
Bu codelab'de BigQuery'nin aşağıdakiler gibi gelişmiş özelliklerinden bazılarını nasıl kullanacağınızı öğreneceksiniz:
- JavaScript'te Kullanıcı Tanımlı İşlevler
- Bölümlendirilmiş tablolar
- Google Cloud Storage ve Google Drive'da yaşayan verilere karşı doğrudan sorgular.
ABD Federal Seçim Komisyonu'ndan verileri alıp temizlemek ve BigQuery'ye yüklemek. Bu veri kümesiyle ilgili bazı ilgi çekici sorular sormanız da mümkün.
Bu codelab'in BigQuery ile ilgili daha önce herhangi bir deneyimi olduğunu varsaymasak da SQL'i anlamak, bu özellikten daha iyi yararlanmanıza yardımcı olacaktır.
Neler öğreneceksiniz?
- SQL'de yapılması zor olan işlemleri gerçekleştirmek için JavaScript Kullanıcı Tanımlı İşlevleri nasıl kullanılır?
- Google Cloud Storage ve Google Drive gibi diğer veri depolarında yaşayan verilerde ETL (Ayıklama, Dönüşüm, Yük) işlemleri gerçekleştirmek için BigQuery'yi kullanma.
Gerekenler
- Faturalandırmanın etkin olduğu bir Google Cloud Projesi.
- Bir Google Cloud Storage Paketi
- Google Cloud SDK yüklendi
Bu eğitimi nasıl kullanacaksınız?
BigQuery deneyiminizi nasıl değerlendirirsiniz?
Bağımsız tempolu ortam kurulumu
Google Hesabınız (Gmail veya Google Apps) yoksa bir hesap oluşturmanız gerekir. Google Cloud Platform Console'da (console.cloud.google.com) oturum açın ve yeni bir proje oluşturun:



Proje kimliğini tüm Google Cloud projeleri genelinde benzersiz bir ad olarak hatırlayın (yukarıdaki ad zaten alınmıştı ve maalesef sizin için çalışmaz). Bu, daha sonra bu codelab'de PROJECT_ID olarak adlandırılacaktır.
Ardından, Google Cloud kaynaklarını kullanmak için Cloud Console'da faturalandırmayı etkinleştirmeniz gerekir.
Bu codelab'i gözden geçirmek için çalışmanın birkaç dolardan fazla maliyeti olmayacak. Ancak daha fazla kaynak kullanmaya karar verirseniz veya bunları çalışır durumda bırakırsanız (bu belgenin sonundaki "temizlik" bölümüne bakın) daha yüksek maliyetli olabilir.
Yeni Google Cloud Platform kullanıcıları 300 ABD doları değerindeki ücretsiz denemeden yararlanabilir.
Google Cloud Shell
Google Cloud ve Big Query, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir. Ancak bu codelab'de, Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacağız.
Bu Debian tabanlı sanal makine, ihtiyacınız olan tüm geliştirme araçları yüklüdür. 5 GB kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışarak ağ performansını ve kimlik doğrulamayı büyük ölçüde iyileştirir. Yani, bu codelab için ihtiyacınız olan tek şey bir tarayıcıdır (evet, Chromebook'ta çalışır).
Google Cloud Shell'i etkinleştirmek için geliştirici konsolunun sağ üst tarafındaki düğmeyi tıklayın (temel hazırlığın yapılması ve ortama bağlanmanız yalnızca birkaç dakika sürer):

"Cloud Shell'i Başlat" düğmesini tıklayın:


Cloud shell'e bağlandıktan sonra kimliğinizin zaten doğrulanmış olduğunu ve projenin PROJECT_ID olarak ayarlandığını görmeniz gerekir :
gcloud auth list
Komut çıkışı
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Komut çıkışı
[core] project = <PROJECT_ID>
Cloud Shell, varsayılan olarak bazı ortam değişkenlerini de ayarlar. Bu değişkenler, gelecekteki komutları çalıştırırken faydalı olabilir.
echo $GOOGLE_CLOUD_PROJECT
Komut çıkışı
<PROJECT_ID>
Herhangi bir nedenle proje ayarlanmadıysa aşağıdaki komutu verin :
gcloud config set project <PROJECT_ID>
PROJECT_ID cihazınızı mı arıyorsunuz? Kurulum adımlarında hangi kimliği kullandığınıza göz atın veya konsolu kontrol panelinde arayın:

ÖNEMLİ: Son olarak varsayılan alt bölgeyi ve proje yapılandırmasını ayarlayın:
gcloud config set compute/zone us-central1-f
Farklı bölgeler seçebilirsiniz. Bölgeler ve Alt Bölgeler dokümanlarında daha fazla bilgi edinin.
Bu codelab'de BigQuery sorgularını çalıştırmak için kendi veri kümenize ihtiyacınız olacaktır. Hesap için campaign_funding gibi bir ad seçin. Kabuğunuzda aşağıdaki komutları çalıştırın (örneğin, CloudShell):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
Veri kümeniz oluşturulduktan sonra kullanıma hazır olmalısınız. Bu komutu çalıştırmak bq komut satırı istemci kurulumunun doğru şekilde yapıldığını, kimlik doğrulamasının çalıştığını ve yürüttüğünüz bulut projesine yazma erişiminizin olduğunu doğrulamanıza da yardımcı olur. Birden fazla projeniz varsa bir projeden ilgilendiğiniz bir projeyi seçmeniz istenir.

ABD Federal Seçim Komisyonu kampanya finans veri kümesi sıkıştırılmış olarak GCS paketine (gs://campaign-funding/) kopyalandı.
Nasıl göründüğüne bakmak için kaynak dosyalardan birini yerel olarak indirelim. Bir komut penceresinde şu komutları çalıştırın:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
Bu işlem, her bir katkı dosyasının içeriğini gösterir. Bu codelab için üç tür dosya arıyoruz: Tek tek katkılar (indiv*.txt), adaylar (cn*.txt) ve komiteler (cm*.txt). İlgilendiğiniz konuları öğrenmek için aynı mekanizmayı kullanın.
Ham verileri doğrudan BigQuery'ye yüklemeyeceğiz; bunun yerine verileri Google Cloud Storage'dan sorgulayacağız. Bunu yapmak için şemayı ve şemayla ilgili bazı bilgileri bilmemiz gerekir.
Veri kümesi, buradaki federal seçim web sitesinde açıklanmıştır. İncelediğimiz tabloların şemaları şunlardır:
Tablolara bağlantı oluşturmak için şemaları içeren bir tablo tanımı oluşturmamız gerekiyor. Tek tek tablo tanımları oluşturmak için aşağıdaki komutları çalıştırın:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
indiv_dev.json dosyasını favori metin düzenleyicinizle açın ve içeriğe göz atın. FEC veri dosyasının nasıl yorumlanacağını açıklayan json dosyasını içerir.
csvOptions bölümünde iki küçük düzenleme yapmamız gerekiyor. fieldDelimiter &&# karakterini; quote değerini ise "" (boş dize) ekleyin. Bu, veri dosyası aslında virgülle ayrılmış olmadığı, dikey çizgiyle ayrıldığı için gereklidir:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
indiv_dev.json dosyası şu şekilde olmalıdır :
"fieldDelimiter": "|",
"quote":"",
Komite ve aday tablolar için tablo tanımları benzer olduğundan ve şemada makul bir ortak metin bulunduğundan, bu dosyaları indirelim.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
Bu dosyalar, indiv_dev.json dosyasına benzer. Ayrıca, doğru değerleri alma konusunda sorun yaşıyorsanız indiv_def.json dosyasını indirebilirsiniz.
Şimdi, bu dosyalara bir BigQuery tablosu bağlayın. Aşağıdaki komutları çalıştırın:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
Bu işlemle, üç bigquery tablosu oluşturulur: işlemler, komiteler ve adaylar. Bu tabloları normal BigQuery tabloları gibi sorgulayabilirsiniz ancak BigQuery'de depolanmazlar, Google Cloud Storage'da saklanırlar. Temel dosyaları güncellerseniz güncellemeler, çalıştırdığınız sorgulara hemen yansıtılır.
Şimdi birkaç sorgu çalıştırmayı deneyelim. BigQuery Web Kullanıcı Arayüzü'nü açın.

Sol gezinme bölmesinde veri kümenizi bulun (sol üst köşedeki proje açılır listesini değiştirmeniz gerekebilir), büyük kırmızı renkli "QUERY OLUŞTUR' düğmesini tıklayın ve kutuya aşağıdaki sorguyu girin:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
Bu, Google'ın çalışanlarına yaptığı en son 100 kampanya bağışını gösterir. Dilerseniz dolaşarak ve posta kodunuzdan sakinlerin kampanya bağışlarını bulmayı deneyin veya bulunduğunuz şehirdeki en büyük bağışları bulun.
Sorgu ve sonuçlar aşağıdaki gibi görünür:
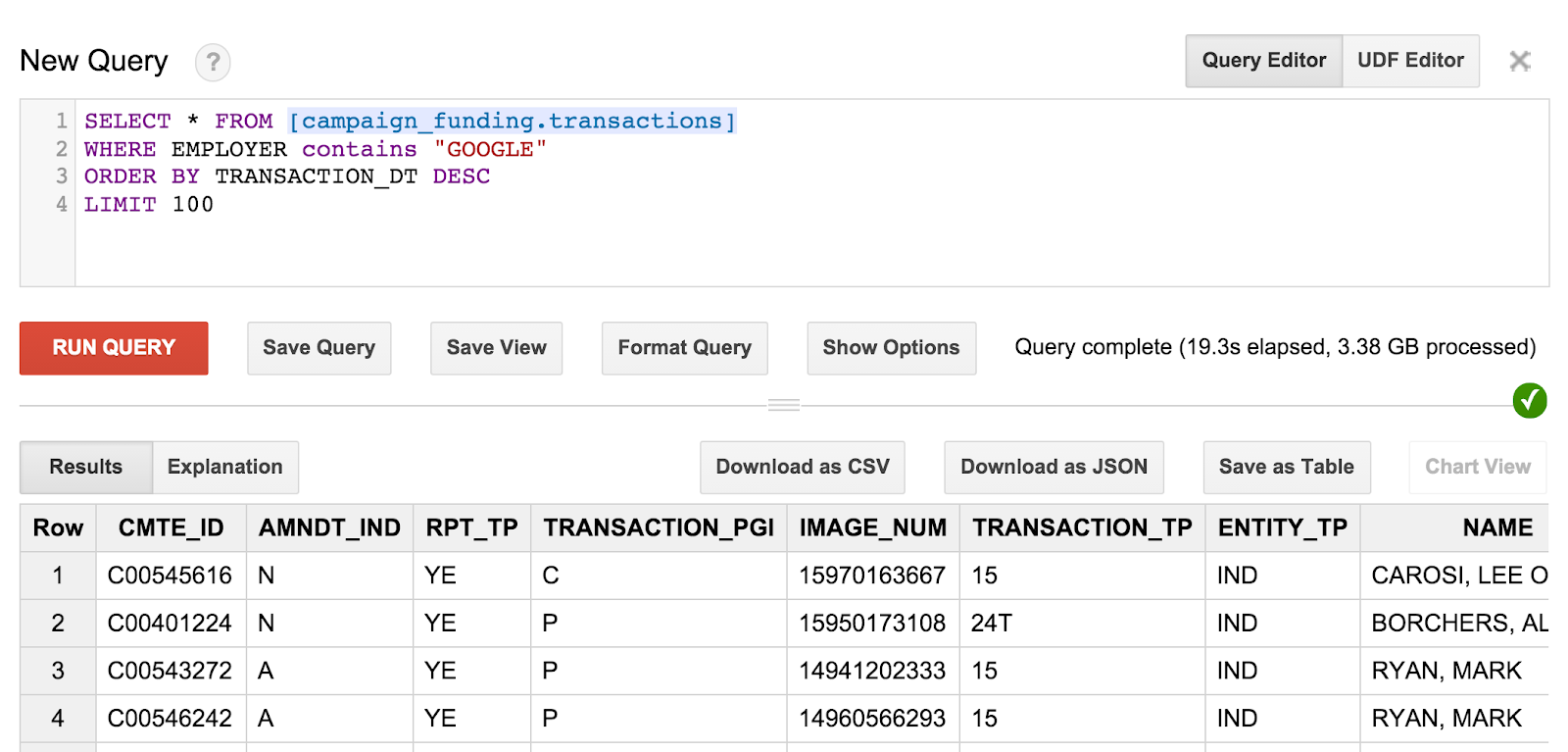
Ancak, bu bağışların kimden geldiğini gerçekten anlayamadığınızı fark edebilirsiniz. Bu bilgileri almak için bazı meraklı sorgular bulmamız gerekiyor.
Sol bölmede işlemler tablosunu, ardından da şema sekmesini tıklayın. Aşağıdaki ekran görüntüsü aşağıdaki gibi görünmelidir:
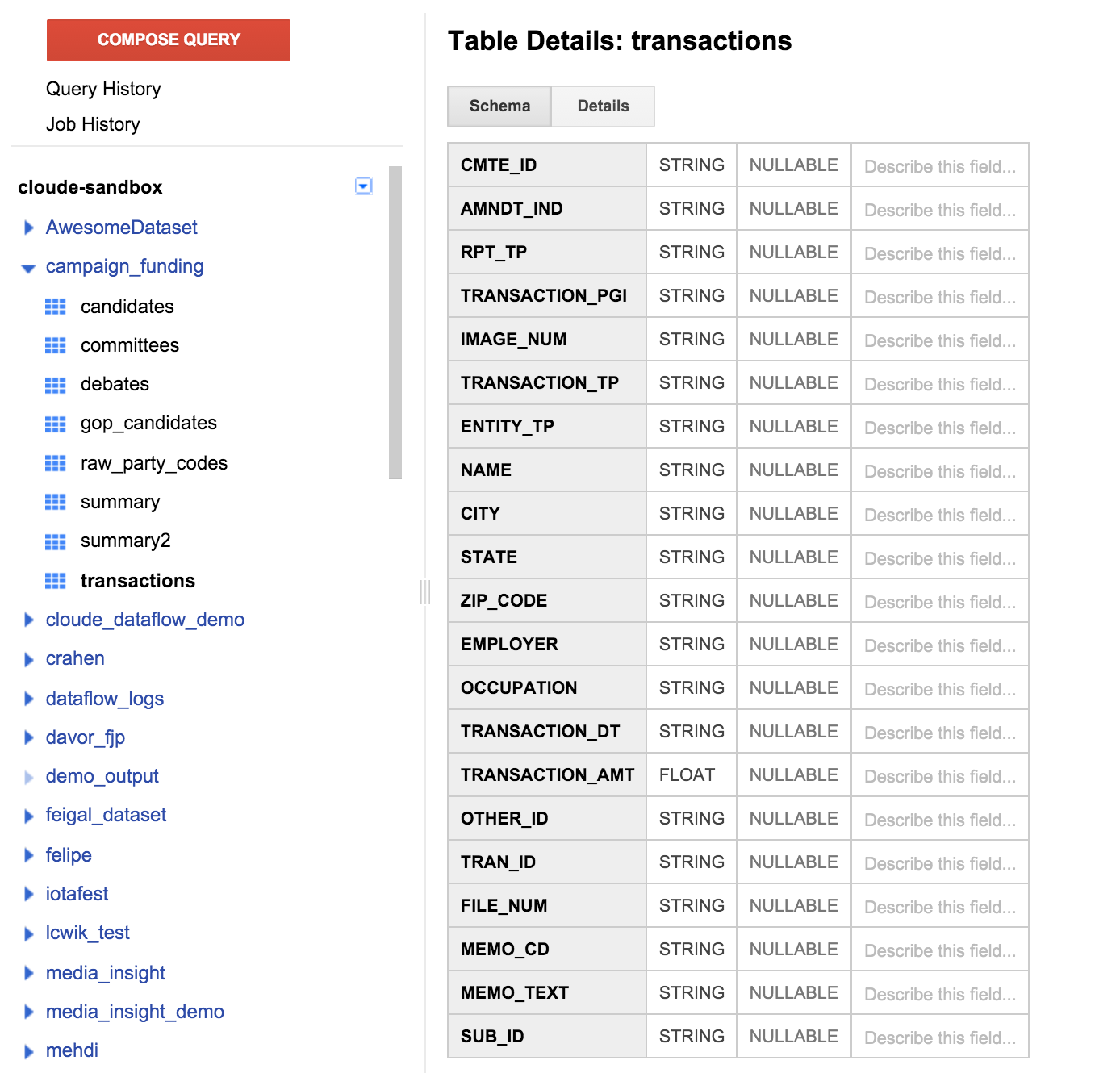
Daha önce belirttiğimiz tablo tanımıyla eşleşen alanların bir listesini görebiliriz. Herhangi bir alıcı alanı olmadığını veya bağışın hangi aday için desteklendiğini öğrenmenin bir yolu olduğunu fark edebilirsiniz. Ancak CMTE_ID adlı bir alan bulunur. Bu sayede, bağışın alındığı komiteyi bağışa bağlayabiliriz. Yine de faydalı değil.
Daha sonra, şemasına göz atmak için komiteler tablosunu tıklayın. İşlemler tablosuna katılabilecek bir CMET_ID var. Diğer bir alan: CAND_ID; adaylar tablosunda bir CAND_ID tablosuyla birleştirilebilir. Son olarak, komiteler tablosundan geçerek işlemler ile adaylar arasında bir bağlantı sağlıyoruz.
GCS tabanlı tablolar için önizleme sekmesinin bulunmadığını unutmayın. Bunun nedeni, BigQuery'nin verileri okuyabilmesi için harici bir veri kaynağından okuması gerektiğidir. Adaylar tablosunda basit bir "SELECT *' sorgusu çalıştırarak verilerin bir örneğini öğrenelim.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
Sonuç şöyle görünmelidir:
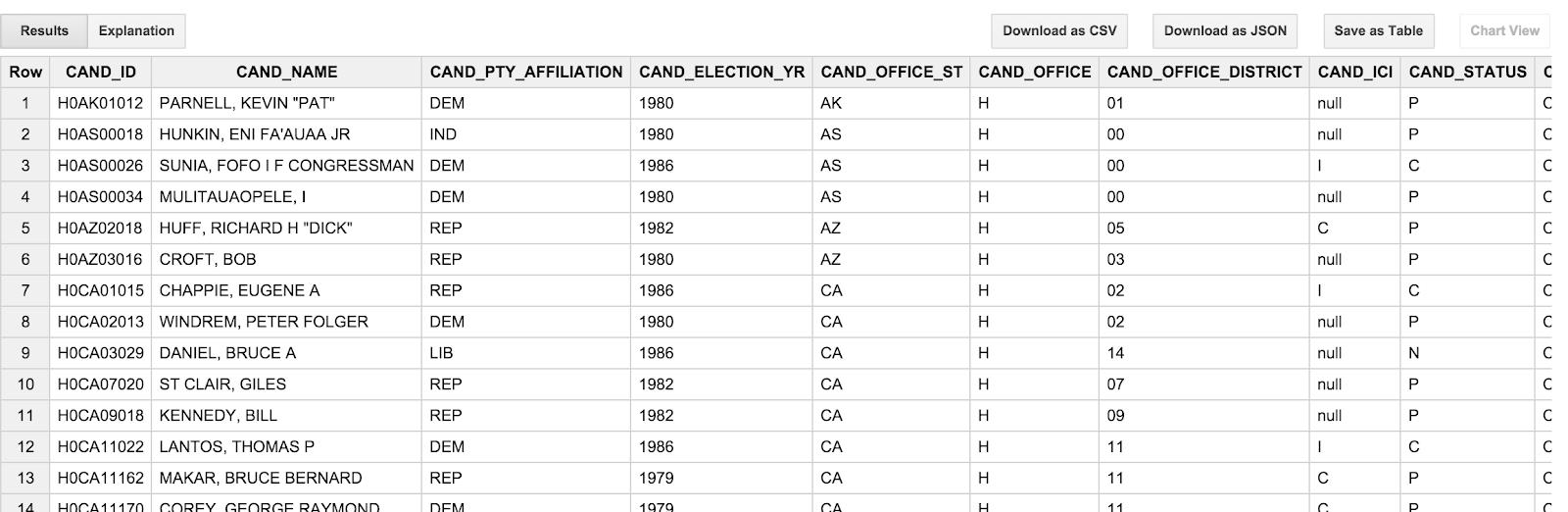
Dikkat etmeniz gereken bir nokta, aday adlarının BÜYÜK HARFLERLE yazmak ve & soyadı, ad ve ad sırasına göre gönderilmesidir. Bu, adaylar hakkındaki düşünme biçimimiz açısından biraz can sıkıcı olduğu için "OBAMA, BARACK" yerine "Barack Obama"yı görmeyi tercih ediyoruz. Ayrıca, işlemler tablosundaki işlem tarihleri de (TRANSACTION_DT) biraz tuhaf olur. Bunlar, YYYYMMDD biçimindeki dize değerleridir. Bir sonraki bölümde bu hatalara değineceğiz.
İşlemlerin adaylarla ilişkisini anladığımıza göre, şimdi kimin kime para verdiğini anlamak için bir sorgu çalıştırabiliriz. Aşağıdaki sorguyu kesip Oluştur kutusuna yapıştırın:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
Bu sorgu, işlemler tablosunu komite tablosuna, ardından adaylar tablosuna birleştirir. Yalnızca mesleği başlığında "ENGINEER" kelimesi bulunan kullanıcıların işlemlerini inceler. Sorgu, sonuçları parti ilişkisine göre toplar; bu da mühendisler arasında çeşitli siyasi partilere yapılan bağışın dağılımını görmemize olanak tanır.
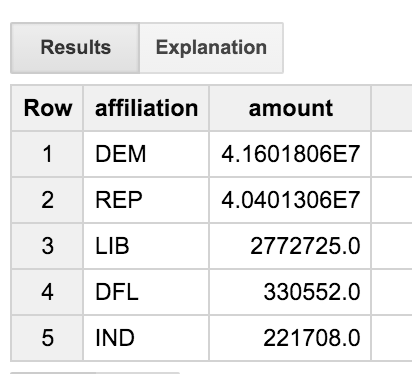
Mühendislerin, demokratlar ve cumhuriyetçilere eşit oranda veya daha az eşitlik sağlayarak oldukça dengeli bir grup olduğunu görüyoruz. Peki "DFL" partisi nedir? Üç harften ziyade tam adları almak daha iyi olmaz mıydı?
Parti kodları, FEC web sitesinde tanımlanır. Parti kodunu tam adla eşleşen bir tablo bulunur ("DFL' "Democratic-Farmer-Labor'" olduğu ortaya çıkar). Sorgumuzdaki çevirileri manuel olarak gerçekleştirebilsek de bu çok fazla iş anlamına geliyor ve senkronizasyonu sürdürmek zor görünüyor.
HTML'yi sorgunun bir parçası olarak ayrıştırabilsek ne olur? Bu sayfada herhangi bir yeri sağ tıklayın ve "sayfa kaynağını görüntüle" bölümüne bakın. Kaynakta çok sayıda başlık / ortak bilgi bulunur, ancak <table> etiketini bulun. Her eşleme satırı bir HTML <tr> öğesinin içindedir, ad ve kod <td> öğelerinin içinde sarmalanır. Her satır aşağıdaki gibi görünür:
HTML şuna benzer:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
BigQuery'nin dosyayı doğrudan web'den okuyamadığını unutmayın. Çünkü bigquery, aynı anda binlerce çalışandan gelen bir kaynağa erişebilir. Bu içeriğin rastgele web sayfalarında çalıştırılmasına izin verildiyse bu temel olarak dağıtılmış bir hizmet reddi saldırısı (DDoS) olur. FEC web sayfasındaki html dosyası, gs://campaign-funding paketinde depolanır.
Kampanya fon verilerine göre bir tablo oluşturmamız gerekiyor. Bu, oluşturduğumuz diğer GCS destekli tablolara benzer olacaktır. Buradaki fark, aslında bir şemamız olmaması. Her satır için tek bir alan kullanıp bunu "data'" olarak adlandıracağız. Virgülle sınırlama yerine, sahte bir ayırıcı (`) kullanacağız ve tırnak işareti kullanılmamış gibi davranacağız.
Parti arama tablosunu oluşturmak için komut satırından aşağıdaki komutları çalıştırın:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
Şimdi dosyayı ayrıştırmak için JavaScript kullanacağız. BigQuery Sorgu Düzenleyici'nin sağ üst tarafında "UDF Düzenleyici" etiketli bir düğme olmalıdır. JavaScript UDF'ye geçiş yapmak için bu simgeyi tıklayın. UDF düzenleyici, yorum yapılan bazı ortak metinle doldurulur.

Devam edip içerdiği kodu silin ve aşağıdaki kodu girin:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
Buradaki JavaScript iki parçaya ayrılmıştır. İlki, bir giriş satırının ayrıştırılmış çıkış vermesini sağlayan bir fonksiyondur. Diğeri, bu işlevi tableParser adlı bir Kullanıcı Tanımlı İşlev (UDF) olarak kaydeden ve "data'" adlı bir giriş sütunu aldığını ve kod ve ad olarak iki sütun ürettiğini belirten bir tanım. Kod sütunu üç harfli kod olur, ad sütunu partinin tam adıdır.
"Sorgu Düzenleyici" sekmesine geri dönün ve aşağıdaki sorguyu girin:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
Bu sorgunun çalıştırılması, ham HTML dosyasının ayrıştırılmasını ve alan değerlerinin yapılandırılmış biçimde gösterilmesini sağlar. Son derece şık, değil mi? "DFL" ne anlama geliyor?
Parti kodlarını adlara çevirebileceğimize göre, ilginç bir şey bulmak için bunu kullanan başka bir sorgu deneyelim. Aşağıdaki sorguyu çalıştırın:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
Bu sorgu, en fazla kampanya bağışı alan adayları gösterir ve parti satış ortaklarını gösterir.
Bu tablolar çok büyük değiller ve sorgulanması 30 saniye kadar sürüyor. Tablolarla çok iş yapacaksanız büyük olasılıkla tabloları BigQuery'ye aktarmak isteyeceksiniz. Verileri kullanımı kolay bir şeye zorlamak için bir ETL sorgusu çalıştırabilir ve ardından kalıcı bir tablo olarak kaydedebilirsiniz. Bu sayede, parti kodlarını nasıl çevireceğinizi her zaman hatırlamanız gerekmez. Ayrıca, bu sırada hatalı verileri filtreleyebilirsiniz.
"Seçenekleri göster" düğmesini, ardından "Destination Table" etiketinin yanındaki "Tablo seç" düğmesini tıklayın. campaign_funding veri kümenizi seçin ve tablo kimliğini "summary'" olarak girin. "allow large results' onay kutusunu seçin.

Şimdi aşağıdaki sorguyu çalıştırın:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
Bu sorgu çok daha uzun ve bazı temizlik seçenekleri var. Örneğin, tutarın 1 milyon ABD dolarından fazla olduğu hiçbir şeyi yoksayar. Ayrıca"LASTNAME, FIRSTNAME"adlı parçayı"dönüştürmek"için normal ifadelerle de kullanır. Maceraya düşkün hissediyorsanız daha da iyi olması için bir UDF yazmayı deneyin ve büyük harf kullanımını düzeltin (ör. "&").
Son olarak, söz konusu tablodaki sorguların daha hızlı olduğunu doğrulamak için campaign_funding.summary tablonuzda birkaç sorgu çalıştırmayı deneyin. İlk olarak hedef tablo sorgu seçeneğini kaldırmayı unutmayın. Aksi takdirde özet tablonuzun üzerine yazabilirsiniz.
FEC web sitesindeki verileri temizleyip BigQuery'ye aktardınız.
Değindiğimiz konular
- BigQuery'de GCS destekli tablolar kullanma.
- BigQuery'de Kullanıcı Tanımlı İşlevleri Kullanma.
Sonraki Adımlar
- Bu seçim döngüsünde kimlerin para verdiğini öğrenmek için bazı ilgi çekici sorgular deneyin.
Daha Fazla Bilgi
- Kullanıcı tanımlı işlevler ile neler yapabileceğiniz hakkında daha fazla bilgi edinin.
- Birleşik veri kaynakları (GCS dahil) hakkında bilgi edinin.
- google-bigquery etiketinin altında Stackoverflow'da sorular yayınlayın ve cevaplara ulaşın.
Görüşlerinizi bildirin
- Sorun bildirmek veya geri bildirim paylaşmak için bu sayfanın sol alt tarafındaki bağlantıyı kullanabilirsiniz.