
Cloud Natural Language API を使用すると、テキストからエンティティを抽出して感情分析や構文解析を行い、テキストをカテゴリに分類できます。
このラボでは、Natural Language API を使ってエンティティ、感情、構文を分析する方法について学びます。
学習内容
- Natural Language API リクエストを作成し、curl で API を呼び出す
- Natural Language API でテキストのエンティティ抽出と感情分析を行う
- Natural Language API でテキストを言語学的に分析する
- 別の言語のテキストを使って Natural Language API リクエストを作成する
必要なもの
このチュートリアルをどのように使用されますか?
Google Cloud Platform のご利用経験について、いずれに該当されますか?
セルフペース型の環境設定
Google アカウント(Gmail または Google Apps)をお持ちでない場合は、1 つ作成する必要があります。Google Cloud Platform のコンソール(console.cloud.google.com)にログインし、新しいプロジェクトを作成します。



プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、このコードラボでは PROJECT_ID と呼びます。
次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
この Codelab の操作をすべて行っても、費用は数ドル程度です。ただし、その他のリソースを使いたい場合や、実行したままにしておきたいステップがある場合は、追加コストがかかる可能性があります(このドキュメントの最後にある「クリーンアップ」セクションをご覧ください)。
Google Cloud Platform の新規ユーザーは、300 ドル分の無料トライアルをご利用いただけます。
画面の左上にあるメニュー アイコンをクリックします。

プルダウンから [API とサービス] を選択し、[ダッシュボード] をクリックします。
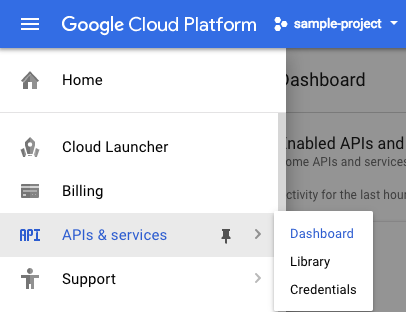
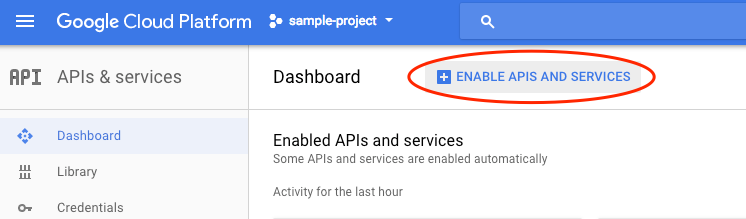
[API とサービスを有効化] をクリックします。
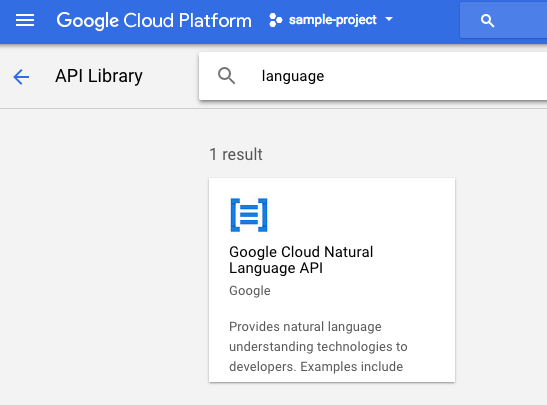
検索ボックスで「language」を検索します。[Google Cloud Natural Language API] をクリックします。
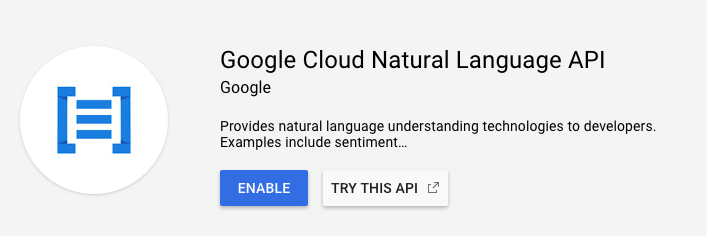
[有効にする] をクリックして、Cloud Natural Language API を有効にします。
有効になるまで数秒待ちます。有効にすると、次のように表示されます。

Google Cloud Shell は、 Cloud 上で動作するコマンドライン環境です。この Debian ベースの仮想マシンには、必要な開発ツール(gcloud、bq、git など)がすべて用意され、永続的な 5 GB のホーム ディレクトリが提供されています。Cloud Shell を使用して Natural Language API へのリクエストを作成します。
Cloud Shell を始めるには、ヘッダーバーの右上にある [Google Cloud Shell をアクティブにする]  アイコンをクリックします。
アイコンをクリックします。

コンソールの下部の新しいフレーム内で Cloud Shell セッションが開き、コマンドライン プロンプトが表示されます。user@project:~$ プロンプトが表示されるまで待ちます。
ここでは curl を使用して Natural Language API にリクエストを送信するため、リクエスト URL で渡す API キーを生成する必要があります。API キーを作成するには、Cloud コンソールの [API とサービス] の [認証情報] セクションに移動します。
プルダウン メニューで [API キー] を選択します。
生成された API キーをコピーし、このキーは後ほどラボで必要になります。
これで API キーができました。各リクエストに API キーの値を挿入せずに済むように、環境変数に API キーを保存します。環境変数にキーを保存するには、Cloud Shell で次のように入力します。<your_api_key> の部分は、コピーしたキーに置き換えてください。
export API_KEY=<YOUR_API_KEY>最初に使用する Natural Language API メソッドは analyzeEntities です。このメソッドを使用すると、API によってテキストからエンティティ(人、場所、イベントなど)が抽出されます。ここでは、次の文を使って Natural Language API のエンティティ分析を試してみます。
Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series.
Natural Language API へのリクエストは、request.json ファイルで構築します。Cloud Shell で次のコードを入力し、request.json ファイルを作成します。Cloud Shell の組み込み Orion エディタ以外のコマンドライン エディタ(nano、vim、emacs)を使用してもかまいません。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}このリクエストでは、送信するテキストについての情報を Natural Language API に知らせます。サポートされている型の値は PLAIN_TEXT または HTML です。content には、分析のために Natural Language API に送信するテキストを指定します。Natural Language API では、Cloud Storage に保存されているファイルをテキスト処理用に送信することもできます。Cloud Storage からファイルを送信する場合は、content を gcsContentUri に置き換えて、Cloud Storage に保存されているテキスト ファイルの URI の値を指定します。encodingType は、テキストを処理するときに使用するテキスト エンコードの種類を API に指示します。API はこの情報を使って、特定のエンティティがテキストのどこに出現するかを調べます。
次の curl コマンドを実行して、リクエストの本文を、先ほど保存した API キー環境変数とともに Natural Language API に渡します(コマンドは 1 行で入力してください)。
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonレスポンスの最初の部分は次のようになります。
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}このレスポンスには、各エンティティの type、ウィキペディアの関連ページの URL(存在する場合)、salience、テキスト内の場所を示すインデックスが含まれています。salience(顕著性)は、[0,1] の範囲の数値です。これは、そのエンティティがテキスト全体でどの程度重要かを表します。Natural Language API では、同じエンティティの別の表現も認識されます。レスポンスの mentions のリストをご覧ください。「Joanne Rowling」、「Rowling」、「novelist」、「Robert Galbriath」がすべて同じものを指していることが API で認識されています。
Natural Language API では、エンティティの抽出に加えて、テキスト ブロックの感情分析を行うこともできます。次の JSON リクエストに含まれているパラメータは先ほどのリクエストと同じですが、今回は分析するテキストをより強い感情を含むものに変更します。request.json ファイルの内容を次のように置き換えます。content の部分は独自のテキストに置き換えてもかまいません。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}次に、このリクエストを API の analyzeSentiment エンドポイントに送信します。
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
レスポンスは次のようになります。
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}sentiment の値が 2 種類あることに注目してください。これは、ドキュメント全体の値と文単位の値です。sentiment メソッドは score と magnitude の 2 つの値を返します。score は、-1.0 ~ 1.0 の数値です。その主張がどのくらいポジティブまたはネガティブかを示します。magnitude は、0 ~無限大の数値です。その主張の中で表現されている感情の重みを表します。感情がポジティブかネガティブかは問いません。重みの大きい主張を含むテキスト ブロックが長くなるほど magnitude の値が大きくなります。この例では、1 つ目の文の score はポジティブ(0.7)ですが、2 つ目の文の score はニュートラル(0.1)です。
NL API に送信するテキスト ドキュメント全体の感情だけでなく、テキスト内のエンティティごとの感情を調べることもできます。次の文を例として使用します。
I liked the sushi but the service was terrible.
この場合、先ほどのように文全体の感情スコアを取得してもあまり役に立ちません。これがレストランのレビューで、同じレストランのレビューが何百件もあった場合、求められる情報は、それらのレビューで何が気に入られていて、何が気に入られていないかです。幸いなことに、NL API には、テキスト内の各エンティティに対する感情を調べることができる analyzeEntitySentiment というメソッドが用意されています。上の文で request.json を更新して試してみましょう。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}次に、次の curl コマンドを使用して analyzeEntitySentiment エンドポイントを呼び出します。
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
レスポンスには 2 つのエンティティ オブジェクトが含まれています。1 つは「sushi」、もう 1 つは「service」です。完全な JSON レスポンスは次のとおりです。
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
「sushi」の score は 0.9 ですが、「service」の score は -0.9 になっています。分析がうまくいったようです。また、sentiment オブジェクトがエンティティごとに 2 つ返されていますが、これは特定の出現箇所の値と、エンティティ全体の集計値を表しています。これらの言葉が複数回出てきた場合は、それぞれに別の score と magnitude の値が返されます。
Natural Language API の 3 つ目のメソッドは、構文アノテーションです。このメソッドでは、言語学的な観点からテキストをさらに詳しく調べることができます。analyzeSyntax は、テキストのすべての意味要素と構文要素の詳細を提示するメソッドです。テキスト内の各単語について、その単語の品詞(名詞、動詞、形容詞など)と、文中の他の単語との関係(主動詞か修飾語かなど)を調べることができます。
簡単な文で試してみましょう。次の JSON リクエストは、先ほどのものとよく似ていますが、features キーが追加されています。これにより、構文アノテーションを行うことが API に伝えられます。request.json を次の内容に置き換えます。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}次に、API の analyzeSyntax メソッドを呼び出します。
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonレスポンスでは、次のようなオブジェクトが文中のトークンごとに返されます。ここでは、「uses」という単語のレスポンスを見てみましょう。
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}レスポンスを細かく見てみましょう。partOfSpeech は各単語の言語的な詳細を提供します(英語やこの特定の単語には適用されないため、多くは不明です)。tag は、この単語の品詞(この場合は動詞)を示します。また、時制、様相、単数形か複数形かなどの詳細も取得できます。lemma は単語の正規形です(「uses」の場合は「use」)。たとえば、run、runs、ran、running の lemma はすべて run です。lemma の値は、大きなテキスト ブロックで単語の出現回数の推移を追跡するのに便利です。
dependencyEdge には、このテキストの係り受け解析ツリーを作成するためのデータが含まれています。係り受け解析ツリーとは、文中の単語が互いにどのように関連しているかを示す図です。たとえば、上の文の係り受け解析ツリーは次のようになります。
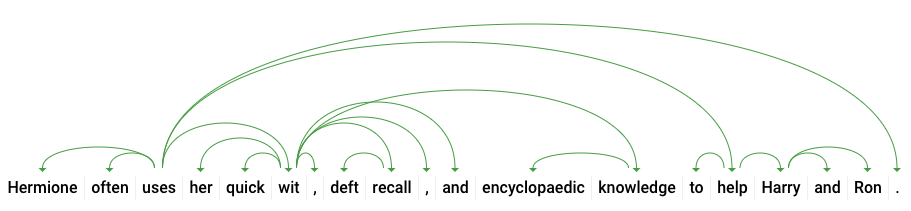
上記のレスポンスの headTokenIndex は、「uses」に向かう曲線を持つトークンのインデックスです。文中の各トークンは、配列内の単語と考えることができます。「uses」の headTokenIndex が 2 の場合、ツリー内で接続されている「often」という単語を指します。
Natural Language API は英語以外の言語もサポートしています(すべての言語のリストについてはこちらをご覧ください)。次のエンティティ リクエストを日本語の文で試してみましょう。
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}テキストの言語を指定していないことに注目してください。言語は API によって自動的に検出されます。次に、これを analyzeEntities エンドポイントに送信します。
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonレスポンスの最初の 2 つのエンティティは次のとおりです。
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}API は、場所として「日本」、組織として「Google」を抽出し、それぞれに対応する Wikipedia ページも抽出します。
ここでは、Cloud Natural Language API によるテキスト分析の方法を学ぶために、エンティティ抽出、感情分析、構文アノテーションを行いました。
学習した内容
- Natural Language API リクエストを作成し、curl で API を呼び出す
- Natural Language API でテキストのエンティティ抽出と感情分析を行う
- テキストを言語学的に分析して係り受け解析ツリーを作成する
- 日本語のテキストを使って Natural Language API リクエストを作成する
次のステップ
- Natural Language API のチュートリアル ドキュメントを確認する
- Vision API と Speech API をお試しください。