
Dengan Cloud Natural Language API, Anda dapat mengekstrak entity dari teks, melakukan analisis sentimen dan sintaksis, serta mengklasifikasikan teks ke dalam beberapa kategori.
Dalam lab ini, kita akan mempelajari cara menggunakan Natural Language API untuk menganalisis entity, sentimen, dan sintaks.
Yang akan Anda pelajari
- Membuat permintaan Natural Language API dan memanggil API menggunakan curl
- Mengekstrak entity dan menjalankan analisis sentimen pada teks menggunakan Natural Language API
- Melakukan analisis linguistik pada teks menggunakan Natural Language API
- Membuat permintaan Natural Language API dalam bahasa lain
Yang akan Anda butuhkan
Bagaimana Anda akan menggunakan tutorial ini?
Bagaimana penilaian Anda terhadap pengalaman dengan Google Cloud Platform?
Penyiapan lingkungan mandiri
Jika belum memiliki Akun Google (Gmail atau Google Apps), Anda harus membuatnya. Login ke Google Cloud Platform console (console.cloud.google.com) dan buat project baru:



Ingat project ID, nama unik di semua project Google Cloud (maaf, nama di atas telah digunakan dan tidak akan berfungsi untuk Anda!) Project ID tersebut selanjutnya akan dirujuk di codelab ini sebagai PROJECT_ID.
Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource Google Cloud.
Menjalankan melalui codelab ini tidak akan menghabiskan biaya lebih dari beberapa dolar, tetapi bisa lebih jika Anda memutuskan untuk menggunakan lebih banyak resource atau jika Anda membiarkannya berjalan (lihat bagian "pembersihan" di akhir dokumen ini).
Pengguna baru Google Cloud Platform memenuhi syarat untuk mendapatkan uji coba gratis senilai$300.
Klik ikon menu di kiri atas layar.

Pilih APIs & services dari drop-down, lalu klik Dashboard
Klik Enable APIs and services.
Kemudian, telusuri "bahasa" di kotak penelusuran. Klik Google Cloud Natural Language API:
Klik Enable untuk mengaktifkan Cloud Natural Language API:
Tunggu beberapa detik hingga tombol diaktifkan. Anda akan melihat ini setelah diaktifkan:

Google Cloud Shell adalah lingkungan command line yang berjalan di Cloud. Mesin virtual berbasis Debian ini dilengkapi dengan semua alat pengembangan yang akan Anda perlukan (gcloud, bq, git, dan lainnya) serta menawarkan direktori beranda persisten sebesar 5 GB. Kita akan menggunakan Cloud Shell untuk membuat permintaan ke Natural Language API.
Untuk mulai menggunakan Cloud Shell, klik ikon "Activate Google Cloud Shell"  di pojok kanan atas header bar
di pojok kanan atas header bar

Sesi Cloud Shell akan terbuka di dalam frame baru di bagian bawah konsol dan menampilkan perintah command-line. Tunggu hingga perintah user@project:~$ muncul
Karena kita akan menggunakan curl untuk mengirim permintaan ke Natural Language API, kita perlu membuat kunci API untuk meneruskan URL permintaan kita. Untuk membuat kunci API, buka bagian Kredensial di APIs & services di Konsol Cloud Anda:
Pada menu drop-down, pilih Kunci API:
Selanjutnya, salin kunci yang baru saja Anda buat. Anda akan memerlukan kunci ini nanti di lab.
Setelah memiliki kunci API, simpan kunci tersebut ke variabel lingkungan agar Anda tidak perlu memasukkan nilai kunci API Anda dalam setiap permintaan. Anda dapat melakukannya di Cloud Shell. Pastikan untuk mengganti <your_api_key> dengan kunci yang baru saja Anda salin.
export API_KEY=<YOUR_API_KEY>Metode Natural Language API pertama yang akan kita gunakan adalah analyzeEntities. Dengan metode ini, API dapat mengekstrak entity (seperti orang, tempat, dan peristiwa) dari teks. Untuk mencoba analisis entity API tersebut, kita akan menggunakan kalimat ini:
Joanne Rowling, yang berkarya menggunakan nama pena J. K. Rowling dan Robert Galbraith, adalah seorang novelis dan penulis skenario asal Inggris yang menulis seri fantasi Harry Potter.
Kita akan membuat permintaan ke Natural Language API dalam file request.json. Di lingkungan Cloud Shell, buat file request.json dengan kode di bawah. Anda dapat membuat file menggunakan salah satu editor command line pilihan Anda (nano, vim, emacs) atau menggunakan editor Orion bawaan di Cloud Shell:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Joanne Rowling, who writes under the pen names J. K. Rowling and Robert Galbraith, is a British novelist and screenwriter who wrote the Harry Potter fantasy series."
},
"encodingType":"UTF8"
}Dalam permintaan tersebut, kita memberi tahu Natural Language API tentang teks yang akan kita kirim. Nilai jenis yang didukung adalah PLAIN_TEXT atau HTML. Pada konten, kita teruskan teks untuk dikirim ke Natural Language API agar dapat dianalisis. Natural Language API juga mendukung pengiriman file yang disimpan di Cloud Storage untuk pemrosesan teks. Jika ingin mengirim file dari Cloud Storage, kita perlu mengganti content dengan gcsContentUri dan memberinya nilai uri file teks kita di Cloud Storage. encodingType memberi tahu API jenis encoding teks mana yang akan digunakan saat pemrosesan teks dilakukan. API akan menggunakannya untuk memperhitungkan letak munculnya entity tertentu di teks kita.
Kini, Anda dapat meneruskan isi permintaan, termasuk variabel lingkungan kunci API yang sebelumnya sudah disimpan, ke Natural Language API dengan perintah curl berikut (semua dalam satu command line tunggal):
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonBagian awal respons Anda akan terlihat seperti berikut:
{
"entities": [
{
"name": "Robert Galbraith",
"type": "PERSON",
"metadata": {
"mid": "/m/042xh",
"wikipedia_url": "https://en.wikipedia.org/wiki/J._K._Rowling"
},
"salience": 0.7980405,
"mentions": [
{
"text": {
"content": "Joanne Rowling",
"beginOffset": 0
},
"type": "PROPER"
},
{
"text": {
"content": "Rowling",
"beginOffset": 53
},
"type": "PROPER"
},
{
"text": {
"content": "novelist",
"beginOffset": 96
},
"type": "COMMON"
},
{
"text": {
"content": "Robert Galbraith",
"beginOffset": 65
},
"type": "PROPER"
}
]
},
...
]
}Untuk setiap entity dalam respons, akan ditampilkan type entity, URL Wikipedia terkait (jika ada), salience, dan indeks tempat entity akan muncul di dalam teks. Salience adalah angka dalam rentang [0,1] yang merujuk pada sentralitas entity terhadap teks secara keseluruhan. Natural Language API juga mampu mengenali entity yang sama yang disebutkan dalam berbagai cara. Perhatikan daftar mentions dalam respons: API mampu mengenali bahwa "Joanne Rowling", "Rowling", "novelis", dan "Robert Galbraith" merujuk ke hal yang sama.
Di samping mengekstrak entity, Anda juga dapat melakukan analisis sentimen pada sebuah blok teks menggunakan Natural Language API. Permintaan JSON kita akan berisi parameter yang sama seperti permintaan di atas, tetapi kali ini kita akan mengubah teksnya untuk menambahkan hal-hal dengan sentimen yang lebih kuat. Ganti file request.json Anda dengan kode berikut, dan jangan sungkan untuk mengganti content di bawah ini dengan teks Anda sendiri:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"Harry Potter is the best book. I think everyone should read it."
},
"encodingType": "UTF8"
}Selanjutnya, kita akan mengirim permintaan ke endpoint analyzeSentiment API:
curl "https://language.googleapis.com/v1/documents:analyzeSentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Respons yang Anda terima seharusnya seperti ini:
{
"documentSentiment": {
"magnitude": 0.8,
"score": 0.4
},
"language": "en",
"sentences": [
{
"text": {
"content": "Harry Potter is the best book.",
"beginOffset": 0
},
"sentiment": {
"magnitude": 0.7,
"score": 0.7
}
},
{
"text": {
"content": "I think everyone should read it.",
"beginOffset": 31
},
"sentiment": {
"magnitude": 0.1,
"score": 0.1
}
}
]
}Perhatikan bahwa kita mendapatkan dua jenis nilai sentimen: sentimen untuk dokumen secara keseluruhan, dan sentimen yang dipecah per kalimat. Metode sentimen ini menampilkan dua nilai: score dan magnitude. score adalah angka dari -1,0 hingga 1,0 yang menunjukkan seberapa positif atau negatifnya suatu pernyataan. magnitude adalah angka mulai dari 0 hingga tak terhingga yang mewakili bobot sentimen yang dinyatakan dalam pernyataan, terlepas dari apakah sentimen itu positif atau negatif. Blok teks yang lebih panjang dengan penyataan yang lebih berbobot memiliki nilai magnitude yang lebih tinggi. Kalimat pertama mendapatkan skor positif (0.7), sedangkan kalimat kedua mendapatkan skor netral (0.1).
Selain memberikan detail sentimen pada keseluruhan dokumen teks yang kami kirimkan ke NL API, API ini juga dapat memecah sentimen berdasarkan entity dalam teks kami. Mari kita gunakan kalimat ini sebagai contoh:
Saya suka sushinya, tetapi pelayanannya sangat buruk.
Dalam kasus ini, mendapatkan skor sentimen untuk keseluruhan kalimat seperti yang sudah didapat di atas mungkin tidak terlalu berguna. Jika kalimat tersebut merupakan ulasan sebuah restoran dan ternyata sudah ada ratusan ulasan untuk restoran yang sama, sebaiknya kita cari tahu item apa saja yang disukai dan tidak disukai oleh pengunjung dalam ulasannya. Untungnya, NL API memiliki metode yang memungkinkan kita mendapatkan sentimen untuk setiap entity dalam teks, yang disebut analyzeEntitySentiment. Perbarui request.json Anda dengan kalimat di atas untuk mencobanya:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"I liked the sushi but the service was terrible."
},
"encodingType": "UTF8"
}Kemudian, panggil endpoint analyzeEntitySentiment dengan perintah curl berikut:
curl "https://language.googleapis.com/v1/documents:analyzeEntitySentiment?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.json
Dalam respons, kita kembali mendapatkan dua objek entity: satu untuk "sushi" dan satu untuk "pelayanan". Berikut adalah respons lengkap JSON:
{
"entities": [
{
"name": "sushi",
"type": "CONSUMER_GOOD",
"metadata": {},
"salience": 0.52716845,
"mentions": [
{
"text": {
"content": "sushi",
"beginOffset": 12
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": 0.9
}
},
{
"name": "service",
"type": "OTHER",
"metadata": {},
"salience": 0.47283158,
"mentions": [
{
"text": {
"content": "service",
"beginOffset": 26
},
"type": "COMMON",
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"sentiment": {
"magnitude": 0.9,
"score": -0.9
}
}
],
"language": "en"
}
Kita dapat melihat bahwa skor yang diraih oleh "sushi" adalah 0,9, sedangkan "pelayanan" meraih skor sebesar -0,9. Keren! Anda mungkin juga melihat bahwa ada dua objek sentimen yang ditampilkan untuk setiap entity. Jika salah satu dari istilah ini disebutkan lebih dari satu kali, API akan mengembalikan skor dan besaran sentimen yang berbeda untuk setiap penyebutan, berikut keseluruhan sentimen untuk entity tersebut.
Dengan melihat metode ketiga Natural Language API - anotasi sintaks - kita akan mempelajari lebih dalam detail linguistik teks kita. analyzeSyntax adalah metode yang memberikan serangkaian detail lengkap tentang elemen semantik dan sintaksis teks. Untuk setiap kata dalam teks, API akan memberi tahu kita jenis kata (nomina, verba, adjektiva, dll.) dan bagaimana kata tersebut berhubungan dengan kata-kata lain dalam kalimat (Apakah itu merupakan kata kerja dasar? Atau penjelas?).
Mari kita coba dengan kalimat sederhana. Permintaan JSON kita akan mirip dengan permintaan di atas, dengan tambahan berupa kunci fitur. Dengan begini, API akan tahu bahwa kita hendak melakukan anotasi sintaks. Ganti request.json Anda dengan yang berikut:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content": "Hermione often uses her quick wit, deft recall, and encyclopaedic knowledge to help Harry and Ron."
},
"encodingType": "UTF8"
}Kemudian, panggil metode analyzeSyntax API:
curl "https://language.googleapis.com/v1/documents:analyzeSyntax?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonRespons akan menampilkan objek seperti contoh di bawah ini untuk tiap token yang ada dalam kalimat. Di sini kita akan melihat respons untuk kata "menggunakan":
{
"text": {
"content": "uses",
"beginOffset": 15
},
"partOfSpeech": {
"tag": "VERB",
"aspect": "ASPECT_UNKNOWN",
"case": "CASE_UNKNOWN",
"form": "FORM_UNKNOWN",
"gender": "GENDER_UNKNOWN",
"mood": "INDICATIVE",
"number": "SINGULAR",
"person": "THIRD",
"proper": "PROPER_UNKNOWN",
"reciprocity": "RECIPROCITY_UNKNOWN",
"tense": "PRESENT",
"voice": "VOICE_UNKNOWN"
},
"dependencyEdge": {
"headTokenIndex": 2,
"label": "ROOT"
},
"lemma": "use"
}Mari kita uraikan responsnya. partOfSpeech memberi kita detail linguistik pada setiap kata (banyak yang tidak diketahui karena tidak berlaku untuk bahasa Inggris atau kata tertentu ini). tag memberikan kelas kata dari kata ini, dalam hal ini kata kerja. Kita juga mendapatkan detail tentang kala, modalitas, dan apakah kata tersebut tunggal atau jamak. lemma adalah bentuk kanonis dari kata (untuk "menggunakan", bentuk kanonisnya adalah "gunakan"). Misalnya, kata run, runs, ran, dan running semuanya memiliki lema run. Nilai lemma berguna untuk melacak frekuensi penggunaan suatu kata dalam sebuah teks bervolume besar dari waktu ke waktu.
dependencyEdge mencakup data yang dapat Anda gunakan untuk membuat hierarki penguraian dependensi teks. Ini adalah diagram yang menunjukkan bagaimana kata-kata dalam kalimat berkaitan satu dengan lainnya. Hierarki penguraian dependensi untuk kalimat di atas akan terlihat seperti berikut:
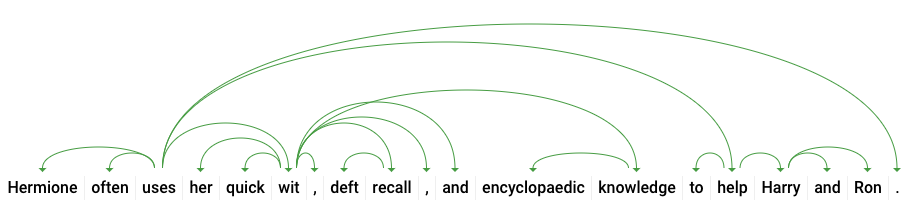
headTokenIndex dalam respons di atas adalah indeks token yang memiliki alur yang mengarah ke "menggunakan". Cukup bayangkan bahwa setiap token dalam kalimat merupakan sebuah kata dalam rangkaian, dan headTokenIndex 2 untuk "menggunakan" merujuk pada kata "sering", yang terhubung ke hierarki.
Natural Language API juga mendukung bahasa lain selain bahasa Inggris (daftar lengkap di sini). Mari kita coba permintaan entity berikut dengan kalimat dalam bahasa Jepang:
request.json
{
"document":{
"type":"PLAIN_TEXT",
"content":"日本のグーグルのオフィスは、東京の六本木ヒルズにあります"
},
"encodingType": "UTF8"
}Perhatikan bahwa kita tidak memberi tahu API tentang bahasa yang digunakan oleh teks kita. API mampu mendeteksinya secara otomatis. Selanjutnya, kita akan mengirimkannya ke endpoint analyzeEntities:
curl "https://language.googleapis.com/v1/documents:analyzeEntities?key=${API_KEY}" \
-s -X POST -H "Content-Type: application/json" --data-binary @request.jsonBerikut adalah dua entitas pertama dalam respons kita:
{
"entities": [
{
"name": "日本",
"type": "LOCATION",
"metadata": {
"mid": "/m/03_3d",
"wikipedia_url": "https://en.wikipedia.org/wiki/Japan"
},
"salience": 0.23854347,
"mentions": [
{
"text": {
"content": "日本",
"beginOffset": 0
},
"type": "PROPER"
}
]
},
{
"name": "グーグル",
"type": "ORGANIZATION",
"metadata": {
"mid": "/m/045c7b",
"wikipedia_url": "https://en.wikipedia.org/wiki/Google"
},
"salience": 0.21155767,
"mentions": [
{
"text": {
"content": "グーグル",
"beginOffset": 9
},
"type": "PROPER"
}
]
},
...
]
"language": "ja"
}API mengekstrak Jepang sebagai lokasi dan Google sebagai organisasi, beserta halaman Wikipedia untuk masing-masing.
Anda telah mempelajari cara melakukan analisis teks menggunakan Cloud Natural Language API dengan cara mengekstrak entity, menganalisis sentimen, dan melakukan anotasi sintaks.
Yang telah kita bahas
- Membuat permintaan Natural Language API dan memanggil API menggunakan curl
- Mengekstrak entity dan menjalankan analisis sentimen pada teks menggunakan Natural Language API
- Melakukan analisis linguistik pada teks untuk membuat hierarki penguraian dependensi
- Membuat permintaan Natural Language API dalam bahasa Jepang
Langkah Berikutnya
- Lihat tutorial Natural Language API dalam dokumentasi.
- Coba Vision API dan Speech API.