
API Cloud Natural Language позволяет извлекать сущности из текста, выполнять анализ тональности и синтаксиса, а также классифицировать текст по категориям.
В этой лабораторной работе мы научимся использовать API естественного языка для анализа сущностей, настроений и синтаксиса.
Чему вы научитесь
- Создание запроса API естественного языка и вызов API с помощью curl
- Извлечение сущностей и анализ настроений в тексте с помощью API естественного языка
- Выполнение лингвистического анализа текста с помощью API естественного языка
- Создание запроса к API естественного языка на другом языке
Что вам понадобится
Как вы будете использовать это руководство?
Как бы вы оценили свой опыт использования Google Cloud Platform?
Настройка среды для самостоятельного обучения
Если у вас ещё нет учётной записи Google (Gmail или Google Apps), необходимо её создать . Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект:



Запомните идентификатор проекта — уникальное имя для всех проектов Google Cloud (имя, указанное выше, уже занято и не будет вам работать, извините!). Далее в этой практической работе он будет обозначаться как PROJECT_ID .
Далее вам необходимо включить биллинг в Cloud Console, чтобы использовать ресурсы Google Cloud.
Выполнение этой лабораторной работы не должно обойтись вам дороже нескольких долларов, но может обойтись дороже, если вы решите использовать больше ресурсов или оставите их запущенными (см. раздел «Очистка» в конце этого документа).
Новые пользователи Google Cloud Platform имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Нажмите на значок меню в левом верхнем углу экрана.

Выберите API и службы из раскрывающегося списка и нажмите «Панель управления».
Нажмите «Включить API и службы» .
Затем введите «язык» в поле поиска. Нажмите на Google Cloud Natural Language API :
Нажмите «Включить» , чтобы включить API Cloud Natural Language:
Подождите несколько секунд, пока он включится. После включения вы увидите следующее:

Google Cloud Shell — это среда командной строки, работающая в облаке . Эта виртуальная машина на базе Debian оснащена всеми необходимыми инструментами разработки ( gcloud , bq , git и другими) и предлагает постоянный домашний каталог объёмом 5 ГБ. Мы будем использовать Cloud Shell для создания запроса к API естественного языка.
Чтобы начать работу с Cloud Shell, нажмите «Активировать Google Cloud Shell».  значок в правом верхнем углу панели заголовка
значок в правом верхнем углу панели заголовка

Сеанс Cloud Shell откроется в новом фрейме в нижней части консоли и отобразит приглашение командной строки. Дождитесь появления приглашения user@project:~$.
Поскольку мы будем использовать curl для отправки запроса к API естественного языка, нам потребуется сгенерировать ключ API для передачи URL-адреса запроса. Чтобы создать ключ API, перейдите в раздел «Учётные данные» в разделе API и сервисы в консоли Cloud:
В выпадающем меню выберите API-ключ :
Затем скопируйте только что сгенерированный ключ. Он понадобится вам позже в лабораторной работе.
Теперь, когда у вас есть ключ API, сохраните его в переменной окружения, чтобы не вставлять значение ключа API в каждый запрос. Это можно сделать в Cloud Shell. Не забудьте заменить <your_api_key> на только что скопированный вами ключ.
export API_KEY=<YOUR_API_KEY> Первый метод API естественного языка, который мы будем использовать, — это analyzeEntities . С помощью этого метода API может извлекать сущности (например, людей, места и события) из текста. Чтобы опробовать анализ сущностей API, мы используем следующее предложение:
Джоан Роулинг, пишущая под псевдонимами Дж. К. Роулинг и Роберт Гэлбрейт, — британская писательница и сценарист, автор серии фэнтези о Гарри Поттере.
Мы создадим наш запрос к API естественного языка в файле request.json . В вашей среде Cloud Shell создайте файл request.json с кодом ниже. Вы можете создать файл в одном из предпочитаемых вами редакторов командной строки (nano, vim, emacs) или использовать встроенный редактор Orion в Cloud Shell:
запрос.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
} В запросе мы сообщаем API естественного языка о тексте, который будем отправлять. Поддерживаемые типы данных: PLAIN_TEXT или HTML . В поле content мы передаем отправляемый текст API естественного языка для анализа. API естественного языка также поддерживает отправку файлов, хранящихся в облачном хранилище, для обработки текста. Если бы мы хотели отправить файл из облачного хранилища, мы бы заменили content на gcsContentUri и передали бы ему значение URI нашего текстового файла в облачном хранилище. encodingType сообщает API, какой тип кодировки текста использовать при обработке текста. API будет использовать это значение для вычисления того, где в тексте встречаются конкретные сущности.
Теперь вы можете передать тело запроса вместе с переменной среды ключа API, которую вы сохранили ранее, в API естественного языка с помощью следующей команды curl (все в одной командной строке):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonНачало вашего ответа должно выглядеть следующим образом:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
} Для каждой сущности в ответе мы получаем type сущности, связанный URL-адрес Википедии (если таковой имеется), salience ) и индексы, указывающие на то, где эта сущность встречается в тексте. Значимость — это число в диапазоне [0,1], которое указывает на центральное положение сущности по отношению к тексту в целом. API естественного языка также может распознавать одну и ту же сущность, упомянутую разными способами. Взгляните на список mentions в ответе: API может определить, что «Джоан Роулинг», «Роулинг», «романист» и «Роберт Гэлбриат» указывают на одно и то же.
Помимо извлечения сущностей, API естественного языка также позволяет анализировать тональность текста. Наш JSON-запрос будет включать те же параметры, что и предыдущий запрос, но на этот раз мы изменим текст, добавив что-то с более выраженной тональностью. Замените файл request.json следующим текстом, а content ниже можете заменить своим собственным:
запрос.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
} Далее мы отправим запрос в конечную точку API analyzeSentiment :
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Ваш ответ должен выглядеть так:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
} Обратите внимание, что мы получаем два типа значений тональности: тональность всего документа и тональность, разбитую по предложениям. Метод тональности возвращает два значения: score и magnitude . score — это число от -1,0 до 1,0, указывающее на то, насколько утверждение положительно или отрицательно. magnitude — это число от 0 до бесконечности, которое представляет вес тональности, выраженной в утверждении, независимо от того, положительно оно или отрицательно. Более длинные фрагменты текста с сильно выраженными утверждениями имеют более высокие значения величины. Оценка для нашего первого предложения положительная (0,7), тогда как оценка для второго предложения нейтральная (0,1).
Помимо предоставления информации о тональности всего текстового документа, который мы отправляем в API NL, он также может анализировать тональность по сущностям в тексте. Рассмотрим это предложение в качестве примера:
Мне понравились суши, но обслуживание было ужасным .
В этом случае получение оценки тональности для всего предложения, как мы сделали выше, может быть не столь полезным. Если бы это был обзор ресторана, и на один и тот же ресторан были бы сотни отзывов, нам бы хотелось точно знать, что людям понравилось, а что нет. К счастью, в API NL есть метод, позволяющий получить оценку тональности для каждой сущности в тексте, называемый analyzeEntitySentiment . Добавьте в файл request.json указанное выше предложение, чтобы проверить это:
запрос.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
} Затем вызовите конечную точку analyzeEntitySentiment с помощью следующей команды curl:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
В ответе мы получаем два объекта сущности: один для «суши» и один для «услуги». Вот полный ответ в формате JSON:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
Видим, что для слова «суши» возвращена оценка 0,9, тогда как для слова «сервис» — -0,9. Отлично! Вы также можете заметить, что для каждой сущности возвращаются два объекта тональности. Если бы любой из этих терминов упоминался более одного раза, API возвращал бы разные оценки тональности и её величину для каждого упоминания, а также общую тональность для сущности.
Рассмотрев третий метод API естественного языка — синтаксическую аннотацию — мы подробнее изучим лингвистические детали нашего текста. Метод analyzeSyntax предоставляет полную информацию о семантических и синтаксических элементах текста. Для каждого слова в тексте API укажет часть речи (существительное, глагол, прилагательное и т. д.) и его связь с другими словами в предложении (это корень глагола? Определитель?).
Давайте попробуем это на простом предложении. Наш JSON-запрос будет похож на приведённые выше, но с добавлением ключа функций. Это сообщит API, что мы хотим выполнить синтаксическую аннотацию. Замените ваш request.json следующим:
запрос.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Затем вызовите метод analyzeSyntax API:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonОтвет должен возвращать объект, подобный приведённому ниже, для каждого токена в предложении. Рассмотрим ответ для слова «uses»:
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Давайте разберём ответ. partOfSpeech предоставляет нам лингвистическую информацию о каждом слове (многие неизвестны, поскольку не относятся к английскому языку или конкретному слову). tag определяет часть речи этого слова, в данном случае глагол. Мы также получаем информацию о времени, модальности и о том, стоит ли слово в единственном или множественном числе. lemma — каноническая форма слова (для «uses» это «use»). Например, слова run , runs , ran и running имеют лемму run . Значение леммы полезно для отслеживания встречаемости слова в большом тексте с течением времени.
dependencyEdge содержит данные, которые можно использовать для создания дерева анализа зависимостей текста. Это диаграмма, показывающая взаимосвязь слов в предложении. Дерево анализа зависимостей для приведенного выше предложения будет выглядеть следующим образом:
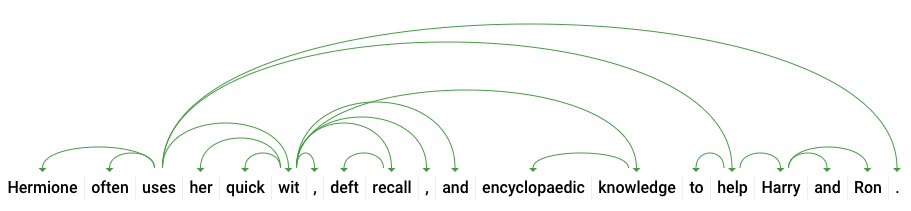
headTokenIndex в нашем ответе выше — это индекс токена, дуга которого указывает на «uses». Каждый токен в предложении можно представить как слово в массиве, а headTokenIndex равный 2 для «uses», относится к слову «often», с которым он связан в дереве.
API естественного языка также поддерживает другие языки, помимо английского (полный список здесь ). Давайте попробуем следующий запрос сущности с предложением на японском языке:
запрос.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}Обратите внимание, что мы не указали API язык текста — он может определить его автоматически. Далее мы отправим его в конечную точку analyzeEntities :
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonИ вот первые два объекта в нашем ответе:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}API извлекает Японию как местоположение и Google как организацию, а также страницы Википедии для каждого из них.
Вы узнали, как выполнять анализ текста с помощью API Cloud Natural Language, извлекая сущности, анализируя тональность и выполняя синтаксическую аннотацию.
Что мы рассмотрели
- Создание запроса API естественного языка и вызов API с помощью curl
- Извлечение сущностей и анализ настроений в тексте с помощью API естественного языка
- Выполнение лингвистического анализа текста для создания деревьев анализа зависимостей
- Создание запроса API естественного языка на японском языке
Следующие шаги
- Ознакомьтесь с учебными пособиями по API естественного языка в документации.
- Попробуйте Vision API и Speech API !