
この Codelab では、Cloud Talent Solution API(CTS)を使用して、組織の求人検索と人材獲得を強化する方法を学びます。CTS を使用することで、求人検索エクスペリエンスに機械学習の機能を追加できます。
ラボの内容
- Google Cloud プロジェクトで CTS を有効にする
- Job Search API を使用した募集中の求人のクエリ
必要なもの
- お支払い情報が設定されている Google Cloud プロジェクトを設定します(まだ作成していない場合)。作成してください。
- 1 時間程度
このチュートリアルの利用方法をお選びください。
Google Cloud Platform の使用経験についてお答えください。
このチュートリアルは Google Cloud Platform 上で完全に動作するように設計されています。ワークステーションへのダウンロードは必要ありません。
- Google アカウントをまだお持ちでない場合は、アカウントを作成してログインしてください
- 新しい GCP プロジェクトを作成し、課金を有効にします。
Cloud Talent Solutions API を有効にします。
Cloud Console でアプリケーションを開き、左上にあるハンバーガー メニューをクリックします。メニューで [Talent Solution -> Overview] に移動します。
これは新しいプロジェクトであるため、新しい画面にリダイレクトされ、API を有効にするよう求められます。[有効にする] をクリックし、このプロジェクトで API が有効になるまで数分待ちます。
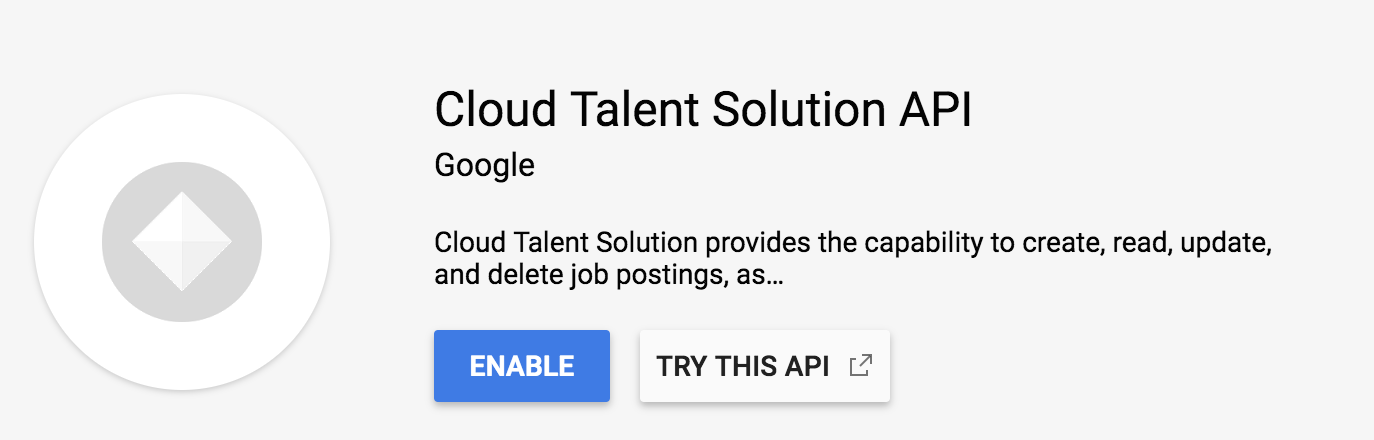
データロギングを有効にする
前の概要ページに戻ります。新しいダイアログが表示され、データロギングを有効にするよう求められます。これは、Job Search API がデータを必要とする機械学習モデルを利用することの確認にすぎません。統合の一環として、これらのモデルをさらにトレーニングしようとしているユーザーのイベントを送信できます。コードを使用して実装する場合、送信する情報を指定できます。
これらのイベントの概要と送信方法については後ほど詳しく説明しますが、事前トレーニング済みのモデルも使用できます。データロギングを有効にしてから、このダイアログの左側のナビゲーションにある [サービス アカウント接続] をクリックしてください。

サービス アカウントを設定する
API リクエストは、実際の認証済みアカウントに代わって行う必要があります。Google Cloud Platform では、この目的でサービス アカウントを作成することをおすすめしています。サービス アカウントは、権限が制限された認証済みユーザーを簡単に設定する方法と考えてください。これによって、独立した安全なシステムを構築できます。
たとえば、Job Search API を使用するにはサービス アカウントが必要です。作成してみましょう。[サービス アカウント接続] をクリックし、ページ上部にある [サービス アカウントの管理] をクリックして、[サービス アカウントを作成] をクリックします。左側のメニューの [Cloud Talent Solution] で [Job Editor] を使用して、読み取り/書き込み権限を付与します。「ジョブ閲覧者」だけを使用してサービス アカウントを設定することもできます。この場合、読み取り専用アクセス権になります。
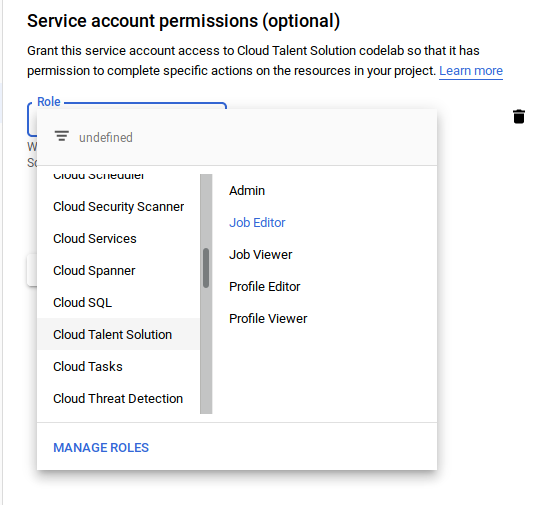
次の手順で、このサービス アカウントへのアクセス権をユーザーに付与するかどうかを尋ねます。この手順は省略できますが、下部にある [&+ キーを作成] をクリックしてください。新しい JSON 認証情報ファイルが自動的にダウンロードされます。このファイルをサーバーに保存します。認証には、この後のセクションで作成するコードが使用します。
環境変数を設定する
便宜上、Google Cloud Shell を使用します。この処理を独自の開発環境から行う場合、選択した言語で Google Cloud SDK とクライアント ライブラリをインストールします(この Codelab では Python を使用します)。Cloud Shell には Cloud クライアント ライブラリがすでにインストールされています。便利ですね。
ライブラリを使用してコードを実行するには、2 つの環境変数が設定されている必要があります。1 つはプロジェクト ID を指定し、もう 1 つはサービス アカウント キーを指定するためのものです。これを設定しましょう。
プロジェクトで、ウェブ コンソールの右上にある >_&tt; アイコンをクリックして Cloud Shell を開きます。次の環境変数を追加して、プロジェクト ID を指定し、json キーファイルへのパスを設定します。
export GOOGLE_CLOUD_PROJECT="your-project-id" export GOOGLE_APPLICATION_CREDENTIALS=/path/to/key.json"
システム内で求人情報を検索する前に、実際に求人情報が存在しているか確認する必要があります。
この API を使用して会社と求人を追加する方法を知りたい場合は、それでは、そのテーマについて Codelab を実施しましょう。それ以外の場合は、このセクションで説明します。
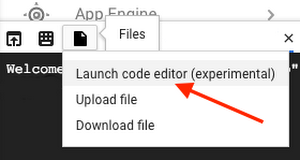
Cloud Shell でコードエディタを開く
Google Cloud Console で、右上の Cloud Shell アイコンから Cloud Shell を開きます。
Cloud Shell の右上に、一連のアイコンが表示されます。次に示すように、[File] -> [Launch Code Editor] をクリックします。
会社と求人をいくつか作成します。
[File] -> New File を使用して新しいソースファイルを作成し、以下の内容を入力します。create_some_jobs.py という名前を付けます。
会社と求人の作成に API を使用することは、この Codelab の対象外です。前の Codelab の「Job Search API」では、この方法を示しています。以下のコードでは、Search API のさまざまな機能を試して結果を確認できるように、システムにいくつかのジョブを作成しています。
create_some_jobs.py
import os
from googleapiclient.discovery import build
from googleapiclient.errors import Error
# Build the service object, passing in the api name and api version
client_service = build('jobs', 'v3')
project_id = 'projects/' + os.environ['GOOGLE_CLOUD_PROJECT']
def create_company(request):
# This is the API call that actually creates the new company.
result = client_service.projects().companies().create(
parent=project_id, body=request).execute()
return result
def create_job(request):
# The actual API call happens here.
result = client_service.projects().jobs().create(
parent=project_id, body=request).execute()
print('Job created: %s' % result)
return result
def create_foo():
foocorp_company_request = {
"company": {
'display_name': "FooCorp",
'external_id': "foo2_llc"
}
}
result_company = create_company(foocorp_company_request)
company_name = result_company.get('name')
job = {
'company_name': company_name,
'title': 'Senior Software Engineer',
'addresses': ["Mountain View, CA"],
'description':
"""Experienced software engineer required for full-time position.
Leadership ability and ability to thrive in highly competitive environment a must.
<p />Ignore postings from that "Bar" company, their microkitchen is terrible. Join Team Foo!""",
'requisition_id': 'foo_swe',
'application_info': {
'uris': ['http://www.example.com/foo/software-engineer-application'],
'emails': ['apply@example.com']
}
}
request = {'job': job}
result_job = create_job(request)
def create_horsehub():
horsehub_company_request = {
"company": {
'display_name': "Horse Hub",
'external_id': "horsies_llc"
}
}
result_company = create_company(horsehub_company_request)
company_name = result_company.get('name')
job = {
'company_name': company_name,
'title': 'Junior Software Engineer',
'description':
"""Hiring entry level software engineer required for full-time position.
Must be passionate about industry intersection of horses and technology.
Ability to intelligently discuss the equine singularity a major bonus.
<p />C'mon bub! Join Horse Hub!""",
'requisition_id': 'hh_swe',
'application_info': {
'uris': ['http://www.example.com/foo/software-engineer-horsehub'],
'emails': ['apply-horsehub@example.com']
}
}
request = {'job': job}
result_job = create_job(request)
def create_tandem():
tandem_company_request = {
"company": {
'display_name': "Tandem",
'external_id': "tandem"
}
}
result_company = create_company(tandem_company_request)
company_name = result_company.get('name')
job = {
'company_name': company_name,
'title': 'Test Engineer',
'description':
"""Hiring Test Engineer for full-time position with Tandem. Must be detail oriented
and (obviously) comfortable with pair programming. Will be working with team of Software Engineers.
<p />Join Tandem today!""",
'requisition_id': 'tandem_te',
'application_info': {
'uris': ['http://www.example.com/tandem/test-engineer'],
'emails': ['apply-tandem-test@example.com']
},
'promotionValue': 1
}
request = {'job': job}
result_job = create_job(request)
job['requisition_id'] = 'a_tandem_te'
result_job = create_job(request)
try:
create_foo()
create_horsehub()
create_tandem()
except Error as e:
print('Got exception while creating company')
raise eコンソールから上記のコードを実行します。
$ python create_some_jobs.py Job created: (Lots of output here)
検索ごとに、Request と RequestMetadata の 2 つのオブジェクトを指定する必要があります。
まず、RequestMetadata に焦点を当てましょう。
RequestMetadata オブジェクトは、検索リクエストを行うユーザーに関する情報を提供します。これらの詳細情報を提供してユーザー エクスペリエンスの一貫性を確保するとともに、機械学習モデルのトレーニング精度を向上させることが重要です。
次の 4 つのプロパティがリクエスト オブジェクトです。
- domain(必須): 検索がホストされているドメイン(foo.com など)。
- sessionId(必須): セッションの一意の ID 文字列。セッションは、エンドユーザーがサービスを一定期間にわたって操作した時間として定義されます。
- userId(必須): ユーザーを表す一意の ID 文字列。
- deviceInfo(省略可): オプションの ID とデバイスタイプ。したがって、ウェブ検索とアプリ検索などを区別できます。
フィールドの全リストと種類、説明については、RequestMetadata に関するドキュメントをご覧ください。
検索の最小手順は次のとおりです。
- RequestMetadata オブジェクトを定義する
- その RequestMetadata を取得して「request」オブジェクトに配置する
- クエリの定義としてそのリクエストを使用して Jobs API を検索する
- 結果を確認します。
どのように表示されるかを確認してみましょう。新しいファイル search_jobs.py を開き、次のコードを貼り付けます。
search_jobs.py
import os
from googleapiclient.discovery import build
from googleapiclient.errors import Error
client_service = build('jobs', 'v3')
project_id = 'projects/' + os.environ['GOOGLE_CLOUD_PROJECT']
# 1) Define RequestMetadata object
request_metadata = {
'domain': 'example.com',
'session_id': 'a5ed434a3f5089b489576cceab824f25',
'user_id': '426e428fb99b609d203c0cdb6af3ba36',
}
try:
# 2) Throw RequestMetadata object in a request
request = {
'request_metadata': request_metadata,
}
# 3) Make the API call
response = client_service.projects().jobs().search(
parent=project_id, body=request).execute()
# 4) Inspect the results
if response.get('matchingJobs') is not None:
print('Search Results:')
for job in response.get('matchingJobs'):
print('%s: %s' % (job.get('job').get('title'),
job.get('searchTextSnippet')))
else:
print('No Job Results')
except Error as e:
# Alternate 3) or 4) Surface error if things don't work.
print('Got exception while searching')
raise e
この「検索」を実行してみてください。
$ python search_jobs.py Search Results: Junior Software Engineer: None Senior Software Engineer: None Test Engineer: None Test Engineer: None
システム内のすべてのジョブを返しました。
理由:
実際には検索パラメータを指定していないためです。では、どうすればよいでしょうか。次のセクションで、有用でなく、データベースの検索に必要なものをすべて取り上げたのであれば、その他
検索パラメータを含む JobQuery オブジェクトを追加する
技術的には RequestMetadata は唯一の必須フィールドですが、ほとんどの場合は実際に検索したいので、JobQuery も含めます。JobQuery は非常にシンプルなオブジェクトで、実際の検索キーワードに対するクエリ文字列と、返されるジョブを絞り込むのに役立つさまざまなフィルタを使用できます。たとえば、特定の会社の求人のみを表示したり、雇用タイプでフィルタしたりできます。ここではクエリ文字列にのみ基づいて説明しますが、フィルタの詳細については、JobQuery のドキュメントをご覧ください。
先ほどのコードを変更して JobQuery を組み込み、既存のリクエストに追加します。
search_jobs.py
...
# Create a job query object, which is just a key/value pair keyed on "query"
job_query = {'query': 'horses'}
...
# Update the request to include the job_query field.
request = {
'request_metadata': request_metadata,
'job_query': job_query
}
...
その後、もう一度検索します。
$ python search_jobs.py Search Results: Junior Software Engineer: Hiring entry level software engineer required for full-time position. Must be passionate about industry intersection of <b>horses</b> and technology. Ability to intelligently discuss the equine singularity a major ...
いいですね!いくつかの点で、実際には良い面です。何が起きたのか詳しく見てみましょう。
- Search API がクエリ パラメータを取得し、一致する結果のみを返しました
- 返される検索結果には、一致する検索キーワードが太字になっている HTML 形式のスニペットが含まれ、検索結果のリストで簡単に表示されます。
- 検索クエリの追加は、わずか 2 行のコードでした。
この時点で、基本的な求人情報の検索は実行されています。ジョブ データベースに対してクエリを実行して結果を取得できます。とはいえ、素晴らしい機能がたくさんあります。
jobView を使用して返されるデータの量を制限する
jobView プロパティを指定することもできます。これは、検索リクエストで取得する情報量を宣言する ENUM です。JOB_VIEW_FULL を使用すると、各ジョブ結果に関するすべての情報が返されます。ただし、バイト数を節約し、フィールドの少ない別のオプションを選択することをおすすめします。使用しているプラットフォームに最も適したオプションを選択してください。有効な値は次のとおりです(JobView ドキュメントから取得)。
- JOB_VIEW_UNSPECIFIED - デフォルト。
- JOB_VIEW_ID_ONLY - ジョブ名、求人 ID、言語コードのみが含まれます。
- JOB_VIEW_MINIMAL - ID_ONLY ビューのすべて、タイトル、会社名、場所。
- JOB_VIEW_SMALL - MINIMAL ビューのすべて、可視性とジョブの説明。
- JOB_VIEW_FULL - 使用可能なすべての属性。
使用できるフィールドの詳細については、Job のドキュメントをご確認ください。このオブジェクトは、検索クエリで返されるオブジェクトです。以下に、リクエスト オブジェクトで JobView を指定する例を示します。
# What your request object looks like with a jobView field
request = {
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL'
}この Codelab では、クエリの対象となるジョブの数(および同時ユーザー数)が非常に少なく、使用可能なさまざまなフィールドを簡単に確認できるため、JOB_VIEW_FULL に設定します。本番環境では、検索結果のインデックスを作成する際に、より軽量なペイロードで JobView を使用できます。そうすれば、不要な帯域幅を削減できます。
ページ分け
多数の結果を取得する可能性があるため、API ではページ分けがなされるため、ページ分けされたインターフェースを操作できます。待ち時間の問題を回避し、すべての結果で読み込むのではなく、常に API でページ分けを行うため、ページサイズを 20 以下にすることをおすすめします。さらに多くのジョブがある場合、レスポンスで nextPageToken を取得するため、次の検索クエリの pageToken に渡すことができます。
ここでも、検索結果に対するこの調整は、リクエストに 1 つのフィールドを追加し、ページごとに必要な検索結果の数を指定することにより行われます。
request = {
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL',
'pageSize': 1
}
リクエストで pageSize を 1 として指定して、search_jobs スクリプトを実行してみてください。このように設定しても、得られる検索結果は 1 つだけです。しかし、データベースには複数の求人情報があります。残りの成果はどのように得られますか?
現在のレスポンスに含まれる結果よりも多くの結果がある場合、レスポンスに nextPageToken フィールドが含まれます。その値を取得し、pageToken という名前の既存のリクエストに再び入力し、もう一度検索します。以下は、その方法の例です。
if "nextPageToken" in response:
request["pageToken"] = response.get('nextPageToken')
response = client_service.projects().jobs().search(
parent=project_id, body=request).execute()
for job in response.get('matchingJobs'):
print('%s: %s' % (job.get('job').get('title'),
job.get('searchTextSnippet')))クエリの自動スペルチェック
スペルチェックは API に組み込まれているため、求職者が「 マネージャー」という単語を検索すると、「マネージャー」という単語を含む検索結果が返されます。
この機能はデフォルトで有効になっています。無効にするには、JobQuery に disableSpellCheck フィールドを追加し、true に設定します。
search_jobs.py
job_query = {
'query': "Enginer",
'disableSpellCheck': "true"
}これを実行してみてください。このフラグがない場合、「Engineer」は文字列に「Engineer」が含まれる結果を返します。スペルチェックを無効にすると、同じクエリでも 0 件の結果が返されます。
次に、検索結果の関連性を調整する方法をいくつか説明します。
Google Cloud Talent Solution Job Search API は、機械学習(ML)を使用して、ユーザーが求人情報を検索したときに求人情報の関連性を判断します。
求人と会社には、検索結果の関連性を判断するために機械学習モデルが参照する複数のプロパティがあります。より詳しい情報を表示したり、注目の求人などを利用したりすると、そのような関連性に大きな影響を与えられます。もちろん、検索結果の関連性は測定が難しい場合があります。特に、ユーザーによって関係する内容が異なるためです。Job Search API は、求人データからの複数のシグナルに基づくアルゴリズムを使用します。これらのシグナルの一部が検索結果にどのように影響するかを見てみましょう。
注目の求人
注目の求人情報により、純粋な関連性ではなくプロモーションの価値に応じて求人情報をランク付けすることで、検索結果に影響を与えることができます。注目の求人を検索すると、プロモーション値が割り当てられている関連求人だけが返されます。
注目の求人は、インデックス内の個々の求人のスポンサーになりたい場合に便利です。たとえば、ビジネス クリティカルな仕事を宣伝するキャリアサイトでは、「注目の求人」の検索を使用して、スポンサーになっている仕事のみを求職者に返すことができます。
ジョブを「注目の機能」として定義するために、ジョブの作成時または更新時に promotionValue フィールドがジョブ定義で使用されます。この Codelab で前に使用した create_some_jobs.py スクリプトでは、ジョブの 1 つがプロモーション値を使用して作成されました。関連する行をコメントで囲んで、もう一度スニペットを表示します。
create_some_jobs.py
job = {
'company_name': company_name,
'title': 'Test Engineer',
'description':
"""Hiring Test engineer for full-time position with Tandem. Must be detail oriented
and (obviously) comfortable with pair programming..
<p />Join Tandem today!""",
'requisition_id': 'tandem_te',
'application_info': {
'uris': ['http://www.example.com/tandem/test-engineer'],
'emails': ['apply-tandem-test@example.com']
},
# Down here vvvvv
'promotionValue': 1
# Up there ^^^^^
}プロモーション値には 1 ~ 10 の任意の整数を指定できます。検索モードを FEATURED_JOB_SEARCH に変更すると(次の検索結果を参照)、検索結果は次の 2 つの影響を受けます。
- promotionalValue > 0 のジョブのみが表示されます
- ジョブは promotionalValue の降順で並べられます。同じ promotionalValue を持つ求人は、(検索アルゴリズムによって決定された)関連性に基づいて並べ替えられます。
search_jobs.py(注目の求人の検索に設定)
request = {
'searchMode': 'FEATURED_JOB_SEARCH',
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL'
}リクエストを更新して、検索モードを FEATURED_JOB_SEARCH に設定します。その後、コードを実行すると、次のような出力が表示されます。
$ $ python search_jobs.py Search Results: Test Engineer: Hiring Test <b>engineer</b> for full-time position with Tandem. Must be detail oriented and (obviously) comfortable with pair programming.. Join Tandem today!
promotionValue が 0 より明示的に設定されているジョブのみが返されます。
地理的位置
最も重要なプロパティの 1 つは地理的位置です。会社と求人の両方に所在地のプロパティが設定されていますが、ユーザーが検索を行うと、その会社が拠点の代わりに会社の場所を使用します。API で位置情報を使用して検索に対して最も関連性の高いジョブが返されるように、求人および会社に固有の住所フィールドを使用する必要があります。「横浜市」を検索したユーザーは、まずサンフランシスコとその周辺で仕事をすることを第一に考えています。
サンプルのジョブでは、FooCorp のシニア ソフトウェア エンジニアの勤務地の所在地が、カリフォルニア州マウンテンビューに設定されています。この処理を行うコード(ページに戻って検索しない場合)は次のようになります。
create_some_jobs.py(ここで、ロケーションは FooCorp に定義されています)
...
job = {
'company_name': company_name,
'title': 'Senior Software Engineer',
'addresses': ["Mountain View, CA"],
...町名は問題ありませんが、最適な結果を得るには完全な住所を使用してください。
場所の追加は技術的には必須ではありませんが、場所を追加すると、求職者にとって多くの便利な機能が提供されます。CTS は、この住所を緯度/経度に変換して、検索シグナルとして使用します。たとえば、ここでは、JobQuery を調整して、Palo Alto エリアの求人を 10 マイル(10 マイル)以内で検索する方法を示します。
search_jobs.py(Palo Alto 圏内の求人情報を検索)
...
location_filter = {
'address': 'Palo Alto',
'distance_in_miles': 10,
}
job_query = {
'location_filters': [location_filter],
'query': "Engineer",
}
...そのコードを実行します。ジョブ作成コードのどこにも Palo Alto が言及されているわけではないことに注意してください。業務内容、会社名もなし。
$ python search_jobs.py Search Results: Senior Software Engineer: Experienced software <b>engineer</b> required for full-time position. Leadership ability and ability to thrive in highly competitive environment a must. Ignore postings from that "Bar" company, their microkitchen ...
結果が見つかりました。パロアルトは仕事から 10 マイル以内です(10 マイルは LocationFilter で定義した境界です)。
他にも、この Codelab では取り扱わない場所でできることがあります。次のことをおすすめします。
- 通勤ベースの検索 - 距離ではなく通勤時間で定められたエリア内の求人情報を検索します。考えているときに...読者の皆さん、こんにちは誰にでもできます。
- 複数地域検索 - 複数の都市の求人情報を同時に検索する方法。
キーワードと拡大
もちろん、求人の名称や説明は、それが検索クエリに適しているかどうかを判断する際に重要な役割を果たします。「スクラム マスター」の求人情報が掲載され、その説明に「ソフトウェア デベロッパーの管理」と記載されている場合は、「ソフトウェア開発マネージャー」を検索してください。求人情報に大量のキーワードを詰め込んだだけでは、関連性の低い求人が表示されてしまいます。
この API には、結果の管理を容易にするために検索を実行する際に渡すことができるパラメータもあります。キーワードのマッチタイプでは、通常の ML 検索の結果以外でキーワードで検索が必要な場合に、一致を有効または無効にできます。また、場所に特化したフィルタも緩和されます。対象範囲を広げると、指定したパラメータの検索範囲が広がり、より多くの検索結果を得ることができます。
その動作例を次に示します。まず、範囲の拡張を有効にせずに、検索語句「アジャイル」を使用して検索します。この Codelab で提供されているスクリプトを使用して会社と求人を作成した場合、何も表示されません。なぜでしょう。「アジャイル」という単語がリスティングにないためです。ただし、エンジニアリング ジョブに関連する一般的なプログラミング方法です。
キーワードを広げて何が変化するか見てみましょう。
search_jobs.py(拡張が有効の場合)
...
job_query = {
'query': "Agile",
}
request = {
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL',
'enableBroadening' : True
}
...スクリプトを再実行すると、今度はいくつかの結果が表示されます。
$ python search_jobs.py Search Results: Junior Software Engineer: Hiring entry level software engineer required for full-time position. Must be passionate about industry intersection of horses and technology. Ability to intelligently discuss the equine singularity a major ... Senior Software Engineer: Experienced software engineer required for full-time position. Leadership ability and ability to thrive in highly competitive environment a must. Ignore postings from that "Bar" company, their microkitchen ... Test Engineer: Hiring Test engineer for full-time position with Tandem. Must be detail oriented and (obviously) comfortable with pair programming.. Join Tandem today!
では、すべてを返すための単なる包括的なフラグではないことを確かめるにはどうすればよいでしょうか。「アジャイル」を「正確」、「ハイテク」、「スイフト」などの類義語に置き換えてください。いずれの場合も、何も表示されません。
ただし、拡張の実現にはトレードオフがあります。求人検索のベスト プラクティス ページでは、このパラメータを有効にすると検索結果の数が増えますが、結果全体の関連性は下がると明記されています。基本的に、この機能は数量を増加させるリスクを冒してリスクをもたらします。言い換えれば、求職者がフレーズを正確に理解する方法を見つけられない場合もあります。
多様化
よく似た複数の求人が検索結果として互いに近接して返されることがあります。その結果、求職者が利用可能なさまざまな結果を確認できなくなる可能性があります。
多様化機能はこれを修正します。求人は、役職、役職、地域に基づいて類似と判断されます。よく似た結果がクラスタ化され、そのクラスタ内の 1 つのジョブが検索結果の上位に表示されるようになります。「エンジニア」を検索したときに、次のような結果が表示されることにお気づきでしょうか。
$ python search_jobs.py Test Engineer ... Senior Software Engineer ... Junior Software Engineer ... Test Engineer ...
なぜそのような注文をしたのですか?ソフトウェア エンジニアの職務は 2 つの企業(HorseHub と FooCorp)のものです。説明は異なります。どちらもソフトウェア エンジニアリングの仕事ですが、結果的に互いに近接していると保証できる程度に異なります。
一方、「テスト エンジニア」のリスティングは、同じ会社が 2 回投稿したものとまったく同じものになります。多様化はデフォルトで有効になっているため、テスト エンジニアの 2 番目のリストは、(より関連性があるとしても)より関心を引く他のリスティングよりも重要でないと見なされました。
多様性のレベルには本当に 3 つの設定がありますが、実際に選択するのは 1 つだけです。それらは次のとおりです。
- DIVERSIFICATION_LEVEL_UNSPECIFIED - レベルを指定しておらず、デフォルトが何でも動作することを確認します(現在、デフォルトは SIMPLE と同じ動作です)。
- 無効
- シンプル - デフォルトの多様化動作。よく似た結果が検索結果の最終ページの最後に表示されるように並べ替えます。
ここでは、リクエストの diversificationLevel を明示的に設定する方法を示します。この Codelab で行った設定についての他のほとんどの操作と同様に、リクエストを調整するだけで済みます。求人のクエリとリクエストについて以下の設定を試してください。これにより、多様化が無効になり、検索キーワードが「エンジニア」に設定されます。
search_jobs.py(多様化レベル)
job_query = {
'query': "Engineer",
}
# 2) Throw RequestMetadata object in a request
request = {
'requestMetadata': request_metadata,
'jobQuery': job_query,
'jobView' : 'JOB_VIEW_FULL',
'diversificationLevel': 'DISABLED'
}ここで search_jobs.py を実行すると、わずかに異なる順序が表示されます。テスト エンジニアのジョブは互いに近接しています。
$python search_jobs.py Test Engineer: Hiring Test <b>Engineer</b> for full-time position with Tandem. Must be detail oriented and (obviously) comfortable with pair programming. Will be working with team of Software Engineers. Join Tandem today! Test Engineer: Hiring Test <b>Engineer</b> for full-time position with Tandem. Must be detail oriented and (obviously) comfortable with pair programming. Will be working with team of Software Engineers. Join Tandem today! Software Engineer: Experienced software <b>engineer</b> required for full-time position. Leadership ability and ability to thrive in highly competitive environment a must. Ignore postings from that "Bar" company, their microkitchen ... Software Engineer: Hiring entry level software <b>engineer</b> required for full-time position. Must be passionate about industry intersection of horses and technology. Ability to intelligently discuss the equine singularity a major ...
Job Search API を使用してジョブにクエリを実行する方法を正式に学びました。
学習した内容
- Cloud プロジェクトの設定
- 開発環境の設定
- ジョブのクエリ
- 検索パラメータを含む JobQuery オブジェクトを追加する
- jobView を使用して返されるデータの量を制限する
- ページ設定
- クエリを自動的にスペルチェック
- 注目の求人
- 検索の関連性を調整する
- 地理的位置
- キーワードと拡大
- 多様化
詳細
- Cloud Talent Solution のデベロッパー チャンネル シリーズを見る
- GitHub プロジェクトを表示します
- API ドキュメントを見る
- google-cloud-talent-solution でタグ付けされた Stack Overflow に質問を投稿したり回答を探したりできます。