
В этой лаборатории кода вы узнаете, как использовать некоторые дополнительные функции BigQuery, в том числе:
- Пользовательские функции в JavaScript
- Секционированные таблицы
- Прямые запросы к данным, хранящимся в Google Cloud Storage и Google Drive.
Вы возьмете данные Федеральной избирательной комиссии США, очистите их и загрузите в BigQuery. У вас также будет возможность задать несколько интересных вопросов об этом наборе данных.
Хотя эта лаборатория кода не предполагает никакого предыдущего опыта работы с BigQuery, некоторое понимание SQL поможет вам извлечь из нее больше пользы.
Что вы узнаете
- Как использовать пользовательские функции JavaScript для выполнения операций, которые сложно выполнить в SQL.
- Как использовать BigQuery для выполнения операций ETL (извлечение, преобразование, загрузка) с данными, которые находятся в других хранилищах данных, таких как Google Cloud Storage и Google Drive.
Что вам понадобится
- Облачный проект Google с включенным выставлением счетов.
- Ведро облачного хранилища Google
- Google Cloud SDK установлен
Как вы будете использовать этот учебник?
Как бы вы оценили свой уровень опыта работы с BigQuery?
Самостоятельная настройка среды
Если у вас еще нет учетной записи Google (Gmail или Google Apps), вы должны создать ее. Войдите в консоль Google Cloud Platform ( console.cloud.google.com ) и создайте новый проект:



Запомните идентификатор проекта, уникальное имя для всех проектов Google Cloud (имя выше уже занято и не будет работать для вас, извините!). Позже в этой кодовой лаборатории он будет упоминаться как PROJECT_ID .
Затем вам нужно включить выставление счетов в облачной консоли, чтобы использовать ресурсы Google Cloud.
Прохождение этой кодовой лаборатории не должно стоить вам больше нескольких долларов, но может стоить больше, если вы решите использовать больше ресурсов или оставите их работающими (см. раздел «Очистка» в конце этого документа).
Новые пользователи Google Cloud Platform имеют право на бесплатную пробную версию стоимостью 300 долларов США .
Облачная оболочка Google
Хотя Google Cloud и Big Query можно управлять удаленно с вашего ноутбука, в этой кодовой лаборатории мы будем использовать Google Cloud Shell , среду командной строки, работающую в облаке.
Эта виртуальная машина на основе Debian загружена всеми необходимыми инструментами разработки. Он предлагает постоянный домашний каталог размером 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Это означает, что все, что вам нужно для этой лаборатории кода, — это браузер (да, он работает на Chromebook).
Чтобы активировать Google Cloud Shell, в консоли разработчика просто нажмите кнопку в правом верхнем углу (подготовка и подключение к среде займет всего несколько минут):

Нажмите кнопку «Запустить Cloud Shell»:


После подключения к облачной оболочке вы должны увидеть, что вы уже прошли аутентификацию и что проект уже настроен на ваш PROJECT_ID :
gcloud auth list
Вывод команды
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Вывод команды
[core] project = <PROJECT_ID>
Cloud Shell также устанавливает некоторые переменные среды по умолчанию, которые могут быть полезны при выполнении будущих команд.
echo $GOOGLE_CLOUD_PROJECT
Вывод команды
<PROJECT_ID>
Если по какой-то причине проект не установлен, просто введите следующую команду:
gcloud config set project <PROJECT_ID>
Ищете свой PROJECT_ID ? Проверьте, какой идентификатор вы использовали на этапах настройки, или найдите его на панели управления консоли:

ВАЖНО: Наконец, установите зону по умолчанию и конфигурацию проекта:
gcloud config set compute/zone us-central1-f
Вы можете выбрать множество различных зон. Подробнее читайте в документации по регионам и зонам .
Чтобы выполнять запросы BigQuery в этой лаборатории кода, вам понадобится собственный набор данных. Выберите для него имя, например, campaign_funding . Запустите следующие команды в вашей оболочке (например, CloudShell):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created. После создания набора данных вы должны быть готовы к работе. Выполнение этой команды также должно помочь убедиться, что вы правильно настроили клиент командной строки bq , аутентификация работает и у вас есть доступ на запись к облачному проекту, в котором вы работаете. Если у вас более одного проекта, вам будет предложено выбрать интересующий вас из списка.

Набор данных о финансировании избирательных кампаний Федеральной избирательной комиссии США был распакован и скопирован в корзину GCS gs://campaign-funding/ .
Давайте скачаем один из исходных файлов локально, чтобы увидеть, как он выглядит. Запустите следующие команды из командного окна:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
Это должно отображать содержимое файла отдельных вкладов. Есть три типа файлов, которые мы рассмотрим в этой лаборатории кода: отдельные вклады ( indiv*.txt ), кандидаты ( cn*.txt ) и комитеты ( cm*.txt ). Если вам интересно, используйте тот же механизм, чтобы проверить, что находится в этих других файлах.
Мы не собираемся загружать необработанные данные напрямую в BigQuery; вместо этого мы собираемся запросить его из Google Cloud Storage. Для этого нам нужно знать схему и некоторую информацию о ней.
Набор данных описан на сайте федеральных выборов здесь . Схемы для таблиц, которые мы рассмотрим:
Чтобы связать таблицы, нам нужно создать для них определение таблицы, включающее схемы. Выполните следующие команды, чтобы сгенерировать определения отдельных таблиц:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
Откройте файл indiv_dev.json в своем любимом текстовом редакторе и просмотрите его содержимое. он будет содержать json, описывающий, как интерпретировать файл данных FEC.
Нам нужно будет внести два небольших изменения в раздел csvOptions . Добавьте значение fieldDelimiter «|» и значение quote "" (пустая строка). Это необходимо, потому что файл данных на самом деле не разделен запятыми, он разделен вертикальной чертой:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
Теперь файл indiv_dev.json должен выглядеть так:
"fieldDelimiter": "|",
"quote":"", Поскольку создание определений таблиц для комитетов и таблиц-кандидатов аналогично, а схема содержит приличную часть шаблонов, давайте просто загрузим эти файлы.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
Эти файлы будут похожи на файл indiv_dev.json . Обратите внимание, что вы также можете загрузить файл indiv_def.json на случай, если у вас возникнут проблемы с получением правильных значений.
Далее давайте на самом деле свяжем таблицу BigQuery с этими файлами. Выполните следующие команды:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.Это создаст три таблицы bigquery: транзакции, комитеты и кандидаты. Вы можете запрашивать эти таблицы, как если бы они были обычными таблицами BigQuery, но на самом деле они хранятся не в BigQuery, а в Google Cloud Storage. Если вы обновите базовые файлы, обновления будут немедленно отражены в выполняемых вами запросах.
Далее, давайте попробуем запустить пару запросов. Откройте веб-интерфейс BigQuery .

Найдите свой набор данных на левой панели навигации (возможно, вам придется изменить раскрывающийся список проекта в верхнем левом углу), нажмите большую красную кнопку «СОСТАВИТЬ ЗАПРОС» и введите в поле следующий запрос:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
Это позволит найти последние 100 пожертвований кампании сотрудниками Google. Если хотите, попробуйте поиграть и найти пожертвования кампании от жителей вашего почтового индекса или найти самые большие пожертвования в вашем городе.
Запрос и результаты будут выглядеть примерно так:
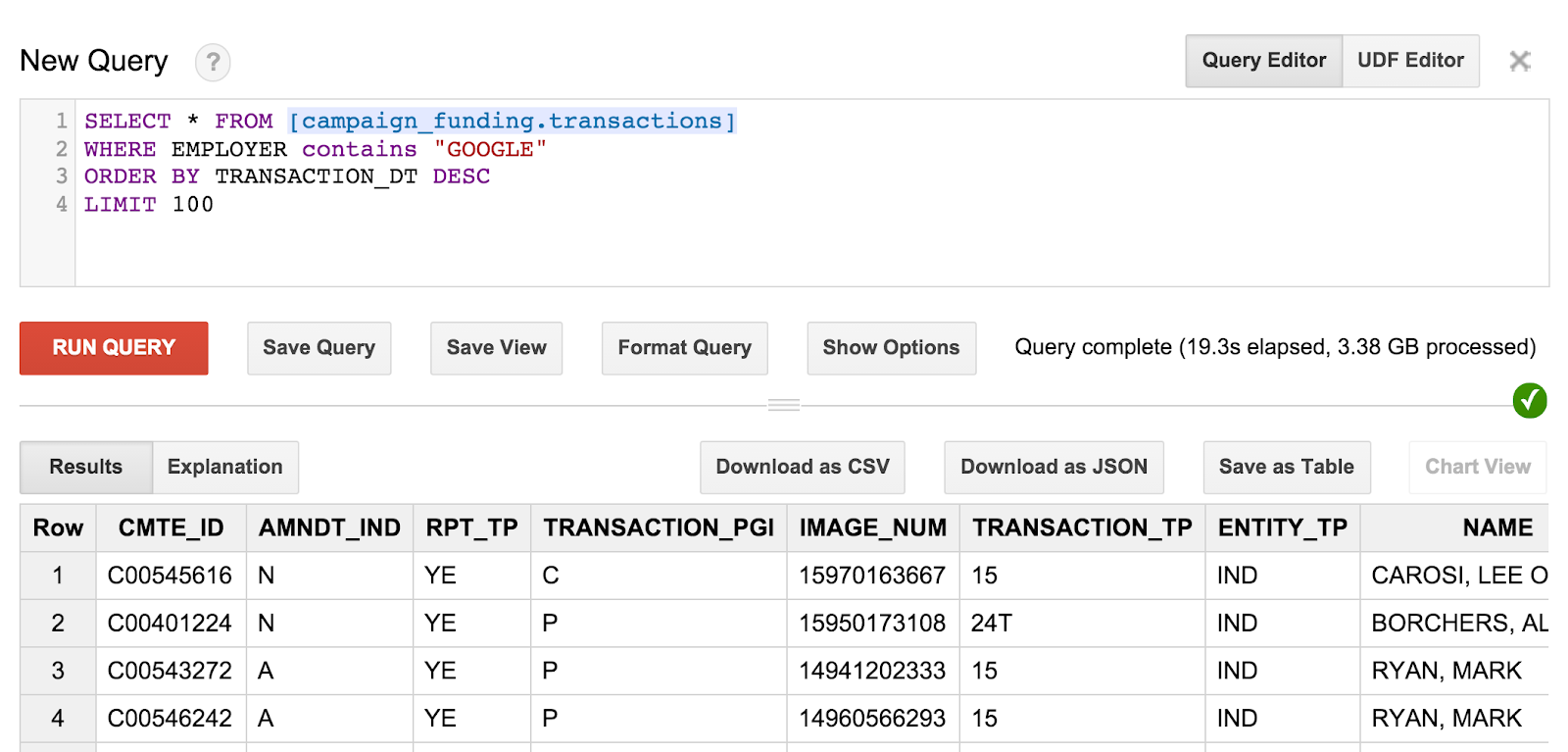
Однако вы можете заметить одну вещь: вы не можете точно сказать, кто был получателем этих пожертвований. Нам нужно придумать несколько более сложных запросов, чтобы получить эту информацию.
Щелкните таблицу транзакций на левой панели и щелкните вкладку схемы. Это должно выглядеть как на скриншоте ниже:
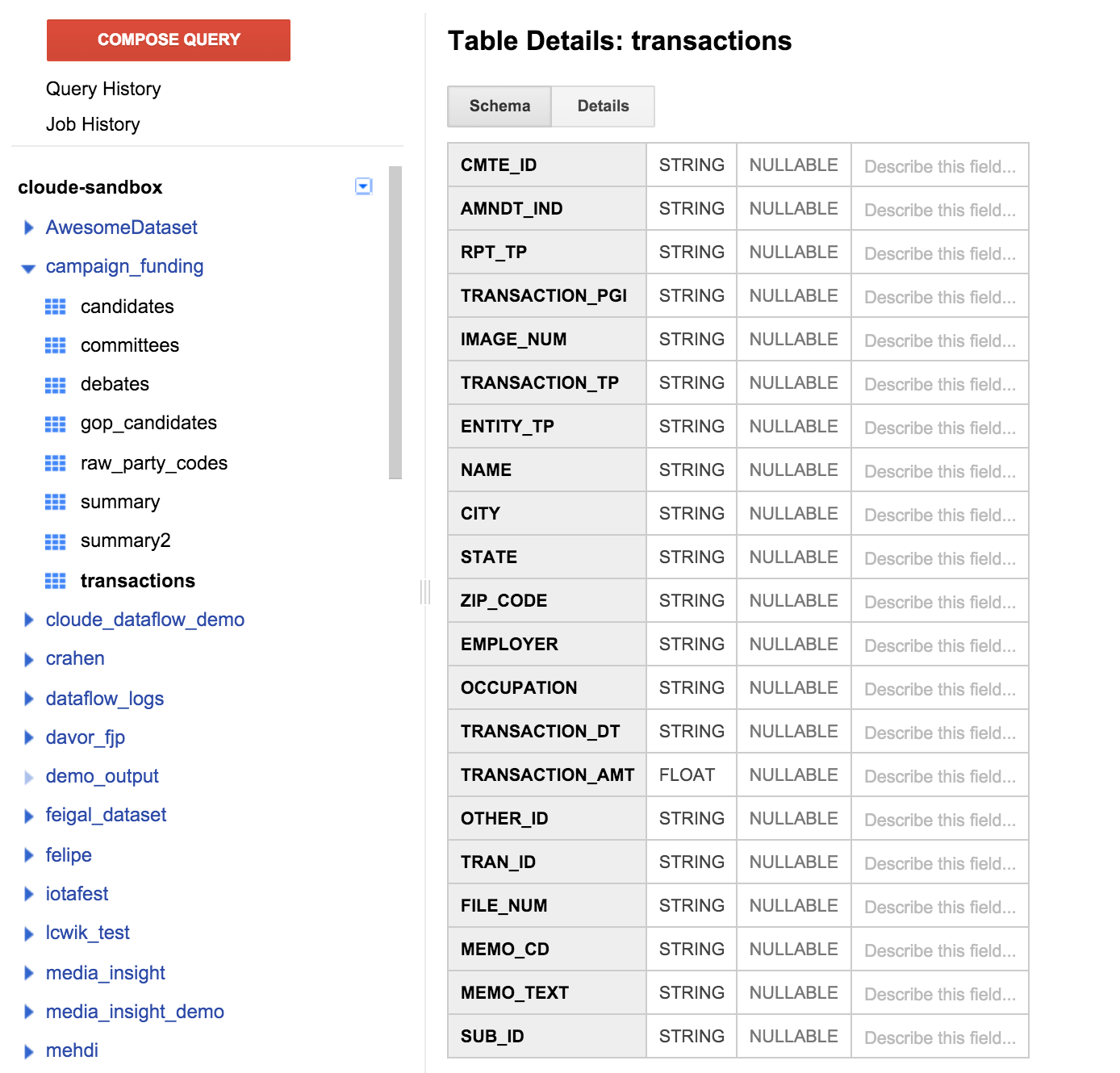
Мы можем увидеть список полей, которые соответствуют определению таблицы, которое мы указали ранее. Вы можете заметить, что здесь нет поля получателя или какого-либо способа выяснить, какого кандидата поддержало пожертвование. Однако есть поле под названием CMTE_ID . Это позволит нам связать комитет, который был получателем пожертвования, с пожертвованием. Это еще не все, что полезно.
Затем щелкните таблицу комитетов, чтобы проверить ее схему. У нас есть CMET_ID , который может присоединиться к нам в таблице транзакций. Другое поле CAND_ID ; это может быть объединено с таблицей CAND_ID в таблице кандидатов. Наконец, у нас есть связь между транзакциями и кандидатами, просматривая таблицу комитетов.
Обратите внимание, что для таблиц на основе GCS нет вкладки предварительного просмотра. Это связано с тем, что для чтения данных BigQuery требуется чтение из внешнего источника данных. Давайте получим образец данных, выполнив простой запрос SELECT * к таблице кандидатов.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
Результат должен выглядеть примерно так:
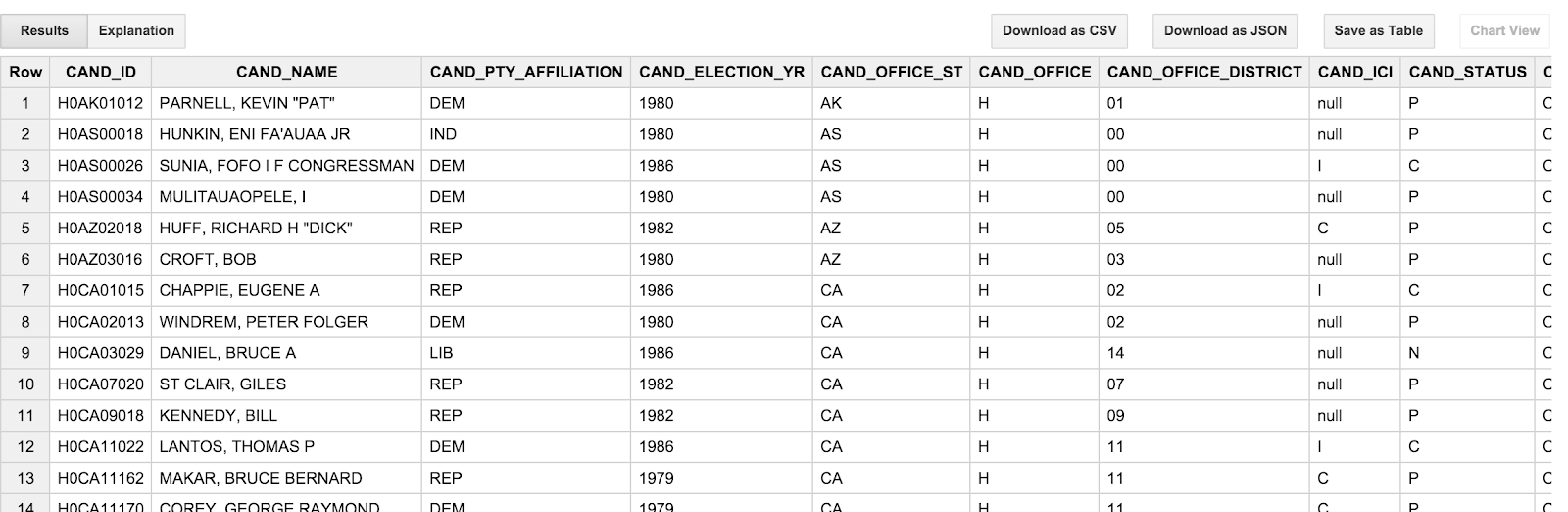
Одна вещь, которую вы можете заметить, это то, что имена кандидатов написаны ЗАГЛАВНЫМИ БУКВАМИ и представлены в порядке «фамилия, имя». Это немного раздражает, поскольку на самом деле мы не так думаем о кандидатах; мы бы скорее увидели «Барак Обаму», чем «ОБАМА, БАРАК». Более того, даты транзакций ( TRANSACTION_DT ) в таблице транзакций также немного неудобны. Это строковые значения в формате YYYYMMDD . Мы рассмотрим эти особенности в следующем разделе.
Теперь, когда у нас есть понимание того, как транзакции связаны с кандидатами, давайте запустим запрос, чтобы выяснить, кто кому дает деньги. Вырежьте и вставьте следующий запрос в поле создания:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC Этот запрос соединяет таблицу транзакций с таблицей комитетов, а затем с таблицей кандидатов. Он рассматривает транзакции только от людей со словом " ENGINEER " в названии их профессии. Запрос агрегирует результаты по партийной принадлежности; это позволяет нам увидеть распределение пожертвований различным политическим партиям среди инженеров.
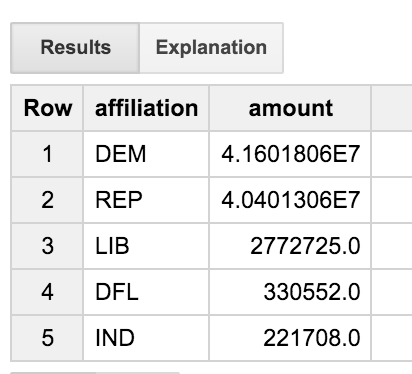
Мы видим, что инженеры представляют собой довольно уравновешенную группу, более или менее поровну отдающую демократам и республиканцам. Но что такое партия «ДФЛ»? Было бы неплохо получить полные имена, а не просто трехбуквенный код?
Партийные коды указаны на веб-сайте FEC . Есть таблица, в которой код партии соответствует полному названию (оказывается, что «ДФЛ» — это «Демократическая-Фермерская-Трудовая»). Хотя мы могли бы вручную выполнять переводы в нашем запросе, это кажется большой работой, и ее сложно синхронизировать.
Что, если бы мы могли анализировать HTML как часть запроса? Щелкните правой кнопкой мыши в любом месте этой страницы и посмотрите «просмотреть исходный код страницы». В исходнике много информации о заголовке/шаблоне, но найдите <table> . Каждая строка сопоставления находится в элементе HTML <tr> , имя и код заключены в элементы <td> . Каждая строка будет выглядеть примерно так:
HTML выглядит примерно так:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
Обратите внимание, что BigQuery не может прочитать файл напрямую из Интернета. это потому, что bigquery способен одновременно обращаться к источнику от тысяч рабочих процессов. Если бы это было разрешено для случайных веб-страниц, это, по сути, была бы распределенная атака типа «отказ в обслуживании» (DDoS). HTML-файл с веб-страницы FEC хранится в gs://campaign-funding .
Нам нужно будет составить таблицу на основе данных о финансировании кампании. Это будет похоже на другие таблицы, поддерживаемые GCS, которые мы создали. Разница здесь в том, что у нас на самом деле нет схемы; мы просто будем использовать одно поле для каждой строки и назовем его « data ». Мы притворимся, что это CSV-файл, но вместо разделителей-запятых мы будем использовать фиктивный разделитель ( ` ) и не будем использовать символ кавычек.
Чтобы создать таблицу поиска участников, выполните следующие команды из командной строки:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.Теперь мы будем использовать javascript для разбора файла. В правом верхнем углу редактора запросов BigQuery должна быть кнопка с надписью «Редактор UDF». Нажмите на нее, чтобы переключиться на редактирование пользовательской функции javascript. Редактор UDF будет заполнен некоторым закомментированным шаблоном.

Идите вперед и удалите код, который он содержит, и введите следующий код:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
JavaScript здесь разделен на две части; первая — это функция, которая принимает строку ввода и выдает проанализированный вывод. Другое — это определение, которое регистрирует эту функцию как определяемую пользователем функцию (UDF) с именем tableParser и указывает, что она принимает входной столбец с именем « data » и выводит два столбца, код и имя. В столбце кода будет трехбуквенный код, в столбце имени — полное название партии.
Вернитесь на вкладку «Редактор запросов» и введите следующий запрос:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
Выполнение этого запроса проанализирует необработанный файл HTML и выведет значения полей в структурированном формате. Довольно ловко, а? Посмотрите, сможете ли вы понять, что означает «DFL».
Теперь, когда мы можем преобразовать коды вечеринок в имена, давайте попробуем другой запрос, который использует это, чтобы узнать что-то интересное. Запустите следующий запрос:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100Этот запрос покажет, какие кандидаты получили самые большие пожертвования на предвыборную кампанию, и укажет их партийную принадлежность.
Эти таблицы не очень большие, и их запрос занимает около 30 секунд. Если вы собираетесь много работать с таблицами, вы, вероятно, захотите импортировать их в BigQuery. Вы можете запустить ETL-запрос к таблице, чтобы привести данные к чему-то простому в использовании, а затем сохранить их как постоянную таблицу. Это означает, что вам не всегда нужно помнить, как переводить партийные коды, и вы также можете отфильтровать ошибочные данные, пока делаете это.
Нажмите кнопку «Показать параметры», а затем кнопку «Выбрать таблицу» рядом с меткой « Destination Table ». Выберите набор данных campaign_funding и введите идентификатор таблицы как « summary ». Установите флажок « allow large results ».

Теперь выполните следующий запрос:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0 Этот запрос значительно длиннее и имеет некоторые дополнительные параметры очистки. Например, он игнорирует все, где сумма превышает 1 миллион долларов. Он также использует регулярные выражения для преобразования " LASTNAME, FIRSTNAME " в " FIRSTNAME LASTNAME ". Если вы чувствуете себя авантюрно, попробуйте написать UDF, чтобы сделать его еще лучше, и исправить использование заглавных букв (например, « Firstname Lastname »).
Наконец, попробуйте выполнить пару запросов к таблице campaign_funding.summary , чтобы убедиться, что запросы к этой таблице выполняются быстрее. Не забудьте сначала удалить параметр запроса таблицы назначения, иначе вы можете перезаписать сводную таблицу!
Вы очистили и импортировали данные с сайта FEC в BigQuery!
Что мы рассмотрели
- Использование таблиц с поддержкой GCS в BigQuery.
- Использование пользовательских функций в BigQuery.
Следующие шаги
- Попробуйте выполнить несколько интересных запросов, чтобы узнать, кто кому дает деньги в этом избирательном цикле.
Учить больше
- Узнайте больше о том, что вы можете делать с пользовательскими функциями .
- Прочтите о федеративных источниках данных (включая GCS).
- Публикуйте вопросы и находите ответы на Stackoverflow под тегом google-bigquery .
Дайте нам свой отзыв
- Не стесняйтесь использовать ссылку в левом нижнем углу этой страницы, чтобы сообщать о проблемах или делиться отзывами!