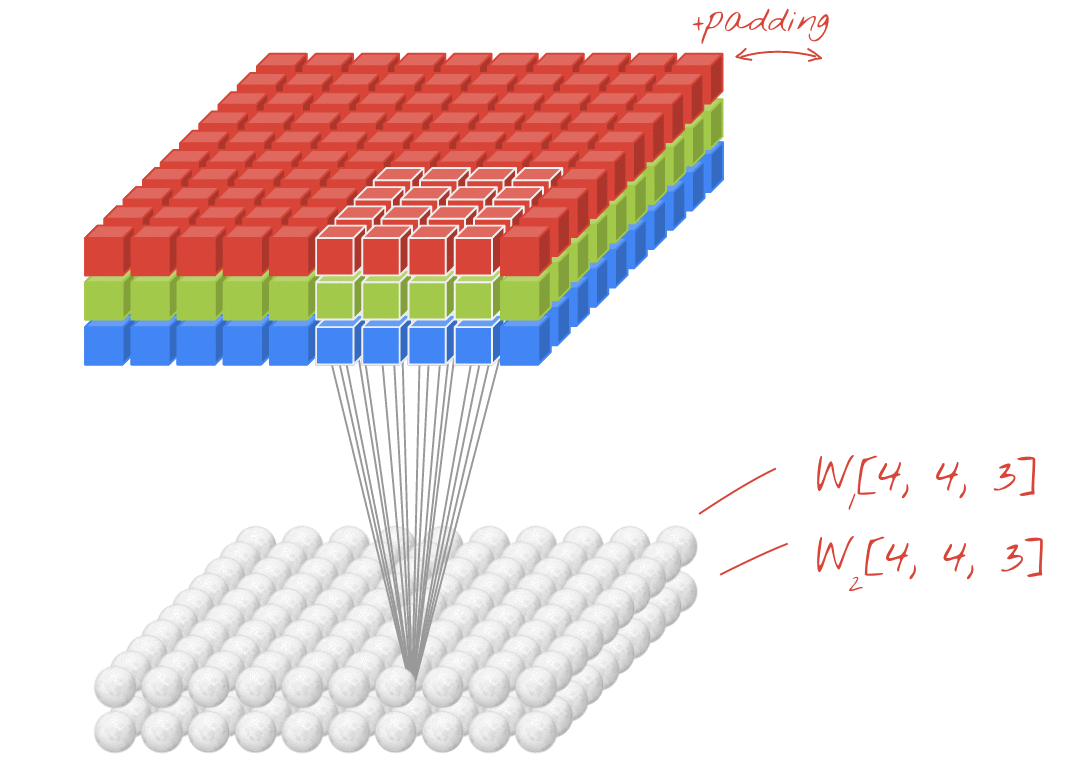
図: それぞれ 4x4x3=48 個の学習可能な重みで構成される 2 つの連続したフィルタで画像をフィルタリングする。
Keras での単純な畳み込みニューラル ネットワークは次のようになります。
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
畳み込みネットワークのレイヤでは、1 つの「ニューロン」が、画像の小さな領域のみで、すぐ上のピクセルの加重和を計算します。通常の密結合レイヤのニューロンと同様に、バイアスを追加し、活性化関数を介して合計を渡します。このオペレーションは、同じ重みを使用して画像全体で繰り返されます。密結合レイヤでは、各ニューロンに独自の重みがありました。ここでは、重みの 1 つの「パッチ」が画像上を両方向にスライドします(「畳み込み」)。出力には、画像内のピクセル数と同じ数の値が含まれます(ただし、エッジでパディングが必要になります)。これはフィルタリング オペレーションです。上の図では、4x4x3=48 の重みのフィルタを使用しています。
ただし、48 個の重みでは不十分です。自由度を高めるために、新しい重みのセットで同じ操作を繰り返します。これにより、新しい一連のフィルタ出力が生成されます。入力画像の R、G、B チャンネルとの類似性から、出力の「チャンネル」と呼びます。
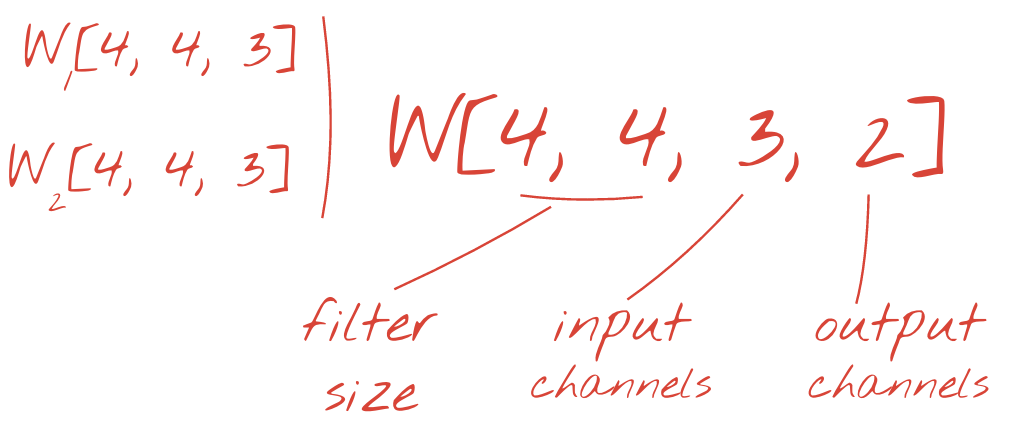
2 つ以上の重みのセットは、新しいディメンションを追加することで 1 つのテンソルとして合計できます。これにより、畳み込みレイヤの重みテンソルの一般的な形状が得られます。入力チャネルと出力チャネルの数はパラメータであるため、畳み込みレイヤのスタックとチェーンを開始できます。
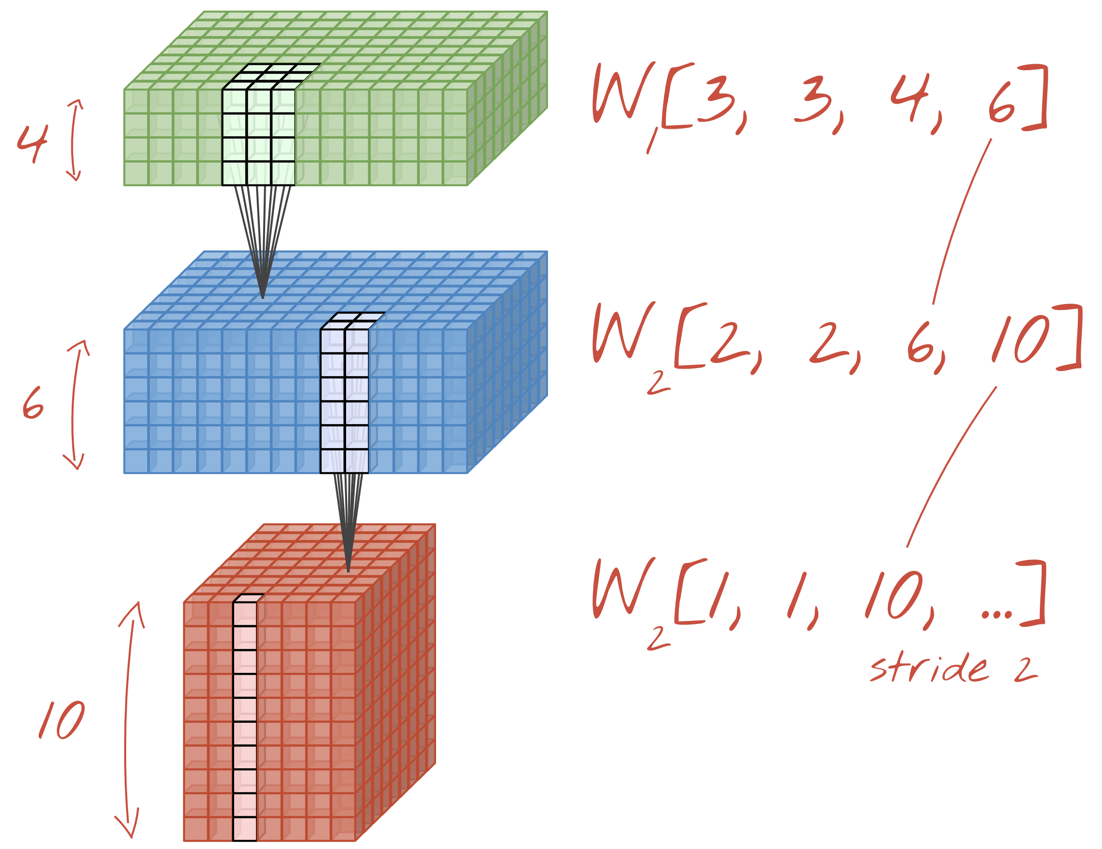
図: 畳み込みニューラル ネットワークがデータの「キューブ」を別のデータの「キューブ」に変換する。
ストライド畳み込み、最大プーリング
ストライド 2 または 3 で畳み込みを行うことで、結果のデータキューブを水平方向に縮小することもできます。これを行うには、次の 2 つの一般的な方法があります。
- ストライド畳み込み: 上記のスライディング フィルタ。ただし、ストライドが 1 より大きい
- 最大プーリング: MAX オペレーションを適用するスライディング ウィンドウ(通常は 2x2 パッチで、2 ピクセルごとに繰り返されます)

図: コンピューティング ウィンドウを 3 ピクセル スライドさせると、出力値が少なくなります。ストライド畳み込みまたは最大プーリング(ストライド 2 でスライドする 2x2 ウィンドウの最大値)は、水平方向にデータキューブを縮小する方法です。
最終レイヤ
最後の畳み込みレイヤの後、データは「キューブ」の形式になります。最終的な密結合レイヤにフィードする方法は 2 つあります。
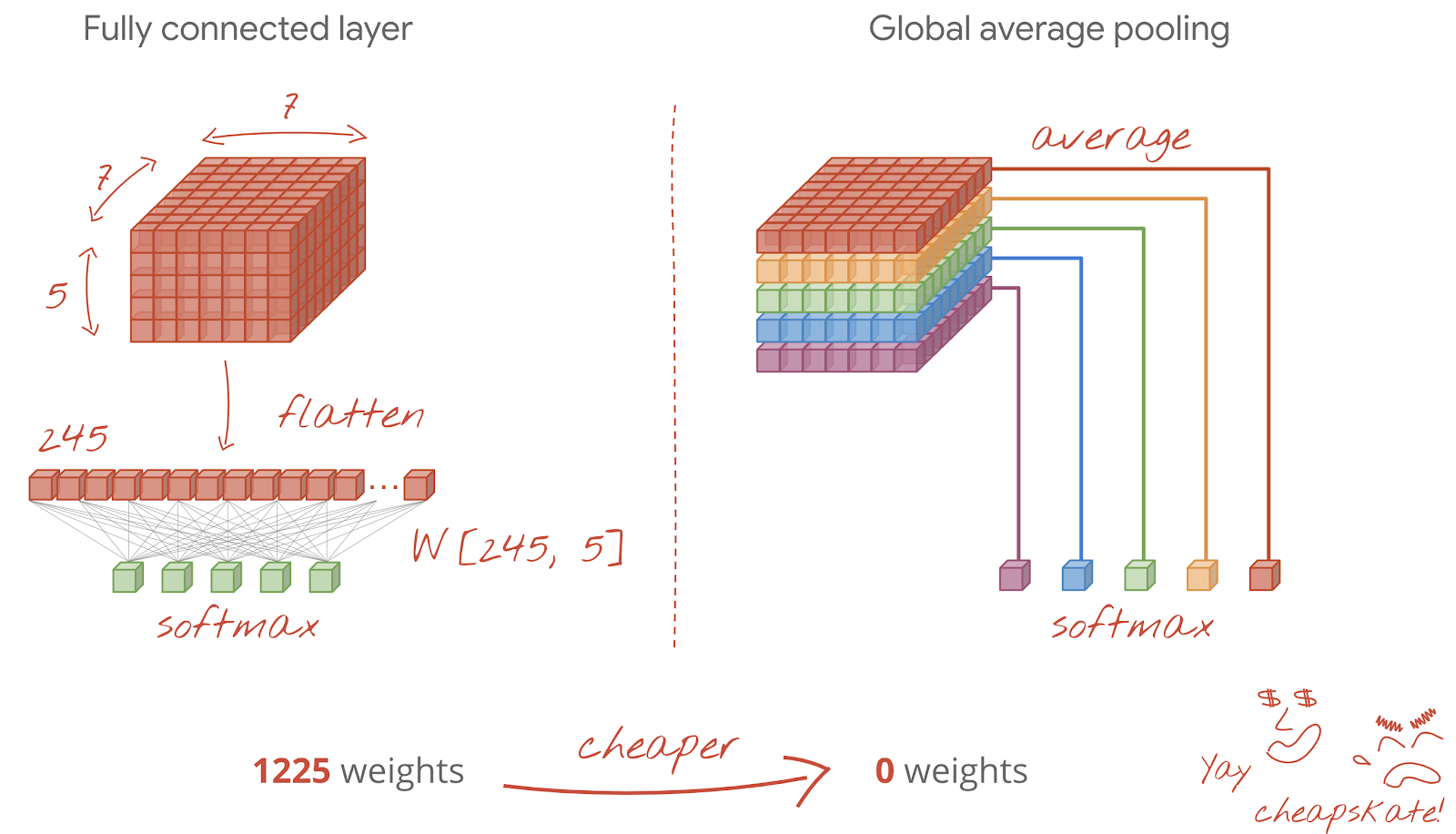
1 つ目は、データのキューブをベクトルに平坦化し、softmax レイヤに渡す方法です。場合によっては、softmax レイヤの前に密レイヤを追加することもできます。これは、重みの数に関してコストが高くなる傾向があります。畳み込みネットワークの最後の密結合層には、ニューラル ネットワーク全体の重みの半分以上が含まれることがあります。
高価な密なレイヤを使用する代わりに、入力データの「キューブ」をクラスの数だけ分割し、それらの値を平均して、ソフトマックス活性化関数に渡すこともできます。この分類ヘッドの構築方法では、重みは 0 になります。Keras には、このためのレイヤ tf.keras.layers.GlobalAveragePooling2D() があります。
次のセクションに進み、当面の問題に対する畳み込みネットワークを構築しましょう。
手書きの数字を認識する畳み込みネットワークを構築しましょう。上部に 3 つの畳み込みレイヤ、下部に従来のソフトマックス読み出しレイヤを使用し、それらを 1 つの全結合レイヤで接続します。
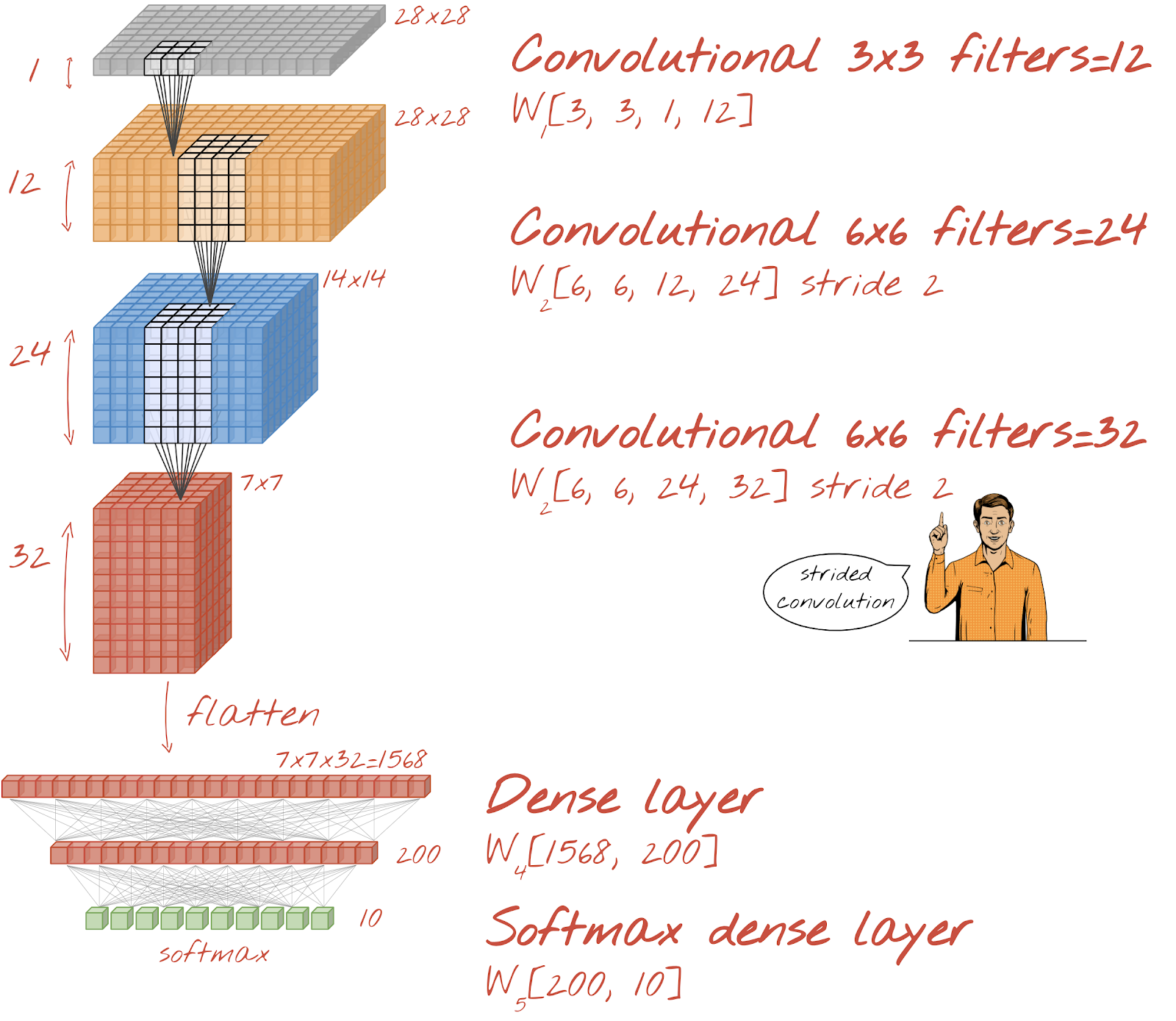
2 番目と 3 番目の畳み込みレイヤのストライドが 2 であるため、出力値の数が 28x28 から 14x14、7x7 に減少していることに注目してください。
Keras コードを記述しましょう。
最初の畳み込みレイヤの前に特別な注意が必要です。実際には、3D の「キューブ」のデータが想定されていますが、これまでのデータセットは密なレイヤ用に設定されており、画像のすべてのピクセルがベクトルに平坦化されています。これらを 28x28x1 画像(グレースケール画像用の 1 チャンネル)に再形成する必要があります。
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))この行は、これまで使用していた tf.keras.layers.Input レイヤの代わりに使用できます。
Keras で「relu」アクティベーションの畳み込みレイヤの構文は次のとおりです。
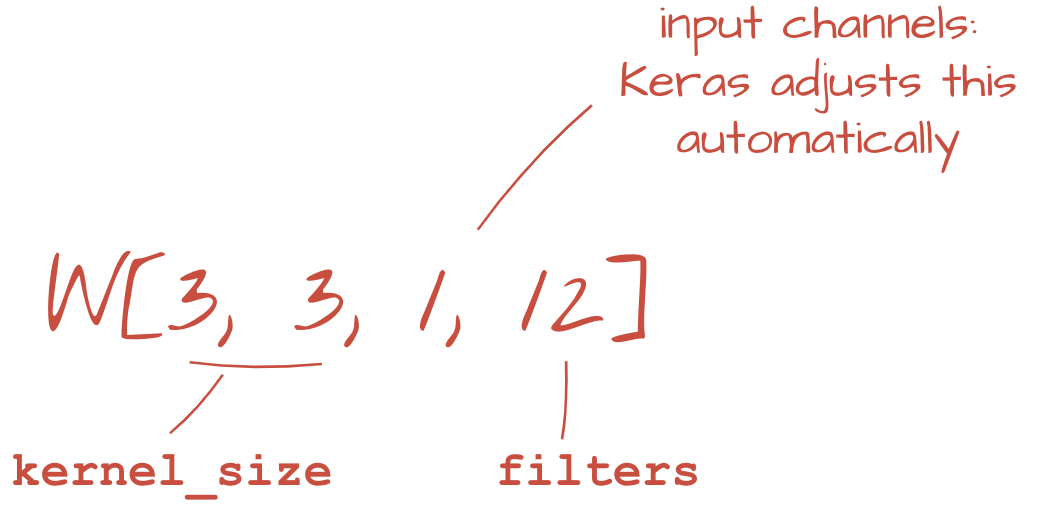
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')ストライド畳み込みの場合は、次のように記述します。
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)密なレイヤで使用できるように、データのキューブをベクトルに平坦化するには:
tf.keras.layers.Flatten()密レイヤの構文は変更されていません。
tf.keras.layers.Dense(200, activation='relu')モデルの精度が 99% を超えましたか?かなり近いですね。検証損失曲線を確認します。ご興味はおありでしょうか。
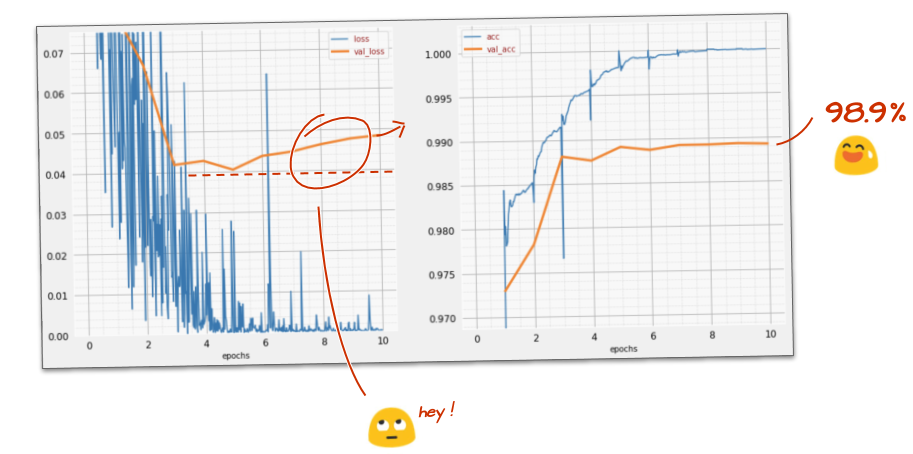
予測も確認します。初めて実行すると、10,000 個のテスト数字のほとんどが正しく認識されるようになります。誤検出は 4 行半程度(10,000 桁のうち約 110 桁)のみ

行き詰まった場合は、次の解決策をお試しください。
前のトレーニングでは、過適合の明確な兆候が見られます(精度は 99% に達していません)。ドロップアウトをもう一度試すべきでしょうか?
今回はどうでしたか?
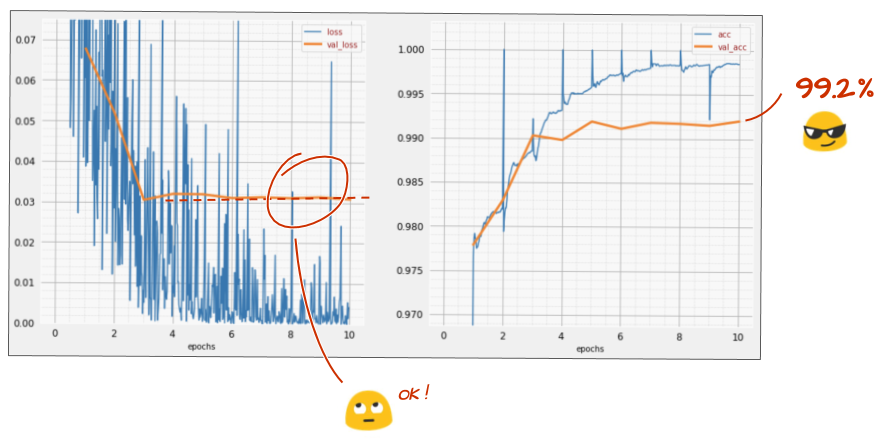
今回はドロップアウトが機能したようです。検証損失は増加しなくなり、最終的な精度は 99% を大幅に超えるはずです。お疲れさまでした
ドロップアウトを初めて適用したとき、過剰適合の問題があると考えましたが、実際にはニューラル ネットワークのアーキテクチャに問題がありました。畳み込みレイヤなしでは先に進むことができませんでした。ドロップアウトではどうすることもできません。
今回は、過学習が問題の原因であり、ドロップアウトが実際に役立ったようです。トレーニング損失曲線と検証損失曲線が乖離し、検証損失が上昇する原因は数多くあります。過剰適合(自由度が多すぎて、ネットワークでうまく使用されない)はその 1 つにすぎません。データセットが小さすぎる場合や、ニューラル ネットワークのアーキテクチャが適切でない場合は、損失曲線で同様の動作が見られることがありますが、ドロップアウトは役に立ちません。

最後に、バッチ正規化を追加してみましょう。
理論は以上ですが、実際には次の 2 つのルールを覚えておけば十分です。
ここでは、各ニューラル ネットワーク レイヤ(最後のレイヤを除く)にバッチ正規化レイヤを追加します。最後の「softmax」レイヤには追加しないでください。この場合は役に立ちません。
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),精度はどの程度ですか?
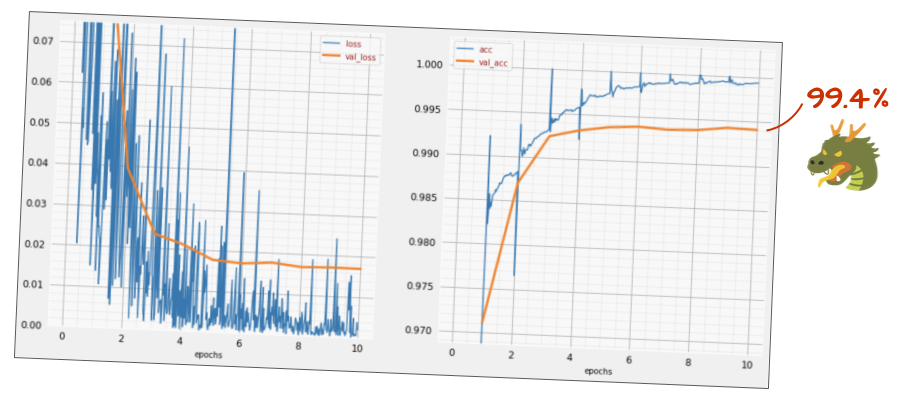
少し調整(BATCH_SIZE=64、学習率減衰パラメータ 0.666、密層のドロップアウト率 0.3)して運が良ければ、99.5% に達することができます。学習率とドロップアウトの調整は、バッチ正規化を使用する際の「ベスト プラクティス」に従って行われました。
- バッチ正規化は、ニューラル ネットワークの収束を助け、通常はトレーニングを高速化します。
- バッチ正規化は正則化です。通常、使用するドロップアウトの量を減らしたり、ドロップアウトをまったく使用しないようにしたりできます。
ソリューション ノートブックのトレーニング実行は 99.5% です。

コードのクラウド対応バージョンは、GitHub の mlengine フォルダにあります。また、Google Cloud AI Platform で実行する手順も記載されています。この部分を実行する前に、Google Cloud アカウントを作成して課金を有効にする必要があります。ラボを完了するために必要なリソースは、数ドル未満です(1 つの GPU で 1 時間のトレーニング時間を想定)。アカウントを準備するには:
- Google Cloud Platform プロジェクト(http://cloud.google.com/console)を作成します。
- 課金の有効化
- GCP コマンドライン ツール(GCP SDK)をインストールします。
- Google Cloud Storage バケットを作成します(リージョン
us-central1に配置)。これは、トレーニング コードのステージングと、トレーニング済みモデルの保存に使用されます。 - 必要な API を有効にして、必要な割り当てをリクエストします(トレーニング コマンドを 1 回実行すると、有効にする必要がある内容を示すエラー メッセージが表示されます)。
最初のニューラル ネットワークを構築し、99% の精度までトレーニングしました。この過程で学習する手法は MNIST データセットに固有のものではなく、ニューラル ネットワークを扱う際に広く使用されています。最後に、ラボの「クリフノート」カードの漫画版をご紹介します。このツールは、学習した内容を思い出すために使用できます。

次のステップ
- 全結合ネットワークと畳み込みネットワークの次は、再帰型ニューラル ネットワークをご覧ください。
- 分散インフラストラクチャでクラウドでトレーニングまたは推論を実行するには、Google Cloud の AI Platform を使用します。
- 最後に、皆様のフィードバックをお待ちしています。このラボで不具合が見つかった場合や、改善すべき点があると思われる場合は、お知らせください。フィードバックは GitHub の問題 [フィードバック リンク] を通じて処理されます。

著者: Martin Görner Twitter: @martin_gorner |
|


このラボのすべての漫画画像の著作権: alexpokusay / 123RF ストックフォト