
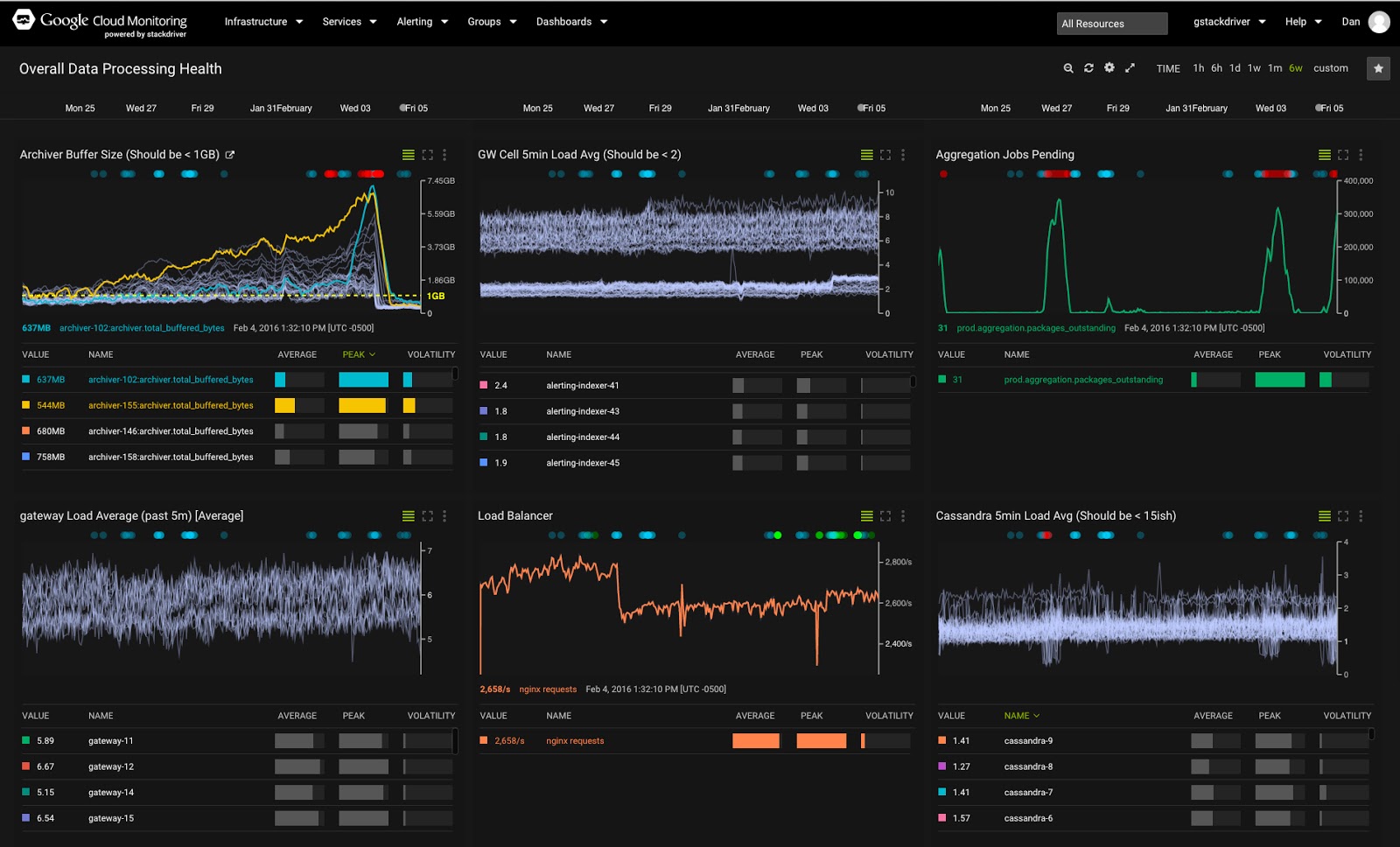
この Codelab では、Stackdriver を使用して Google Cloud Platform サービスと VM のパフォーマンス指標とログをモニタリングし、レビューする方法を学習します。
この Codelab では、次のことを行います。
- Stackdriver のホームページについて理解します。
- ダッシュボードとグラフについて理解します。
- 稼働時間チェックを作成する。
- シンプルなアラート ポリシーを作成します。
- アラート インシデントを操作します。
- ログビューアを操作します。
Stackdriver の使用経験について教えてください。
セルフペース型の環境 設定
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。
Google Cloud Platform のコンソール(console.developers.google.com)にログインし、新しいプロジェクトを作成します。
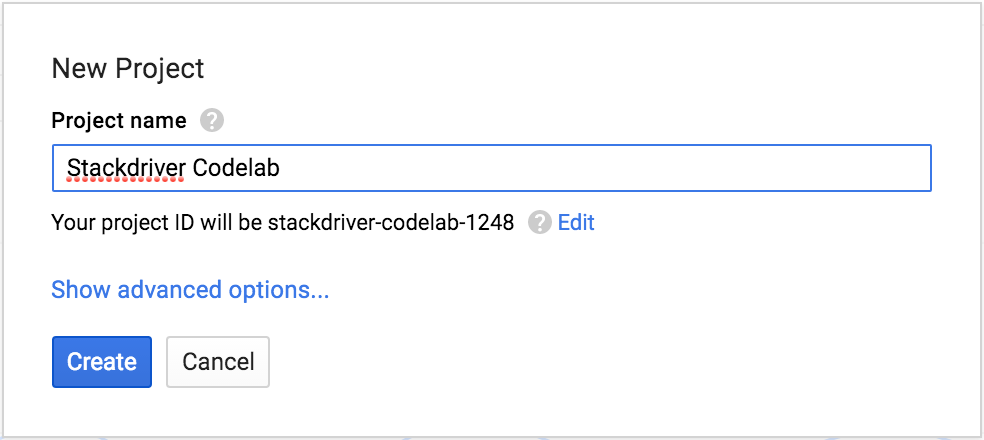
プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります。以降、このコードラボでは PROJECT_ID と呼びます。
非常に重要 - Compute Engine API の有効化を開始するには、Compute Engine ページにアクセスします。
[Compute] → [Compute Engine] → [VM インスタンス] に移動します。

初めてこの操作を行う場合は、「Compute Engine の準備中です。この処理には 1 分以上かかることがあります。」以下の Google Cloud Shell には引き続きログインできますが、このオペレーションが完了するまで VM を作成することはできません。
ほとんどの作業は、Google Cloud Shell( Cloud 上で動作するコマンドライン環境)で行います。この Debian ベースの仮想マシンには、必要な開発ツールがすべて用意されており、永続的な 5 GB のホーム ディレクトリが提供されています。画面の右上にあるアイコンをクリックして、Google Cloud Shell を開きます。
最後に、Cloud Shell を使用してデフォルト ゾーンとプロジェクト構成を設定します。
$ gcloud config set compute/zone us-central1-b $ gcloud config set compute/region us-central
異なるゾーンを選択することもできます。ゾーンの詳細については、リージョンとゾーンのドキュメントをご確認ください。
このセクションでは、Cloud Launcher を使用して nginx+ を実行する Compute Engine インスタンスを作成します。モニタリングとアラートをデモンストレートするには、これらのインスタンスが必要です。Compute Engine インスタンスは、グラフィカル コンソールまたはコマンドラインから作成できます。このラボでは、コマンドラインについて説明します。
それでは始めましょう。
gcloud を使用してプロジェクト ID を設定します。
$ gcloud config set project PROJECT_ID
次に、このコードをそのままコピーして貼り付けます。
$ for i in {1..3}; do \
gcloud compute instances create "nginx-plus-$i" \
--machine-type "n1-standard-1" \
--metadata "google-cloud-marketplace-solution-key=nginx-public:nginx-plus" \
--maintenance-policy "MIGRATE" --scopes default="https://www.googleapis.com/auth/cloud-platform" \
--tags "http-server","google-cloud-marketplace" \
--image "https://www.googleapis.com/compute/v1/projects/nginx-public/global/images/nginx-plus-ubuntu1404-v20150916-final" \
--boot-disk-size "10" --boot-disk-type "pd-standard" \
--boot-disk-device-name "nginx-plus-$i"; doneディスクサイズに関する警告メッセージが表示され、各 VM の作成時に次の出力が表示されます。
NAME ZONE MACHINE_TYPE PREEMPTIBLE INTERNAL_IP EXTERNAL_IP STATUS nginx-plus-1 us-central1-b n1-standard-2 X.X.X.X X.X.X.X RUNNING ...
EXTERNAL_IP をメモしておきます。これは後で重要になります。
これらのオペレーションが完了するまで数分かかることがあります。
デフォルトでは、Google Cloud Platform で許可されるポート アクセスはごくわずかです。まもなく Nginx にアクセスするため、ファイアウォール構成でポート 80 を有効にしましょう。
$ gcloud compute firewall-rules create allow-80 --allow tcp:80 --target-tags "http-server" Created [...]. NAME NETWORK SRC_RANGES RULES SRC_TAGS TARGET_TAGS allow-80 default 0.0.0.0/0 tcp:80 http-server
これにより、次のデフォルト値を持つ allow-80 という名前のファイアウォール ルールが作成されます。
- インバウンド接続を許可する IP アドレス ブロックのリスト(
--source-ranges)が0.0.0.0/0(すべての場所)に設定されている。 - インバウンド接続を受け入れるネットワーク上のインスタンスのセットを示すインスタンス タグのリストが none に設定されています。これは、ファイアウォール ルールがすべてのインスタンスに適用されることを意味します。
すべてのデフォルトを表示するには、gcloud compute firewall-rules create --help を実行します。
最初のインスタンスを作成したら、http://EXTERNAL_IP/ に移動して nginx が実行されてアクセス可能かどうかをテストできます。ここで、EXTERNAL_IP は nginx-plus-1 のパブリック IP です。Nginx ページが表示されます。
次のコマンドを入力して、実行中のインスタンスを確認することもできます。
$ gcloud compute instances list
Google Stackdriver は、さまざまなツールを統合して、クラウドベースのアプリケーションのモニタリングと分析を容易にする強力なモニタリング ソリューションです。Stackdriver を使用すると、パフォーマンス指標の表示、アラートの設定と受信、独自のカスタム ダッシュボードと指標の追加、ログとトレースの表示、統合ダッシュボードの設定をすべて一元的に行うことができます。
次の手順では、Stackdriver を有効にしてコンソールを操作します。
デフォルトでは、Google Stackdriver は現在ベータ版であり、新しいプロジェクトでは有効になっていません。有効にするには、左側のナビゲーション バーで [モニタリング] をクリックします(この項目を表示するには、必要に応じて下にスクロールしてください)。
次の画面で [Enable Monitoring] をクリックし、有効になるまで 1 分ほど待ちます。
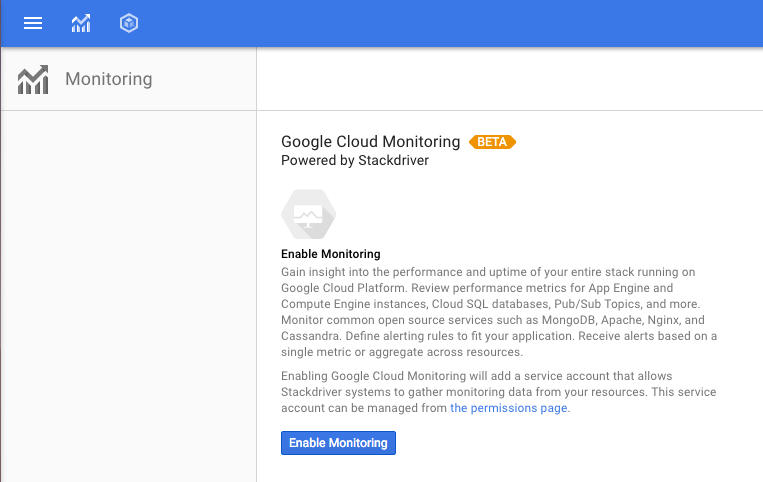
有効にすると、コンテンツが変更され、以下のテキストが表示されます。[モニタリングに移動] をクリックして、詳細を確認してください。Google でログインすると、プロジェクトの Stackdriver コンソールに移動します。ここで、モニタリング関連のタスクを実行して分析します。
ホームページについて説明します。
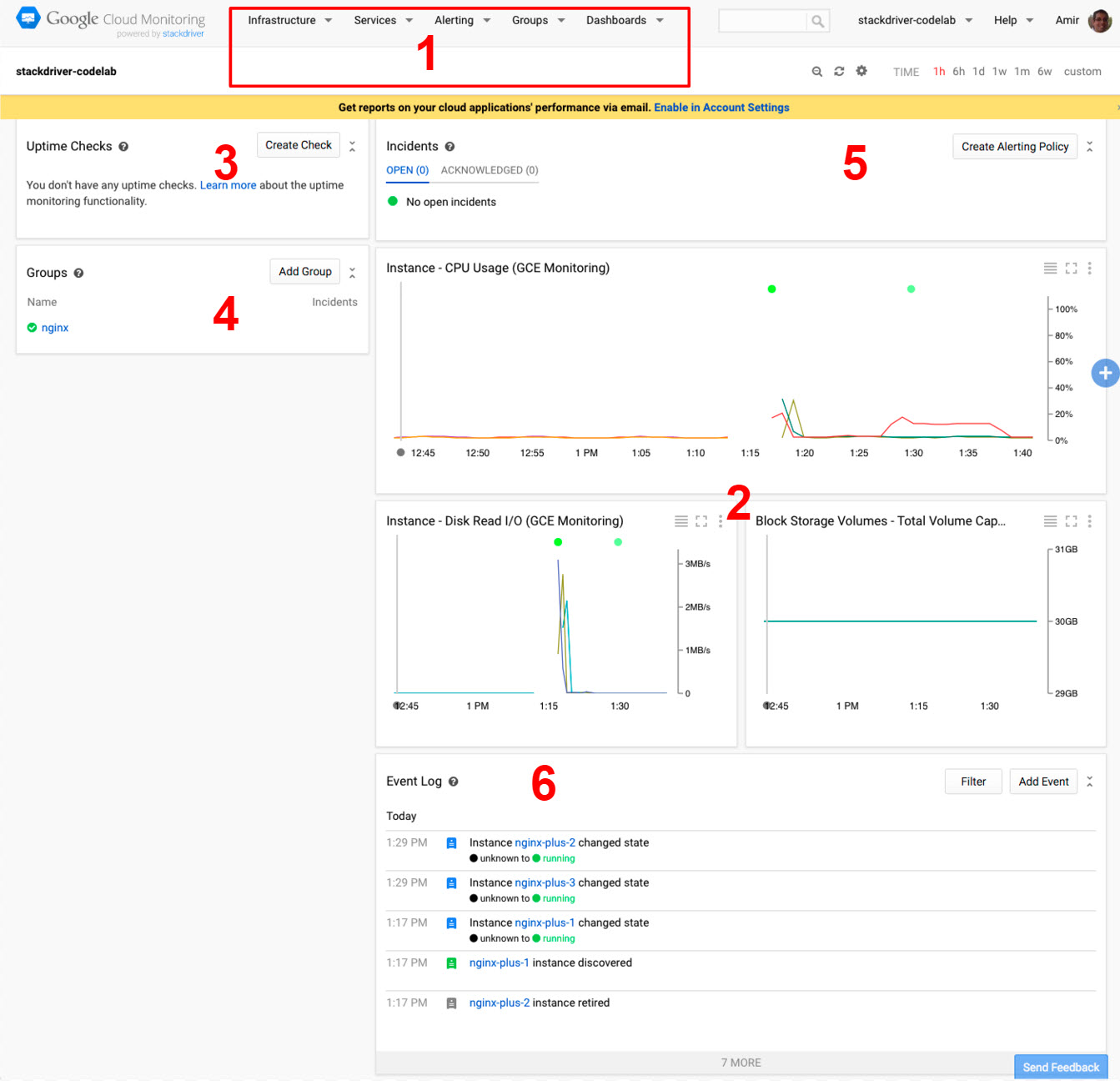
- 上部のメニュー: さまざまなビューやコンテキストを選択し、利用可能なすべての Stackdriver アクションにアクセスするために使用します。
- ダッシュボード: モニタリング対象の指標とイベントのダッシュボードです。最初は、プロジェクト内のリソースに基づく事前定義のシステム ダッシュボードですが、独自のカスタム ダッシュボードを作成することもできます。
- 稼働時間チェック: ユーザー向けリソースの可用性を定期的にチェックし、利用できなくなった場合にアラートを有効にします。
- グループ リスト: グループは、プロパティと特性を共有するリソースをグループ化して、モニタリングやアラートなどのタスクでグループまたはクラスタとして処理できるようにするために使用されます。これらは自動検出することも、ユーザー定義することもできます。
- [インシデント] ペイン: [インシデント] ペインは、アラート インシデントをトラッキングします。アラート ポリシーを定義するまで、ここには何も表示されません。
- イベントログ: モニタリング対象リソースに関連するイベント(インスタンスの変更、インシデント イベントなど)を一覧表示します。
グラフを見る前に、ほとんどの線が最初のインスタンスの初期化後に平坦になっていることに気づくでしょう。インスタンスの 1 つに負荷を生成して、一部のインスタンスのフラット化を解除できるかどうかを確認してみましょう。
Cloud Shell コマンドラインからインスタンスに SSH で接続するには:
$ gcloud compute ssh nginx-plus-1 ... Do you want to continue (Y/n)? Y ... Generating public/private rsa key pair. Enter passphrase (empty for no passphrase): [Hit Enter] Enter same passphrase again: [Hit Enter] ... yourusername@nginx-plus-1:~$
これで完了です。簡単でしょう。(本番環境では、パスフレーズを必ず入力してください)。また、パスフレーズの追加を求めるメッセージが表示されない場合もあります。
または、[Compute Engine] > [VM インスタンス] に移動して [SSH] をクリックすると、コンソールからインスタンスに直接 SSH 接続することもできます。
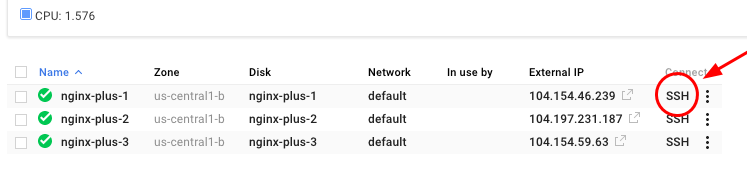
In the SSH window, type:
yourusername@nginx-plus-1:~$ sudo apt-get install rand
yourusername@nginx-plus-1:~$ for i in {1..10}; do dd if=/dev/zero of=/dev/null count=$(rand -M 80)M; sleep 60; done &これで、インスタンス nginx-plus-1 の CPU が読み込まれます。Stackdriver ダッシュボードのタブに戻って探索を開始できますが、Stackdriver ダッシュボードのページに戻る前に、Cloud Logging エージェントをインストールしましょう。
Fetch and install the script:
yourusername@nginx-plus-1:~$ curl -sS https://dl.google.com/cloudagents/add-logging-agent-repo.sh | sudo bash /dev/stdin --also-install
本番環境にインストールする場合は、SHA-256 ハッシュを必ず確認してください。インストール プロセスの詳細については、こちらをご覧ください。
Google Stackdriver コンソールに戻ります。
ダッシュボードとグラフの操作と使用方法をよく理解しておきましょう。グラフの線にマウスカーソルを合わせて、何が起こるかを確認します。グラフの期間を変更します(コントロールは右上隅にあります)。コンソールの左上隅にある Stackdriver ロゴをクリックすると、いつでも「ホームページ」ビューに戻ることができます。
CPU 使用率グラフを見てみましょう。
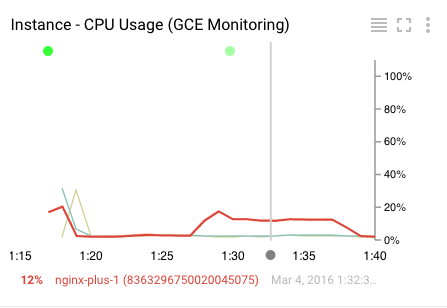
グラフの要素は次のとおりです。
- ハイライト表示された線は、現在選択されている指標です(グラフには複数の指標を表示できます)。
- グレーの水平線は、マウスホバーが指している時点を表します。
- 下部には、リソースの名前と、選択した時点の値が表示されます。
- グラフの上部には、イベントログに詳細が記載されているイベントを表す色の付いたドットが表示されます。これらをクリックすると、イベントのリストが表示されます。注: まだイベントがない場合は、何も表示されないことがあります。
- グラフの右上には、次の 3 つのコントロールがあります(左から順に)。
- グラフの下にある指標のリストの表示/非表示を切り替えます
- フルスクリーン モードに切り替える
- さまざまな機能が用意されたメニュー(詳細なグラフが表示されたら、X 線モードを試してみてください)。[View Logs] オプションに注目してください。これについては後ほど説明します。
稼働時間チェックで、任意のウェブページ、インスタンス、リソース グループの状態をすばやく確認できます。構成された各チェックに対して、世界中のさまざまな場所から定期的に接続が行われます。稼働時間チェックは、アラート ポリシー定義の条件としても使用できます。
チェックとそのステータスを表示するには、上部のメニューで [アラート] > [稼働時間チェック] を選択します。Google Stackdriver ダッシュボードと特定のリソース専用のページには、[稼働時間チェック] セクションもあります。リソース グループを対象とする稼働時間チェックでは、チェックを拡大してグループの個々のメンバーのステータスを表示できます。
稼働時間チェックを作成しましょう。Stackdriver のホーム画面で稼働時間チェック ウィジェットを見つけます。
新しいポップアップが表示されます。単一のリソースまたはリソース グループの稼働時間チェックを構成し、カスタム ヘッダーとペイロードを利用して、認証などのオプションを追加できます。ここでは、自動作成された nginx グループを 1 分ごとにチェックするデフォルトの http チェックを使用します。
以下のスクリーンショットを参考に、さまざまなオプションを入力します。
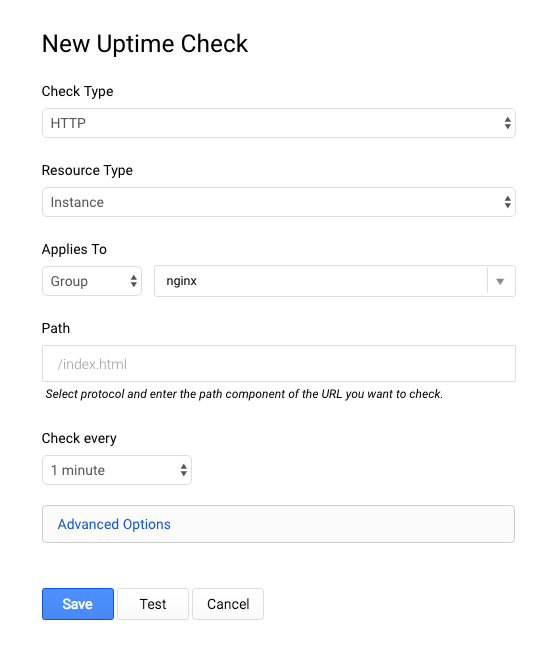
[テスト] ボタンをクリックして、エンドポイントに到達できることを確認し(緑色の OK が 3 つ表示されます)、[保存] をクリックします。注: OK が返ってこなくても、ラボを進めることができます。テストチェックのタイミングの問題である可能性があります。
次に、[稼働時間チェックが作成されました] というボックスが表示され、このチェックのアラート ポリシーを作成するかどうかをたずねられます。次のセクションでその操作を行います。まだ何もクリックしないでください。
アラート ポリシーを設定して、クラウド サービスとプラットフォームが正常に動作しているかどうかを判断する条件を定義できます。Cloud Monitoring には、ポリシーで使用できるさまざまな種類の指標とヘルスチェックが用意されています。
アラート ポリシーの条件に違反すると、インシデントが作成され、Stackdriver コンソールの [Incidents] セクションに表示されます。応答者は通知の受信を確認し、対応後にインシデントを閉じることができます。
[アラート ポリシーを作成] をクリックして、ポリシーの構成に進みます。
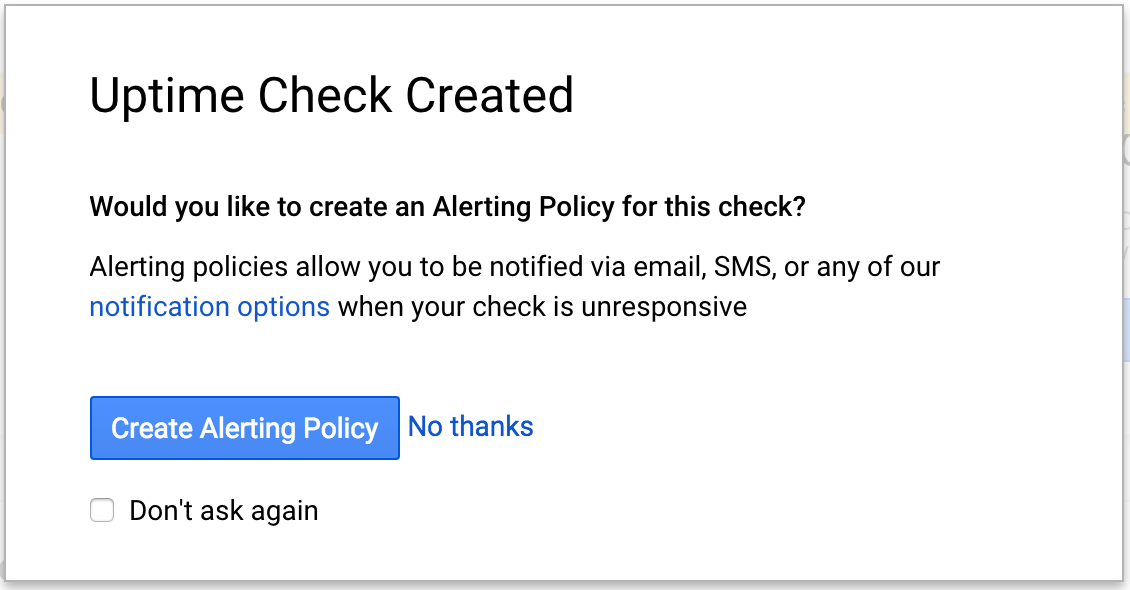
次の画面が表示されます。
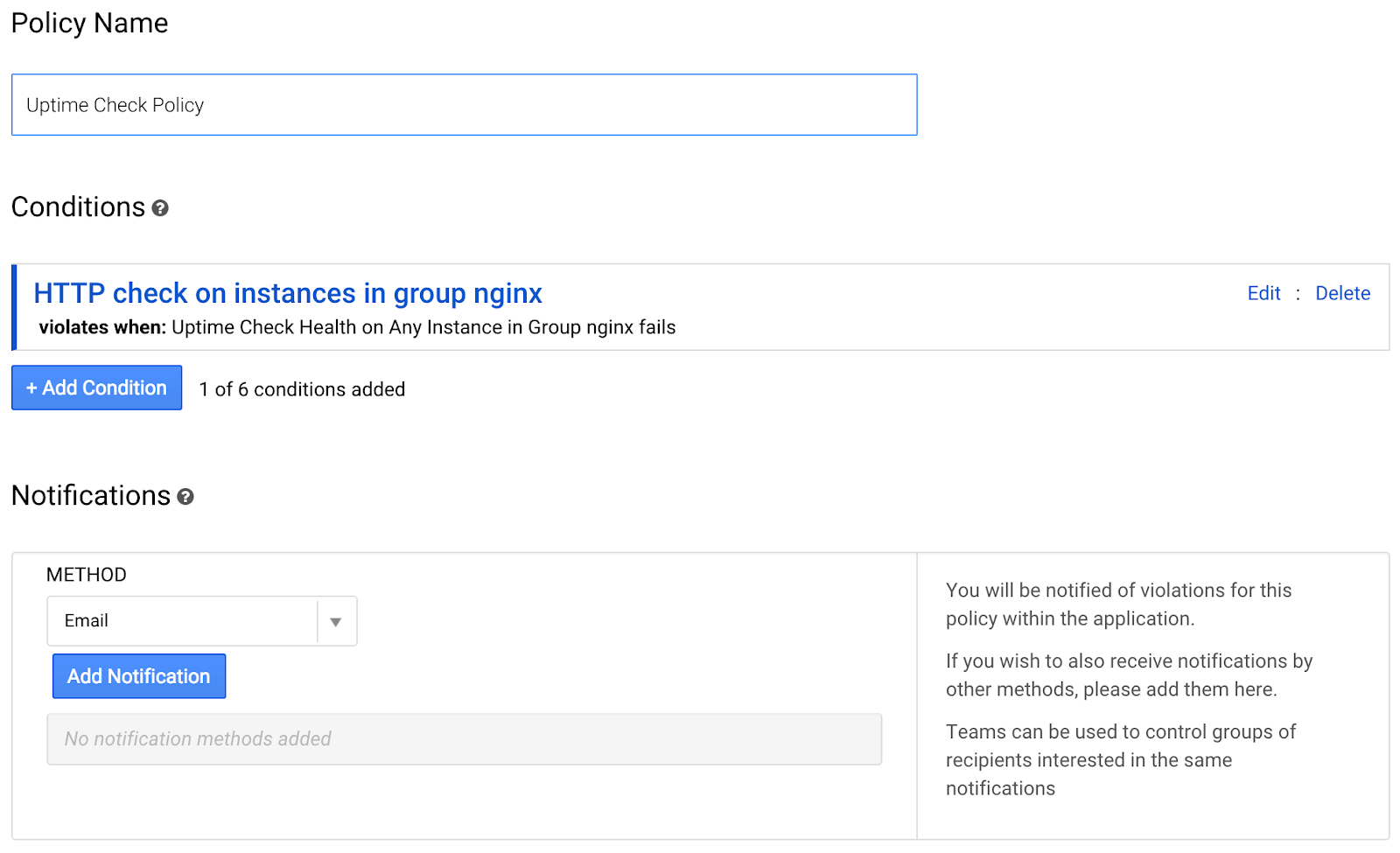
ポリシーの名前(「nginx グループの稼働時間チェック」)を入力します。

[通知方法] セクションで、[通知を追加] をクリックします。
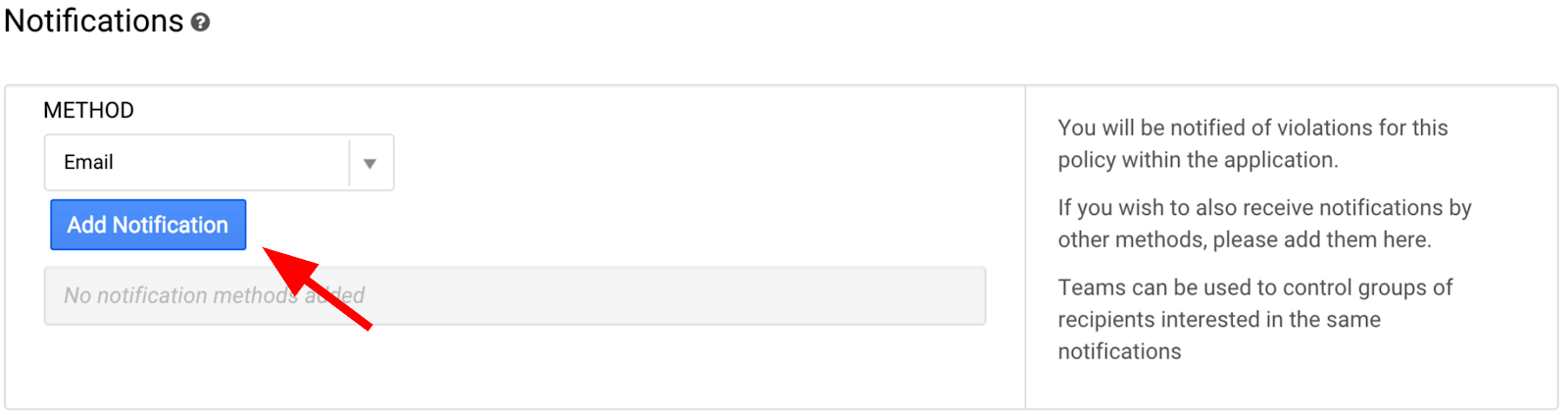
Google Cloud アカウントに関連付けられているメールアドレスを入力します。画面の一番下までスクロールし、[Save Policy](ポリシーを保存)をクリックします。
(左上隅のロゴをクリックして)Stackdriver のホームページに戻ります。
これで、作成した稼働時間チェックがダッシュボードの [稼働時間チェック] セクションに表示されます。現時点ではステータスは緑色です。
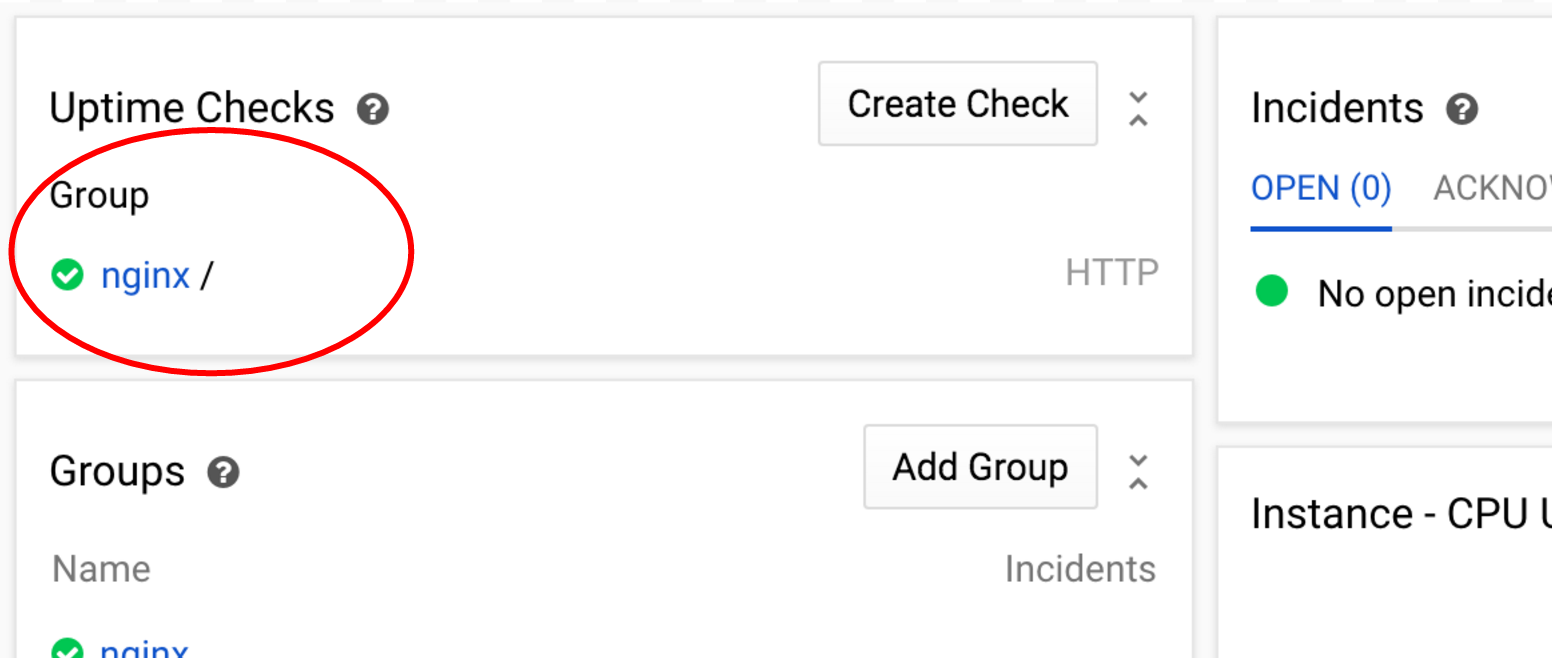
イベントログまでスクロールすると、アラート ポリシーが作成されたイベントが表示されます。
では、問題を作成してみましょう。
Nginx サービスを停止するとどうなるか見てみましょう。
Cloud Shell コマンドラインからインスタンスに再度 SSH 接続します。
$ gcloud compute ssh nginx-plus-1
次のように入力します。
yourusername@nginx-plus-1:~$ sudo service nginx stop
作成した稼働時間チェックが失敗します。その結果、インシデントが作成され、上記で入力したアドレスにアラート通知メールが送信されます。条件が検出されるまでに 1 分かかります(稼働時間チェックの設定時に 1 分の期間を設定したことを思い出してください)。nginx グループのページを確認しましょう。
特定のリソース グループのダッシュボードに移動するには、いくつかの方法があります。
- ホームページでグループの名前をクリックします。これにより、グループのリソースのモニタリング専用に構築されたダッシュボードに切り替わります。このダッシュボードをカスタマイズすることもできます。
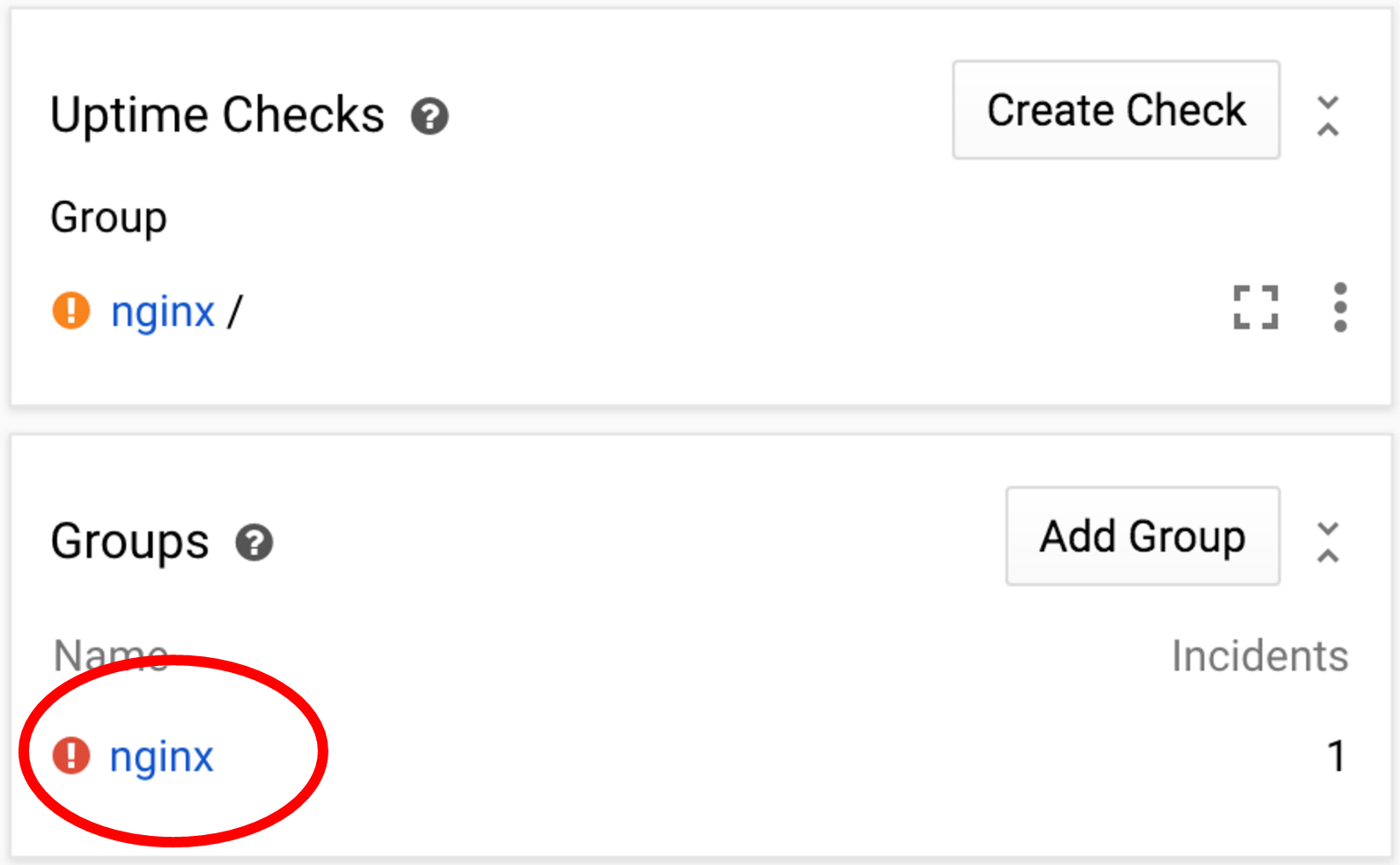
- 最上位のメニューから [グループ] を選択し、特定のグループを見つけます。
次に、自動更新ボタンをクリックして、ダッシュボードが自動的に更新されるようにします。アイコンが赤色に変わります。

自動作成された nginx グループに固有のダッシュボードが表示されます。右側には、グループに関連するいくつかの重要な指標のグラフが表示されます。つまり、これらのグラフには、nginx グループ内のすべてのリソース(前に作成した 3 つの nginx+ VM)に関連する指標が表示されます。
左側には、グループに関するさまざまな情報が表示されます。
- インシデントのステータス
- 稼働時間チェック
- イベントログ
- リソース(インスタンス、ボリュームなど)のリスト
これらはグループにのみ関連するため、イベントログにはグループのイベントのみが一覧表示されます。
さまざまなリソースやサブグループをクリックして、それぞれ専用のダッシュボードに移動できます。たとえば、nginx-plus-1 をクリックすると、そのインスタンスに関連する指標とチェックのみで構成されたダッシュボードが表示されます。今すぐ試す:
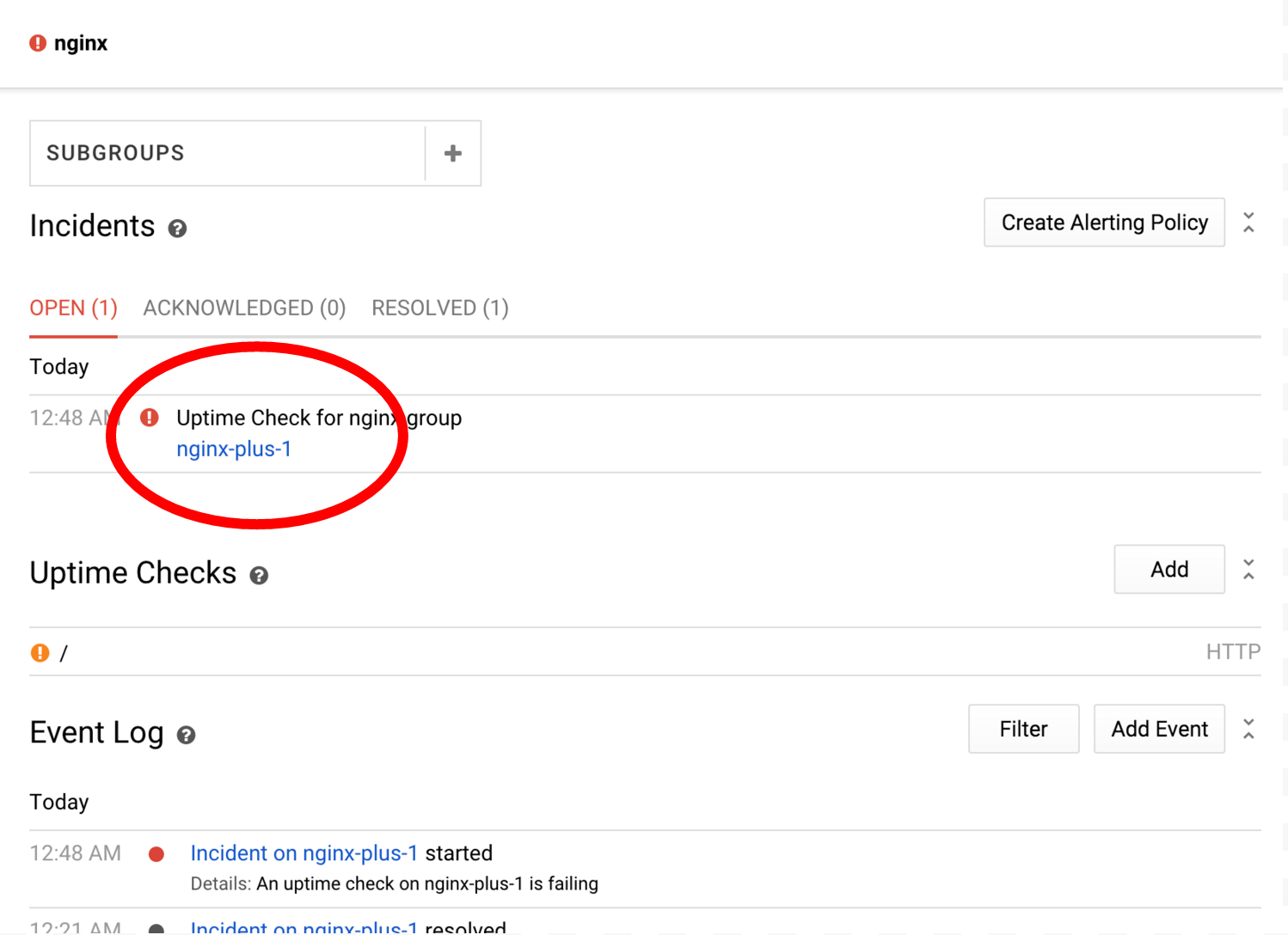
Stackdriver インシデントは、一連のアラート条件が特定の条件を満たしたときに開かれます。この例では、nginx の稼働時間チェックのアラートを設定しています。このアラートは現在 nginx-plus-1 で失敗しています。インシデントを使用すると、現在の状況を追跡し、問題の解決に取り組む際に他のチームメンバーと連携できます。
インシデントを認識し、調査中であることを他のチームメンバーに知らせましょう。
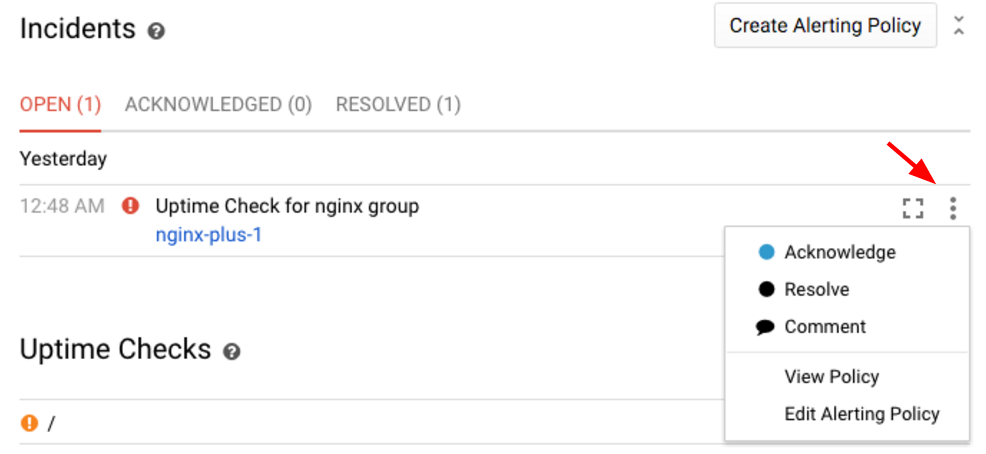
これにより、インシデントの状態が [Open] から [Acknowledged] に変わります。状況はまだ進行中(アラート ポリシーの条件がまだ違反している)ですが、チームメンバーに状況を把握していることを知らせます。この操作はイベントログにも記録されます。
インシデントは手動で解決することも、自動で解決することもできます。後者を確認するには、nginx-plus-1 に SSH 接続して問題を修正します。
yourusername@nginx-plus-1:~$ sudo service nginx start
これで、稼働時間チェックが正常に戻ると、インシデントは自動的に解決されます。[解決] メニュー項目を選択して、ご自身で解決することもできます。
Cloud Logging は、複数のソースからのログを表示してクエリを実行できる便利な一元的な場所を提供するロギング サービス ソリューションです。ログを使用して、他の宛先(Google Cloud Storage、Google BigQuery、Google Cloud Pub/Sub)にエクスポートすることもできます。
Cloud ログビューアにアクセスするには、Cloud Console の左側のメニューから選択します。
ログビューアに移動します。ここでは、事前定義されたクエリを使用したり、独自のカスタムクエリを作成して保存したり、クラウド デプロイ全体で複数のリソースから送信されるログのライブ ストリームを取得したり、ログから指標を作成したり、エクスポートしたりできます。
関連情報をすばやく絞り込むための便利なコントロールがいくつかあります。
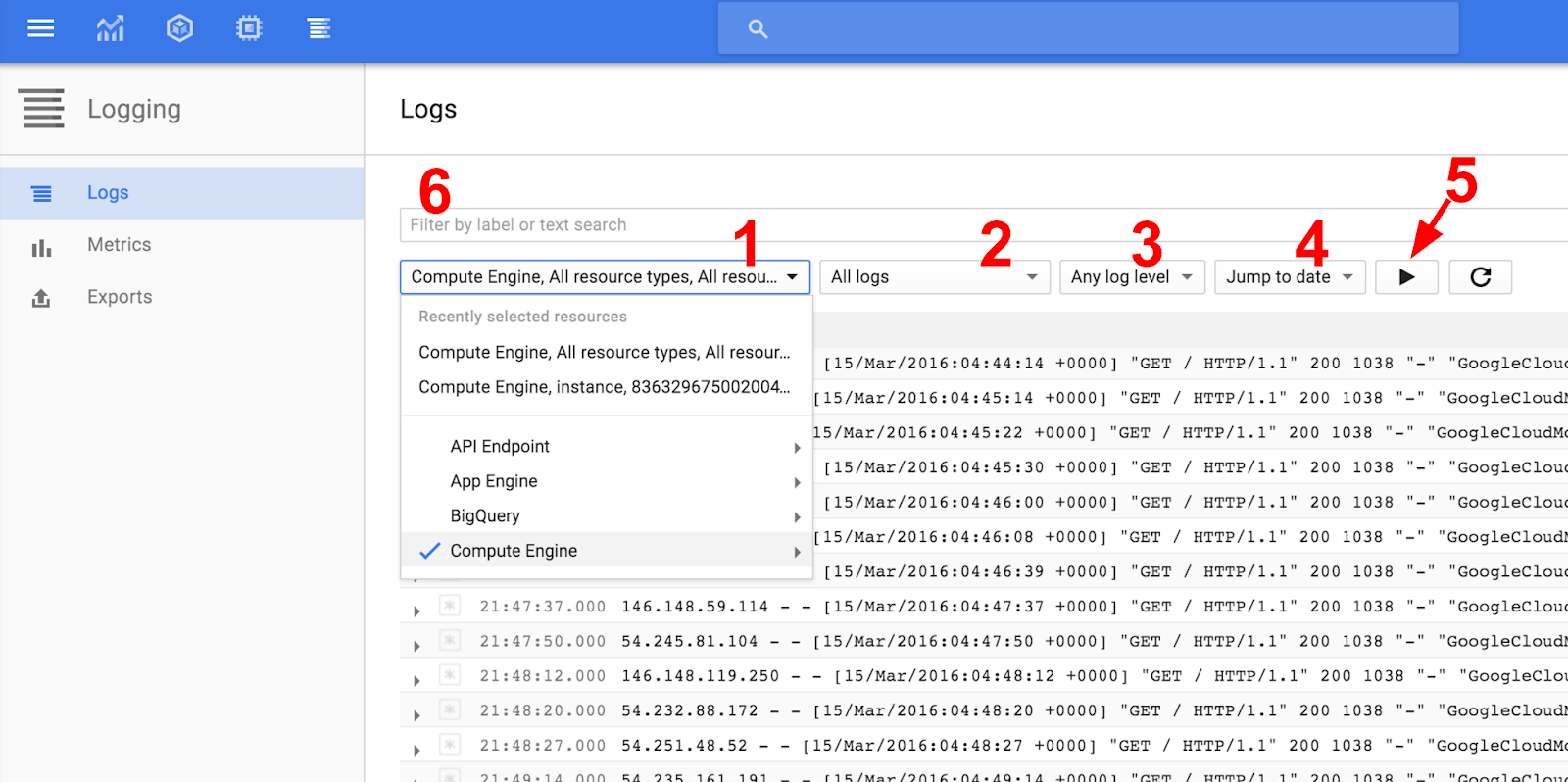
- リソースタイプでフィルタする
- 選択したリソースの特定のログタイプにフィルタする
- 特定のログレベルをフィルタする
- 過去の問題を調べるために特定の日付でフィルタする
- 連続ストリーミングを切り替える
- テキスト、ラベル、正規表現を検索するための検索ボックス
特定のログに絞り込む練習をしましょう。
リソースタイプ セレクタ(スクリーンショットの 1)から、[Compute Engine] -> [すべてのリソースタイプ] を選択します。
次に、ログタイプ セレクタ(スクリーンショットの 2)から nginx-access を選択して、すべてのアクセスログを表示します。
次に、継続的ストリーミング(5)をオンにして、ログが届くのを確認します。新しいログが表示されない場合は、ブラウザに nginx-plus VM のいずれかの外部 IP アドレスを入力してみてください。
この Codelab ではログに重点を置いていませんが、後でクリーンアップする前に自由に確認してください。ビューアの操作について詳しくは、こちらをご覧ください。Cloud Logging の用途に関する詳細については、関連ドキュメントの最上位ディレクトリをご覧ください。こちら
Codelab で作成したコンピューティング リソースをリリースしましょう。Cloud Shell で以下のコマンドを実行します。
$ for i in {1..3}; do \
gcloud -q --user-output-enabled=false compute instances delete nginx-plus-$i ; done次に、Google Stackdriver コンソール(Cloud Console の左側のペインのメニューから [モニタリング])に移動し、作成した稼働時間チェックとアラート ポリシーを削除します。これを行うには、トップレベルのメニュー項目 [Alerting] -> [Policies overview] と [Alerting] -> [Uptime checks] を使用します。
これで、クラウド対応アプリケーションをモニタリングする準備が整いました。
学習した内容
- Stackdriver のホームページについて理解する。
- ダッシュボードとグラフについて。
- 稼働時間チェックの作成。
- シンプルなアラート ポリシーを作成する。
- アラート インシデントの操作。
- ログビューアの操作。
次のステップ
- カスタム ダッシュボードを作成してみましょう。
- アラート ポリシーを作成する際のさまざまなオプションを確認する。
- Cloud Logging を使用する際に利用できるさまざまなオプションを確認する。
詳細
- モニタリング API の使用方法について学習する。
- カスタム指標を使用します。
フィードバックをお寄せください
- 簡単なアンケートにご協力ください