

在此 Codelab 中,您将了解如何开始使用 Stackdriver 来监控和查看 Google Cloud Platform 服务和虚拟机的性能指标和日志。
在此 Codelab 中,您将
- 熟悉 Stackdriver 首页。
- 了解信息中心和图表。
- 创建拨测。
- 创建简单的提醒政策。
- 处理提醒事件。
- 浏览日志查看器。
您使用 Stackdriver 的经验如何?
自定进度的环境 设置
如果您还没有 Google 账号(Gmail 或 Google Apps),则必须创建一个。
登录 Google Cloud Platform Console (console.developers.google.com) 并创建一个新项目:


请记住项目 ID,它是所有 Google Cloud 项目中的唯一名称。它稍后将在此 Codelab 中被称为 PROJECT_ID。
非常重要 - 访问 Compute Engine 页面,以开始启用 Compute Engine API:

然后依次选择:Compute → Compute Engine → 虚拟机实例

首次执行此操作时,您会看到一个屏幕,其中显示“Compute Engine 正在准备就绪。这可能需要一分钟或更长时间”。您可以继续登录下方的 Google Cloud Shell,但在该操作完成之前,您无法创建虚拟机。
您将通过 Google Cloud Shell( 在云端运行的命令行环境)完成大部分工作。基于 Debian 的这个虚拟机已加载了您需要的所有开发工具,并提供 5GB 的永久性主目录。点击屏幕右上角的图标,打开 Google Cloud Shell:

最后,使用 Cloud Shell 设置默认可用区和项目配置:
$ gcloud config set compute/zone us-central1-b $ gcloud config set compute/region us-central
您也可以选择不同的可用区。如需详细了解地区,请参阅“区域和地区”说明文档。
在本部分中,您将使用 Cloud Launcher 创建运行 nginx+ 的 Compute Engine 实例。我们需要这些实例来演示监控和提醒功能。您可以通过图形化控制台或命令行创建 Compute Engine 实例。本实验将引导您完成命令行操作。
现在,我们开始吧。
使用 gcloud 设置项目 ID:
$ gcloud config set project PROJECT_ID
接下来,请务必按原样复制并粘贴以下内容:
$ for i in {1..3}; do \
gcloud compute instances create "nginx-plus-$i" \
--machine-type "n1-standard-1" \
--metadata "google-cloud-marketplace-solution-key=nginx-public:nginx-plus" \
--maintenance-policy "MIGRATE" --scopes default="https://www.googleapis.com/auth/cloud-platform" \
--tags "http-server","google-cloud-marketplace" \
--image "https://www.googleapis.com/compute/v1/projects/nginx-public/global/images/nginx-plus-ubuntu1404-v20150916-final" \
--boot-disk-size "10" --boot-disk-type "pd-standard" \
--boot-disk-device-name "nginx-plus-$i"; done您会看到有关磁盘大小的警告消息,然后看到以下输出,因为每个虚拟机都是创建的:
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS nginx-plus-1 us-central1-b n1-standard-2 X.X.X.X X.X.X.X RUNNING ...
记下 EXTERNAL_IP,这在稍后非常重要。
这些操作可能需要几分钟才能完成。
默认情况下,Google Cloud Platform 仅允许访问少数端口。由于我们很快就要访问 Nginx,因此我们先在防火墙配置中启用端口 80:
$ gcloud compute firewall-rules create allow-80 --allow tcp:80 --target-tags "http-server" Created [...]. NAME NETWORK SRC_RANGES RULES SRC_TAGS TARGET_TAGS allow-80 default 0.0.0.0/0 tcp:80 http-server
此命令将创建一个名为 allow-80 的防火墙规则,该规则具有以下默认值:
- 允许建立入站连接的 IP 地址块列表 (
--source-ranges) 设置为0.0.0.0/0(任何位置)。 - 指示网络上可接受入站连接的实例集的实例标记列表设置为“无”,这意味着防火墙规则适用于所有实例。
运行 gcloud compute firewall-rules create --help 即可查看所有默认值。
创建第一个实例后,您可以前往 http://EXTERNAL_IP/ 测试 nginx 是否正在运行且可访问,其中 EXTERNAL_IP 是 nginx-plus-1 的公共 IP,您应该能够看到 Nginx 页面:

您还可以通过输入以下命令来查看正在运行的实例:
$ gcloud compute instances list
Google Stackdriver 是一款强大的监控解决方案,集成了各种工具,可帮助您轻松监控和分析云端应用。您可以使用 Stackdriver 从一个中心位置查看性能指标、设置和接收提醒、添加自己的自定义信息中心和指标、查看日志和轨迹、设置集成式信息中心。
接下来的步骤将引导您启用 Stackdriver 并使用控制台。
默认情况下,Google Stackdriver 目前处于 Beta 版阶段,不会为新项目启用。如需启用此功能,请前往左侧导航栏,然后点击“监控”(您可能需要向下滚动才能找到该选项)

在下一个界面中,点击“启用监控”,然后等待一分钟,系统会启用监控。

启用后,内容会发生变化,您会看到以下文字。点击“前往监控”即可开始探索!您需要使用 Google 账号登录,然后系统会将您转到项目的 Stackdriver 控制台,您可以在其中执行和分析与监控相关的任务。

我们先来熟悉一下首页。

- 顶部菜单:用于选择不同的视图 / 上下文,以及访问所有可用的 Stackdriver 操作。
- 信息中心:这些信息中心显示的是正在监控的指标和事件。最初,这些是基于项目中的资源预定义的系统信息中心,但您也可以自行创建自定义信息中心。
- 拨测:定期检查面向用户的资源的可用性,并在这些资源不可用时启用提醒。
- 群组列表:群组用于将具有相同属性和特征的资源分组在一起,以便在执行监控和提醒等任务时,将这些资源作为一个群组或集群进行处理。这些指标可以是自动发现的,也可以是用户定义的。
- “突发事件”窗格:此窗格用于跟踪提醒突发事件。在您定义提醒政策之前,此处不会显示任何内容。
- 事件日志:列出与受监控资源相关的事件,例如实例更改、突发事件等。
在检查图表之前,您会注意到,在初始实例初始化之后,大多数线条都变得平缓。我们来尝试在其中一个实例上生成一些负载,看看是否可以“取消扁平化”其中一些图表。
如需通过 Cloud Shell 命令行通过 SSH 连接到实例,请执行以下操作:
$ gcloud compute ssh nginx-plus-1 ... Do you want to continue (Y/n)? Y ... Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): [Hit Enter] Enter same passphrase again: [Hit Enter] ... yourusername@nginx-plus-1:~$
就是这样!非常简单。(在生产环境中,请务必输入口令 :) 另请注意,系统可能不会提示您添加口令。
或者,您也可以直接从控制台通过 SSH 连接到实例,方法是依次前往 Compute Engine > 虚拟机实例,然后点击 SSH。

In the SSH window, type:
yourusername@nginx-plus-1:~$ sudo apt-get install rand
yourusername@nginx-plus-1:~$ for i in {1..10}; do dd if=/dev/zero of=/dev/null count=$(rand -M 80)M; sleep 60; done &现在,实例 nginx-plus-1 的 CPU 正在加载。我们可以返回到 Stackdriver 信息中心标签页并开始探索,但在返回到 Stackdriver 信息中心页面之前,我们先来安装 Cloud Logging 代理。
Fetch and install the script:
yourusername@nginx-plus-1:~$ curl -sS https://dl.google.com/cloudagents/add-logging-agent-repo.sh | sudo bash /dev/stdin --also-install
请注意,在生产环境中安装时,请务必检查 SHA-256 哈希。如需详细了解安装流程,请点击此处。
现在,您可以返回到 Google Stackdriver 控制台了。
请花时间熟悉如何浏览和使用信息中心及图表。使用鼠标悬停在图表线上,看看会发生什么。更改图表的时间段(控件位于右上角)。您可以随时点击控制台左上角的 Stackdriver 徽标,返回到“首页”视图。
我们来看看 CPU 利用率图表:

图表中的部分元素如下:
- 突出显示的折线是当前所选的指标(一个图表可以显示多个指标)。
- 灰色水平线表示鼠标悬停所指向的时间点。
- 底部是资源名称,以及所选时间点的值。
- 图表顶部是彩色圆点,表示事件日志中详细记录的事件。您可以点击这些标签页来获取事件列表。注意:如果您还没有任何活动,则可能看不到任何数据。
- 图表右上角有三个控件(从左到右):
- 切换显示/隐藏图表下方的指标列表
- 切换全屏模式
- 包含各种实用功能的菜单(如果您有非常详细的图表,一定要尝试一下 X 射线模式!)。请注意“查看日志”选项,我们稍后会介绍该选项。
拨测可让您快速验证任何网页、实例或资源群组的健康状况。每个配置好的拨测都会在全球不同位置定期运行。拨测可用作提醒政策定义中的条件。
您可以在顶部菜单中依次选择提醒 > 正常运行时间检查,以显示检查及其状态。您还可以在 Google Stackdriver 信息中心和专门针对特定资源的页面上找到正常运行时间检查部分。对于涵盖一组资源的正常运行时间检查,您可以展开检查以显示该组中各个成员的状态。
让我们来创建一项正常运行时间检查。在 Stackdriver 主屏幕中找到“拨测”微件:

系统随即会显示一个新弹出式窗口。我们可以为单个资源或一组资源配置正常运行时间检查,利用自定义标头和载荷,添加身份验证和其他选项。目前,我们仅使用默认的 HTTP 检查,该检查将每 1 分钟检查一次自动创建的 nginx 组。
请参考下面的屏幕截图填写不同的选项:

点击“测试”按钮,确保您的端点可访问(您应该会看到 3 个绿色对勾标记),然后点击“保存”。注意:如果您没有收到“确定”响应,仍然可以继续完成实验,因为这可能只是测试检查时间问题。
接下来,您会看到“已创建拨测”框,系统会询问您是否要为此拨测创建提醒政策。我们将在下一部分中执行此操作 - 请勿点击任何内容。
您可以设置提醒政策,以定义用于确定云服务和平台是否正常运行的条件。Cloud Monitoring 提供了许多不同类型的指标和健康检查,您可以在政策中使用这些指标和健康检查。
如果违反了提醒政策的条件,系统会创建一个突发事件,并显示在 Stackdriver 控制台的“突发事件”部分。回复者可以确认收到通知,并在处理完毕后关闭突发事件。
点击“创建提醒政策”,然后继续配置政策。

现在,您应该会看到以下界面:
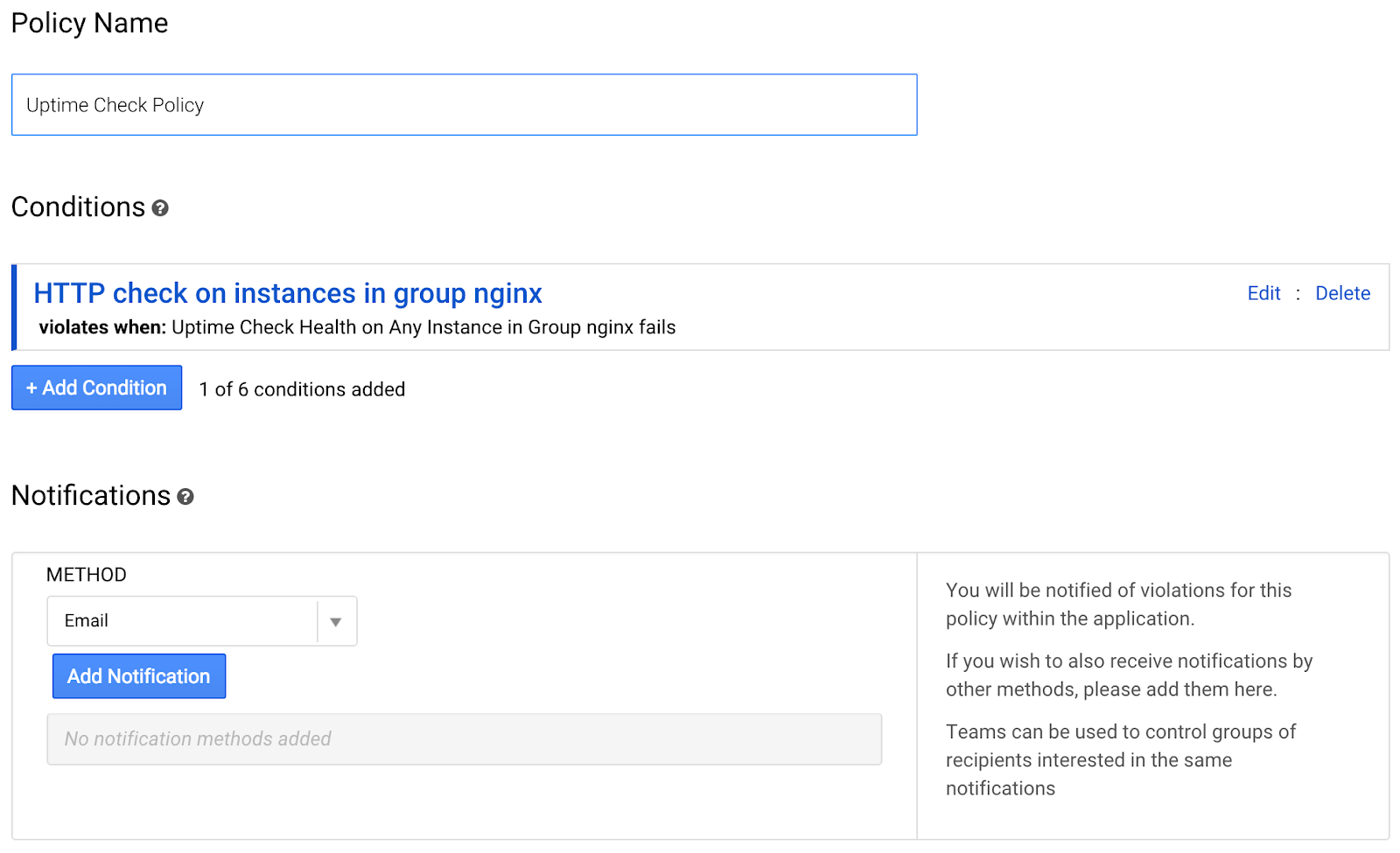
输入政策的名称:“nginx 组的拨测”

现在,在通知方法部分,点击“添加通知”

输入与您的 Google Cloud 账号关联的电子邮件地址。滚动到屏幕底部,然后点击“保存政策”。
返回 Stackdriver 首页(点击左上角的徽标)。
现在,您应该会在信息中心的“拨测”部分看到您创建的拨测。目前,状态应为绿色。

向下滚动到“事件日志”,您应该会看到创建提醒政策的事件。
现在,我们来制造一些麻烦吧 :)
让我们看看停止 Nginx 服务时会发生什么情况。
再次通过 Cloud Shell 命令行 SSH 连接到实例:
$ gcloud compute ssh nginx-plus-1
然后输入:
yourusername@nginx-plus-1:~$ sudo service nginx stop
现在,我们创建的拨测应该会失败。因此,系统会创建一个突发事件,并向您在上面输入的地址发送一封提醒通知电子邮件。系统需要一分钟时间才能检测到该情况(请注意设置拨测时指定的 1 分钟时长),因此我们前往 nginx 组页面查看。
您可以通过多种方式前往特定资源组的信息中心:
- 您可以在首页中点击群组的名称。这会切换到专门用于监控群组资源的信息中心。您还可以自定义此信息中心。

- 在顶级菜单中,选择“群组”,然后找到您的特定群组。
现在,点击自动刷新按钮,确保信息中心自动刷新。该图标将变为红色。

您现在看到的是专门针对自动创建的 nginx 群组的信息中心。右侧是与该群组相关的几个关键指标的图表。换句话说,这些图表显示了与 nginx 组中的所有资源(我们之前创建的 3 个 nginx+ 虚拟机)相关的指标。
在左侧,您会看到与群组相关的各种信息:
- 突发事件状态
- 拨测
- 事件日志
- 资源(实例、卷等)列表
请注意,这些日志仅与群组相关,因此事件日志仅列出群组的事件。
您可以点击不同的资源或子群组,转到其各自的专用信息中心。例如,点击 nginx-plus-1 会将您带到仅包含与该实例相关的指标和检查的信息中心。立即尝试:

当一组提醒条件满足特定条件时,系统会打开 Stackdriver 突发事件。在本例中,我们为 nginx 正常运行时间检查设置了提醒,该检查目前在 nginx-plus-1 上失败。借助突发事件,您可以跟踪当前状况,并在处理问题时与其他团队成员协作。
我们来确认一下突发事件,让其他团队成员知道我们正在调查情况:

请注意,此操作会将突发事件的状态从“未结”更改为“已确认”。情况仍在持续(提醒政策条件仍未得到满足),但您正在向团队成员表明您正在处理此问题。系统也会在事件日志中记录此操作。
突发事件可以手动解决,也可以自动解决。如需查看后者,请通过 SSH 连接到 nginx-plus-1 并解决问题:
yourusername@nginx-plus-1:~$ sudo service nginx start
现在,拨测恢复正常后,突发事件会自动解决。您也可以选择“解决”菜单项自行解决此问题。
Cloud Logging 是一种日志记录即服务解决方案,可提供一个便捷的集中位置来查看和查询来自多个来源的日志。您还可以使用日志将其导出到其他目标位置(Google Cloud Storage、Google BigQuery 或 Google Cloud Pub/Sub)。
如需访问 Cloud 日志查看器,请从 Cloud 控制台左侧的菜单中选择它:

系统会将您带到日志查看器,您可以在其中使用预定义的查询,也可以创建并保存自己的自定义查询,实时查看来自云部署中多个资源的日志流,根据日志创建指标,导出日志等等。
您可以使用一些便捷的控件快速过滤出相关信息:

- 按资源类型过滤
- 过滤出所选资源的特定日志类型
- 过滤特定日志级别
- 过滤到特定日期,以便检查过去的问题
- 切换持续播放
- 用于搜索文本、标签或正则表达式的搜索框
现在,我们来练习如何缩小范围,找到特定日志。
从资源类型选择器(屏幕截图中的 1)中,依次选择“Compute Engine”->“所有资源类型”
接下来,从日志类型选择器(屏幕截图中的 2)中选择 nginx-access 以查看所有访问日志
现在,开启持续流式传输 (5),即可在日志到达时观看。如果您没有看到任何新日志,请尝试在浏览器中输入其中一个 nginx-plus 虚拟机的外部 IP 地址。
虽然此 Codelab 不会深入介绍日志,但您可以在清理之前随意探索。如需详细了解如何浏览查看器,请点击此处。如果您想更广泛地了解 Cloud Logging 的用途,请点击此处查看相关文档的顶级目录。
我们来释放在 Codelab 期间创建的计算资源。在 Cloud Shell 中运行以下命令:
$ for i in {1..3}; do \
gcloud -q --user-output-enabled=false compute instances delete nginx-plus-$i ; done接下来,前往 Google Stackdriver 控制台(从 Cloud 控制台左侧窗格菜单中选择“监控”),然后移除我们创建的拨测和提醒政策。您可以通过顶级菜单项“提醒”>“政策概览”和“提醒”>“拨测”来完成此操作。
现在,您已准备好监控云应用。
所学内容
- 熟悉 Stackdriver 首页。
- 了解信息中心和图表。
- 创建正常运行时间检查。
- 创建简单的提醒政策。
- 处理提醒事件。
- 浏览日志查看器。
后续步骤
- 尝试创建自定义信息中心。
- 了解创建提醒政策时的不同选项。
- 探索使用 Cloud Logging 时可用的不同选项。
了解更多
向我们提供反馈
- 请抽出片刻时间,完成这份非常简短的调查问卷