

इस कोडलैब में, आपको हाथ से लिखे गए अंकों को पहचानने वाला न्यूरल नेटवर्क बनाने और उसे ट्रेन करने का तरीका बताया जाएगा. इस दौरान, 99% सटीकता हासिल करने के लिए अपने न्यूरल नेटवर्क को बेहतर बनाते समय, आपको ऐसे टूल के बारे में भी पता चलेगा जिनका इस्तेमाल डीप लर्निंग के पेशेवर, अपने मॉडल को बेहतर तरीके से ट्रेन करने के लिए करते हैं.
इस कोडलैब में, MNIST डेटासेट का इस्तेमाल किया गया है. इसमें लेबल किए गए 60,000 अंकों का कलेक्शन है. इस डेटासेट पर पीएचडी करने वाले लोग, पिछले दो दशकों से काम कर रहे हैं. आपको Python / TensorFlow के 100 से कम लाइनों वाले कोड का इस्तेमाल करके समस्या हल करनी होगी.
आपको क्या सीखने को मिलेगा
- न्यूरल नेटवर्क क्या है और इसे कैसे ट्रेन किया जाता है
- tf.keras का इस्तेमाल करके, एक लेयर वाला बुनियादी न्यूरल नेटवर्क बनाने का तरीका
- ज़्यादा लेयर जोड़ने का तरीका
- लर्निंग रेट का शेड्यूल सेट अप करने का तरीका
- कनवोल्यूशनल न्यूरल नेटवर्क कैसे बनाएं
- रेगुलराइज़ेशन की तकनीकों का इस्तेमाल कैसे करें: ड्रॉपआउट, बैच नॉर्मलाइज़ेशन
- ओवरफ़िटिंग क्या है
आपको किन चीज़ों की ज़रूरत होगी
सिर्फ़ एक ब्राउज़र. इस वर्कशॉप को पूरी तरह से Google Colaboratory की मदद से चलाया जा सकता है.
सुझाव, राय या शिकायत
अगर आपको इस लैब में कोई गड़बड़ी दिखती है या आपको लगता है कि इसमें सुधार किया जाना चाहिए, तो कृपया हमें बताएं. हम GitHub की समस्याओं [सुझाव/राय देने या शिकायत करने का लिंक] के ज़रिए सुझाव/राय देते हैं या शिकायत करते हैं.
इस लैब में Google Colaboratory का इस्तेमाल किया जाता है. इसके लिए, आपको कोई सेटअप करने की ज़रूरत नहीं है. इसे Chromebook से चलाया जा सकता है. Colab notebook के बारे में जानने के लिए, कृपया नीचे दी गई फ़ाइल खोलें और सेल को एक्ज़ीक्यूट करें.

यहां दिए गए अन्य निर्देशों का पालन करें:
कोई जीपीयू बैकएंड चुनें

Colab मेन्यू में, रनटाइम > रनटाइम का टाइप बदलें को चुनें. इसके बाद, GPU को चुनें. पहली बार कोड चलाने पर, रनटाइम से कनेक्शन अपने-आप हो जाएगा. इसके अलावा, सबसे ऊपर दाएं कोने में मौजूद "कनेक्ट करें" बटन का इस्तेमाल करके भी कनेक्शन किया जा सकता है.
नोटबुक को एक्ज़ीक्यूट करना

एक बार में एक सेल को चलाने के लिए, किसी सेल पर क्लिक करें और Shift-ENTER का इस्तेमाल करें. रनटाइम > सभी सेल चलाएं का इस्तेमाल करके, पूरी नोटबुक को भी चलाया जा सकता है
विषय सूची

सभी नोटबुक में विषय सूची होती है. बाईं ओर मौजूद काले ऐरो का इस्तेमाल करके, इसे खोला जा सकता है.
छिपे हुए सेल

कुछ सेल में सिर्फ़ उनका टाइटल दिखेगा. यह Colab notebook की एक खास सुविधा है. इनके अंदर मौजूद कोड देखने के लिए, इन पर दो बार क्लिक किया जा सकता है. हालांकि, यह आम तौर पर बहुत दिलचस्प नहीं होता. आम तौर पर, ये सहायता या विज़ुअलाइज़ेशन फ़ंक्शन होते हैं. हालांकि, फ़ंक्शन को तय करने के लिए, आपको अब भी इन सेल को चलाना होगा.
सबसे पहले, हम न्यूरल नेटवर्क को ट्रेन होते हुए देखेंगे. कृपया नीचे दी गई नोटबुक खोलें और सभी सेल चलाएं. फ़िलहाल, कोड पर ध्यान न दें. हम इसके बारे में बाद में बताएंगे.
नोटबुक को लागू करते समय, विज़ुअलाइज़ेशन पर फ़ोकस करें. एक्सप्लेनेशन के लिए यहां देखें.
ट्रेनिंग के लिए डेटा
हमारे पास हाथ से लिखे गए अंकों का एक डेटासेट है.इन्हें लेबल किया गया है, ताकि हमें पता चल सके कि हर तस्वीर क्या दिखाती है. जैसे, 0 से 9 के बीच की कोई संख्या. आपको नोटबुक में यह जानकारी दिखेगी:
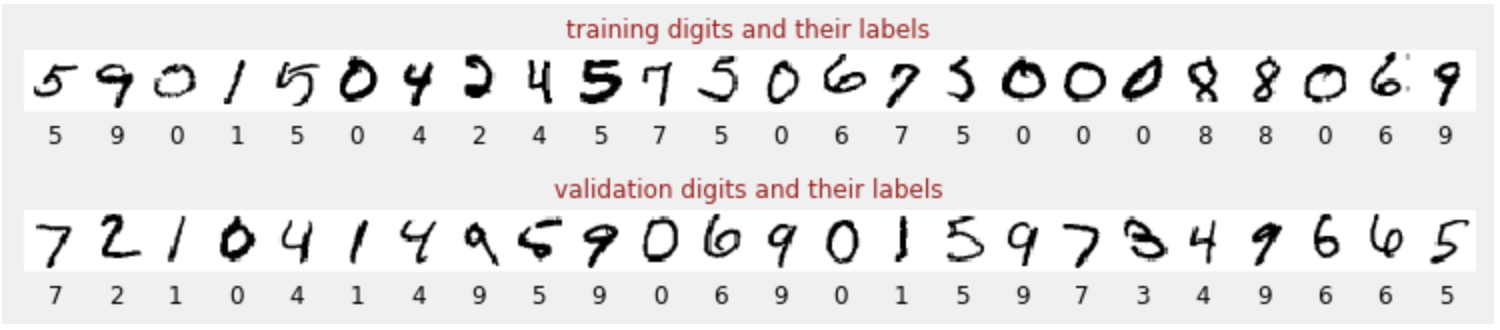
हम जिस न्यूरल नेटवर्क को बनाएंगे वह हाथ से लिखे गए अंकों को उनकी 10 क्लास (0, .., 9) में बांटेगा. ऐसा इंटरनल पैरामीटर के आधार पर किया जाता है. क्लासिफ़िकेशन के सही तरीके से काम करने के लिए, इन पैरामीटर की वैल्यू सही होनी चाहिए. "सही वैल्यू" का पता ट्रेनिंग प्रोसेस से चलता है. इसके लिए, "लेबल किए गए डेटासेट" की ज़रूरत होती है. इसमें इमेज और उनसे जुड़े सही जवाब शामिल होते हैं.
हमें कैसे पता चलेगा कि ट्रेन किया गया न्यूरल नेटवर्क अच्छी परफ़ॉर्मेंस दे रहा है या नहीं? नेटवर्क की जांच करने के लिए ट्रेनिंग डेटासेट का इस्तेमाल करना, धोखाधड़ी होगी. मॉडल, ट्रेनिंग के दौरान उस डेटासेट को कई बार देख चुका है. इसलिए, वह उस डेटासेट पर बेहतर परफ़ॉर्म कर सकता है. हमें एक और लेबल किए गए डेटासेट की ज़रूरत होती है. इसे ट्रेनिंग के दौरान कभी नहीं देखा गया. इससे नेटवर्क की "असल दुनिया" में परफ़ॉर्मेंस का आकलन किया जा सकता है. इसे "पुष्टि करने वाला डेटासेट" कहा जाता है
ट्रेनिंग
ट्रेनिंग के दौरान, एक बार में ट्रेनिंग डेटा का एक बैच इस्तेमाल किया जाता है. इससे मॉडल के इंटरनल पैरामीटर अपडेट होते हैं. साथ ही, मॉडल, हाथ से लिखे गए अंकों को बेहतर तरीके से पहचानने लगता है. इसे ट्रेनिंग ग्राफ़ पर देखा जा सकता है:
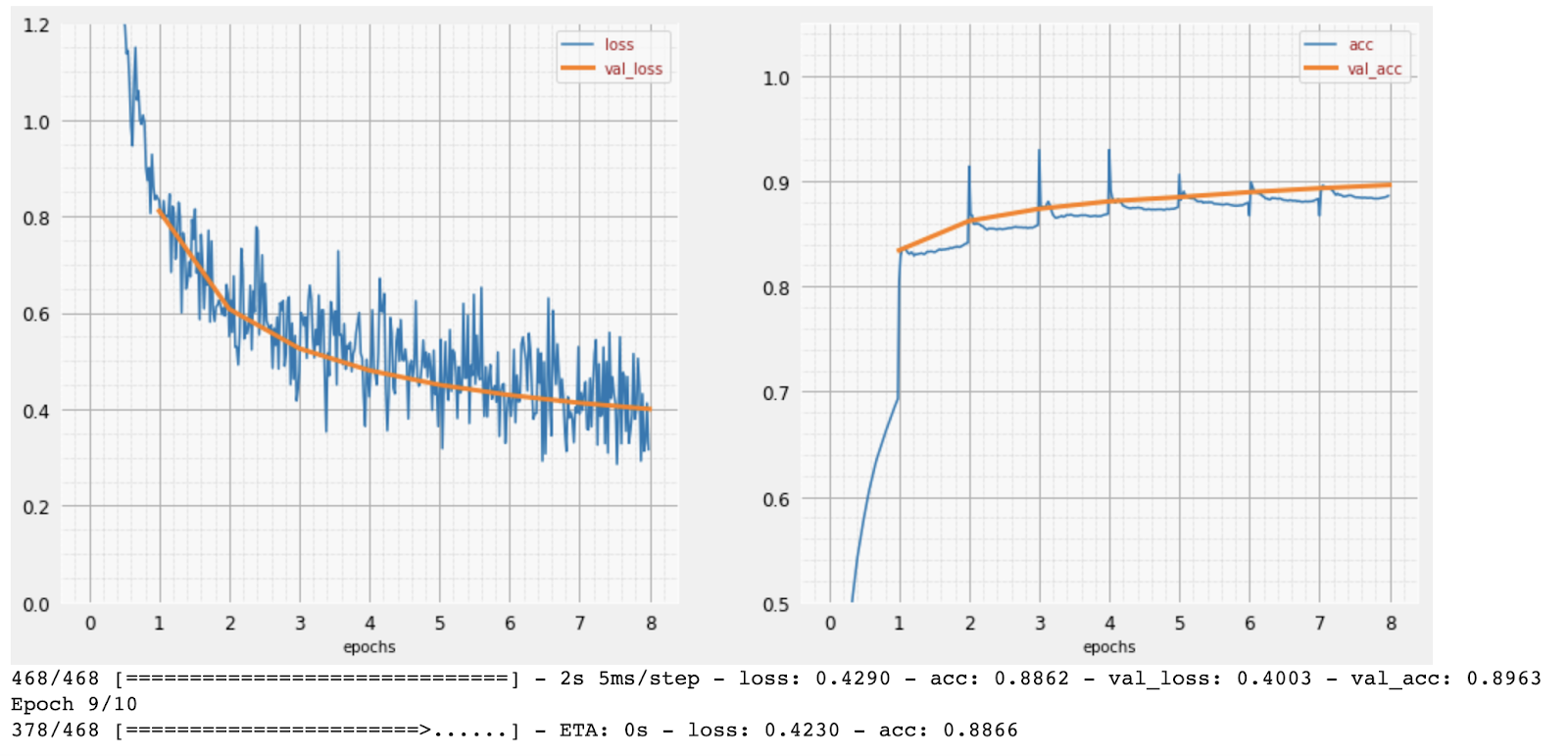
दाईं ओर, "सटीकता" से मतलब, सही तरीके से पहचाने गए अंकों के प्रतिशत से है. ट्रेनिंग की प्रोसेस आगे बढ़ने के साथ-साथ यह बढ़ता है, जो कि अच्छी बात है.
बाईं ओर, हमें "नुकसान" दिख रहा है. ट्रेनिंग के लिए, हम "लॉस" फ़ंक्शन तय करेंगे. इससे पता चलेगा कि सिस्टम, अंकों को कितनी खराब तरीके से पहचानता है. हम इसे कम करने की कोशिश करेंगे. यहां आपको दिखेगा कि ट्रेनिंग के दौरान, ट्रेनिंग और पुष्टि, दोनों के डेटा में नुकसान कम होता जाता है. यह अच्छी बात है. इसका मतलब है कि न्यूरल नेटवर्क सीख रहा है.
X-ऐक्सिस, पूरे डेटासेट में "युगों" या पुनरावृत्तियों की संख्या को दिखाता है.
अनुमानित
मॉडल को ट्रेन करने के बाद, हम इसका इस्तेमाल हाथ से लिखे गए अंकों की पहचान करने के लिए कर सकते हैं. अगले विज़ुअलाइज़ेशन में दिखाया गया है कि यह स्थानीय फ़ॉन्ट से रेंडर किए गए कुछ अंकों (पहली लाइन) पर कैसा परफ़ॉर्म करता है. इसके बाद, यह पुष्टि करने वाले डेटासेट के 10,000 अंकों पर कैसा परफ़ॉर्म करता है. अनुमानित क्लास हर अंक के नीचे दिखती है. अगर यह गलत है, तो लाल रंग में दिखती है.

जैसा कि आप देख सकते हैं, यह शुरुआती मॉडल बहुत अच्छा नहीं है. हालांकि, यह कुछ अंकों को सही तरीके से पहचानता है. इसकी पुष्टि करने की आखिरी सटीकता करीब 90% है. यह उस आसान मॉडल के लिए बहुत अच्छी है जिसका इस्तेमाल हम शुरू कर रहे हैं. हालांकि, इसका मतलब यह भी है कि यह 10,000 में से 1,000 पुष्टि करने वाले अंकों का पता नहीं लगा पाता. यह संख्या, दिखाए जा सकने वाले जवाबों की संख्या से बहुत ज़्यादा है. इसलिए, ऐसा लगता है कि सभी जवाब गलत (लाल रंग में) हैं.
टेंसर
डेटा को मैट्रिक्स में सेव किया जाता है. 28x28 पिक्सल की ग्रेस्केल इमेज, 28x28 की दो डाइमेंशन वाली मैट्रिक्स में फ़िट हो जाती है. हालांकि, रंगीन इमेज के लिए हमें ज़्यादा डाइमेंशन की ज़रूरत होती है. हर पिक्सल के लिए तीन रंग की वैल्यू (लाल, हरा, नीला) होती हैं. इसलिए, डाइमेंशन [28, 28, 3] वाली तीन डाइमेंशन वाली टेबल की ज़रूरत होगी. साथ ही, 128 रंगीन इमेज के बैच को सेव करने के लिए, चार डाइमेंशन वाली टेबल की ज़रूरत होती है. इसका डाइमेंशन [128, 28, 28, 3] होता है.
इन मल्टी-डाइमेंशनल टेबल को "टेंसर" कहा जाता है. साथ ही, इनके डाइमेंशन की सूची को इनका "शेप" कहा जाता है.
कम शब्दों में
अगर आपको अगले पैराग्राफ़ में बोल्ड किए गए सभी शब्दों के बारे में पहले से पता है, तो अगले अभ्यास पर जाएं. अगर आपने अभी-अभी डीप लर्निंग शुरू की है, तो आपका स्वागत है. कृपया आगे पढ़ें.

लेयर के क्रम के तौर पर बनाए गए मॉडल के लिए, Keras Sequential API उपलब्ध कराता है. उदाहरण के लिए, तीन डेंस लेयर का इस्तेमाल करने वाले इमेज क्लासिफ़ायर को Keras में इस तरह लिखा जा सकता है:
model = tf.keras.Sequential([
tf.keras.layers.Flatten(input_shape=[28, 28, 1]),
tf.keras.layers.Dense(200, activation="relu"),
tf.keras.layers.Dense(60, activation="relu"),
tf.keras.layers.Dense(10, activation='softmax') # classifying into 10 classes
])
# this configures the training of the model. Keras calls it "compiling" the model.
model.compile(
optimizer='adam',
loss= 'categorical_crossentropy',
metrics=['accuracy']) # % of correct answers
# train the model
model.fit(dataset, ... )
एक डेंस लेयर
MNIST डेटासेट में हाथ से लिखे गए अंक, 28x28 पिक्सल की ग्रेस्केल इमेज होते हैं. इन्हें क्लासिफ़ाई करने का सबसे आसान तरीका यह है कि 28x28=784 पिक्सल को एक लेयर वाले न्यूरल नेटवर्क के लिए इनपुट के तौर पर इस्तेमाल किया जाए.
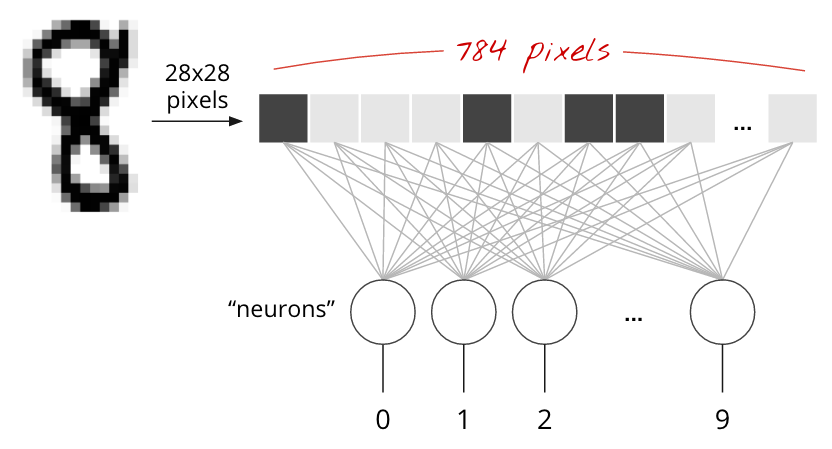
न्यूरल नेटवर्क में मौजूद हर "न्यूरॉन" , अपने सभी इनपुट का वेटेड सम करता है. इसके बाद, इसमें "बायस" नाम का एक कॉन्स्टेंट जोड़ता है. इसके बाद, यह नतीजे को किसी नॉन-लीनियर "ऐक्टिवेशन फ़ंक्शन" के ज़रिए आगे भेजता है. "weights" और "biases" ऐसे पैरामीटर हैं जिन्हें ट्रेनिंग के ज़रिए तय किया जाएगा. इन्हें शुरुआत में रैंडम वैल्यू के साथ शुरू किया जाता है.
ऊपर दी गई तस्वीर में, एक लेयर वाला न्यूरल नेटवर्क दिखाया गया है. इसमें 10 आउटपुट न्यूरॉन हैं, क्योंकि हमें अंकों को 10 क्लास (0 से 9) में बांटना है.
मैट्रिक्स को गुणा करके
यहां बताया गया है कि इमेज के कलेक्शन को प्रोसेस करने वाली न्यूरल नेटवर्क लेयर को मैट्रिक्स मल्टिप्लिकेशन से कैसे दिखाया जा सकता है:
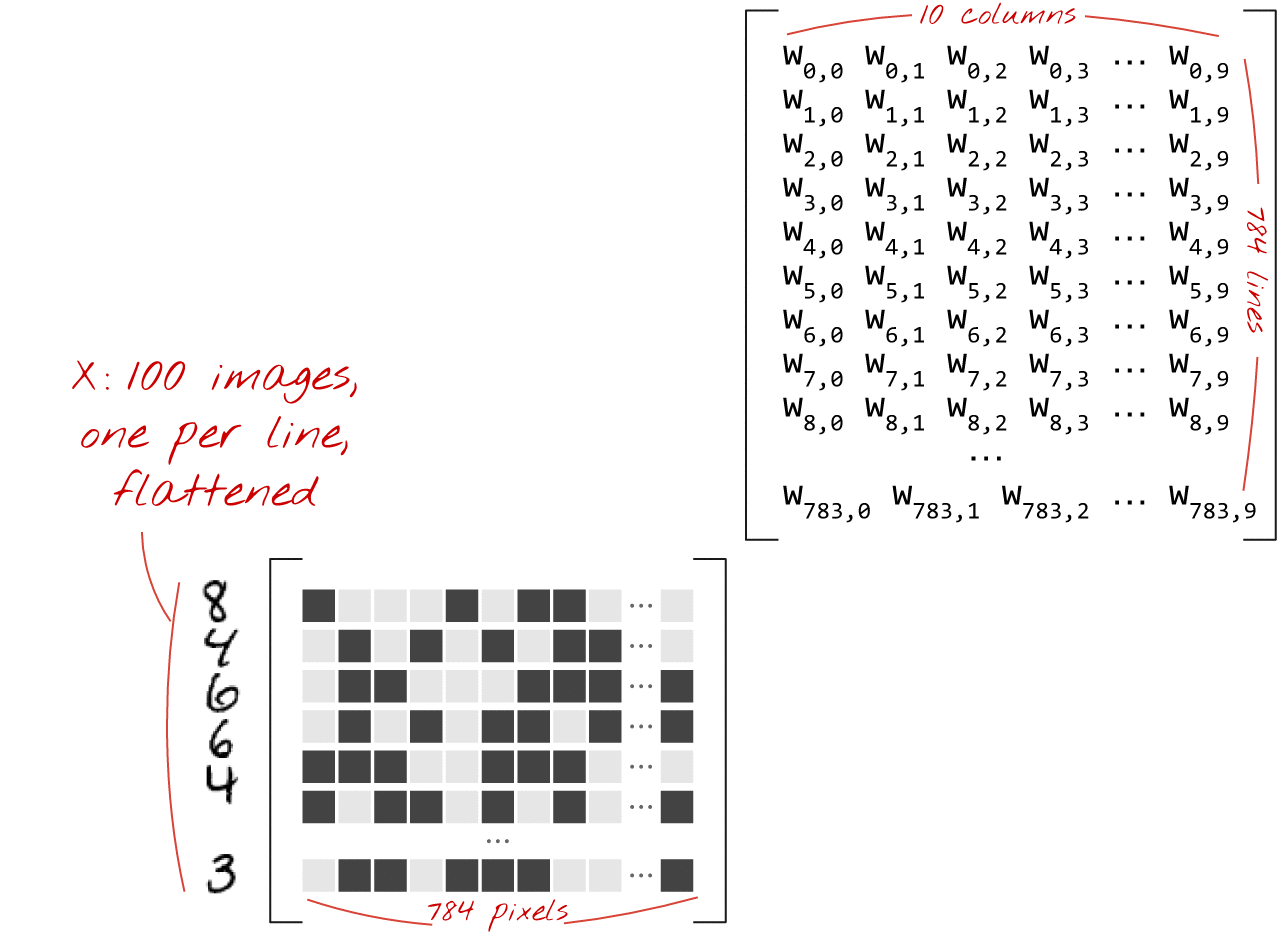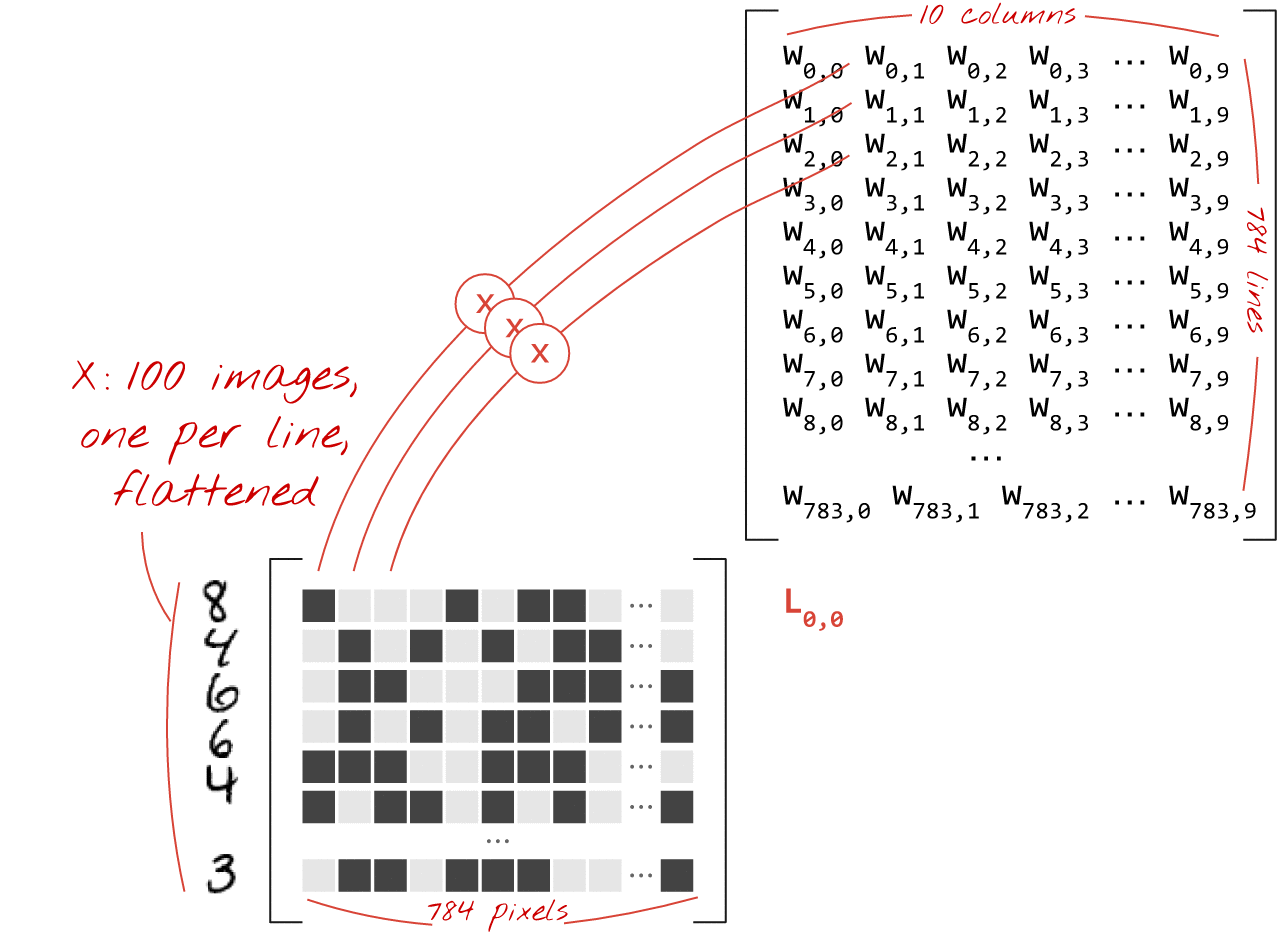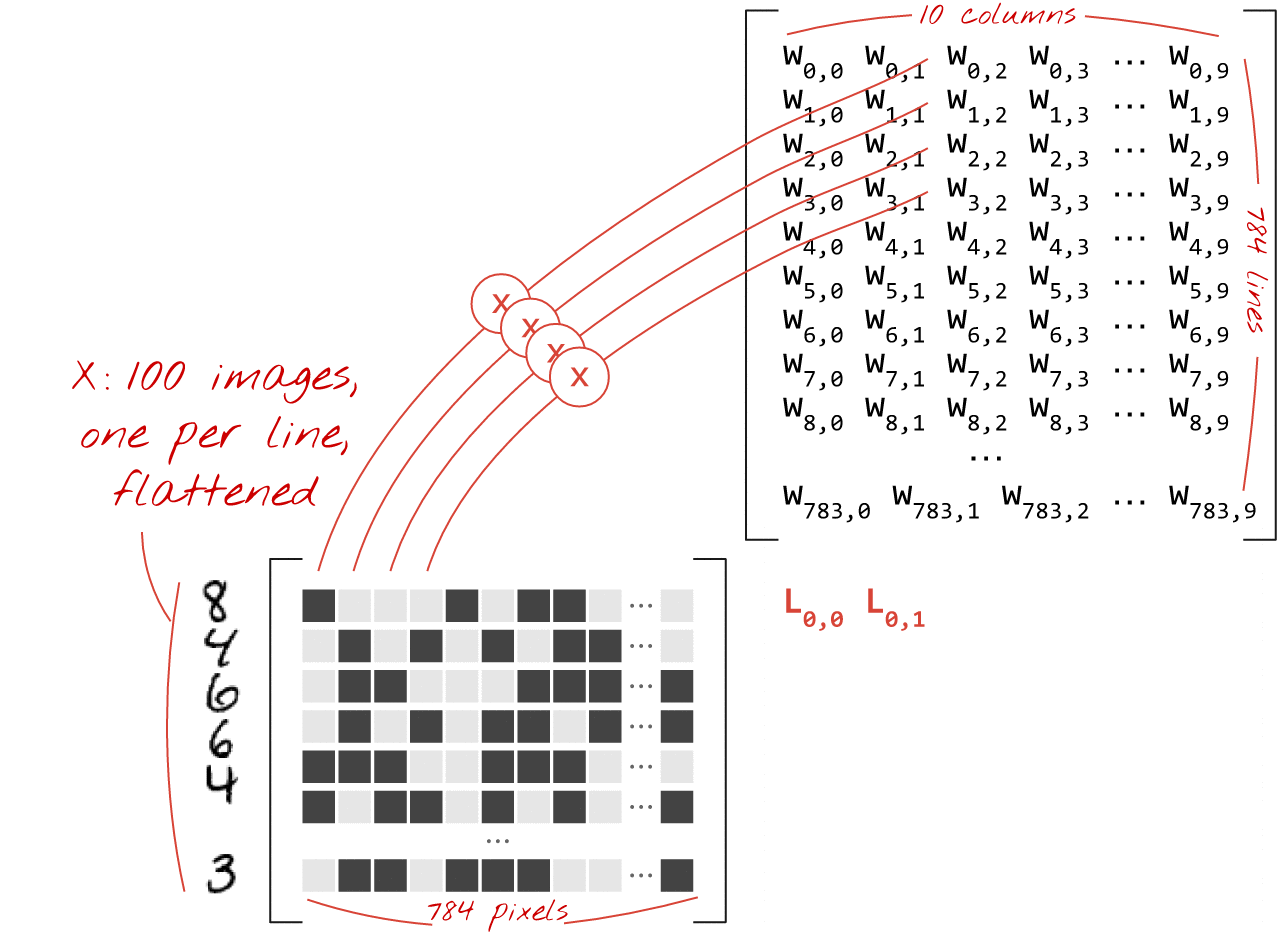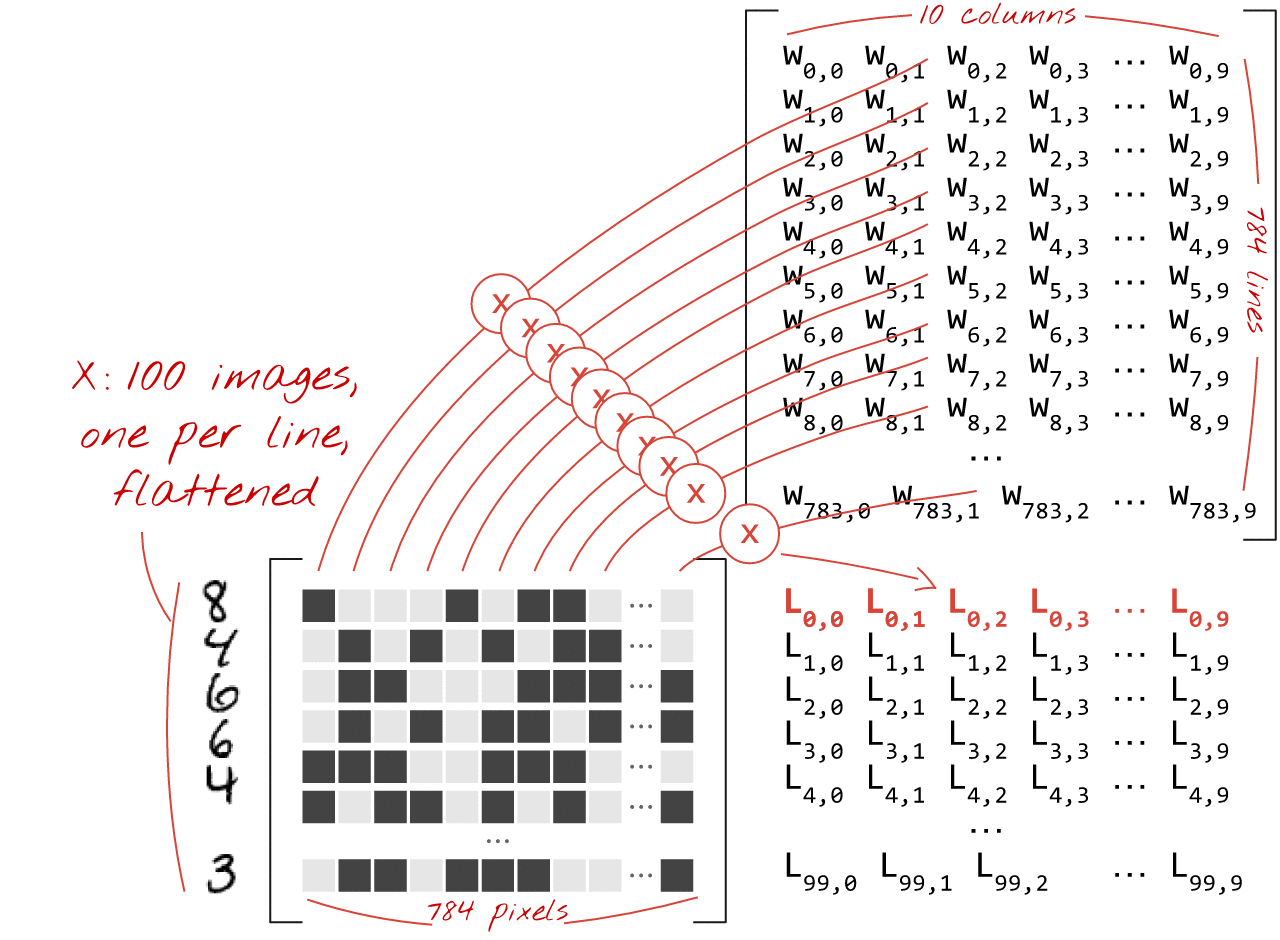
वज़न मैट्रिक्स W के पहले कॉलम का इस्तेमाल करके, हम पहली इमेज के सभी पिक्सल के वज़न का योग निकालते हैं. यह योग, पहले न्यूरॉन से मेल खाता है. वज़न के दूसरे कॉलम का इस्तेमाल करके, हम दूसरे न्यूरॉन के लिए भी यही प्रोसेस दोहराते हैं. ऐसा 10वें न्यूरॉन तक किया जाता है. इसके बाद, हम बाकी 99 इमेज के लिए यह प्रोसेस दोहरा सकते हैं. अगर हम 100 इमेज वाली मैट्रिक्स को X कहते हैं, तो हमारे 10 न्यूरॉन के लिए, 100 इमेज पर कैलकुलेट किए गए सभी वेटेड सम, मैट्रिक्स मल्टिप्लिकेशन X.W होते हैं.
अब हर न्यूरॉन को अपना बायस (एक कॉन्स्टेंट) जोड़ना होगा. हमारे पास 10 न्यूरॉन हैं. इसलिए, हमारे पास 10 बायस कॉन्स्टेंट हैं. हम 10 वैल्यू वाले इस वेक्टर को b कहेंगे. इसे पहले से कैलकुलेट की गई मैट्रिक्स की हर लाइन में जोड़ा जाना चाहिए. हम "ब्रॉडकास्टिंग" नाम की एक तकनीक का इस्तेमाल करके, इसे प्लस के निशान के साथ लिखेंगे.
आखिर में, हम एक्टिवेशन फ़ंक्शन लागू करते हैं. उदाहरण के लिए, "सॉफ़्टमैक्स" (इसके बारे में नीचे बताया गया है). इसके बाद, हमें 100 इमेज पर लागू किए गए, एक लेयर वाले न्यूरल नेटवर्क का फ़ॉर्मूला मिलता है:
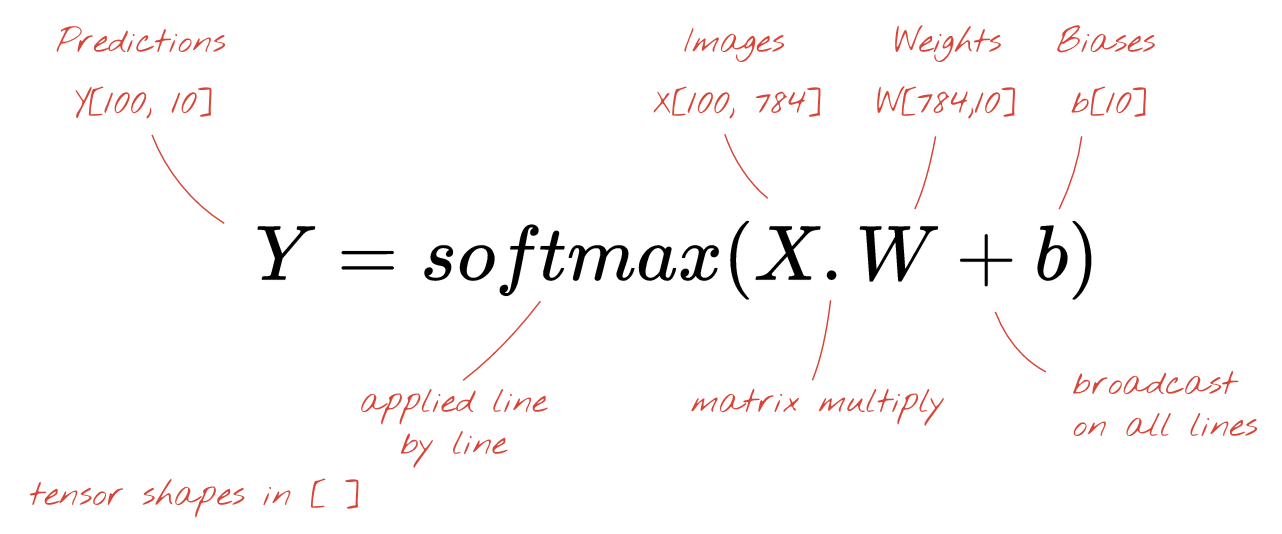
Keras में
Keras जैसी हाई-लेवल न्यूरल नेटवर्क लाइब्रेरी की मदद से, हमें इस फ़ॉर्मूले को लागू करने की ज़रूरत नहीं होगी. हालांकि, यह समझना ज़रूरी है कि न्यूरल नेटवर्क लेयर, सिर्फ़ गुणा और जोड़ की एक सीरीज़ होती है. Keras में, डेंस लेयर को इस तरह लिखा जाएगा:
tf.keras.layers.Dense(10, activation='softmax')ज़्यादा जानकारी
न्यूरल नेटवर्क लेयर को चेन करना आसान है. पहली लेयर, पिक्सल के वज़न के हिसाब से योग का हिसाब लगाती है. इसके बाद की लेयर, पिछली लेयर के आउटपुट के वेटेड सम का हिसाब लगाती हैं.
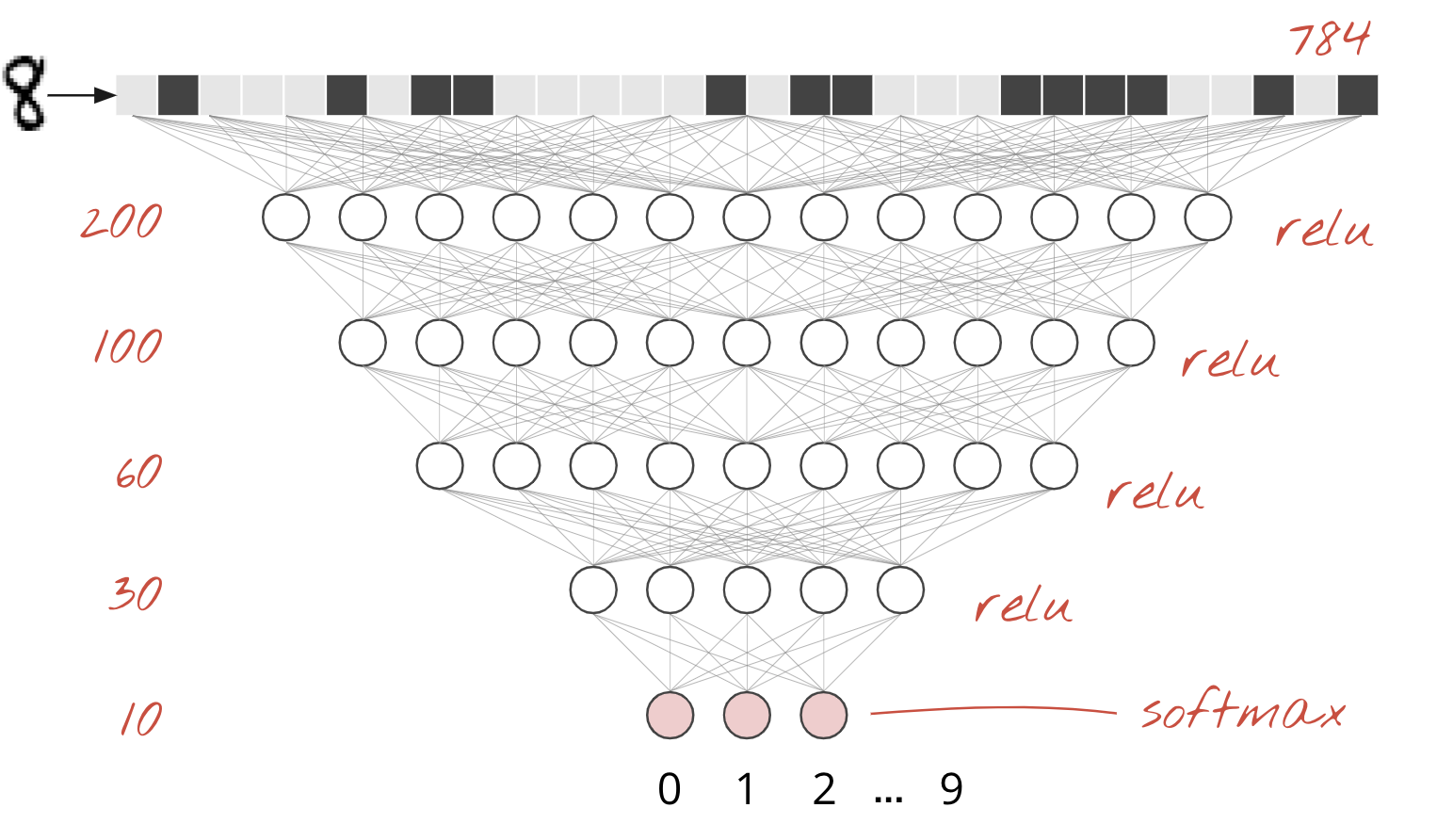
न्यूरॉन की संख्या के अलावा, दोनों मॉडल में सिर्फ़ ऐक्टिवेशन फ़ंक्शन का अंतर होगा.
ऐक्टिवेशन फ़ंक्शन: relu, softmax, और sigmoid
आम तौर पर, सभी लेयर के लिए "relu" ऐक्टिवेशन फ़ंक्शन का इस्तेमाल किया जाता है. हालांकि, आखिरी लेयर के लिए इसका इस्तेमाल नहीं किया जाता. क्लासिफ़ायर में, आखिरी लेयर "सॉफ्टमैक्स" ऐक्टिवेशन का इस्तेमाल करेगी.
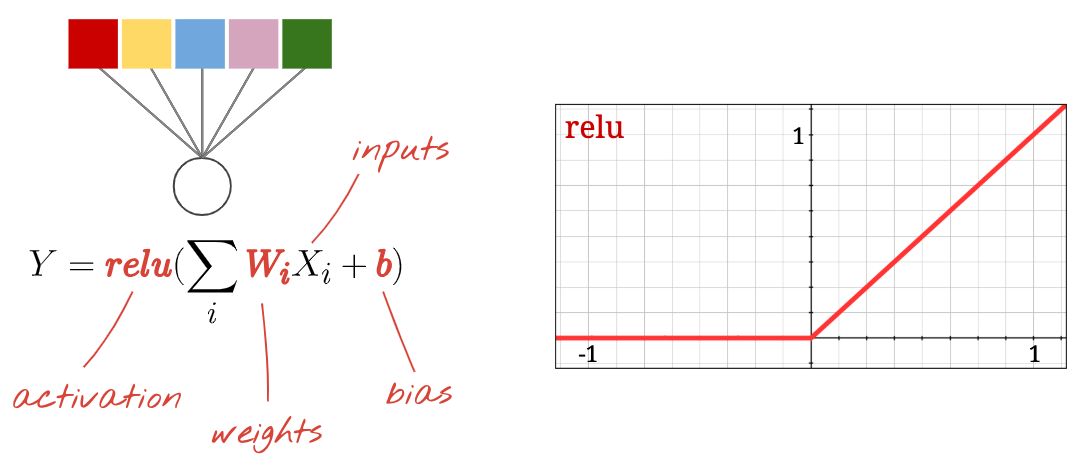
"न्यूरॉन" अपने सभी इनपुट का वेटेड सम कंप्यूट करता है. इसके बाद, इसमें "बायस" नाम की वैल्यू जोड़ता है और नतीजे को ऐक्टिवेशन फ़ंक्शन के ज़रिए आगे भेजता है.
सबसे ज़्यादा इस्तेमाल किए जाने वाले ऐक्टिवेशन फ़ंक्शन को रेक्टिफ़ाइड लीनियर यूनिट के लिए "RELU" कहा जाता है. यह एक बहुत ही आसान फ़ंक्शन है, जैसा कि ऊपर दिए गए ग्राफ़ में देखा जा सकता है.
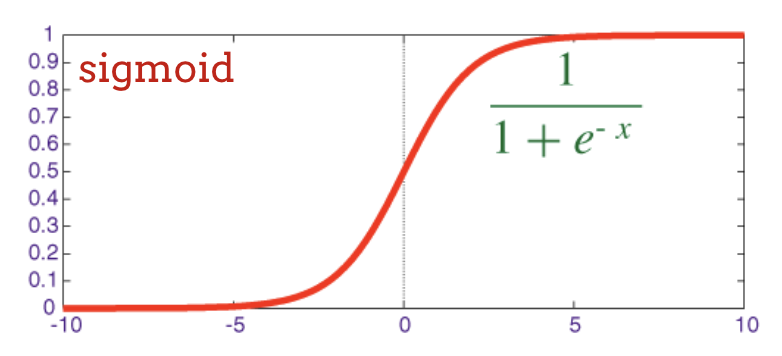
न्यूरल नेटवर्क में, ऐक्टिवेशन फ़ंक्शन के तौर पर "सिग्मॉइड" का इस्तेमाल किया जाता था. हालांकि, "relu" को ज़्यादातर मामलों में बेहतर कन्वर्जेंस प्रॉपर्टी के तौर पर दिखाया गया है. इसलिए, अब इसे प्राथमिकता दी जाती है.
क्लासिफ़िकेशन के लिए सॉफ़्टमैक्स ऐक्टिवेशन
हमारे न्यूरल नेटवर्क की आखिरी लेयर में 10 न्यूरॉन हैं, क्योंकि हमें हाथ से लिखे गए अंकों को 10 क्लास (0 से 9) में बांटना है. इसे 0 से 1 के बीच की 10 संख्याओं को आउटपुट करना चाहिए. ये संख्याएं, इस अंक के 0, 1, 2 वगैरह होने की संभावना को दिखाती हैं. इसके लिए, हम आखिरी लेयर पर "सॉफ़्टमैक्स" नाम के ऐक्टिवेशन फ़ंक्शन का इस्तेमाल करेंगे.
किसी वेक्टर पर सॉफ़्टमैक्स लागू करने के लिए, हर एलिमेंट का एक्सपोनेंशियल लिया जाता है.इसके बाद, वेक्टर को सामान्य किया जाता है. आम तौर पर, इसे इसके "L1" नॉर्म (यानी कि ऐब्सलूट वैल्यू का योग) से भाग दिया जाता है, ताकि सामान्य की गई वैल्यू का योग 1 हो और इसे संभावनाओं के तौर पर समझा जा सके.
एक्टिवेशन से पहले, आखिरी लेयर के आउटपुट को कभी-कभी "लॉजेट" कहा जाता है. अगर यह वेक्टर L = [L0, L1, L2, L3, L4, L5, L6, L7, L8, L9] है, तो:
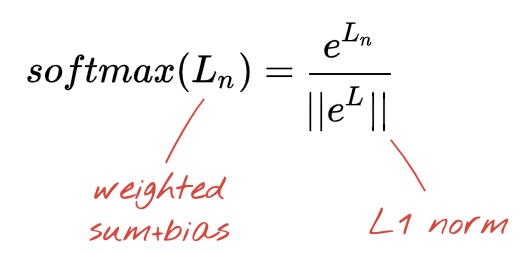
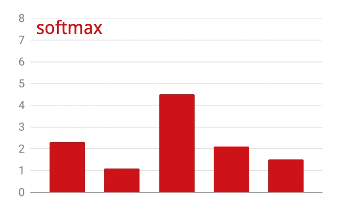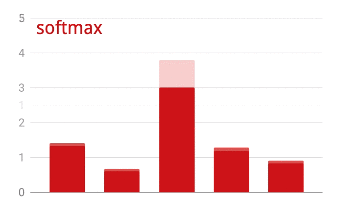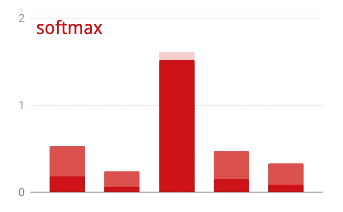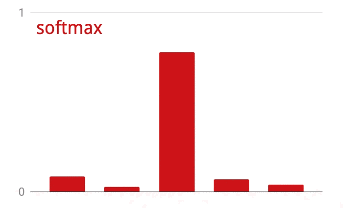
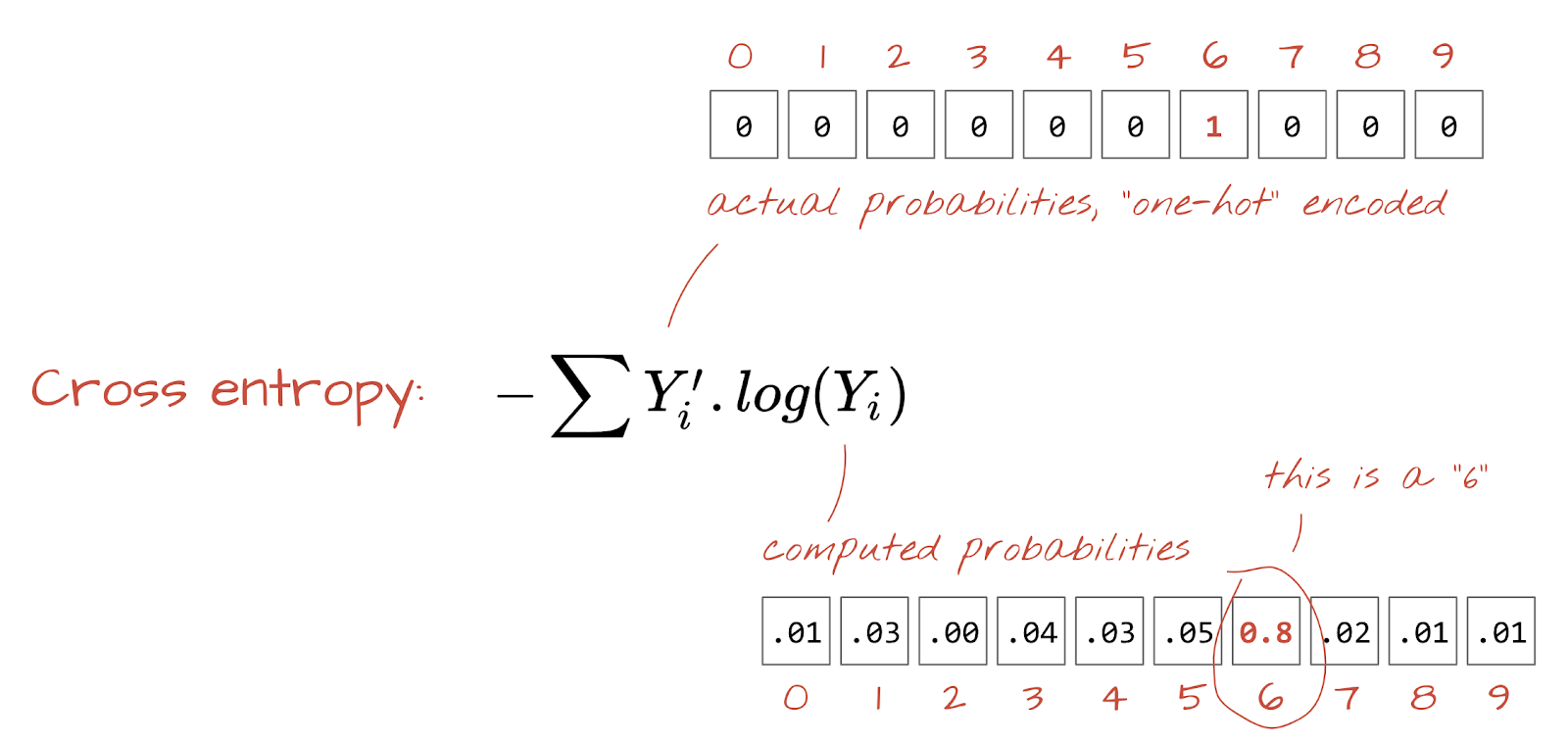
क्रॉस-एंट्रॉपी लॉस
अब हमारा न्यूरल नेटवर्क, इनपुट इमेज से अनुमान लगाता है. हमें यह मेज़र करना होगा कि ये अनुमान कितने सही हैं. इसका मतलब है कि नेटवर्क से मिले जवाब और सही जवाबों के बीच का अंतर. सही जवाबों को अक्सर "लेबल" कहा जाता है. ध्यान रखें कि हमारे पास डेटासेट में मौजूद सभी इमेज के लिए सही लेबल हैं.
कोई भी दूरी काम करेगी, लेकिन क्लासिफ़िकेशन की समस्याओं के लिए, "क्रॉस-एंट्रॉपी दूरी" सबसे असरदार होती है. हम इसे गड़बड़ी या "लॉस" फ़ंक्शन कहेंगे:
ग्रेडिएंट डिसेंट
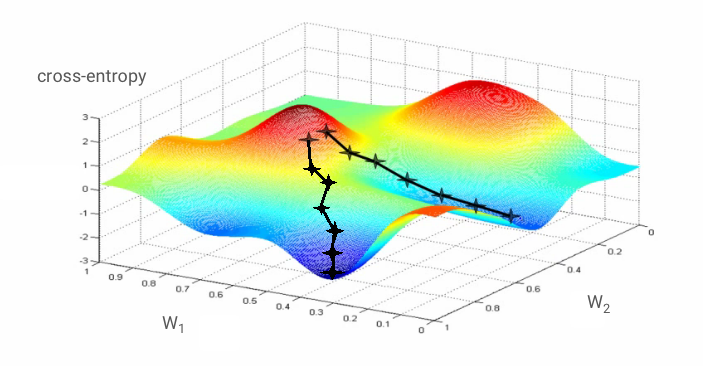
न्यूरल नेटवर्क को "ट्रेनिंग" देने का मतलब है कि ट्रेनिंग इमेज और लेबल का इस्तेमाल करके, वज़न और पूर्वाग्रहों को इस तरह से अडजस्ट किया जाए कि क्रॉस-एंट्रॉपी लॉस फ़ंक्शन को कम किया जा सके. यह सुविधा इस तरह से काम करती है.
क्रॉस-एंट्रॉपी, वेट, बायस, ट्रेनिंग इमेज के पिक्सल, और उसकी क्लास का फ़ंक्शन है.
अगर हम सभी वेट और सभी बायस के हिसाब से क्रॉस-एंट्रॉपी के पार्शियल डेरिवेटिव का हिसाब लगाते हैं, तो हमें "ग्रेडिएंट" मिलता है. इसका हिसाब किसी इमेज, लेबल, और वेट और बायस की मौजूदा वैल्यू के लिए किया जाता है. ध्यान रखें कि हमारे पास लाखों वेट और बायस हो सकते हैं. इसलिए, ग्रेडिएंट की गिनती करना बहुत मुश्किल काम लगता है. अच्छी बात यह है कि TensorFlow हमारे लिए यह काम करता है. ग्रेडिएंट की गणितीय प्रॉपर्टी यह है कि यह "ऊपर" की ओर इशारा करता है. हमें उस दिशा में जाना है जहां क्रॉस-एंट्रॉपी कम हो. इसलिए, हम विपरीत दिशा में जाते हैं. हम ग्रेडिएंट के कुछ हिस्से से वज़न और बायस को अपडेट करते हैं. इसके बाद, हम ट्रेनिंग लूप में ट्रेनिंग इमेज और लेबल के अगले बैच का इस्तेमाल करके, इसी प्रोसेस को बार-बार दोहराते हैं. उम्मीद है कि यह एक ऐसी जगह पर जाकर खत्म होगा जहां क्रॉस-एंट्रॉपी कम से कम हो. हालांकि, इस बात की कोई गारंटी नहीं है कि यह कम से कम वैल्यू यूनीक है.
मिनी-बैचिंग और मोमेंटम
सिर्फ़ एक उदाहरण इमेज पर ग्रेडिएंट का हिसाब लगाया जा सकता है. साथ ही, वज़न और पक्षपातों को तुरंत अपडेट किया जा सकता है. हालांकि, उदाहरण के लिए, 128 इमेज के बैच पर ऐसा करने से, एक ऐसा ग्रेडिएंट मिलता है जो अलग-अलग उदाहरण इमेज से जुड़ी पाबंदियों को बेहतर तरीके से दिखाता है. इसलिए, यह समाधान की ओर तेज़ी से बढ़ता है. मिनी-बैच का साइज़, अडजस्ट किया जा सकने वाला पैरामीटर होता है.
इस तकनीक को कभी-कभी "स्टोकास्टिक ग्रेडिएंट डिसेंट" भी कहा जाता है. इसका एक और फ़ायदा यह है कि बैच के साथ काम करने का मतलब है कि बड़ी मैट्रिक्स के साथ काम करना. इन्हें आम तौर पर जीपीयू और टीपीयू पर ऑप्टिमाइज़ करना आसान होता है.
हालांकि, कन्वर्जेंस अब भी थोड़ा गड़बड़ हो सकता है. साथ ही, अगर ग्रेडिएंट वेक्टर पूरी तरह से शून्य है, तो यह रुक भी सकता है. क्या इसका मतलब यह है कि हमें कम से कम एक गड़बड़ी मिली है? हमेशा नहीं. ग्रेडिएंट कॉम्पोनेंट की वैल्यू, कम से कम या ज़्यादा से ज़्यादा पर शून्य हो सकती है. लाखों एलिमेंट वाले ग्रेडिएंट वेक्टर में, अगर सभी एलिमेंट ज़ीरो हैं, तो इस बात की संभावना बहुत कम होती है कि हर ज़ीरो, कम से कम वैल्यू से मेल खाता हो और उनमें से कोई भी ज़्यादा से ज़्यादा वैल्यू से मेल न खाता हो. कई डाइमेंशन वाले स्पेस में, सैडल पॉइंट काफ़ी सामान्य होते हैं और हम इन पर नहीं रुकना चाहते.
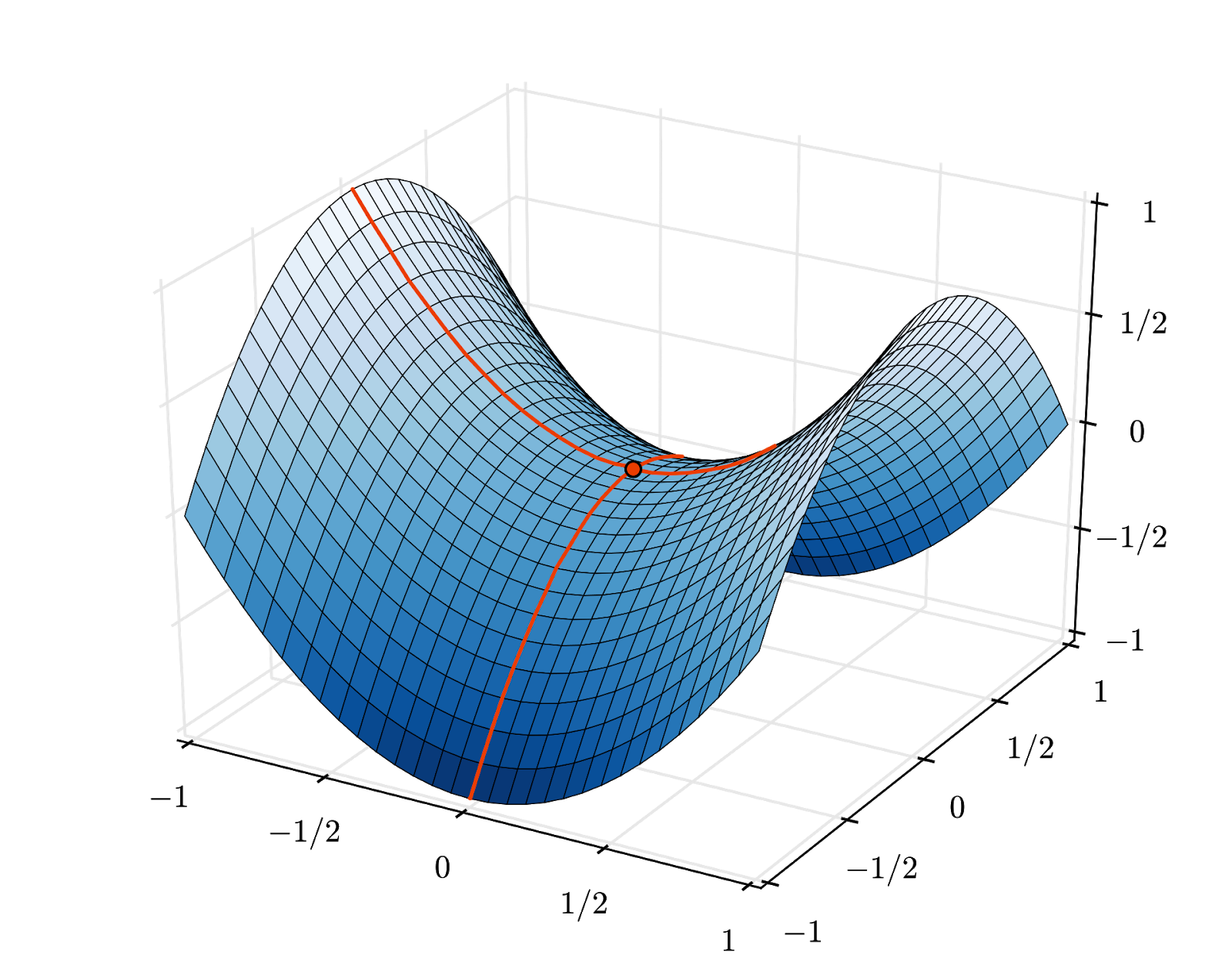
इलस्ट्रेशन: सैडल पॉइंट. ग्रेडिएंट 0 है, लेकिन यह सभी दिशाओं में कम से कम नहीं है. (इमेज एट्रिब्यूशन Wikimedia: By Nicoguaro - Own work, CC BY 3.0)
इसका समाधान यह है कि ऑप्टिमाइज़ेशन एल्गोरिदम में कुछ मोमेंटम जोड़ा जाए, ताकि वह बिना रुके सैडल पॉइंट को पार कर सके.
शब्दावली
बैच या मिनी-बैच: ट्रेनिंग हमेशा ट्रेनिंग डेटा और लेबल के बैच पर की जाती है. ऐसा करने से, एल्गोरिदम को कन्वर्ज होने में मदद मिलती है. "बैच" डाइमेंशन, आम तौर पर डेटा टेंसर का पहला डाइमेंशन होता है. उदाहरण के लिए, [100, 192, 192, 3] शेप वाले टेंसर में, 192x192 पिक्सल की 100 इमेज होती हैं. हर पिक्सल की तीन वैल्यू (आरजीबी) होती हैं.
क्रॉस-एंट्रॉपी लॉस: यह एक खास लॉस फ़ंक्शन है, जिसका इस्तेमाल अक्सर क्लासिफ़ायर में किया जाता है.
डेंस लेयर: न्यूरॉन की एक लेयर, जिसमें हर न्यूरॉन पिछली लेयर के सभी न्यूरॉन से जुड़ा होता है.
विशेषताएं: न्यूरल नेटवर्क के इनपुट को कभी-कभी "विशेषताएं" कहा जाता है. डेटासेट के किन हिस्सों (या हिस्सों के कॉम्बिनेशन) को न्यूरल नेटवर्क में डाला जाए, ताकि अच्छी तरह से अनुमान लगाया जा सके, इस कला को "फ़ीचर इंजीनियरिंग" कहा जाता है.
लेबल: सुपरवाइज़्ड क्लासिफ़िकेशन की समस्या में "क्लास" या सही जवाब के लिए इस्तेमाल किया जाने वाला दूसरा नाम
लर्निंग रेट: यह ग्रेडिएंट का वह हिस्सा होता है जिससे ट्रेनिंग लूप के हर इटरेशन में वज़न और बायस अपडेट किए जाते हैं.
लॉजेट: ऐक्टिवेशन फ़ंक्शन लागू होने से पहले, न्यूरॉन की लेयर के आउटपुट को "लॉजेट" कहा जाता है. यह शब्द, "लॉजिस्टिक फ़ंक्शन" से लिया गया है. इसे "सिग्मॉइड फ़ंक्शन" भी कहा जाता है. यह सबसे ज़्यादा इस्तेमाल किया जाने वाला ऐक्टिवेशन फ़ंक्शन था. "लॉजिस्टिक फ़ंक्शन से पहले न्यूरॉन आउटपुट" को छोटा करके "लॉजिट" कर दिया गया है.
loss: यह एक गड़बड़ी वाला फ़ंक्शन है. यह न्यूरल नेटवर्क के आउटपुट की तुलना सही जवाबों से करता है
न्यूरॉन: यह अपने इनपुट का वेटेड सम कंप्यूट करता है, इसमें एक बायस जोड़ता है, और नतीजे को ऐक्टिवेशन फ़ंक्शन के ज़रिए फ़ीड करता है.
वन-हॉट एन्कोडिंग: पांच में से क्लास 3 को पांच एलिमेंट वाले वेक्टर के तौर पर एन्कोड किया जाता है. इसमें तीसरे एलिमेंट को छोड़कर बाकी सभी एलिमेंट शून्य होते हैं.
relu: रेक्टिफ़ाइड लीनियर यूनिट. यह न्यूरॉन के लिए एक लोकप्रिय ऐक्टिवेशन फ़ंक्शन है.
sigmoid: यह एक और ऐक्टिवेशन फ़ंक्शन है. यह पहले काफ़ी लोकप्रिय था और अब भी कुछ खास मामलों में काम आता है.
softmax: यह एक खास ऐक्टिवेशन फ़ंक्शन है, जो वेक्टर पर काम करता है. यह सबसे बड़े कॉम्पोनेंट और अन्य सभी कॉम्पोनेंट के बीच के अंतर को बढ़ाता है. साथ ही, वेक्टर को सामान्य बनाता है, ताकि उसका योग 1 हो. इससे वेक्टर को संभावनाओं के वेक्टर के तौर पर समझा जा सकता है. इसका इस्तेमाल क्लासिफ़ायर में आखिरी चरण के तौर पर किया जाता है.
टेंसर: "टेंसर" मैट्रिक्स की तरह होता है, लेकिन इसमें डाइमेंशन की संख्या तय नहीं होती. एक डाइमेंशन वाला टेंसर, वेक्टर होता है. दो डाइमेंशन वाला टेंसर, मैट्रिक्स होता है. इसके बाद, आपके पास 3, 4, 5 या इससे ज़्यादा डाइमेंशन वाले टेंसर हो सकते हैं.
अब हम स्टडी नोटबुक पर वापस जाते हैं और इस बार, कोड पढ़ते हैं.
आइए, इस नोटबुक की सभी सेल पर एक नज़र डालते हैं.
"पैरामीटर" सेल
यहां बैच का साइज़, ट्रेनिंग के इपॉक की संख्या, और डेटा फ़ाइलों की जगह तय की जाती है. डेटा फ़ाइलें, Google Cloud Storage (GCS) बकेट में होस्ट की जाती हैं. इसलिए, उनके पते की शुरुआत gs:// से होती है
"इंपोर्ट" सेल
यहां सभी ज़रूरी Python लाइब्रेरी इंपोर्ट की जाती हैं. इनमें TensorFlow और विज़ुअलाइज़ेशन के लिए matplotlib भी शामिल है.
सेल "विज़ुअलाइज़ेशन यूटिलिटी [RUN ME]"
इस सेल में, विज़ुअलाइज़ेशन का ऐसा कोड मौजूद है जो काम का नहीं है. यह डिफ़ॉल्ट रूप से छोटा किया गया होता है. हालांकि, आपके पास इसे खोलने और कोड देखने का विकल्प होता है. इसके लिए, इस पर दो बार क्लिक करें.
सेल "tf.data.Dataset: parse files and prepare training and validation datasets"
इस सेल में, डेटा फ़ाइलों से MNIST डेटासेट लोड करने के लिए, tf.data.Dataset API का इस्तेमाल किया गया है. इस सेल पर ज़्यादा समय बिताने की ज़रूरत नहीं है. अगर आपको tf.data.Dataset API के बारे में जानना है, तो यहां एक ट्यूटोरियल दिया गया है. इसमें इसके बारे में बताया गया है: टीपीयू की स्पीड से डेटा पाइपलाइन तैयार करना. फ़िलहाल, बुनियादी बातें ये हैं:
MNIST डेटासेट की इमेज और लेबल (सही जवाब), चार फ़ाइलों में तय लंबाई के रिकॉर्ड में सेव किए जाते हैं. फ़ाइलों को, तय किए गए रिकॉर्ड फ़ंक्शन की मदद से लोड किया जा सकता है:
imagedataset = tf.data.FixedLengthRecordDataset(image_filename, 28*28, header_bytes=16)अब हमारे पास इमेज बाइट का डेटासेट है. इन्हें इमेज में डिकोड करना होगा. इसके लिए, हम एक फ़ंक्शन तय करते हैं. इमेज को कंप्रेस नहीं किया जाता है, इसलिए फ़ंक्शन को किसी भी चीज़ को डिकोड करने की ज़रूरत नहीं होती (decode_raw का मतलब है कि कुछ नहीं करना). इसके बाद, इमेज को 0 और 1 के बीच की फ़्लोटिंग पॉइंट वैल्यू में बदल दिया जाता है. हम इसे यहां 2D इमेज के तौर पर फिर से आकार दे सकते हैं. हालांकि, हम इसे 28*28 साइज़ के पिक्सल के फ़्लैट ऐरे के तौर पर रखते हैं, क्योंकि हमारी शुरुआती डेंस लेयर यही उम्मीद करती है.
def read_image(tf_bytestring):
image = tf.decode_raw(tf_bytestring, tf.uint8)
image = tf.cast(image, tf.float32)/256.0
image = tf.reshape(image, [28*28])
return imageहम .map का इस्तेमाल करके, इस फ़ंक्शन को डेटासेट पर लागू करते हैं और हमें इमेज का डेटासेट मिलता है:
imagedataset = imagedataset.map(read_image, num_parallel_calls=16)हम लेबल के लिए भी इसी तरह से पढ़ने और डिकोड करने की प्रोसेस का इस्तेमाल करते हैं. साथ ही, हम .zip इमेज और लेबल को एक साथ इस्तेमाल करते हैं:
dataset = tf.data.Dataset.zip((imagedataset, labelsdataset))अब हमारे पास इमेज और लेबल के जोड़े का डेटासेट है. हमारे मॉडल को इसी तरह के इनपुट की ज़रूरत होती है. हम अभी ट्रेनिंग फ़ंक्शन में इसका इस्तेमाल करने के लिए तैयार नहीं हैं:
dataset = dataset.cache()
dataset = dataset.shuffle(5000, reshuffle_each_iteration=True)
dataset = dataset.repeat()
dataset = dataset.batch(batch_size)
dataset = dataset.prefetch(tf.data.experimental.AUTOTUNE)tf.data.Dataset API में, डेटासेट तैयार करने के लिए सभी ज़रूरी यूटिलिटी फ़ंक्शन होते हैं:
.cache, डेटासेट को रैम में कैश मेमोरी में सेव करता है. यह एक छोटा डेटासेट है, इसलिए यह काम करेगा. .shuffle इसे 5,000 एलिमेंट के बफ़र के साथ शफ़ल करता है. यह ज़रूरी है कि ट्रेनिंग के डेटा को अच्छी तरह से शफ़ल किया जाए. .repeat डेटासेट को लूप करता है. हम इस पर कई बार (कई इपोक) ट्रेनिंग देंगे. .batch, कई इमेज और लेबल को एक साथ मिलाकर मिनी-नैच बनाता है. आखिर में, .prefetch सीपीयू का इस्तेमाल करके अगले बैच को तैयार कर सकता है. इस दौरान, मौजूदा बैच को जीपीयू पर ट्रेन किया जाता है.
पुष्टि करने के लिए डेटासेट को भी इसी तरह तैयार किया जाता है. अब हम मॉडल को तय करने और उसे ट्रेनिंग देने के लिए इस डेटासेट का इस्तेमाल करने के लिए तैयार हैं.
"Keras Model" सेल
हमारे सभी मॉडल, लेयर के सीधे क्रम में होंगे, ताकि हम उन्हें बनाने के लिए tf.keras.Sequential स्टाइल का इस्तेमाल कर सकें. शुरुआत में, यहां एक ही लेयर होती है. इसमें 10 न्यूरॉन हैं, क्योंकि हमें हाथ से लिखे गए अंकों को 10 क्लास में बांटना है. इसमें "सॉफ़्टमैक्स" ऐक्टिवेशन का इस्तेमाल किया जाता है, क्योंकि यह क्लासिफ़ायर की आखिरी लेयर होती है.
Keras मॉडल को भी अपने इनपुट के शेप के बारे में पता होना चाहिए. इसे तय करने के लिए, tf.keras.layers.Input का इस्तेमाल किया जा सकता है. यहां, इनपुट वेक्टर, 28*28 लंबाई वाले पिक्सल वैल्यू के फ़्लैट वेक्टर हैं.
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(10, activation='softmax')
])
model.compile(optimizer='sgd',
loss='categorical_crossentropy',
metrics=['accuracy'])
# print model layers
model.summary()
# utility callback that displays training curves
plot_training = PlotTraining(sample_rate=10, zoom=1)मॉडल को Keras में model.compile फ़ंक्शन का इस्तेमाल करके कॉन्फ़िगर किया जाता है. यहां हम बेसिक ऑप्टिमाइज़र 'sgd' (स्टोकास्टिक ग्रेडिएंट डिसेंट) का इस्तेमाल करते हैं. क्लासिफ़िकेशन मॉडल के लिए, क्रॉस-एंट्रॉपी लॉस फ़ंक्शन की ज़रूरत होती है. इसे Keras में 'categorical_crossentropy' कहा जाता है. आखिर में, हम मॉडल से 'accuracy' मेट्रिक का हिसाब लगाने के लिए कहते हैं. यह मेट्रिक, सही तरीके से क्लासिफ़ाई की गई इमेज का प्रतिशत होती है.
Keras, model.summary() नाम की एक बहुत अच्छी यूटिलिटी उपलब्ध कराता है. यह यूटिलिटी, आपके बनाए गए मॉडल की जानकारी प्रिंट करती है. आपके इंस्ट्रक्टर ने PlotTraining यूटिलिटी जोड़ी है. इसे "विज़ुअलाइज़ेशन यूटिलिटी" सेल में तय किया गया है. इससे ट्रेनिंग के दौरान अलग-अलग ट्रेनिंग कर्व दिखेंगे.
"मॉडल को ट्रेन और पुष्टि करें" सेल
यहां ट्रेनिंग होती है. इसके लिए, model.fit को कॉल किया जाता है और ट्रेनिंग और पुष्टि करने वाले दोनों डेटासेट पास किए जाते हैं. डिफ़ॉल्ट रूप से, Keras हर युग के आखिर में पुष्टि का एक राउंड चलाता है.
model.fit(training_dataset, steps_per_epoch=steps_per_epoch, epochs=EPOCHS,
validation_data=validation_dataset, validation_steps=1,
callbacks=[plot_training])Keras में, ट्रेनिंग के दौरान कॉलबैक का इस्तेमाल करके, कस्टम व्यवहार जोड़े जा सकते हैं. इस वर्कशॉप के लिए, ट्रेनिंग के प्लॉट को डाइनैमिक तरीके से अपडेट करने की सुविधा को इस तरह लागू किया गया था.
"अनुमानों को विज़ुअलाइज़ करें" सेल
मॉडल को ट्रेन करने के बाद, model.predict() को कॉल करके उससे अनुमान पाए जा सकते हैं:
probabilities = model.predict(font_digits, steps=1)
predicted_labels = np.argmax(probabilities, axis=1)यहां हमने स्थानीय फ़ॉन्ट से रेंडर किए गए प्रिंट किए गए अंकों का एक सेट तैयार किया है, ताकि हम यह जांच कर सकें कि क्या यह काम करता है. ध्यान रखें कि न्यूरल नेटवर्क, अपने फ़ाइनल "सॉफ़्टमैक्स" से 10 संभावनाओं का वेक्टर दिखाता है. लेबल पाने के लिए, हमें यह पता लगाना होगा कि किस संभावना की वैल्यू सबसे ज़्यादा है. np.argmax फ़ंक्शन, numpy लाइब्रेरी से लिया गया है.
axis=1 पैरामीटर की ज़रूरत क्यों है, यह समझने के लिए कृपया याद रखें कि हमने 128 इमेज के बैच को प्रोसेस किया है. इसलिए, मॉडल संभावनाओं के 128 वेक्टर दिखाता है. आउटपुट टेंसर का आकार [128, 10] है. हम हर इमेज के लिए, 10 संभावनाओं में से सबसे बड़ी संभावना का पता लगा रहे हैं. इसलिए, axis=1 (पहला ऐक्सिस 0 है).
यह सामान्य मॉडल, 90% अंकों की पहचान पहले से ही कर लेता है. आपने अच्छा किया, लेकिन अब आप इसे और बेहतर बना पाएंगे.
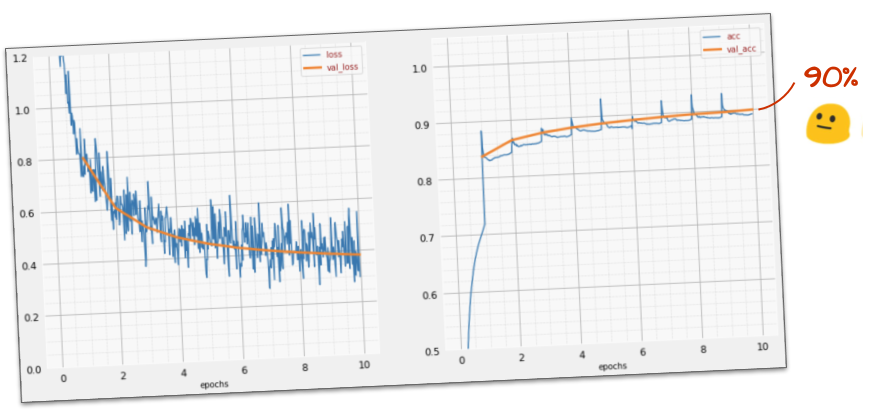

पहचानने की क्षमता को ज़्यादा सटीक बनाने के लिए, हम न्यूरल नेटवर्क में और लेयर जोड़ेंगे.
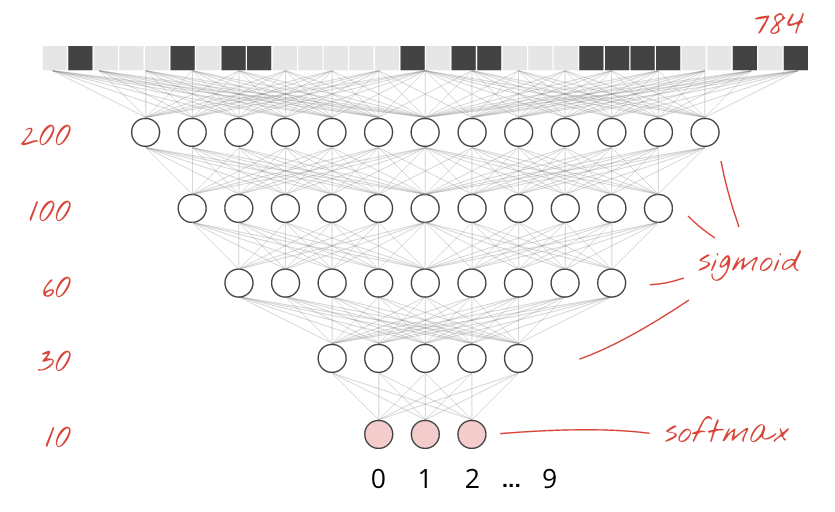
हम आखिरी लेयर पर ऐक्टिवेशन फ़ंक्शन के तौर पर सॉफ़्टमैक्स का इस्तेमाल करते हैं, क्योंकि यह क्लासिफ़िकेशन के लिए सबसे अच्छा काम करता है. हालांकि, इंटरमीडिएट लेयर पर हम सबसे क्लासिकल ऐक्टिवेशन फ़ंक्शन का इस्तेमाल करेंगे: सिग्मॉइड:
उदाहरण के लिए, आपका मॉडल ऐसा दिख सकता है. कॉमा लगाना न भूलें. tf.keras.Sequential में, कॉमा लगाकर अलग की गई लेयर की सूची होती है:
model = tf.keras.Sequential(
[
tf.keras.layers.Input(shape=(28*28,)),
tf.keras.layers.Dense(200, activation='sigmoid'),
tf.keras.layers.Dense(60, activation='sigmoid'),
tf.keras.layers.Dense(10, activation='softmax')
])अपने मॉडल की "खास जानकारी" देखें. अब इसमें कम से कम 10 गुना ज़्यादा पैरामीटर हैं. यह 10 गुना बेहतर होना चाहिए! हालांकि, किसी वजह से ऐसा नहीं हो रहा है ...
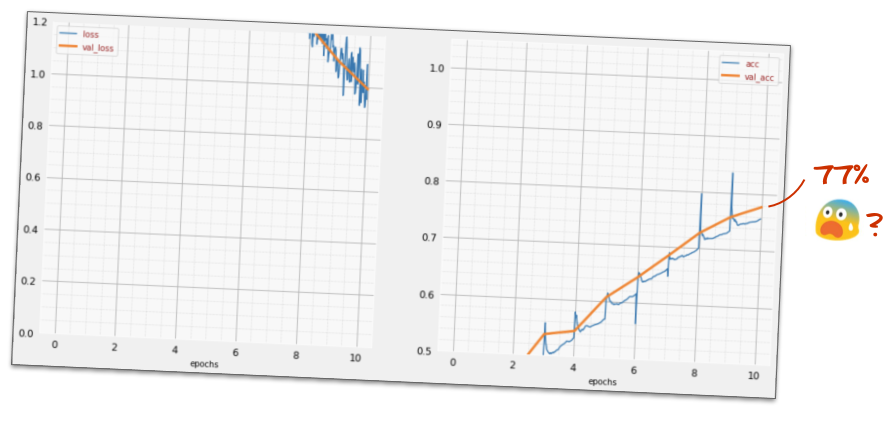
ऐसा लगता है कि नुकसान भी बहुत ज़्यादा हुआ है. कुछ गड़बड़ी हुई है.
आपने अभी न्यूरल नेटवर्क का अनुभव किया है. लोग 80 और 90 के दशक में इन्हें डिज़ाइन करते थे. इसलिए, उन्होंने इस आइडिया को छोड़ दिया और इसे "एआई विंटर" कहा जाने लगा. दरअसल, लेयर जोड़ने पर न्यूरल नेटवर्क को कन्वर्ज होने में ज़्यादा से ज़्यादा समस्याएं आती हैं.
यह पता चला है कि कई लेयर (आज 20, 50, यहां तक कि 100) वाले डीप न्यूरल नेटवर्क, बहुत अच्छी तरह से काम कर सकते हैं. हालांकि, इसके लिए कुछ गणितीय तरकीबों का इस्तेमाल करना पड़ता है, ताकि वे एक साथ काम कर सकें. इन आसान तरकीबों की खोज, 2010 के दशक में डीप लर्निंग के पुनर्जागरण की एक वजह है.
RELU ऐक्टिवेशन

सिग्मॉइड ऐक्टिवेशन फ़ंक्शन, डीप नेटवर्क में काफ़ी समस्याएं पैदा करता है. यह 0 और 1 के बीच की सभी वैल्यू को स्क्वैश करता है. ऐसा बार-बार करने पर, न्यूरॉन के आउटपुट और उनके ग्रेडिएंट पूरी तरह से गायब हो सकते हैं. इसे ऐतिहासिक वजहों से बताया गया था. हालांकि, आधुनिक नेटवर्क RELU (रेक्टिफ़ाइड लीनियर यूनिट) का इस्तेमाल करते हैं. यह इस तरह दिखता है:
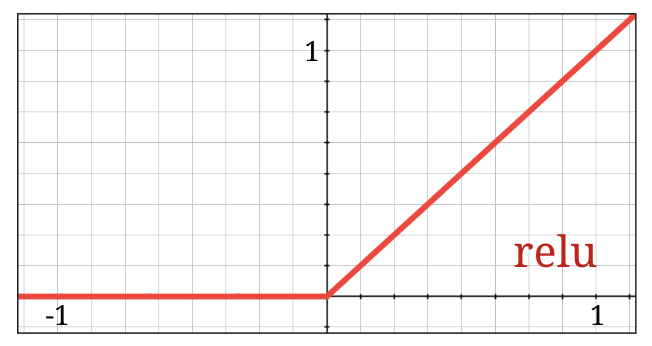
वहीं दूसरी ओर, relu का डेरिवेटिव कम से कम इसकी दाईं ओर 1 होता है. RELU ऐक्टिवेशन के साथ, भले ही कुछ न्यूरॉन से आने वाले ग्रेडिएंट शून्य हो सकते हैं, लेकिन हमेशा ऐसे न्यूरॉन मौजूद रहेंगे जो शून्य से अलग ग्रेडिएंट देंगे. इससे ट्रेनिंग अच्छी स्पीड से जारी रहेगी.
बेहतर ऑप्टिमाइज़र
यहां जैसे बहुत ज़्यादा डाइमेंशन वाले स्पेस में, "सैंडल पॉइंट" अक्सर होते हैं. हमारे पास 10 हज़ार से ज़्यादा वज़न और पूर्वाग्रह हैं. ये ऐसे पॉइंट होते हैं जो लोकल मिनिमम नहीं होते. हालांकि, यहां ग्रेडिएंट शून्य होता है और ग्रेडिएंट डिसेंट ऑप्टिमाइज़र यहीं पर रुक जाता है. TensorFlow में कई तरह के ऑप्टिमाइज़र उपलब्ध हैं. इनमें से कुछ ऑप्टिमाइज़र, इनर्शिया के साथ काम करते हैं और सैडल पॉइंट को आसानी से पार कर लेते हैं.
रैंडम तरीके से शुरू करना
ट्रेनिंग से पहले, वेट और बायस को शुरू करने की कला, अपने-आप में एक रिसर्च का विषय है. इस विषय पर कई पेपर पब्लिश किए गए हैं. Keras में उपलब्ध सभी इनिशियलाइज़र यहां देखे जा सकते हैं. अच्छी बात यह है कि Keras डिफ़ॉल्ट रूप से सही काम करता है और 'glorot_uniform' इनिशियलाइज़र का इस्तेमाल करता है. यह लगभग सभी मामलों में सबसे अच्छा होता है.
आपको कुछ भी करने की ज़रूरत नहीं है, क्योंकि Keras पहले से ही सही काम करता है.
NaN ???
क्रॉस-एंट्रॉपी फ़ॉर्मूले में लघुगणक शामिल होता है और log(0) एक संख्या नहीं है (NaN, अगर आपको पसंद है तो एक संख्यात्मक क्रैश). क्या क्रॉस-एंट्रॉपी के लिए इनपुट 0 हो सकता है? इनपुट, सॉफ़्टमैक्स से मिलता है. यह एक एक्सपोनेशियल फ़ंक्शन है और एक्सपोनेशियल फ़ंक्शन की वैल्यू कभी भी शून्य नहीं होती. इसलिए, हम सुरक्षित हैं!
वाकई? गणित की खूबसूरत दुनिया में, हम सुरक्षित रहेंगे. हालांकि, कंप्यूटर की दुनिया में, फ़्लोट32 फ़ॉर्मैट में दिखाए गए exp(-150) की वैल्यू शून्य होती है. इसलिए, क्रॉस-एंट्रॉपी क्रैश हो जाती है.
अच्छी बात यह है कि आपको यहां भी कुछ नहीं करना है, क्योंकि Keras इसका ध्यान रखता है. साथ ही, यह खास तरीके से सॉफ़्टमैक्स और उसके बाद क्रॉस-एंट्रॉपी का हिसाब लगाता है, ताकि यह पक्का किया जा सके कि संख्या स्थिर है और NaN से बचा जा सके.
क्या यह काम कर रहा है?
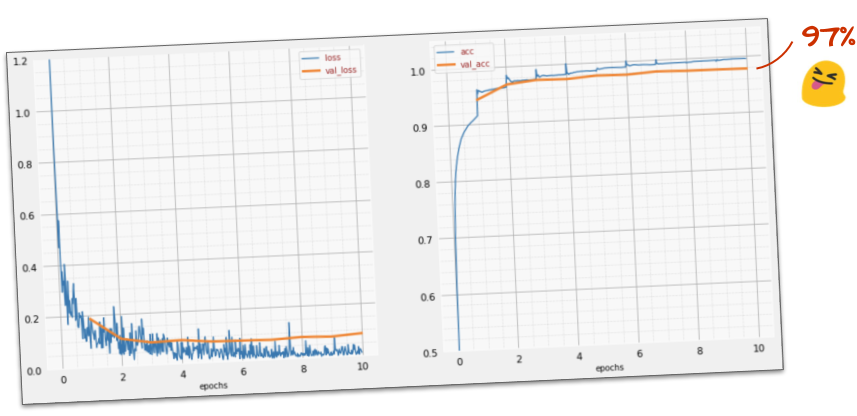
अब आपको 97% तक सटीक नतीजे मिलने चाहिए. इस वर्कशॉप का लक्ष्य, 99% से ज़्यादा स्कोर पाना है. इसलिए, आइए आगे बढ़ते हैं.
अगर आपको कोई समस्या आ रही है, तो यहां दिए गए तरीके से इसे हल करें:
क्या हम मॉडल को तेज़ी से ट्रेन करने की कोशिश कर सकते हैं? Adam ऑप्टिमाइज़र में डिफ़ॉल्ट लर्निंग रेट 0.001 होता है. आइए, इसे बढ़ाने की कोशिश करते हैं.
तेज़ी से चलने पर, ज़्यादा मदद नहीं मिलती. यह आवाज़ कैसी है?
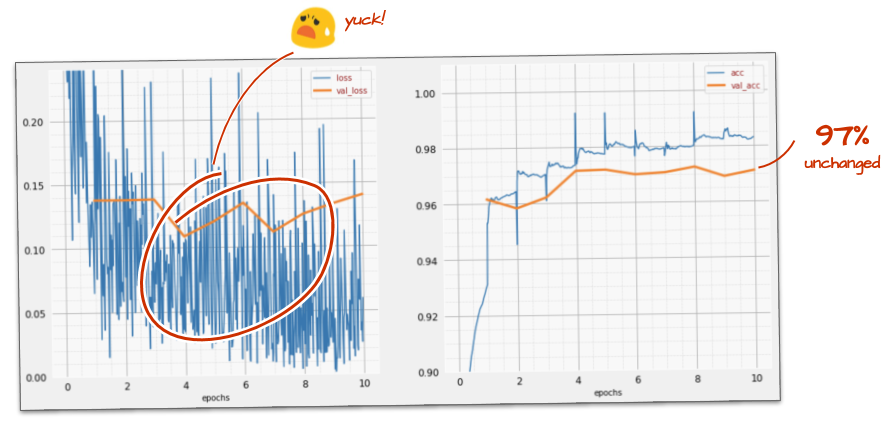
ट्रेनिंग कर्व में बहुत ज़्यादा उतार-चढ़ाव है. साथ ही, दोनों पुष्टि करने वाले कर्व में भी उतार-चढ़ाव दिख रहा है. इसका मतलब है कि हम बहुत तेज़ी से आगे बढ़ रहे हैं. हम अपनी पिछली स्पीड पर वापस जा सकते हैं, लेकिन इससे बेहतर तरीका भी है.

सबसे सही तरीका यह है कि लर्निंग रेट को तेज़ी से शुरू किया जाए और इसे तेज़ी से कम किया जाए. Keras में, tf.keras.callbacks.LearningRateScheduler कॉलबैक का इस्तेमाल करके ऐसा किया जा सकता है.
कॉपी करके चिपकाने के लिए काम का कोड:
# lr decay function
def lr_decay(epoch):
return 0.01 * math.pow(0.6, epoch)
# lr schedule callback
lr_decay_callback = tf.keras.callbacks.LearningRateScheduler(lr_decay, verbose=True)
# important to see what you are doing
plot_learning_rate(lr_decay, EPOCHS)आपने जो lr_decay_callback बनाया है उसका इस्तेमाल करना न भूलें. इसे model.fit में मौजूद, कॉलबैक की सूची में जोड़ें:
model.fit(..., callbacks=[plot_training, lr_decay_callback])इस छोटे से बदलाव का असर काफ़ी ज़्यादा है. आपको दिखेगा कि ज़्यादातर आवाज़ें हट गई हैं और टेस्ट की सटीकता अब लगातार 98% से ज़्यादा है.
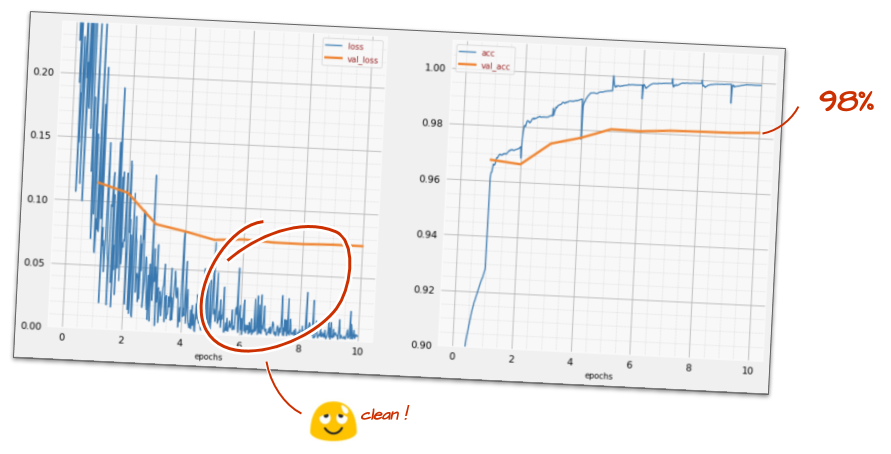
ऐसा लगता है कि मॉडल अब ठीक से काम कर रहा है. आइए, इसके बारे में और ज़्यादा जानें.
क्या इससे मदद मिलती है?
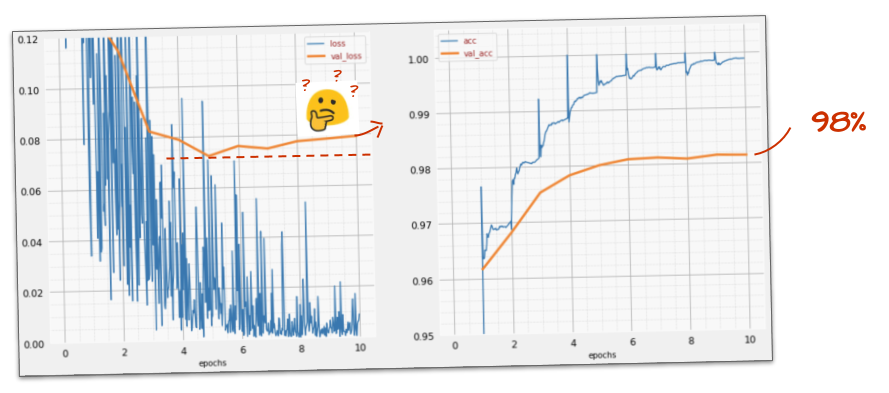
ऐसा नहीं है. अब भी सटीकता 98% पर है और पुष्टि करने के दौरान होने वाले नुकसान को देखें. यह बढ़ रहा है! लर्निंग एल्गोरिदम सिर्फ़ ट्रेनिंग डेटा पर काम करता है और ट्रेनिंग लॉस को उसी के हिसाब से ऑप्टिमाइज़ करता है. इसे कभी भी पुष्टि करने वाला डेटा नहीं दिखता. इसलिए, इसमें कोई हैरानी की बात नहीं है कि कुछ समय बाद, इसके काम का असर पुष्टि करने वाले नुकसान पर नहीं पड़ता. इससे नुकसान कम होना बंद हो जाता है और कभी-कभी तो नुकसान फिर से बढ़ने लगता है.
इससे आपके मॉडल की, असल दुनिया की चीज़ों को पहचानने की क्षमताओं पर तुरंत कोई असर नहीं पड़ता. हालांकि, इससे आपको कई बार ट्रेनिंग चलाने से रोका जाएगा. आम तौर पर, यह इस बात का संकेत होता है कि ट्रेनिंग का अब कोई फ़ायदा नहीं हो रहा है.

इस तरह के डिसकनेक्ट को आम तौर पर "ओवरफ़िटिंग" कहा जाता है. ऐसा होने पर, "ड्रॉपआउट" नाम की रेगुलराइज़ेशन तकनीक लागू की जा सकती है. ड्रॉपआउट तकनीक, ट्रेनिंग के हर इटरेशन में रैंडम न्यूरॉन को बंद कर देती है.
क्या इसने काम किया?
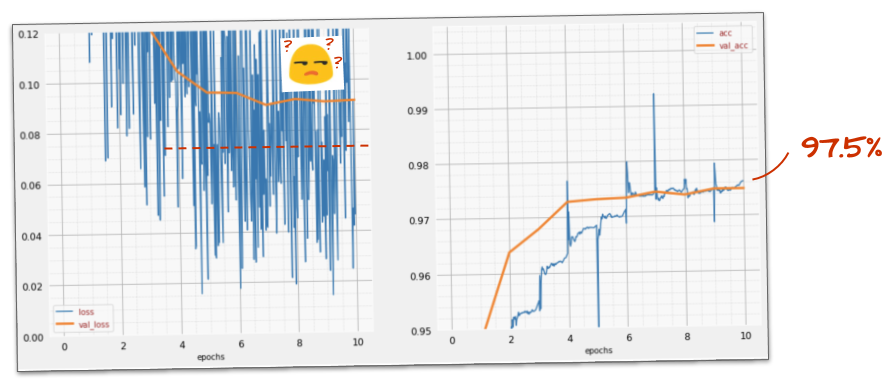
नॉइज़ फिर से दिखने लगता है. ऐसा इसलिए होता है, क्योंकि ड्रॉपआउट इसी तरह काम करता है. ऐसा लगता है कि अब पुष्टि करने के दौरान होने वाले नुकसान में बढ़ोतरी नहीं हो रही है. हालांकि, यह ड्रॉपआउट के बिना होने वाले नुकसान से ज़्यादा है. साथ ही, पुष्टि करने की सटीकता में थोड़ी गिरावट आई है. यह नतीजा काफ़ी निराशाजनक है.
ऐसा लगता है कि ड्रॉपआउट सही समाधान नहीं था. ऐसा भी हो सकता है कि "ओवरफ़िटिंग" एक ज़्यादा जटिल कॉन्सेप्ट है और इसकी कुछ वजहों को "ड्रॉपआउट" से ठीक नहीं किया जा सकता?
"ओवरफ़िटिंग" क्या है? ओवरफ़िटिंग तब होती है, जब कोई न्यूरल नेटवर्क "गलत" तरीके से सीखता है. इसका मतलब है कि वह ट्रेनिंग के उदाहरणों के लिए तो काम करता है, लेकिन असल दुनिया के डेटा के लिए उतना अच्छा नहीं होता. ड्रॉपआउट जैसी रेगुलराइज़ेशन तकनीकें हैं, जो इसे बेहतर तरीके से सीखने के लिए मजबूर कर सकती हैं. हालांकि, ओवरफ़िटिंग की समस्या भी काफ़ी गंभीर है.

बेसिक ओवरफ़िटिंग तब होती है, जब किसी न्यूरल नेटवर्क में मौजूद समस्या के लिए, बहुत ज़्यादा डिग्री ऑफ़ फ़्रीडम होती है. मान लें कि हमारे पास इतने न्यूरॉन हैं कि नेटवर्क, ट्रेनिंग के लिए इस्तेमाल की गई सभी इमेज को उनमें सेव कर सकता है. इसके बाद, पैटर्न मैचिंग के ज़रिए उन्हें पहचान सकता है. यह असल दुनिया के डेटा पर पूरी तरह से काम नहीं करेगा. न्यूरल नेटवर्क को कुछ हद तक सीमित किया जाना चाहिए, ताकि ट्रेनिंग के दौरान सीखी गई जानकारी को सामान्य बनाया जा सके.
अगर आपके पास ट्रेनिंग के लिए बहुत कम डेटा है, तो छोटा नेटवर्क भी उसे आसानी से सीख सकता है. ऐसे में, आपको "ओवरफ़िटिंग" दिखेगी. आम तौर पर, न्यूरल नेटवर्क को ट्रेन करने के लिए हमेशा बहुत ज़्यादा डेटा की ज़रूरत होती है.
आखिर में, अगर आपने सभी ज़रूरी काम कर लिए हैं, नेटवर्क के अलग-अलग साइज़ के साथ एक्सपेरिमेंट किया है, ड्रॉपआउट लागू किया है, और बहुत सारे डेटा पर ट्रेनिंग दी है, तो हो सकता है कि आप अब भी परफ़ॉर्मेंस के उस लेवल पर अटके हों जिसमें कोई सुधार नहीं हो रहा है. इसका मतलब है कि आपका न्यूरल नेटवर्क, मौजूदा स्थिति में आपके डेटा से ज़्यादा जानकारी नहीं निकाल सकता. जैसा कि यहां हमारे मामले में है.
याद रखें कि हम अपनी इमेज का इस्तेमाल कैसे कर रहे हैं, जिन्हें एक वेक्टर में फ़्लैट किया गया है? यह बहुत बुरा आइडिया था. हाथ से लिखे गए अंक, अलग-अलग शेप से बने होते हैं. पिक्सल को फ़्लैट करते समय, हमने शेप की जानकारी को हटा दिया था. हालांकि, एक तरह का न्यूरल नेटवर्क होता है, जो शेप की जानकारी का फ़ायदा उठा सकता है: कनवोल्यूशनल नेटवर्क. आइए, इन्हें आज़माकर देखें.
अगर आपको कोई समस्या आ रही है, तो यहां दिए गए तरीके से इसे हल करें:
कम शब्दों में
अगर आपको अगले पैराग्राफ़ में बोल्ड किए गए सभी शब्दों के बारे में पहले से पता है, तो अगले अभ्यास पर जाएं. अगर आपने हाल ही में कनवोल्यूशनल न्यूरल नेटवर्क का इस्तेमाल शुरू किया है, तो कृपया आगे पढ़ें.
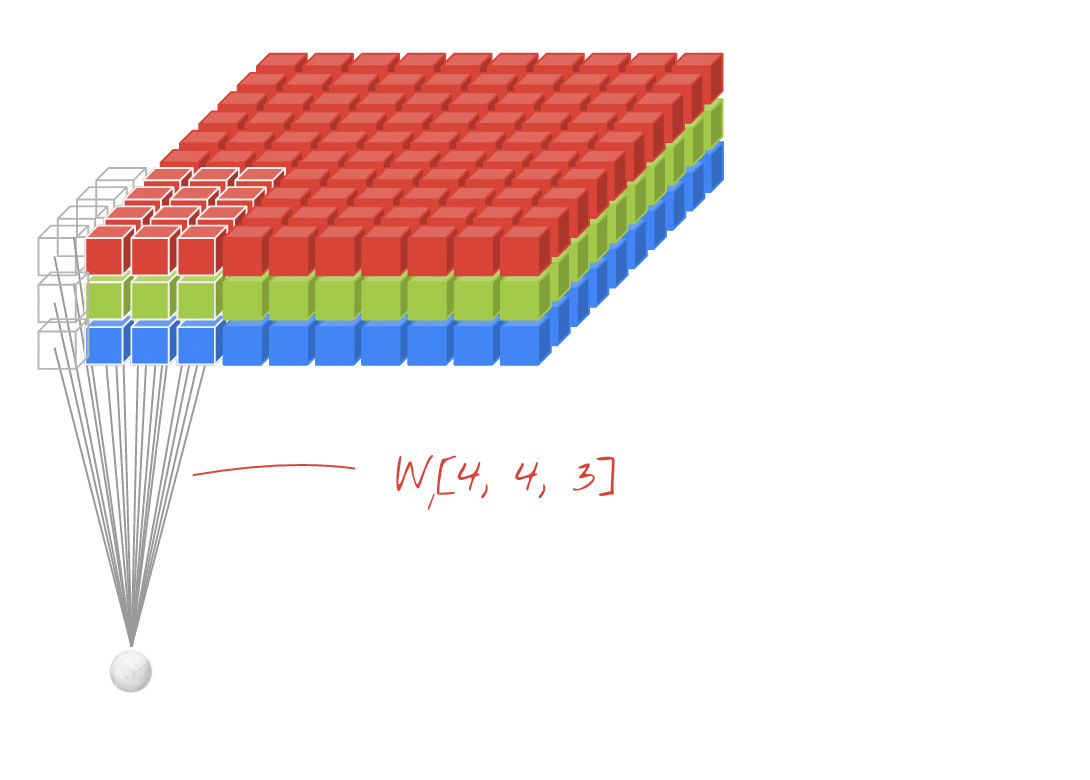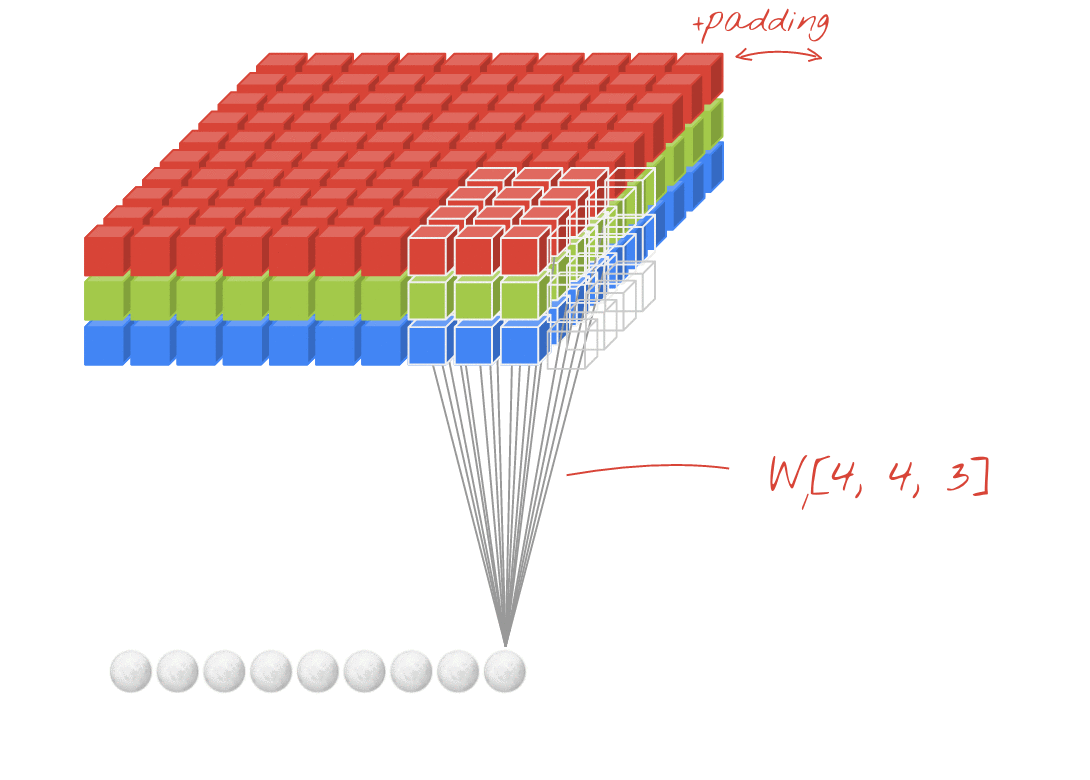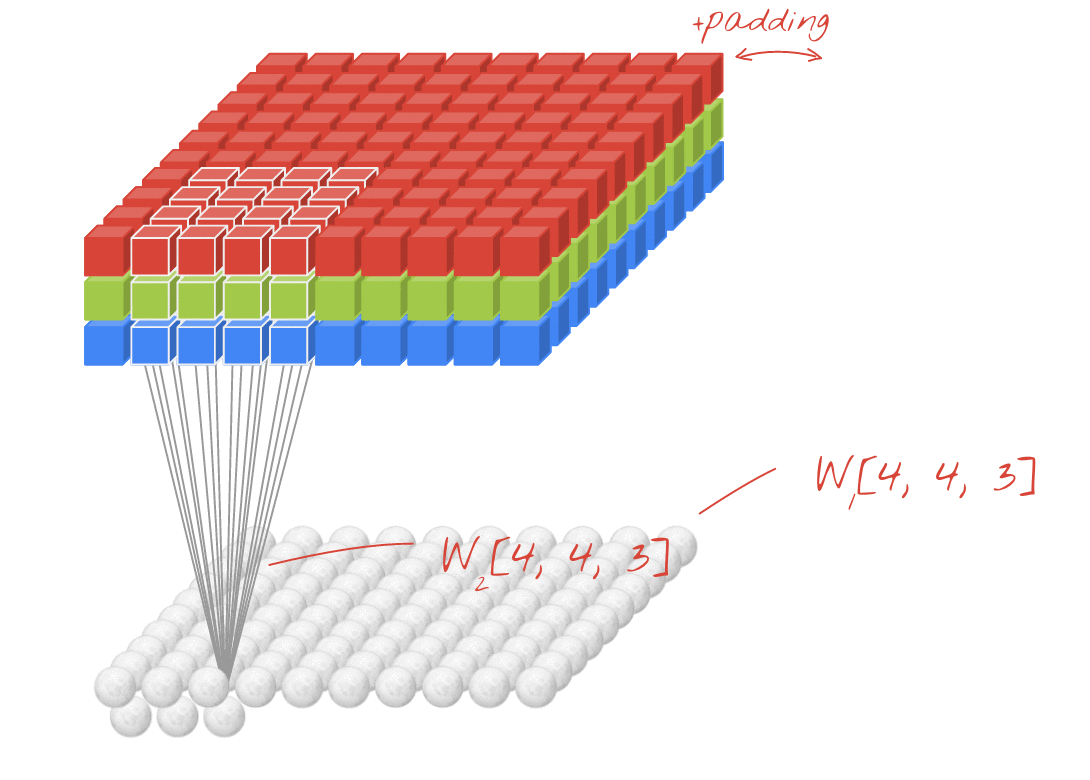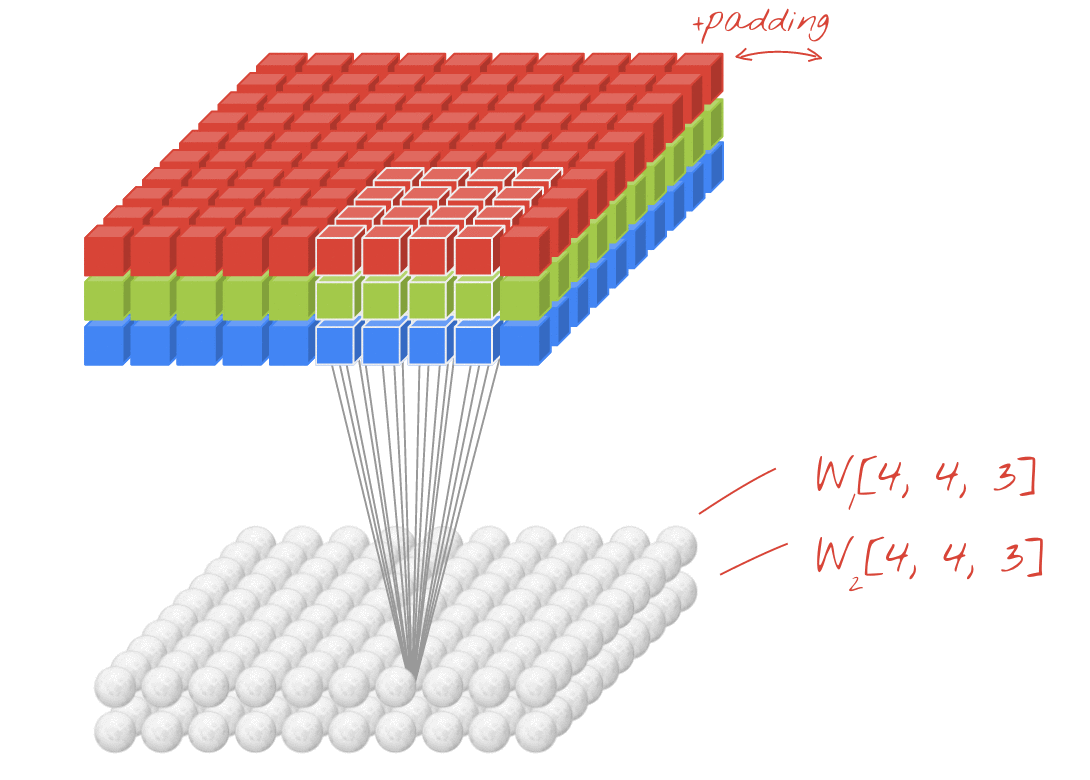
इलस्ट्रेशन: किसी इमेज को दो फ़िल्टर की मदद से फ़िल्टर किया जा रहा है. हर फ़िल्टर में 4x4x3=48 लर्निंग वेट हैं.
Keras में, एक सामान्य कनवोल्यूशनल न्यूरल नेटवर्क इस तरह दिखता है:
model = tf.keras.Sequential([
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1)),
tf.keras.layers.Conv2D(kernel_size=3, filters=12, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=24, strides=2, activation='relu'),
tf.keras.layers.Conv2D(kernel_size=6, filters=32, strides=2, activation='relu'),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(10, activation='softmax')
])
कनवोल्यूशनल नेटवर्क की किसी लेयर में, एक "न्यूरॉन" सिर्फ़ इमेज के छोटे से हिस्से में, ठीक ऊपर मौजूद पिक्सल का वेटेड सम करता है. यह एक पूर्वाग्रह जोड़ता है और सम को ऐक्टिवेशन फ़ंक्शन के ज़रिए फ़ीड करता है. ठीक उसी तरह जैसे किसी रेगुलर डेंस लेयर में न्यूरॉन करता है. इसके बाद, इस ऑपरेशन को पूरी इमेज पर दोहराया जाता है. इसके लिए, एक ही वज़न का इस्तेमाल किया जाता है. याद रखें कि डेंस लेयर में, हर न्यूरॉन के अपने वेट होते हैं. यहां, वज़न का एक "पैच", इमेज पर दोनों दिशाओं में स्लाइड करता है ("कनवोल्यूशन"). आउटपुट में उतनी ही वैल्यू होती हैं जितने इमेज में पिक्सल होते हैं. हालांकि, किनारों पर कुछ पैडिंग ज़रूरी होती है. यह फ़िल्टर करने की कार्रवाई है. ऊपर दिए गए इलस्ट्रेशन में, 4x4x3=48 वज़न वाले फ़िल्टर का इस्तेमाल किया गया है.
हालांकि, 48 वैल्यू काफ़ी नहीं होंगी. ज़्यादा डिग्री ऑफ़ फ़्रीडम जोड़ने के लिए, हम वज़न के नए सेट के साथ उसी ऑपरेशन को दोहराते हैं. इससे फ़िल्टर किए गए डेटा का नया सेट मिलता है. हम इसे आउटपुट का "चैनल" कहेंगे. यह इनपुट इमेज में R,G,B चैनलों के जैसा होता है.
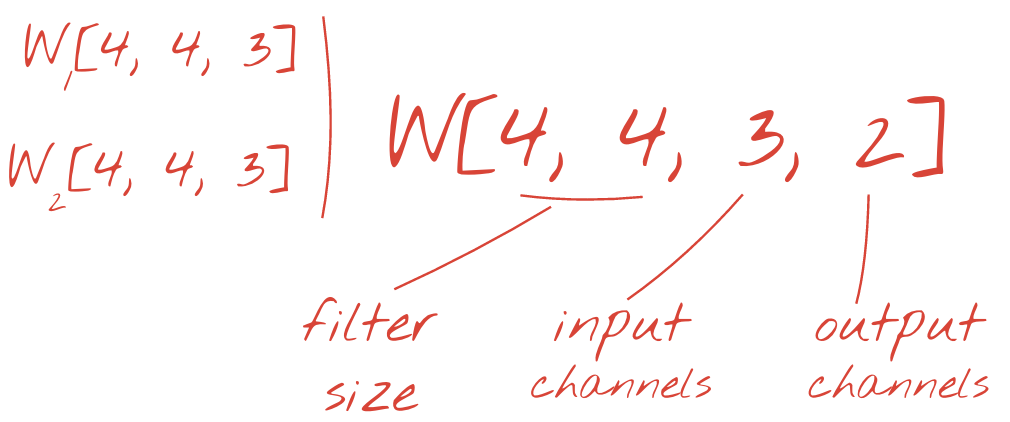
नए डाइमेंशन को जोड़कर, वज़न के दो (या इससे ज़्यादा) सेट को एक टेंसर के तौर पर जोड़ा जा सकता है. इससे हमें कनवोल्यूशनल लेयर के लिए, वेट के टेंसर का सामान्य आकार मिलता है. इनपुट और आउटपुट चैनलों की संख्या पैरामीटर होती है. इसलिए, हम कनवोल्यूशनल लेयर को स्टैक और चेन करना शुरू कर सकते हैं.
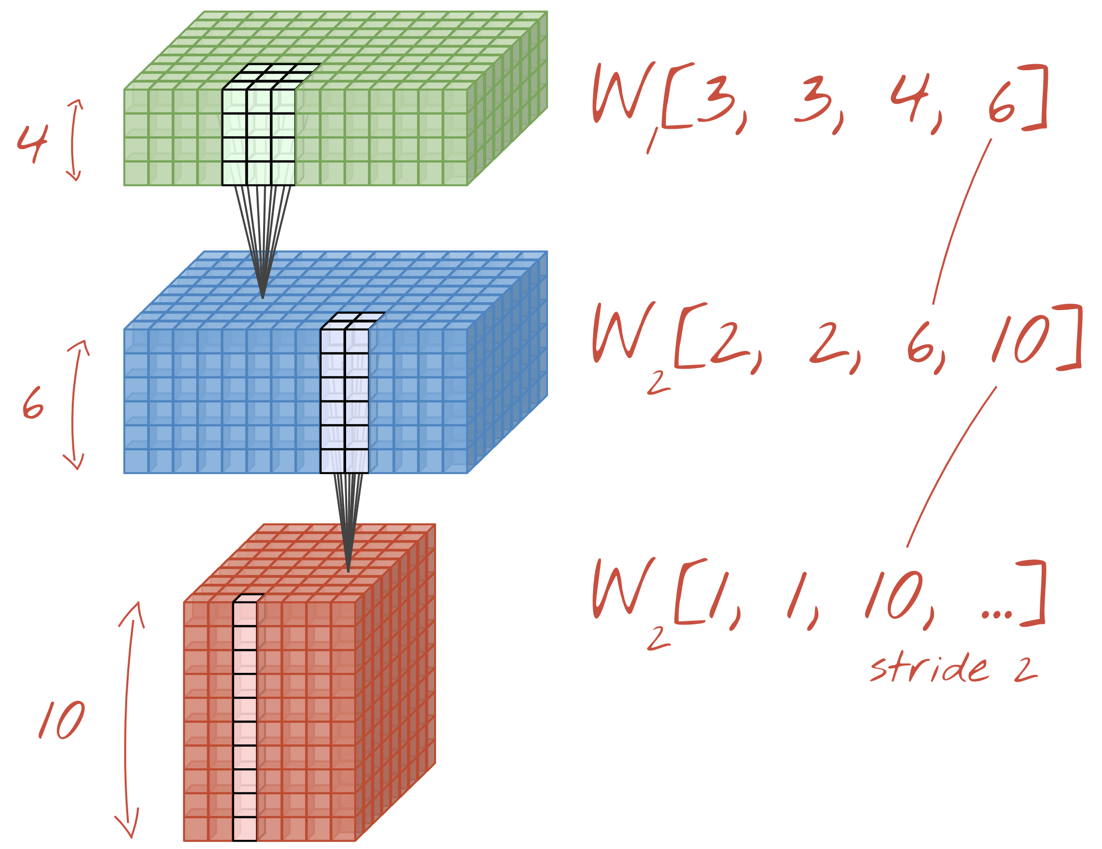
उदाहरण: कनवोल्यूशनल न्यूरल नेटवर्क, डेटा के "क्यूब" को डेटा के अन्य "क्यूब" में बदलता है.
स्ट्राइड कनवोल्यूशन, मैक्स पूलिंग
स्ट्राइड 2 या 3 के साथ कनवोल्यूशन करने पर, हम नतीजे के तौर पर मिले डेटा क्यूब को उसके हॉरिज़ॉन्टल डाइमेंशन में छोटा भी कर सकते हैं. ऐसा करने के दो सामान्य तरीके हैं:
- स्ट्राइड कनवोल्यूशन: ऊपर की तरह स्लाइडिंग फ़िल्टर, लेकिन स्ट्राइड >1 के साथ
- मैक्स पूलिंग: यह एक स्लाइडिंग विंडो होती है, जो MAX ऑपरेशन लागू करती है. आम तौर पर, यह 2x2 पैच पर लागू होती है और हर 2 पिक्सल पर दोहराई जाती है

उदाहरण: कंप्यूटिंग विंडो को 3 पिक्सल तक स्लाइड करने पर, आउटपुट वैल्यू कम हो जाती हैं. स्ट्राइड कनवोल्यूशन या मैक्स पूलिंग (2x2 विंडो पर ज़्यादा से ज़्यादा, जो 2 के स्ट्राइड से स्लाइड होती है) की मदद से, हॉरिज़ॉन्टल डाइमेंशन में डेटा क्यूब को छोटा किया जा सकता है.
फ़ाइनल लेयर
आखिरी कनवोल्यूशनल लेयर के बाद, डेटा "क्यूब" के फ़ॉर्म में होता है. इसे फ़ाइनल डेंस लेयर के ज़रिए दो तरीकों से फ़ीड किया जा सकता है.
पहला तरीका यह है कि डेटा के क्यूब को वेक्टर में बदला जाए. इसके बाद, इसे सॉफ़्टमैक्स लेयर में फ़ीड किया जाए. कभी-कभी, सॉफ़्टमैक्स लेयर से पहले एक डेंस लेयर भी जोड़ी जा सकती है. वज़न की संख्या के हिसाब से, यह महंगा होता है. कन्वलूशनल नेटवर्क के आखिर में मौजूद डेंस लेयर में, पूरे न्यूरल नेटवर्क के आधे से ज़्यादा वेट हो सकते हैं.
ज़्यादा लेयर वाली डेंस लेयर का इस्तेमाल करने के बजाय, हम आने वाले डेटा "क्यूब" को उतनी ही संख्या में बांट सकते हैं जितनी हमारे पास क्लास हैं. इसके बाद, उनकी वैल्यू का औसत निकाल सकते हैं और उन्हें सॉफ़्टमैक्स ऐक्टिवेशन फ़ंक्शन के ज़रिए फ़ीड कर सकते हैं. क्लासिफ़िकेशन हेड बनाने के इस तरीके में, वज़न का इस्तेमाल नहीं किया जाता. Keras में, इसके लिए एक लेयर होती है: tf.keras.layers.GlobalAveragePooling2D().
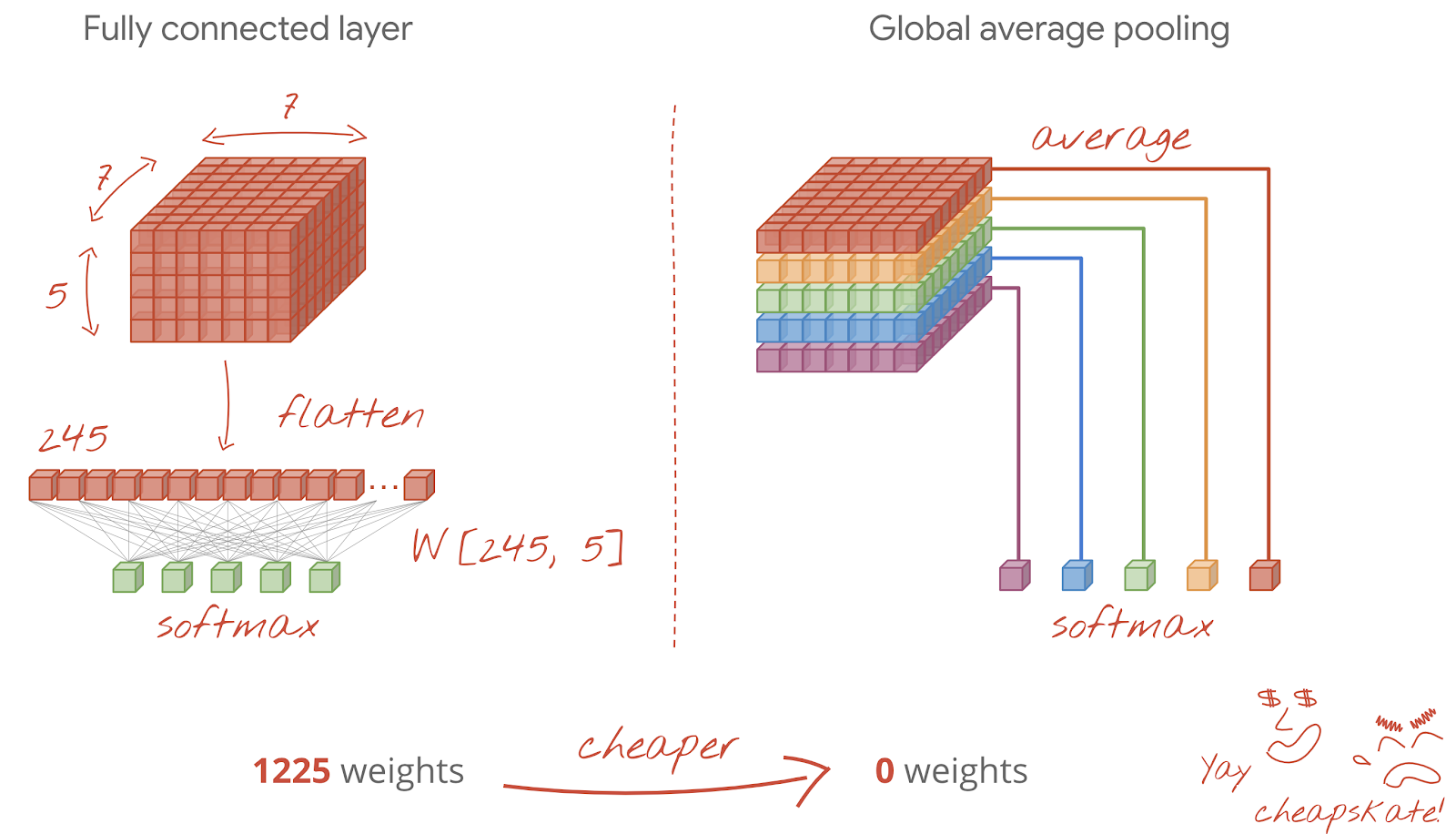
इस समस्या के लिए कनवोल्यूशनल नेटवर्क बनाने के लिए, अगले सेक्शन पर जाएं.
आइए, हाथ से लिखे गए अंकों को पहचानने के लिए एक कनवोल्यूशनल नेटवर्क बनाते हैं. हम सबसे ऊपर तीन कनवोल्यूशनल लेयर का इस्तेमाल करेंगे. साथ ही, सबसे नीचे अपनी पारंपरिक सॉफ़्टमैक्स रीडआउट लेयर का इस्तेमाल करेंगे. इसके बाद, हम इन दोनों को पूरी तरह से कनेक्ट की गई एक लेयर से कनेक्ट करेंगे:
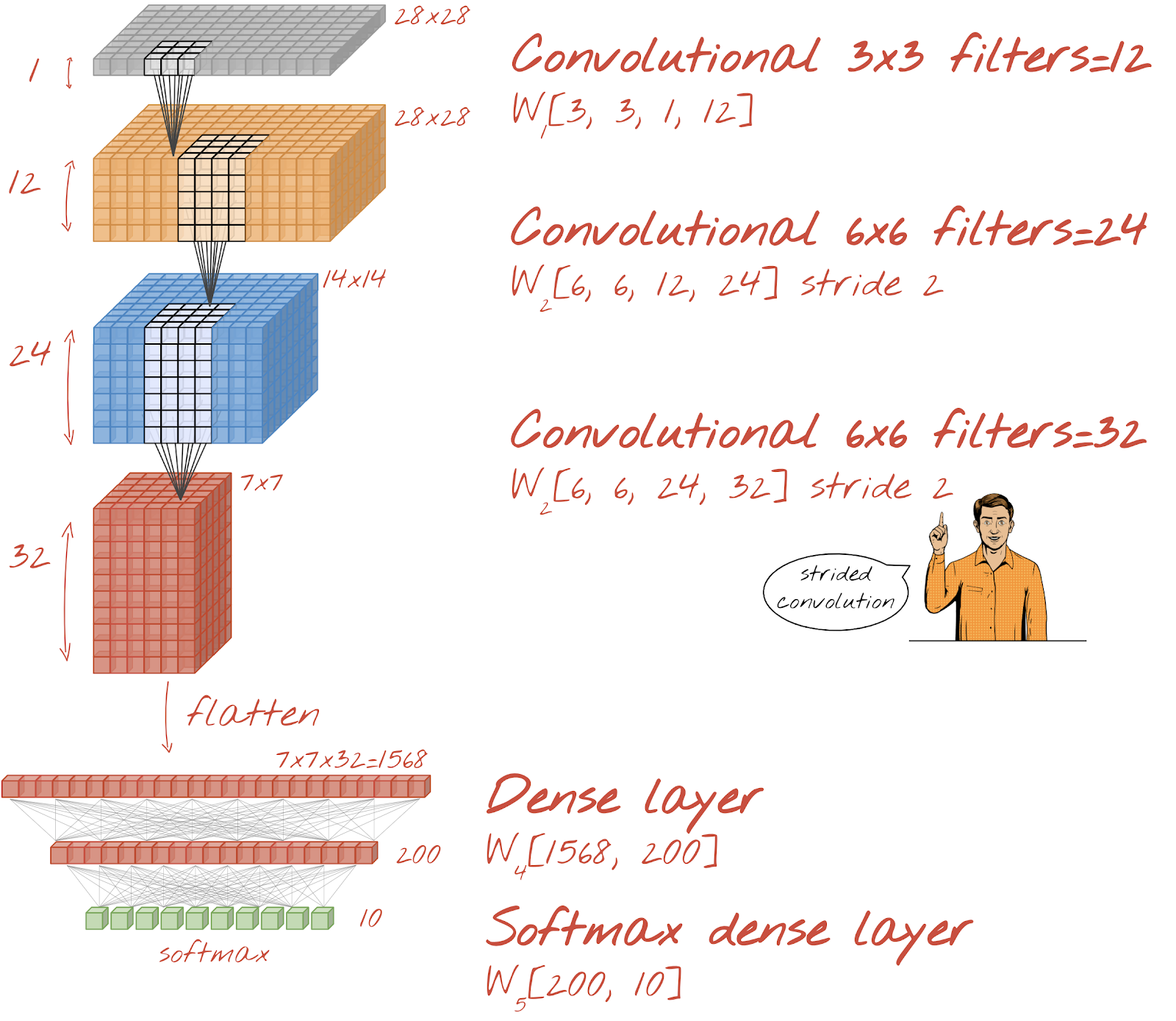
ध्यान दें कि दूसरी और तीसरी कनवोल्यूशनल लेयर में स्ट्राइड की वैल्यू दो है. इससे पता चलता है कि आउटपुट वैल्यू की संख्या 28x28 से घटकर 14x14 और फिर 7x7 क्यों हो जाती है.
आइए, Keras कोड लिखते हैं.
पहली कनवोल्यूशनल लेयर से पहले, खास ध्यान देने की ज़रूरत होती है. दरअसल, इसे डेटा के 3D ‘क्यूब' की ज़रूरत होती है. हालांकि, हमारा डेटासेट अब तक डेंस लेयर के लिए सेट अप किया गया है. साथ ही, इमेज के सभी पिक्सल को वेक्टर में बदल दिया गया है. हमें उन्हें वापस 28x28x1 इमेज (ग्रेस्केल इमेज के लिए 1 चैनल) में बदलना होगा:
tf.keras.layers.Reshape(input_shape=(28*28,), target_shape=(28, 28, 1))अब तक इस्तेमाल की गई tf.keras.layers.Input लेयर के बजाय, इस लाइन का इस्तेमाल किया जा सकता है.
Keras में, ‘relu'-ऐक्टिवेटेड कनवोल्यूशनल लेयर के लिए सिंटैक्स यह है:
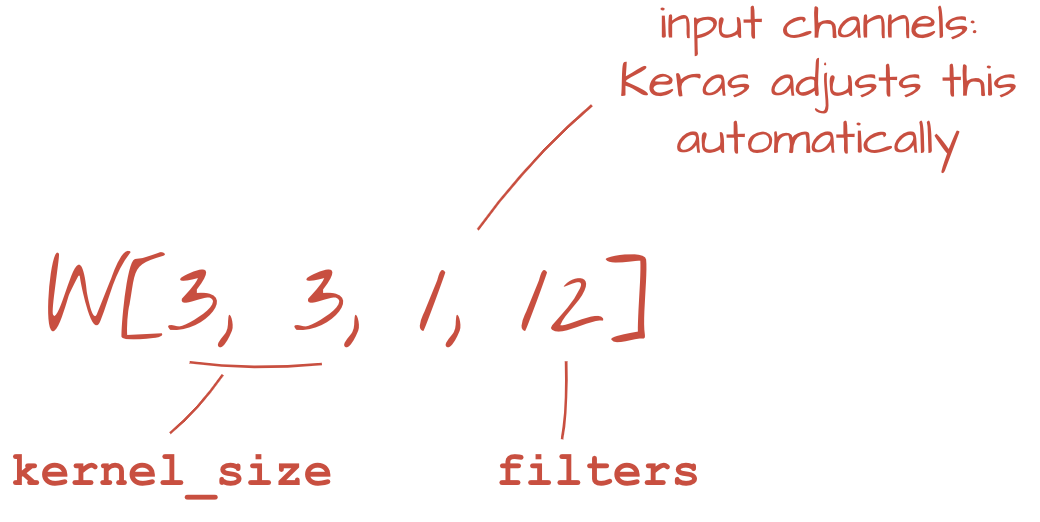
tf.keras.layers.Conv2D(kernel_size=3, filters=12, padding='same', activation='relu')स्ट्राइड वाले कनवोल्यूशन के लिए, यह लिखा जाएगा:
tf.keras.layers.Conv2D(kernel_size=6, filters=24, padding='same', activation='relu', strides=2)डेटा के क्यूब को वेक्टर में बदलने के लिए, ताकि इसका इस्तेमाल डेंस लेयर में किया जा सके:
tf.keras.layers.Flatten()डेंस लेयर के लिए, सिंटैक्स में कोई बदलाव नहीं किया गया है:
tf.keras.layers.Dense(200, activation='relu')क्या आपके मॉडल ने 99% सटीकता के बैरियर को तोड़ दिया है? काफ़ी हद तक सही जवाब... लेकिन, पुष्टि करने के दौरान होने वाले नुकसान के कर्व को देखें. क्या आपको कुछ याद आया?
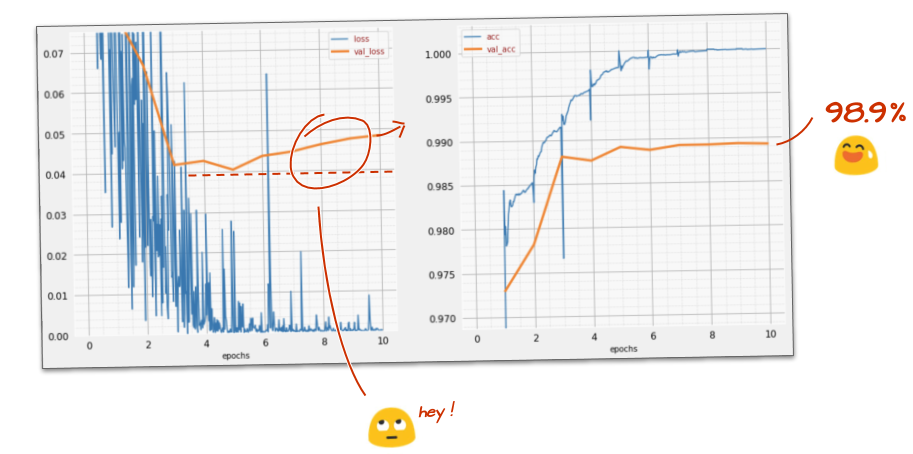
पूर्वानुमानों पर भी नज़र डालें. पहली बार, आपको दिखेगा कि 10,000 टेस्ट डिजिट में से ज़्यादातर अब सही तरीके से पहचाने जा रहे हैं. सिर्फ़ करीब 4½ लाइनों में गलत तरीके से पहचाने गए अंक बचे हैं (10,000 में से करीब 110 अंक)

अगर आपको कोई समस्या आ रही है, तो यहां दिए गए तरीके से इसे हल करें:
पिछली ट्रेनिंग में, ओवरफ़िटिंग के साफ़ तौर पर संकेत मिलते हैं. साथ ही, यह अब भी 99% सटीकता से कम है. क्या हमें फिर से ड्रॉपआउट की कोशिश करनी चाहिए?
इस बार आपको कैसा लगा?
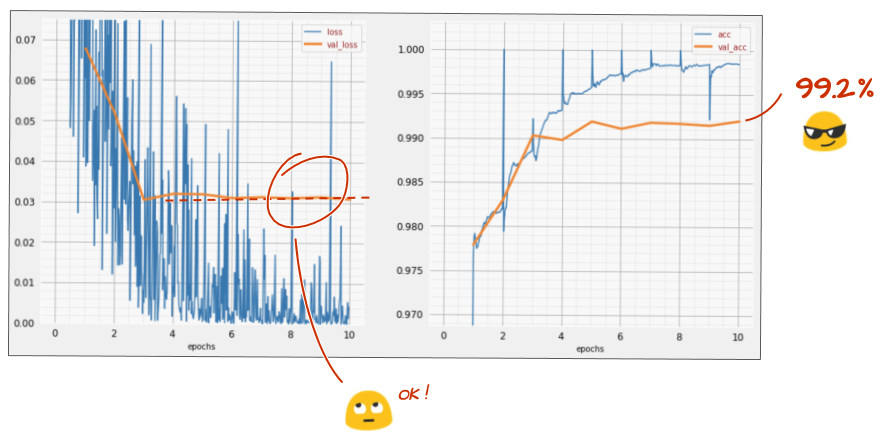
ऐसा लगता है कि इस बार ड्रॉपआउट की सुविधा काम कर रही है. अब पुष्टि करने के दौरान होने वाला नुकसान नहीं बढ़ रहा है. साथ ही, फ़ाइनल सटीकता 99% से ज़्यादा होनी चाहिए. बधाई हो!
जब हमने पहली बार ड्रॉपआउट लागू करने की कोशिश की, तो हमें लगा कि हमें ओवरफ़िटिंग की समस्या है. हालांकि, समस्या न्यूरल नेटवर्क के आर्किटेक्चर में थी. कनवोल्यूशनल लेयर के बिना, हम आगे नहीं बढ़ सकते थे. ड्रॉपआउट इस समस्या को ठीक नहीं कर सकता.
इस बार, ऐसा लगता है कि ओवरफ़िटिंग की वजह से समस्या हुई है और ड्रॉपआउट से वाकई मदद मिली है. याद रखें, ऐसी कई वजहें हो सकती हैं जिनकी वजह से ट्रेनिंग और पुष्टि करने के दौरान होने वाले नुकसान के कर्व अलग-अलग हो सकते हैं. साथ ही, पुष्टि करने के दौरान होने वाले नुकसान में बढ़ोतरी हो सकती है. ओवरफ़िटिंग (बहुत ज़्यादा डिग्री ऑफ़ फ़्रीडम, जिसका इस्तेमाल नेटवर्क ने सही तरीके से नहीं किया) इनमें से सिर्फ़ एक है. अगर आपका डेटासेट बहुत छोटा है या आपके न्यूरल नेटवर्क का आर्किटेक्चर सही नहीं है, तो आपको लॉस कर्व में एक जैसा पैटर्न दिख सकता है. हालांकि, ऐसे में ड्रॉपआउट से कोई फ़ायदा नहीं होगा.

आखिर में, बैच नॉर्मलाइज़ेशन जोड़ने की कोशिश करते हैं.
यह सिद्धांत है. हालांकि, व्यवहार में सिर्फ़ इन दो नियमों का ध्यान रखें:
फ़िलहाल, हम नियमों के हिसाब से काम करते हैं और हर न्यूरल नेटवर्क लेयर पर बैच नॉर्म लेयर जोड़ते हैं. हालांकि, आखिरी लेयर पर इसे नहीं जोड़ा जाता. इसे आखिरी "softmax" लेयर में न जोड़ें. यह वहाँ काम का नहीं होगा.
# Modify each layer: remove the activation from the layer itself.
# Set use_bias=False since batch norm will play the role of biases.
tf.keras.layers.Conv2D(..., use_bias=False),
# Batch norm goes between the layer and its activation.
# The scale factor can be turned off for Relu activation.
tf.keras.layers.BatchNormalization(scale=False, center=True),
# Finish with the activation.
tf.keras.layers.Activation('relu'),अब यह कितना सटीक है?
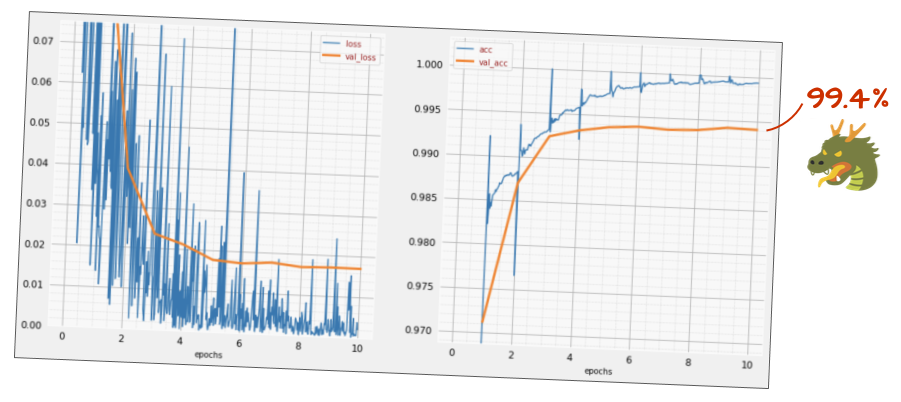
थोड़ा बदलाव करके (BATCH_SIZE=64, लर्निंग रेट डेके पैरामीटर 0.666, डेंस लेयर पर ड्रॉपआउट रेट 0.3) और थोड़ी किस्मत से, आपको 99.5% तक का स्कोर मिल सकता है. बैच नॉर्म का इस्तेमाल करने के "सबसे सही तरीकों" के मुताबिक, लर्निंग रेट और ड्रॉपआउट में बदलाव किए गए थे:
- बैच नॉर्मलाइज़ेशन से न्यूरल नेटवर्क को कन्वर्ज करने में मदद मिलती है. साथ ही, इससे ट्रेनिंग को ज़्यादा तेज़ी से पूरा किया जा सकता है.
- बैच नॉर्मलाइज़ेशन एक रेगुलराइज़र है. आम तौर पर, ड्रॉपआउट की मात्रा को कम किया जा सकता है या इसका इस्तेमाल पूरी तरह से बंद किया जा सकता है.
इस सलूशन नोटबुक में 99.5% ट्रेनिंग रन है:

आपको GitHub पर mlengine फ़ोल्डर में, कोड का क्लाउड-रेडी वर्शन मिलेगा. साथ ही, इसे Google Cloud AI Platform पर चलाने के निर्देश भी मिलेंगे. इस हिस्से को चलाने से पहले, आपको Google Cloud खाता बनाना होगा और बिलिंग की सुविधा चालू करनी होगी. लैब को पूरा करने के लिए ज़रूरी संसाधनों की कीमत, कुछ डॉलर से कम होनी चाहिए. इसमें यह माना गया है कि एक जीपीयू पर ट्रेनिंग में एक घंटा लगता है. अपना खाता तैयार करने के लिए:
- Google Cloud Platform प्रोजेक्ट बनाएं (http://cloud.google.com/console).
- बिलिंग चालू करें.
- GCP कमांड लाइन टूल इंस्टॉल करें (यहां GCP SDK).
- Google Cloud Storage बकेट बनाएं (इसे
us-central1क्षेत्र में रखें). इसका इस्तेमाल ट्रेनिंग कोड को स्टेज करने और ट्रेन किए गए मॉडल को सेव करने के लिए किया जाएगा. - ज़रूरी एपीआई चालू करें और ज़रूरी कोटा का अनुरोध करें. ट्रेनिंग कमांड को एक बार चलाएं. इससे आपको गड़बड़ी के मैसेज मिलेंगे. इन मैसेज से आपको पता चलेगा कि कौनसे एपीआई चालू करने हैं.
आपने अपना पहला न्यूरल नेटवर्क बना लिया है और उसे 99% सटीकता तक ट्रेन कर लिया है. इस प्रोसेस में सीखी गई तकनीकें, MNIST डेटासेट के लिए खास नहीं हैं. दरअसल, न्यूरल नेटवर्क के साथ काम करते समय इनका बड़े पैमाने पर इस्तेमाल किया जाता है. यह लैब का "क्लिफ़ नोट्स" कार्ड है. इसे कार्टून वर्शन में बनाया गया है. इसका इस्तेमाल, सीखी गई बातों को याद रखने के लिए किया जा सकता है:

अगले चरण
- पूरी तरह से कनेक्ट किए गए और कनवोल्यूशनल नेटवर्क के बाद, आपको रीकरंट न्यूरल नेटवर्क पर एक नज़र डालनी चाहिए.
- Google Cloud, डिस्ट्रिब्यूटेड इन्फ़्रास्ट्रक्चर पर क्लाउड में ट्रेनिंग या अनुमान लगाने की सुविधा देता है. इसके लिए, AI Platform का इस्तेमाल किया जाता है.
- आखिर में, हमें आपके सुझाव/राय/शिकायत का इंतज़ार रहेगा. अगर आपको इस लैब में कोई गड़बड़ी दिखती है या आपको लगता है कि इसमें सुधार किया जाना चाहिए, तो कृपया हमें बताएं. हम GitHub की समस्याओं [सुझाव/राय देने या शिकायत करने का लिंक] के ज़रिए सुझाव/राय देते हैं या शिकायत करते हैं.

लेखक: मार्टिन गर्नर Twitter: @martin_gorner |
|


इस लैब में मौजूद सभी कार्टून इमेज का कॉपीराइट: alexpokusay / 123RF stock photos के पास है