
Dataflow adalah model pemrograman terpadu dan layanan terkelola untuk mengembangkan dan menjalankan berbagai pola pemrosesan data, termasuk ETL, komputasi batch, dan komputasi berkelanjutan. Karena merupakan layanan terkelola, Dataflow dapat mengalokasikan resource sesuai permintaan untuk meminimalkan latensi sekaligus mempertahankan efisiensi pemanfaatan yang tinggi.
Model Dataflow menggabungkan pemrosesan batch dan streaming sehingga developer tidak perlu mengorbankan kebenaran, biaya, dan waktu pemrosesan. Dalam codelab ini, Anda akan mempelajari cara menjalankan pipeline Dataflow yang menghitung kemunculan kata unik dalam file teks.
Tutorial ini diadaptasi dari https://cloud.google.com/dataflow/docs/quickstarts/quickstart-java-maven
Yang akan Anda pelajari
- Cara membuat project Maven dengan Cloud Dataflow SDK
- Menjalankan contoh pipeline menggunakan Konsol Google Cloud Platform
- Cara menghapus bucket Cloud Storage terkait dan isinya
Yang Anda butuhkan
Bagaimana Anda akan menggunakan tutorial ini?
Bagaimana penilaian Anda terhadap pengalaman menggunakan layanan Google Cloud Platform?
Penyiapan lingkungan mandiri
Jika belum memiliki Akun Google (Gmail atau Google Apps), Anda harus membuatnya. Login ke Google Cloud Platform console (console.cloud.google.com) dan buat project baru:



Ingat project ID, nama unik di semua project Google Cloud (maaf, nama di atas telah digunakan dan tidak akan berfungsi untuk Anda!) Project ID tersebut selanjutnya akan dirujuk di codelab ini sebagai PROJECT_ID.
Selanjutnya, Anda harus mengaktifkan penagihan di Konsol Cloud untuk menggunakan resource Google Cloud.
Menjalankan melalui codelab ini tidak akan menghabiskan biaya lebih dari beberapa dolar, tetapi bisa lebih jika Anda memutuskan untuk menggunakan lebih banyak resource atau jika Anda membiarkannya berjalan (lihat bagian "pembersihan" di akhir dokumen ini).
Pengguna baru Google Cloud Platform memenuhi syarat untuk mendapatkan uji coba gratis senilai$300.
Aktifkan API
Klik ikon menu di kiri atas layar.

Pilih API Manager dari menu drop-down.

Telusuri "Google Compute Engine" di kotak penelusuran. Klik "Google Compute Engine API" dalam daftar hasil yang muncul.
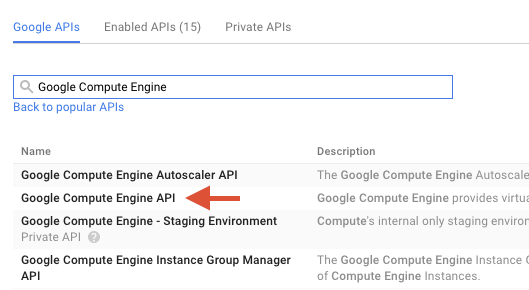
Di halaman Google Compute Engine, klik Enable
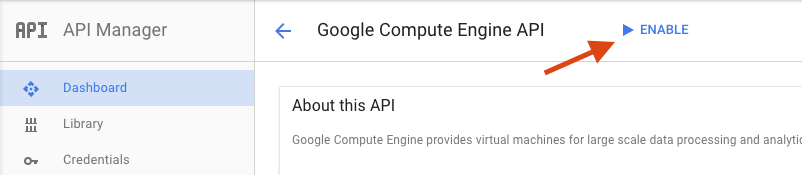
Setelah diaktifkan, klik panah untuk kembali.
Sekarang telusuri API berikut dan aktifkan juga:
- Google Dataflow API
- Stackdriver Logging API
- Google Cloud Storage
- Google Cloud Storage JSON API
- BigQuery API
- Google Cloud Pub/Sub API
- Google Cloud Datastore API
Di Konsol Google Cloud Platform, klik ikon Menu di kiri atas layar:
Scroll ke bawah, lalu pilih Cloud Storage di subbagian Storage:
Sekarang Anda akan melihat Browser Cloud Storage, dan jika Anda menggunakan project yang saat ini tidak memiliki bucket Cloud Storage, Anda akan melihat kotak dialog yang meminta Anda membuat bucket baru:
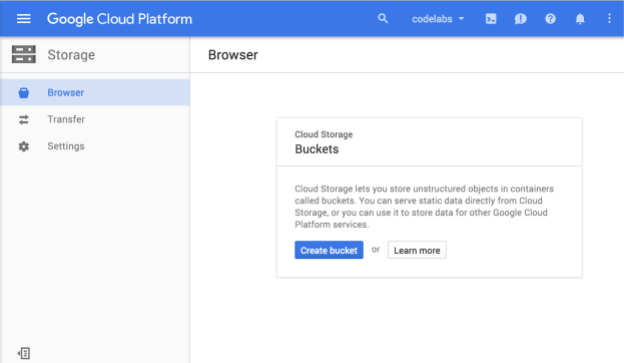
Tekan tombol Buat bucket untuk membuatnya:
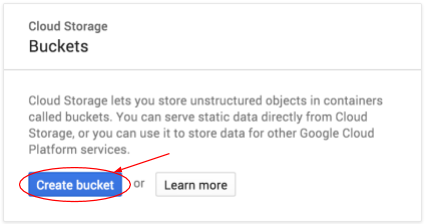
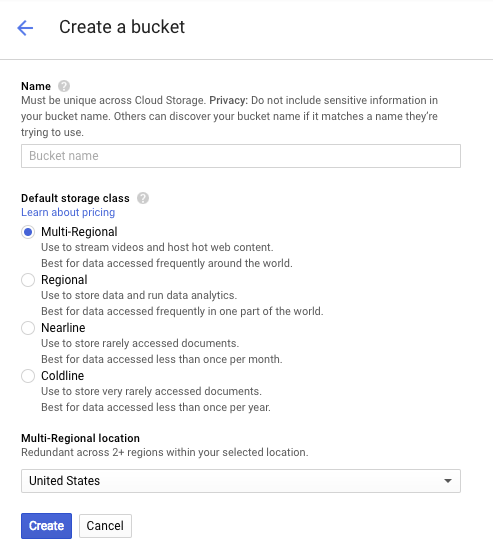
Masukkan nama untuk bucket Anda. Seperti yang tercantum dalam kotak dialog, nama bucket harus unik di seluruh Cloud Storage. Jadi, jika Anda memilih nama yang jelas, seperti "test", Anda mungkin akan mendapati bahwa orang lain telah membuat bucket dengan nama tersebut, dan akan menerima error.
Ada juga beberapa aturan terkait karakter yang diizinkan dalam nama bucket. Jika Anda memulai dan mengakhiri nama bucket dengan huruf atau angka, dan hanya menggunakan tanda hubung di tengah, Anda tidak akan mengalami masalah. Jika Anda mencoba menggunakan karakter khusus, atau mencoba memulai atau mengakhiri nama bucket dengan sesuatu selain huruf atau angka, kotak dialog akan mengingatkan Anda tentang aturan tersebut.
Masukkan nama unik untuk bucket Anda, lalu tekan Buat. Jika Anda memilih sesuatu yang sudah digunakan, Anda akan melihat pesan error yang ditampilkan di atas. Setelah berhasil membuat bucket, Anda akan diarahkan ke bucket baru yang kosong di browser:
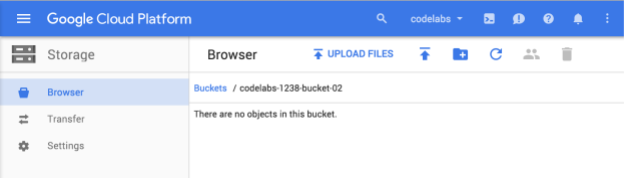
Nama bucket yang Anda lihat tentu akan berbeda, karena harus unik di semua project.
Mengaktifkan Google Cloud Shell
Dari Konsol GCP, klik ikon Cloud Shell di toolbar kanan atas:

Kemudian, klik "Start Cloud Shell":

Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Sebagian besar pekerjaan Anda di lab ini dapat dilakukan hanya dengan browser atau Google Chromebook.
Setelah terhubung ke Cloud Shell, Anda akan melihat bahwa Anda sudah diautentikasi dan project sudah ditetapkan ke PROJECT_ID Anda.
Jalankan perintah berikut di Cloud Shell untuk mengonfirmasi bahwa Anda telah diautentikasi:
gcloud auth list
Output perintah
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Output perintah
[core] project = <PROJECT_ID>
Jika tidak, Anda dapat menyetelnya dengan perintah ini:
gcloud config set project <PROJECT_ID>
Output perintah
Updated property [core/project].
Setelah Cloud Shell diluncurkan, mari kita mulai dengan membuat project Maven yang berisi Cloud Dataflow SDK untuk Java.
Jalankan perintah mvn archetype:generate di shell Anda sebagai berikut:
mvn archetype:generate \
-DarchetypeArtifactId=google-cloud-dataflow-java-archetypes-examples \
-DarchetypeGroupId=com.google.cloud.dataflow \
-DarchetypeVersion=1.9.0 \
-DgroupId=com.example \
-DartifactId=first-dataflow \
-Dversion="0.1" \
-DinteractiveMode=false \
-Dpackage=com.exampleSetelah menjalankan perintah, Anda akan melihat direktori baru bernama first-dataflow di direktori saat ini. first-dataflow berisi project Maven yang mencakup Cloud Dataflow SDK untuk Java dan contoh pipeline.
Mari kita mulai dengan menyimpan project ID dan nama bucket Cloud Storage sebagai variabel lingkungan. Anda dapat melakukannya di Cloud Shell. Pastikan untuk mengganti <your_project_id> dengan project ID Anda.
export PROJECT_ID=<your_project_id>Sekarang kita akan melakukan hal yang sama untuk bucket Cloud Storage. Ingat, ganti <your_bucket_name> dengan nama unik yang Anda gunakan untuk membuat bucket di langkah sebelumnya.
export BUCKET_NAME=<your_bucket_name>Ubah ke direktori first-dataflow/.
cd first-dataflowKita akan menjalankan pipeline bernama WordCount, yang membaca teks, membuat token baris teks menjadi kata individual, dan menjalankan penghitungan frekuensi pada setiap kata tersebut. Pertama, kita akan menjalankan pipeline, dan saat pipeline berjalan, kita akan melihat apa yang terjadi di setiap langkah.
Mulai pipeline dengan menjalankan perintah mvn compile exec:java di shell atau jendela terminal Anda. Untuk argumen --project, --stagingLocation, dan --output, perintah di bawah mereferensikan variabel lingkungan yang Anda siapkan sebelumnya pada langkah ini.
mvn compile exec:java \
-Dexec.mainClass=com.example.WordCount \
-Dexec.args="--project=${PROJECT_ID} \
--stagingLocation=gs://${BUCKET_NAME}/staging/ \
--output=gs://${BUCKET_NAME}/output \
--runner=BlockingDataflowPipelineRunner"Saat tugas berjalan, mari kita temukan tugas di daftar tugas.
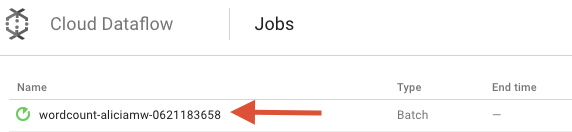
Buka UI Pemantauan Cloud Dataflow di Google Cloud Platform Console. Anda akan melihat tugas wordcount Anda dengan status Running:

Sekarang, mari kita lihat parameter pipeline. Mulai dengan mengklik nama tugas Anda:
Saat memilih tugas, Anda dapat melihat grafik eksekusi. Grafik eksekusi pipeline merepresentasikan setiap transformasi dalam pipeline sebagai kotak yang berisi nama transformasi dan beberapa informasi status. Anda dapat mengklik tanda sisipan di sudut kanan atas setiap langkah untuk melihat detail selengkapnya:
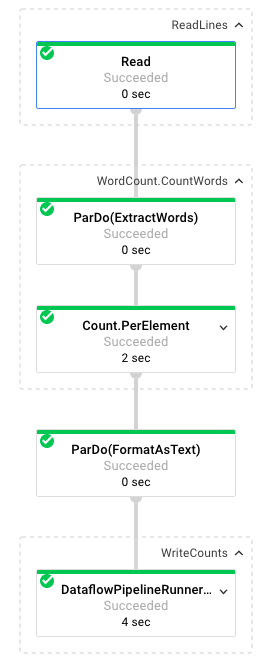
Mari kita lihat bagaimana pipeline mentransformasi data di setiap langkah:
- Baca: Pada langkah ini, pipeline membaca dari sumber input. Dalam hal ini, file tersebut adalah file teks dari Cloud Storage dengan seluruh teks drama Shakespeare King Lear. Pipeline kami membaca file baris demi baris dan menghasilkan setiap
PCollection, di mana setiap baris dalam file teks kami adalah elemen dalam koleksi. - CountWords: Langkah
CountWordsmemiliki dua bagian. Pertama, fungsi ini menggunakan fungsi do paralel (ParDo) bernamaExtractWordsuntuk melakukan tokenisasi setiap baris menjadi kata-kata individual. Output ExtractWords adalah PCollection baru yang setiap elemennya adalah kata. Langkah berikutnya,Count, menggunakan transformasi yang disediakan oleh Dataflow SDK yang menampilkan pasangan kunci-nilai dengan kunci berupa kata unik dan nilai berupa jumlah kemunculannya. Berikut adalah metode yang menerapkanCountWords, dan Anda dapat melihat file WordCount.java lengkap di GitHub:
/**
* A PTransform that converts a PCollection containing lines of text
* into a PCollection of formatted word counts.
*/
public static class CountWords extends PTransform<PCollection<String>,
PCollection<KV<String, Long>>> {
@Override
public PCollection<KV<String, Long>> apply(PCollection<String> lines) {
// Convert lines of text into individual words.
PCollection<String> words = lines.apply(
ParDo.of(new ExtractWordsFn()));
// Count the number of times each word occurs.
PCollection<KV<String, Long>> wordCounts =
words.apply(Count.<String>perElement());
return wordCounts;
}
}- FormatAsText: Ini adalah fungsi yang memformat setiap pasangan nilai kunci menjadi string yang dapat dicetak. Berikut transformasi
FormatAsTextuntuk mengimplementasikannya:
/** A SimpleFunction that converts a Word and Count into a printable string. */
public static class FormatAsTextFn extends SimpleFunction<KV<String, Long>, String> {
@Override
public String apply(KV<String, Long> input) {
return input.getKey() + ": " + input.getValue();
}
}- WriteCounts: Pada langkah ini, kita menulis string yang dapat dicetak ke dalam beberapa file teks yang di-shard.
Kita akan melihat output yang dihasilkan dari pipeline dalam beberapa menit.
Sekarang lihat halaman Ringkasan di sebelah kanan grafik, yang mencakup parameter pipeline yang disertakan dalam perintah mvn compile exec:java.
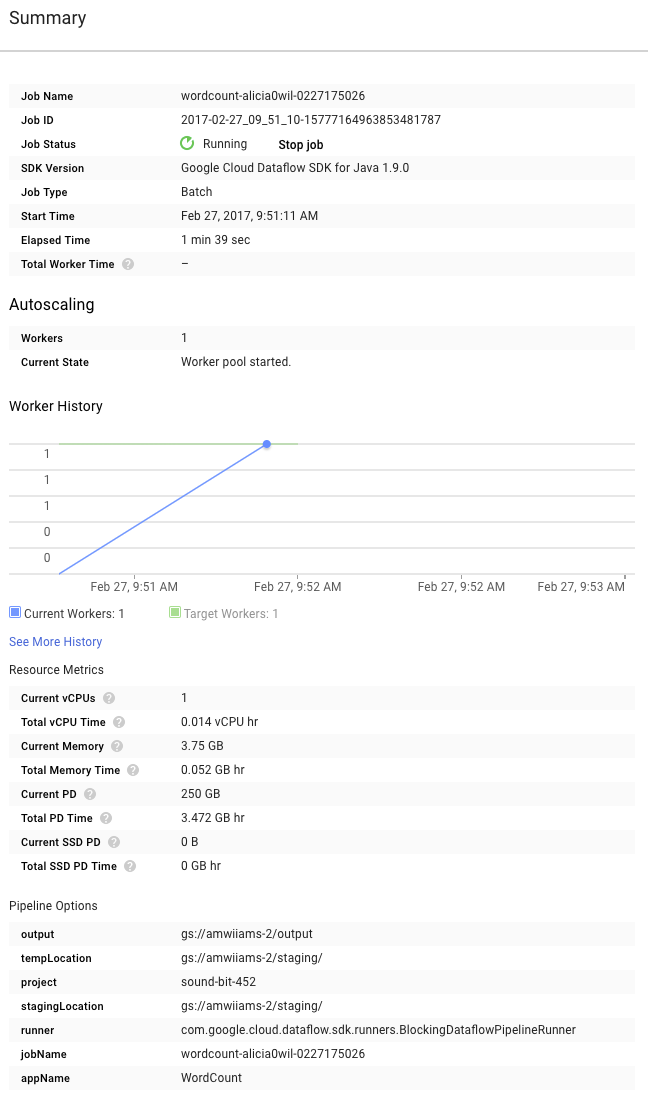
Anda juga dapat melihat Penghitung kustom untuk pipeline, yang dalam hal ini menunjukkan jumlah baris kosong yang telah ditemukan sejauh ini selama eksekusi. Anda dapat menambahkan penghitung baru ke pipeline untuk melacak metrik spesifik per aplikasi.
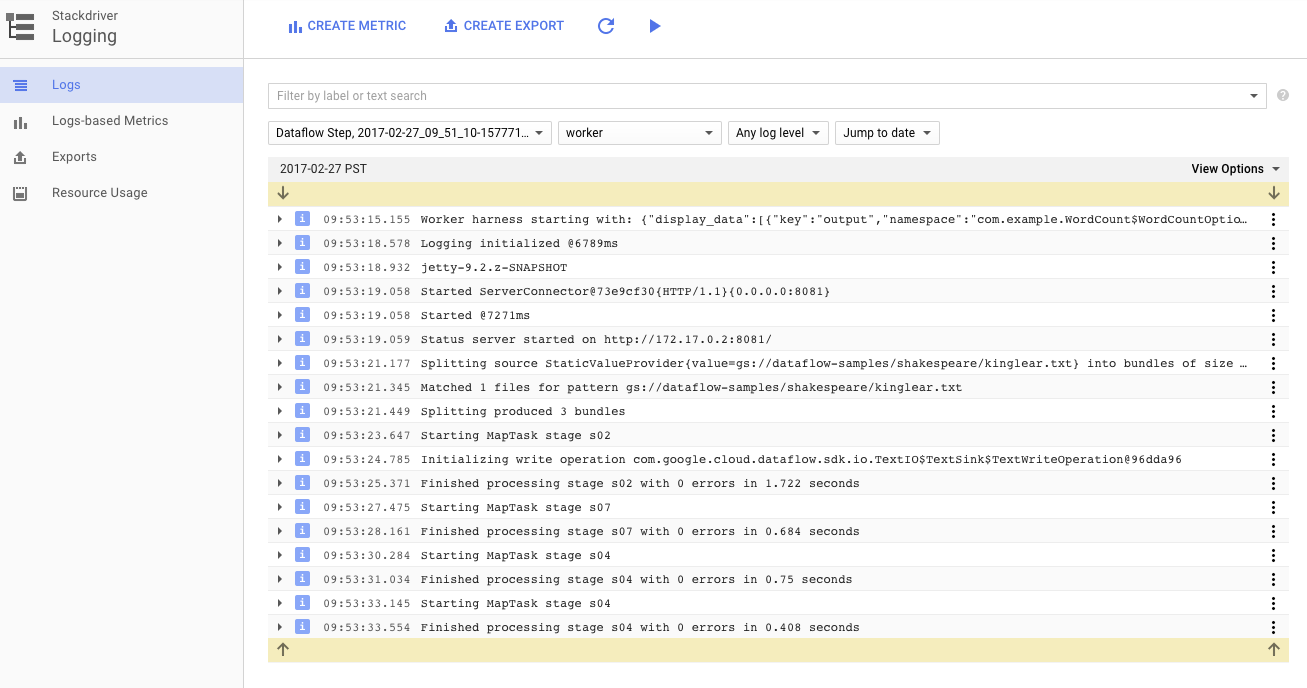
Anda dapat mengklik ikon Log untuk melihat pesan error tertentu.

Anda memfilter pesan yang muncul di tab Job Log menggunakan menu drop-down Minimum Severity.

Anda dapat menggunakan tombol Worker Logs di tab log untuk melihat log pekerja untuk instance Compute Engine yang menjalankan pipeline Anda. Log Pekerja terdiri dari baris log yang dihasilkan oleh kode Anda dan kode yang dihasilkan Dataflow yang menjalankannya.
Jika Anda mencoba men-debug kegagalan dalam pipeline, sering kali ada logging tambahan di Log Pekerja yang membantu menyelesaikan masalah. Perlu diingat bahwa log ini digabungkan di semua pekerja, dan dapat difilter serta ditelusuri.
Pada langkah berikutnya, kita akan memeriksa apakah pekerjaan Anda berhasil.
Buka UI Pemantauan Cloud Dataflow di Google Cloud Platform Console.
Di awal, Anda akan melihat tugas wordcount Anda dengan status Running, lalu Succeeded:

Tugas ini akan memerlukan waktu sekitar 3-4 menit untuk dijalankan.
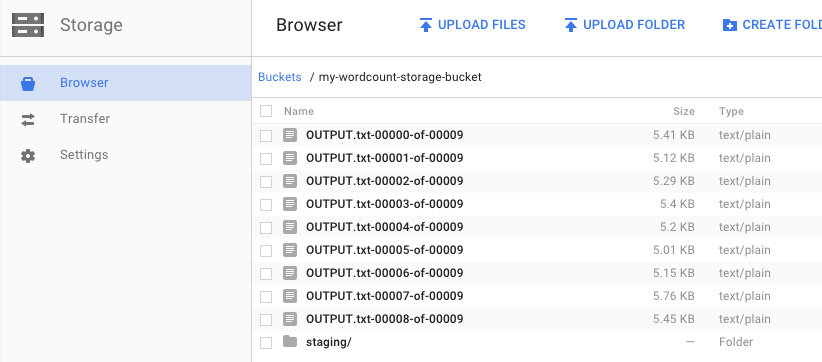
Ingatkah saat Anda menjalankan pipeline dan menentukan bucket output? Mari kita lihat hasilnya (karena Anda pasti ingin tahu berapa kali setiap kata dalam King Lear muncul, bukan?). Kembali ke Browser Cloud Storage di Konsol Google Cloud Platform. Di bucket, Anda akan melihat file output dan file penyiapan yang dibuat oleh tugas Anda:
Anda dapat mematikan resource dari Konsol Google Cloud Platform.
Buka browser Cloud Storage di Konsol Google Cloud Platform.
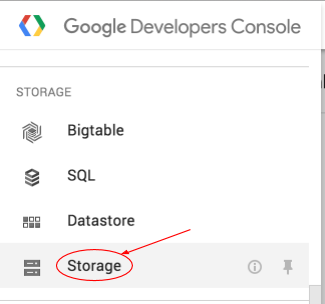
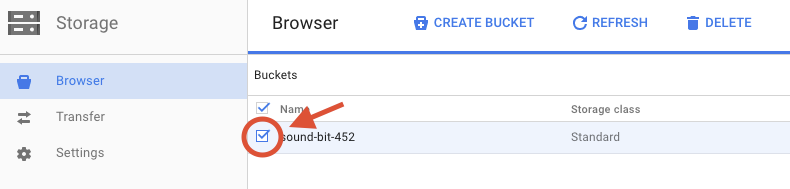
Pilih kotak centang di samping bucket yang Anda buat.
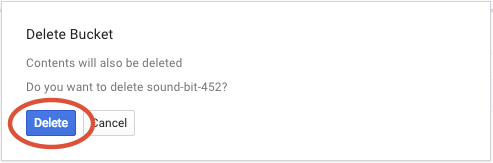
Klik HAPUS untuk menghapus bucket dan isinya secara permanen.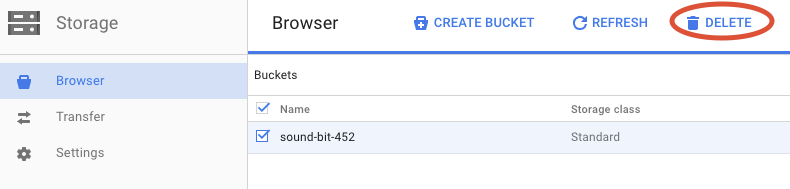
Anda telah mempelajari cara membuat project Maven dengan Cloud Dataflow SDK, menjalankan contoh pipeline menggunakan Konsol Google Cloud Platform, dan menghapus bucket Cloud Storage terkait beserta isinya.
Pelajari Lebih Lanjut
- Dokumentasi Dataflow: https://cloud.google.com/dataflow/docs/
Lisensi
Karya ini dilisensikan berdasarkan Lisensi Umum Creative Commons Attribution 3.0, dan lisensi Apache 2.0.