
ใน Codelab นี้ คุณจะได้ดูวิธีใช้ฟีเจอร์ขั้นสูงของ BigQuery ได้แก่
- ฟังก์ชันที่ผู้ใช้กําหนดใน JavaScript
- ตารางที่แบ่งพาร์ติชันแล้ว
- ส่งคําถามโดยตรงไปยังข้อมูลที่อยู่ใน Google Cloud Storage และ Google ไดรฟ์
คุณจะนําข้อมูลจากคณะกรรมาธิการการเลือกตั้งสหพันธรัฐของสหรัฐอเมริกา ล้างข้อมูล และโหลดเข้าสู่ BigQuery นอกจากนี้ คุณจะมีโอกาสถามคําถามที่น่าสนใจของชุดข้อมูลนั้นด้วย
แม้ว่า Codelab นี้จะไม่ได้คํานึงถึงประสบการณ์การใช้งาน BigQuery มาก่อน แต่การทําความเข้าใจเกี่ยวกับ SQL จะช่วยให้คุณใช้ประโยชน์จากโค้ดนี้ได้มากขึ้น
สิ่งที่คุณจะได้เรียนรู้
- วิธีใช้ฟังก์ชันที่กําหนดโดย JavaScript ในการดําเนินงานที่ทําได้ยากใน SQL
- วิธีใช้ BigQuery เพื่อดําเนินการ ETL (แยก เปลี่ยนรูปแบบ โหลด) กับข้อมูลที่อยู่ในที่เก็บข้อมูลอื่นๆ เช่น Google Cloud Storage และ Google ไดรฟ์
สิ่งที่ต้องมี
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- ที่เก็บข้อมูล Google Cloud Storage
- ติดตั้ง Google Cloud SDK แล้ว
คุณจะใช้บทแนะนํานี้อย่างไร
คุณจะให้คะแนนระดับประสบการณ์ของคุณด้วย BigQuery อย่างไร
การตั้งค่าสภาพแวดล้อมด้วยตนเอง
หากยังไม่มีบัญชี Google (Gmail หรือ Google Apps) คุณต้องสร้างบัญชี ลงชื่อเข้าใช้คอนโซล Google Cloud Platform (console.cloud.google.com) และสร้างโปรเจ็กต์ใหม่ ดังนี้



โปรดทราบว่ารหัสโปรเจ็กต์ ซึ่งเป็นชื่อที่ไม่ซ้ํากันสําหรับโปรเจ็กต์ Google Cloud ทั้งหมด (ชื่อข้างต้นมีผู้อื่นนําไปใช้แล้ว ขออภัยในความไม่สะดวก) และจะเรียกใน Codelab นี้ว่า PROJECT_ID ในภายหลัง
จากนั้นคุณจะต้องเปิดใช้การเรียกเก็บเงินใน Cloud Console เพื่อใช้ทรัพยากรของ Google Cloud
การเรียกใช้ Codelab นี้ไม่ควรมีค่าใช้จ่ายเกิน 2-3 ดอลลาร์ แต่อาจมากกว่านั้นหากคุณตัดสินใจใช้ทรัพยากรเพิ่มเติมหรือปล่อยให้ทรัพยากรทํางาน (ดู "cleanup" ในตอนท้ายของเอกสารนี้)
ผู้ใช้ใหม่ของ Google Cloud Platform มีสิทธิ์รับช่วงทดลองใช้ฟรี$300
Google Cloud Shell
แม้ว่า Google Cloud และ Big Query ทํางานจากแล็ปท็อปได้จากระยะไกล แต่ใน Codelab นี้ เราจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคําสั่งที่ทํางานในระบบคลาวด์
เครื่องเสมือนบน Debian นี้เต็มไปด้วยเครื่องมือการพัฒนาทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหน้าแรกขนาด 5 GB ถาวรและทํางานอยู่ใน Google Cloud ซึ่งช่วยปรับปรุงประสิทธิภาพและการตรวจสอบสิทธิ์ของเครือข่ายได้อย่างมาก ซึ่งหมายความว่า เพียงแค่ใช้ Codelab นี้ คุณก็สามารถใช้เบราว์เซอร์ได้ (ใช่บนอุปกรณ์ Chromebook)
หากต้องการเปิดใช้งาน Google Cloud Shell เพียงคลิกปุ่มด้านขวาบนของคอนโซลของนักพัฒนาซอฟต์แวร์ (ใช้เวลาเพียงไม่กี่นาทีในการจัดสรรและเชื่อมต่อกับสภาพแวดล้อม) โดยทําดังนี้

คลิกปุ่ม "เริ่ม Cloud Shell"


เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ตรวจสอบว่าคุณได้รับการตรวจสอบสิทธิ์แล้ว และมีการตั้งค่าโปรเจ็กต์เป็น PROJECT_ID แล้ว:
gcloud auth list
เอาต์พุตจากคําสั่ง
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
เอาต์พุตจากคําสั่ง
[core] project = <PROJECT_ID>
นอกจากนี้ Cloud Shell จะตั้งค่าตัวแปรสภาพแวดล้อมโดยค่าเริ่มต้นด้วย ซึ่งอาจเป็นประโยชน์เมื่อเรียกใช้คําสั่งในอนาคต
echo $GOOGLE_CLOUD_PROJECT
เอาต์พุตจากคําสั่ง
<PROJECT_ID>
หากไม่ได้ตั้งค่าโปรเจ็กต์ไว้ด้วยเหตุผลบางประการ เพียงใช้คําสั่งต่อไปนี้
gcloud config set project <PROJECT_ID>
กําลังมองหา PROJECT_ID ของคุณอยู่ใช่ไหม โปรดดูรหัสที่คุณใช้ในขั้นตอนการตั้งค่าหรือค้นหาในแดชบอร์ดของคอนโซล

ข้อสําคัญ: สุดท้าย กําหนดโซนเริ่มต้นและการกําหนดค่าโปรเจ็กต์ดังนี้
gcloud config set compute/zone us-central1-f
คุณเลือกได้หลายโซน ดูข้อมูลเพิ่มเติมในเอกสารประกอบเกี่ยวกับภูมิภาคและภูมิภาค
หากต้องการเรียกใช้ BigQuery BigQuery ใน Codelab นี้ คุณจะต้องมีชุดข้อมูลของตนเอง เลือกชื่อ เช่น campaign_funding เรียกใช้คําสั่งต่อไปนี้ใน Shell (เช่น CloudShell)
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
หลังจากสร้างชุดข้อมูลแล้ว คุณก็พร้อมดําเนินการต่อ การเรียกใช้คําสั่งนี้จะช่วยยืนยันว่าคุณได้ตั้งค่าไคลเอ็นต์บรรทัดคําสั่ง bq อย่างถูกต้อง การตรวจสอบสิทธิ์ทํางานได้ และคุณมีสิทธิ์การเขียนสําหรับโปรเจ็กต์ระบบคลาวด์ที่คุณทํางานอยู่ หากมีมากกว่า 1 โปรเจ็กต์ ระบบจะแจ้งให้คุณเลือกโปรเจ็กต์ที่คุณสนใจจากรายการ

ชุดข้อมูลแคมเปญการเงินของคณะกรรมาธิการการเลือกตั้งสหพันธรัฐของสหรัฐอเมริกาถูกบีบอัดและคัดลอกไปยังที่เก็บข้อมูล GCS gs://campaign-funding/ แล้ว
มาดาวน์โหลดไฟล์ต้นฉบับไฟล์ใดไฟล์หนึ่งภายในเครื่อง เพื่อให้เรามองเห็นได้ เรียกใช้คําสั่งต่อไปนี้จากหน้าต่างคําสั่ง
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
โดยควรแสดงเนื้อหาของไฟล์การมีส่วนร่วมแต่ละรายการ ไฟล์ที่เราจะพิจารณาจาก Codelab นี้มี 3 ประเภท ได้แก่ การมีส่วนร่วมแต่ละรายการ (indiv*.txt) ผู้สมัคร (cn*.txt) และคณะกรรมการ (cm*.txt) หากคุณสนใจ ให้ใช้กลไกเดียวกันนี้เพื่อตรวจสอบในไฟล์อื่นๆ เหล่านั้น
เราจะไม่โหลดข้อมูลดิบลงใน BigQuery โดยตรง แต่จะค้นหาจาก Google Cloud Storage แทน เราจําเป็นต้องทราบสคีมาและข้อมูลบางอย่างก่อนดําเนินการดังกล่าว
โดยสามารถดูชุดข้อมูลได้ในเว็บไซต์การเลือกตั้งของรัฐบาลกลางที่นี่ สคีมาสําหรับตารางที่เราจะดูอยู่ ได้แก่
ในการลิงก์กับตาราง เราต้องสร้างคําจํากัดความของตารางสําหรับสคีมาที่มีสคีมา เรียกใช้คําสั่งต่อไปนี้เพื่อสร้างคําจํากัดความของตารางแต่ละรายการ
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
เปิดไฟล์ indiv_dev.json ด้วยเครื่องมือแก้ไขข้อความที่ต้องการและดูเนื้อหา ไฟล์จะมี JSON อธิบายวิธีตีความไฟล์ข้อมูล FEC
เราจําเป็นต้องแก้ไขเล็กน้อย 2 รายการในส่วน csvOptions เพิ่มค่า fieldDelimiter ของ "|" และค่า quote ของ "" (สตริงว่างเปล่า) ซึ่งจําเป็นเนื่องจากไฟล์ข้อมูลไม่ได้คั่นด้วยคอมมา แต่คั่นด้วยเครื่องหมายไปป์ ดังนี้
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
ตอนนี้ไฟล์ indiv_dev.json ควรเป็น
"fieldDelimiter": "|",
"quote":"",
เนื่องจากการสร้างคําจํากัดความของตารางสําหรับคณะกรรมการและตารางผู้สมัครคล้ายกันและสคีมามี Boilerplate ที่ดีอยู่แล้ว มาดาวน์โหลดไฟล์เหล่านั้นกัน
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
ไฟล์เหล่านี้จะมีลักษณะคล้ายกับไฟล์ indiv_dev.json โปรดทราบว่าคุณยังสามารถดาวน์โหลดไฟล์ indiv_def.json ได้เผื่อในกรณีที่มีปัญหาในการรับค่าที่ถูกต้อง
ต่อไปเราจะลิงก์ตาราง BigQuery กับไฟล์เหล่านี้จริงๆ เรียกใช้คําสั่งต่อไปนี้
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
ซึ่งจะสร้างตาราง BigQuery 3 ตาราง ได้แก่ ธุรกรรม คณะกรรมการ และผู้สมัคร คุณสามารถค้นหาตารางเหล่านี้ได้เหมือนกับตาราง BigQuery ปกติ แต่ตารางดังกล่าวไม่ได้เก็บไว้ใน BigQuery จริงๆ แต่เก็บอยู่ใน Google Cloud Storage หากคุณอัปเดตไฟล์ที่สําคัญ การอัปเดตจะมีผลในคําค้นหาที่คุณเรียกใช้ทันที
ต่อไปเราจะลองเรียกใช้การค้นหาสัก 2-3 ข้อความ เปิด UI ของเว็บ BigQuery

ค้นหาชุดข้อมูลในแผงการนําทางด้านซ้าย (คุณอาจต้องเปลี่ยนเมนูแบบเลื่อนลงของโปรเจ็กต์ที่มุมซ้ายบน) คลิกปุ่ม "ComPOSE QUERY' สีแดงขนาดใหญ่" และป้อนคําค้นหาต่อไปนี้ในช่อง
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
โดยจะแสดงเงินบริจาคจากแคมเปญ 100 ล่าสุดของพนักงานของ Google หากต้องการ ลองลองทําดูและค้นหาเงินบริจาคจากแคมเปญจากผู้พํานักอาศัยในรหัสไปรษณีย์ของคุณ หรือค้นหาเงินบริจาคที่ใหญ่ที่สุดในเมืองของคุณ
คําค้นหาและผลลัพธ์จะมีลักษณะดังนี้
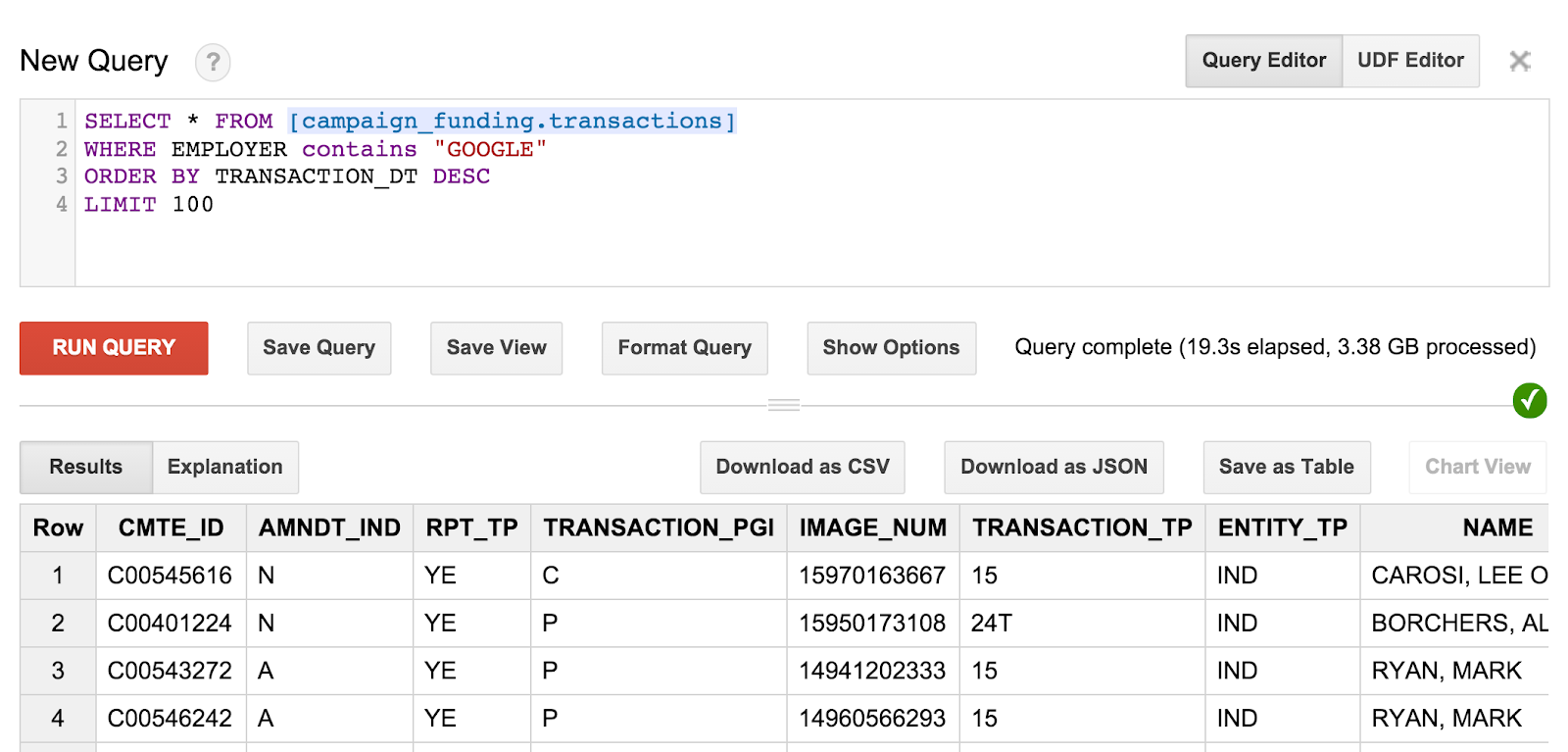
อย่างไรก็ตาม สิ่งหนึ่งที่คุณอาจสังเกตเห็นคือไม่สามารถบอกได้ว่าผู้รับคือใครจากการบริจาคเหล่านี้ เราต้องคิดคําถามสมมติขึ้นเพื่อให้ได้ข้อมูลดังกล่าว
คลิกตารางธุรกรรมในแผงด้านซ้าย แล้วคลิกแท็บสคีมา ซึ่งควรมีลักษณะดังนี้ภาพหน้าจอด้านล่าง
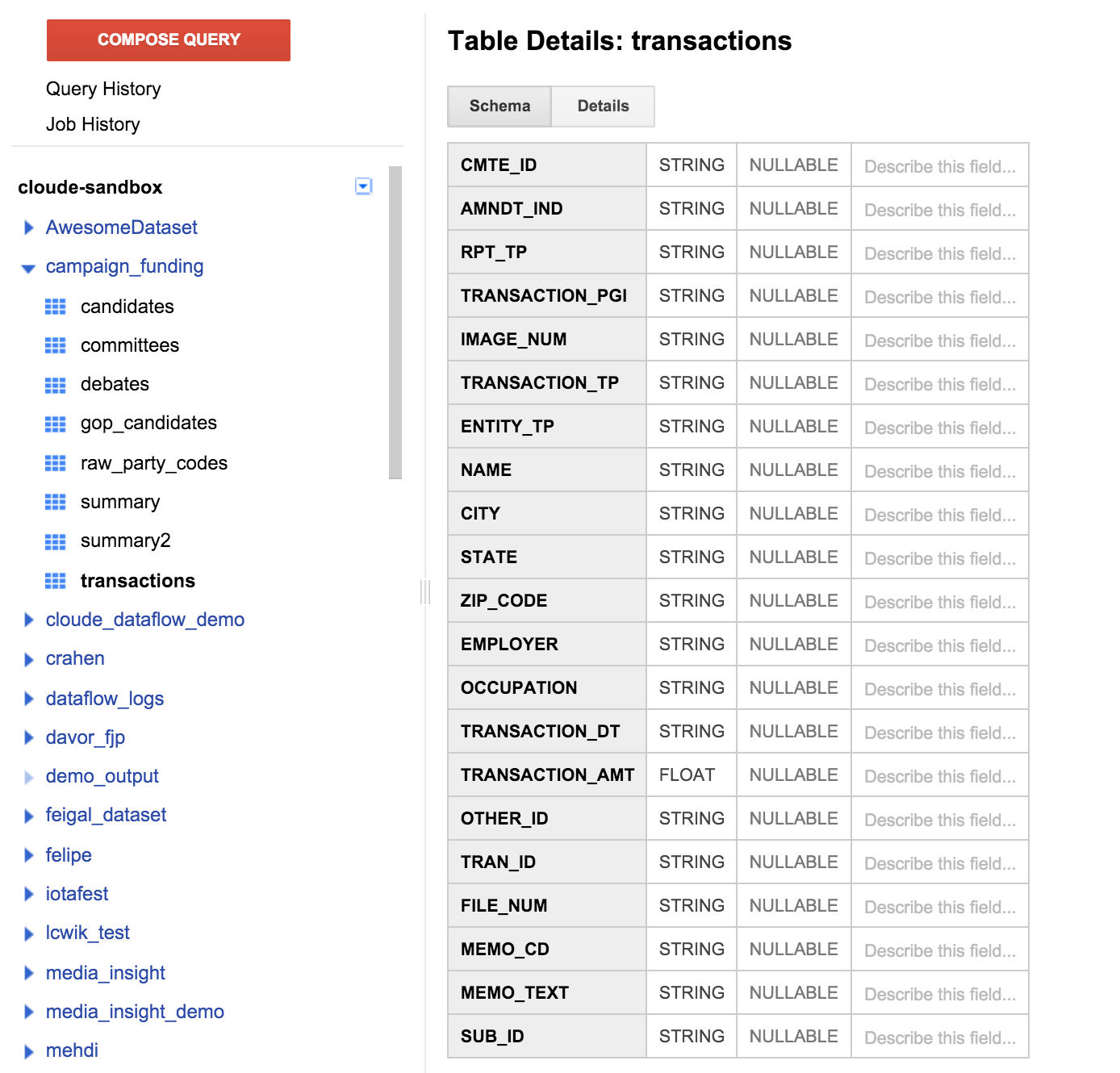
เราสามารถดูรายการของช่องที่ตรงกับคําจํากัดความของตารางที่เราระบุก่อนหน้านี้ คุณอาจสังเกตเห็นว่าไม่มีช่องสําหรับผู้รับ หรือไม่มีวิธีใดที่พิจารณาผู้สมัครที่ได้รับการสนับสนุน อย่างไรก็ตาม มีช่องชื่อ CMTE_ID ซึ่งจะทําให้เราลิงก์คณะกรรมการที่เป็นผู้รับเงินบริจาคกับเงินบริจาคได้ แต่ทั้งหมดนี้ก็ไม่มีประโยชน์นัก
จากนั้นคลิกตารางคณะกรรมการเพื่อดูสคีมา เรามี CMET_ID ซึ่งเข้าร่วมตารางธุรกรรมได้ ช่องอื่นคือ CAND_ID ซึ่งสามารถใช้ร่วมกับตาราง CAND_ID ในตารางผู้สมัคร สุดท้ายนี้ เรามีลิงก์ระหว่างธุรกรรมกับผู้สมัครโดยผ่านตารางคณะกรรมการ
โปรดทราบว่าแท็บแสดงตัวอย่างสําหรับตารางแบบ GCS ไม่มีแท็บ ##39 เนื่องจาก BigQuery จําเป็นต้องอ่านจากแหล่งข้อมูลภายนอก เพื่อที่จะอ่านข้อมูล ลองมาดูตัวอย่างข้อมูลโดยเรียกใช้คําค้นหา "SELECT *' ง่ายๆ ในตารางผู้สมัคร
SELECT * FROM [campaign_funding.candidates] LIMIT 100
ผลลัพธ์ที่ได้ควรมีลักษณะดังนี้
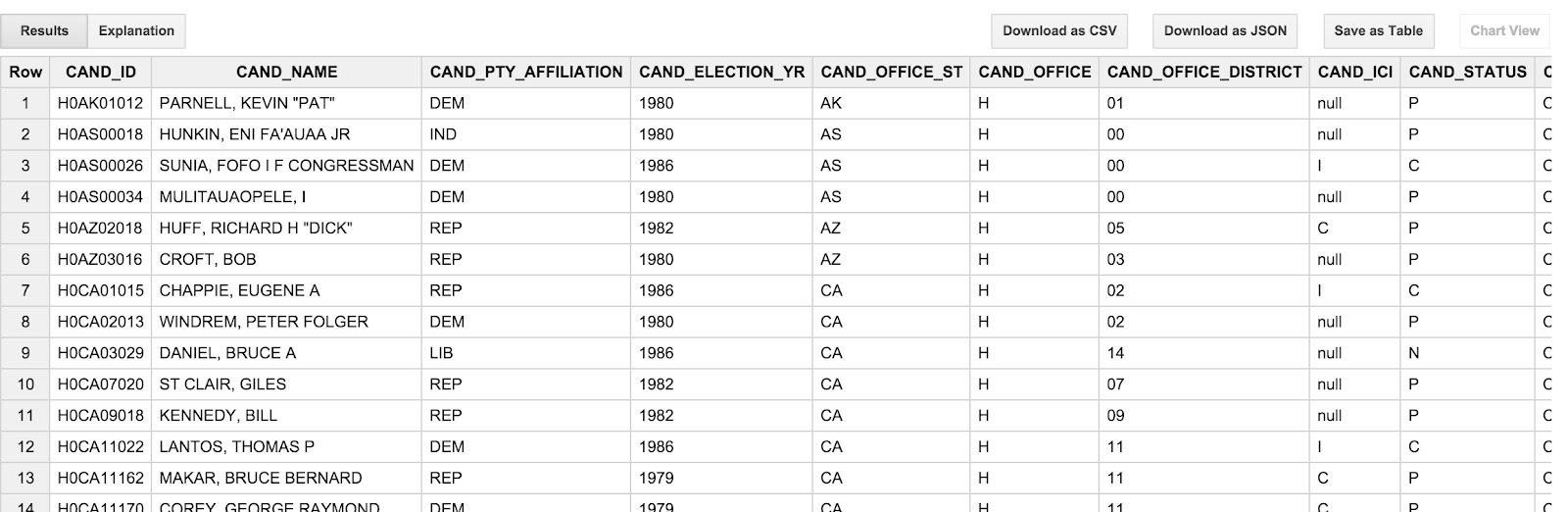
สิ่งหนึ่งที่คุณอาจสังเกตคือ ชื่อผู้สมัครคือตัวพิมพ์ใหญ่ทั้งหมด และจะแสดงในรูปแบบ "lastname, firstname" ตามลําดับ จะน่ารําคาญสักหน่อย เพราะเราไม่ได้คิดแบบนั้นเกี่ยวกับผู้สมัคร เพราะเรามักเห็น "Brack โอบามา; มากกว่า "OBAMA, BARACK" นอกจากนี้ วันที่ทําธุรกรรม (TRANSACTION_DT) ในตารางธุรกรรมก็ดูแปลกไปเล็กน้อย โดยจะเป็นค่าสตริงในรูปแบบ YYYYMMDD เราจะพูดถึงเรื่องที่ไม่น่ารู้เหล่านี้ในส่วนถัดไป
เมื่อเข้าใจแล้วว่าธุรกรรมมีความเกี่ยวข้องกับผู้สมัครอย่างไร เรามาตอบคําถามกันเพื่อดูว่าใครให้เงินกับใคร ตัดและวางคําค้นหาต่อไปนี้ลงในช่องเขียน
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
การค้นหานี้จะนําตารางธุรกรรมไปใช้กับตารางคณะกรรมการ จากนั้นไปยังตารางผู้สมัคร โดยจะดูเฉพาะธุรกรรมจากคนที่มีคําว่า "ENGINEER" ในชื่ออาชีพ การค้นหาจะรวบรวมผลลัพธ์ตามความเกี่ยวข้องของพรรคการเมือง ซึ่งช่วยให้เราเห็นการกระจายเงินบริจาคไปยังพรรคการเมืองต่างๆ ระหว่างวิศวกรได้
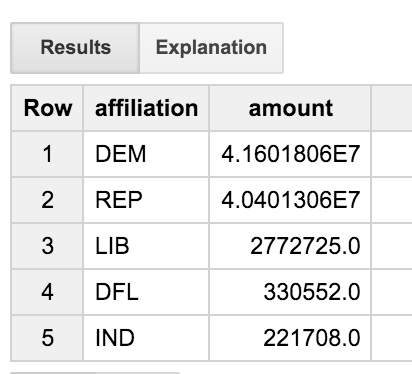
เราพบว่าวิศวกรจํานวนมากกําลังสร้างสมดุลกัน ทําให้ทุกคนมีข้อมูลเกี่ยวกับประชาธิปไตยและประชาธิปไตยมากขึ้น แต่พรรค "DFL' คืออะไร" คงจะดีไม่น้อยถ้าการได้ชื่อเต็มนั้นแทนที่จะใช้แค่ตัวอักษร 3 ตัว
รหัสปาร์ตี้มีดังต่อไปนี้ในเว็บไซต์ FEC มีตารางที่ตรงกับรหัสปาร์ตี้ตรงกับชื่อเต็ม (ปรากฏว่า "DFL' คือ "Democratic-Farmer-Labor') แม้ว่าเราจะสามารถแปลคําแปลของเราในข้อความค้นหาได้ด้วยตัวเอง แต่ก็ดูเป็นงานหนักและใช้การซิงค์ได้ยาก
จะเกิดอะไรขึ้นหากเราแยกวิเคราะห์ HTML เป็นส่วนหนึ่งของการค้นหาได้ คลิกขวาที่ใดก็ได้ในหน้านั้นแล้วดูที่ "ดูแหล่งที่มาของหน้า" มีข้อมูลส่วนหัว / Boilerplate จํานวนมากในแหล่งที่มา แต่ค้นหาแท็ก <table> ได้ แถวการแมปแต่ละแถวอยู่ในองค์ประกอบ <tr> ของ HTML ชื่อและโค้ดจะรวมอยู่ด้วยในองค์ประกอบ <td> แต่ละแถวจะมีลักษณะดังนี้
HTML จะมีลักษณะดังนี้
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
โปรดทราบว่า BigQuery อ่านไฟล์จากเว็บโดยตรงไม่ได้ เนื่องจาก BigQuery รองรับ Hit จากแหล่งที่มาของผู้ปฏิบัติงานหลายพันคนได้พร้อมกัน หากหน้าเว็บประเภทนี้ได้รับอนุญาตให้ทํางานกับหน้าเว็บแบบสุ่ม อาจจะเป็นการโจมตีแบบปฏิเสธการให้บริการแบบกระจาย (DDoS) ไฟล์ HTML จากหน้าเว็บ FEC จะเก็บไว้ในที่เก็บข้อมูล gs://campaign-funding
และเราจะต้องสร้างตารางตามข้อมูลการระดมทุนของแคมเปญ ซึ่งคล้ายกับตารางอื่นๆ ที่รองรับ GCS ที่เราสร้างไว้ ความแตกต่างคือเราไม่มีสคีมาจริงๆ แต่เราจะใช้ช่องเพียงช่องเดียวและเรียกว่า "data'" เราจะสมมติว่าเป็นไฟล์ CSV โดยแทนที่เครื่องหมายคอมมา (ตัวคั่น) โดยจะใช้อักขระปลอม (`) และไม่มีอักขระอัญประกาศ
หากต้องการสร้างตารางการค้นหาปาร์ตี้ ให้เรียกใช้คําสั่งต่อไปนี้จากบรรทัดคําสั่ง
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
ตอนนี้เราจะใช้ JavaScript เพื่อแยกวิเคราะห์ไฟล์ ที่ด้านบนขวาของตัวแก้ไขคําค้นหา BigQuery ควรเป็นปุ่มที่มีป้ายกํากับ "UDF Editor" คลิกเพื่อเปลี่ยนเป็นการแก้ไข UDF ของ JavaScript ระบบจะป้อนข้อมูลเครื่องมือแก้ไข UDF พร้อมข้อความสําเร็จรูปบางส่วนที่คุณแสดงความคิดเห็นไว้

ดําเนินการลบโค้ดที่มีอยู่และป้อนรหัสต่อไปนี้
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
JavaScript ที่นี่แบ่งออกเป็น 2 ส่วน ส่วนแรกคือฟังก์ชันที่ใช้แถวอินพุตส่งเอาต์พุตที่แยกวิเคราะห์แล้ว อีกคําจํากัดความคือคําจํากัดความซึ่งลงทะเบียนฟังก์ชันดังกล่าวเป็น User Function (UDF) ที่มีชื่อว่า tableParser ซึ่งใช้เป็นคอลัมน์อินพุตชื่อ "data'" และจะแสดงผลคอลัมน์ 2 คอลัมน์ โค้ด และชื่อ คอลัมน์รหัสจะเป็นรหัสแบบ 3 ตัวอักษร คอลัมน์ชื่อนี้จะเป็นชื่อเต็มของฝ่าย
กลับไปยังแท็บ "Query Editor" และป้อนคําค้นหาต่อไปนี้
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
การเรียกใช้การค้นหานี้จะแยกวิเคราะห์ไฟล์ HTML ดิบ และส่งค่าของช่องในรูปแบบที่มีโครงสร้าง เจ๋งเลยจริงไหม มาดูกันว่าคุณ "DFL'" ย่อมาจากอะไร
ทีนี้เราจะแปลโค้ดงานเลี้ยงให้เป็นชื่อได้แล้ว ลองใช้คําถามอื่นที่ช่วยค้นหาสิ่งที่น่าสนใจ เรียกใช้การค้นหาต่อไปนี้
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
การค้นหานี้จะแสดงผู้สมัครที่ได้รับเงินบริจาคมากที่สุดและสะกดคําเป็นพาร์ทเนอร์ที่เกี่ยวข้อง
ตารางเหล่านี้ไม่ใหญ่มากและใช้เวลา 30 วินาทีในการค้นหาโดยประมาณ หากจะใช้งานตารางต่างๆ เป็นจํานวนมาก คุณอาจจะต้องนําเข้าตารางไปยัง BigQuery คุณเรียกใช้คําค้นหา ETL กับตารางเพื่อบังคับให้ข้อมูลรวมไว้ด้วยวิธีง่ายๆ แล้วบันทึกเป็นตารางถาวรได้ ซึ่งหมายความว่าคุณไม่ต้องอย่าลืมว่าต้องแปลโค้ดปาร์ตี้ทุกครั้ง ทั้งยังสามารถกรองข้อมูลที่ผิดพลาดออกขณะดําเนินการได้ด้วย
คลิกปุ่ม "แสดงตัวเลือก" แล้วคลิกปุ่ม "เลือกตาราง' ติดกับป้ายกํากับ "Destination Table" เลือกชุดข้อมูล campaign_funding และป้อนรหัสตารางเป็น "summary' เลือกช่องทําเครื่องหมาย "allow large results'

แล้วเรียกใช้การค้นหาต่อไปนี้
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
การค้นหานี้ใช้เวลานานขึ้นมากและมีตัวเลือกการล้างข้อมูลเพิ่มเติม เช่น แอปจะละเว้นทุกสิ่งที่จํานวนเงินมากกว่า $1 ล้าน และยังใช้นิพจน์ทั่วไปเพื่อเปลี่ยน "LASTNAME, FIRSTNAME" เป็น "FIRSTNAME LASTNAME" หากรู้สึกอยากลองอะไรใหม่ๆ ให้ลองเขียน UDF ให้ดียิ่งขึ้นไปอีกและแก้ไขการใช้อักษรตัวพิมพ์ใหญ่ (เช่น "Firstname Lastname")
สุดท้าย ลองเรียกใช้คําค้นหา 2-3 รายการกับตาราง campaign_funding.summary เพื่อยืนยันว่าคําค้นหาในตารางดังกล่าวเร็วขึ้น อย่าลืมนําตัวเลือกการค้นหาตารางปลายทางออกก่อน มิฉะนั้นระบบอาจเขียนทับตารางสรุป
คุณได้ล้างและนําเข้าข้อมูลจากเว็บไซต์ FEC ไปยัง BigQuery แล้ว
สิ่งที่เราพูดถึง
- ใช้ตารางที่มี GCS ใน BigQuery
- การใช้ฟังก์ชันที่ผู้ใช้กําหนดใน BigQuery
ขั้นตอนถัดไป
- ลองใช้คําค้นหาที่น่าสนใจเพื่อหาผู้ที่ให้เงินสนับสนุนรอบการเลือกตั้งนี้
ดูข้อมูลเพิ่มเติม
- ดูข้อมูลเพิ่มเติมเกี่ยวกับสิ่งที่คุณทําได้ด้วยฟังก์ชันที่ผู้ใช้กําหนด
- อ่านเกี่ยวกับแหล่งข้อมูลแบบรวมศูนย์(รวมถึง GCS)
- โพสต์คําถามและค้นหาคําตอบใน Stackflow โดยใช้แท็ก google-bigquery
แสดงความคิดเห็น
- โปรดใช้ลิงก์ที่ด้านซ้ายล่างของหน้านี้เพื่อรายงานปัญหาหรือแชร์ความคิดเห็น