
Neste codelab, você aprenderá a usar alguns recursos avançados do BigQuery, incluindo:
- Funções definidas pelo usuário em JavaScript
- Tabelas particionadas
- Faça consultas diretas nos dados do Google Cloud Storage e no Google Drive.
Você usará os dados da Comissão Eleitoral Federal dos EUA, limpará esses dados e os carregará no BigQuery. Você também terá a chance de fazer algumas perguntas interessantes sobre o conjunto de dados.
Embora este codelab não presuma nenhuma experiência anterior com o BigQuery, algum conhecimento de SQL ajudará você a aproveitá-lo melhor.
O que você vai aprender
- Como usar funções definidas pelo usuário do JavaScript para executar operações difíceis de executar em SQL.
- usar o BigQuery para realizar operações ETL (Extrair, Transformar e carregar) de dados que estão em outros armazenamentos de dados, como o Google Cloud Storage e o Google Drive;
Pré-requisitos
- um projeto do Google Cloud com faturamento ativado
- Um bucket do Google Cloud Storage
- SDK do Google Cloud instalado
Como você usará este tutorial?
Como você classificaria seu nível de experiência com o BigQuery?
Configuração de ambiente personalizada
Se você ainda não tem uma Conta do Google (Gmail ou Google Apps), crie uma. Faça login no Console do Google Cloud Platform (console.cloud.google.com) e crie um novo projeto:



Lembre-se do código do projeto, um nome exclusivo em todos os projetos do Google Cloud. O nome acima já foi escolhido e não servirá para você. Faremos referência a ele mais adiante neste codelab como PROJECT_ID.
Em seguida, você precisará ativar o faturamento no Console do Cloud para usar os recursos do Google Cloud.
A execução por meio deste codelab terá um custo baixo, mas poderá ser mais se você decidir usar mais recursos ou se deixá-los em execução. Consulte a seção "limpeza" no final deste documento.
Novos usuários do Google Cloud Platform estão qualificados para um teste sem custo financeiro de US$ 300.
Google Cloud Shell
O Google Cloud e o Big Query podem ser operados remotamente no seu laptop, mas usaremos Google Cloud Shell, um ambiente de linha de comando executado no Cloud neste codelab.
O Cloud Shell é uma máquina virtual com base em Debian que contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal permanente de 5 GB, além de ser executada no Google Cloud, o que aprimora o desempenho e a autenticação da rede. Isso significa que tudo que você precisa para este codelab é um navegador (sim, funciona em um Chromebook).
Para ativar o Google Cloud Shell, no console do desenvolvedor, clique no botão no canto superior direito (só leva alguns instantes para provisionar e se conectar ao ambiente):

Clique no botão "Iniciar o Cloud Shell":


Depois que você se conectar ao Cloud Shell, sua autenticação já terá sido feita, e o projeto estará definido com o PROJECT_ID:
gcloud auth list
Resposta ao comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Resposta ao comando
[core] project = <PROJECT_ID>
O Cloud Shell também define algumas variáveis de ambiente por padrão, que podem ser úteis à medida que você executa comandos futuros.
echo $GOOGLE_CLOUD_PROJECT
Resposta ao comando
<PROJECT_ID>
Se, por algum motivo, o projeto não estiver definido, basta emitir o seguinte comando :
gcloud config set project <PROJECT_ID>
Quer encontrar seu PROJECT_ID? Confira o ID usado nas etapas de configuração ou procure no painel do console:

IMPORTANTE: por fim, defina a zona padrão e a configuração do projeto:
gcloud config set compute/zone us-central1-f
É possível escolher uma variedade de zonas diferentes. Saiba mais na documentação "Regiões e zonas".
Para executar as consultas do BigQuery neste codelab, você precisará do seu próprio conjunto de dados. Escolha um nome para ela, como campaign_funding. Execute os seguintes comandos no shell (Cloud Shell, por exemplo):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
Depois que seu conjunto de dados for criado, você provavelmente estará pronto. A execução deste comando também ajuda a verificar se você configurou corretamente o cliente da linha de comando bq, se a autenticação está funcionando e se você tem acesso de gravação ao projeto de nuvem em que está operando. Se você tiver mais de um projeto, precisará selecionar em uma lista aquele em que tem interesse.

O conjunto de dados de finanças da campanha da Comissão Eleitoral Federal dos EUA foi descompactado e copiado para o bucket gs://campaign-funding/ do GCS.
Vamos fazer o download de um dos arquivos de origem localmente para vermos como ele é. Execute os seguintes comandos em uma janela de comando:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
Isso exibirá o conteúdo do arquivo de contribuições. Vamos ver três tipos de arquivos neste codelab: contribuições individuais (indiv*.txt), candidatos (cn*.txt) e comitês (cm*.txt). Se você tiver interesse, use o mesmo mecanismo para conferir o que há nesses outros arquivos.
Não vamos carregar os dados brutos diretamente no BigQuery. Em vez disso, vamos consultá-los a partir do Google Cloud Storage. Para isso, precisamos conhecer o esquema e algumas informações sobre ele.
O conjunto de dados está descrito no site da eleição federal aqui. Os esquemas das tabelas que veremos são:
Para vincular as tabelas, precisamos criar uma definição de tabela que inclua os esquemas. Execute os seguintes comandos para gerar as definições de tabela individuais:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
Abra o arquivo indiv_dev.json com seu editor de texto favorito e observe o conteúdo. Ele conterá um JSON que descreve como interpretar o arquivo de dados da FEC.
Precisaremos fazer duas pequenas edições na seção csvOptions. Adicione um valor fieldDelimiter de "|" e um valor quote de "" (a string vazia). Isso é necessário porque o arquivo de dados não é separado por vírgulas, e sim separado por barras verticais:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
O arquivo indiv_dev.json agora será lido em :
"fieldDelimiter": "|",
"quote":"",
Como a criação das definições de tabela para o comitê e as tabelas candidatas são semelhantes, e o esquema contém um pouco de código boilerplate, vamos fazer o download desses arquivos.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
Esses arquivos serão semelhantes a indiv_dev.json. Também é possível fazer o download do arquivo indiv_def.json caso esteja com problemas para receber os valores certos.
Agora, vamos vincular uma tabela do BigQuery a esses arquivos. Execute os seguintes comandos:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
Isso criará três tabelas BigQuery: transações, comitês e candidatos. É possível consultar essas tabelas como se fossem tabelas normais do BigQuery, mas, na verdade, elas não estão armazenadas no BigQuery, mas no Google Cloud Storage. Se você atualizar os arquivos subjacentes, as atualizações serão refletidas imediatamente nas consultas executadas.
Agora, vamos executar algumas consultas. Abra a IU da Web do BigQuery.

Encontre seu conjunto de dados no painel de navegação à esquerda (talvez seja necessário mudar a lista suspensa do projeto no canto superior esquerdo), clicar no botão vermelho "COMPOSE QUERY'" e fazer a seguinte consulta na caixa:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
Essa ferramenta encontrará as 100 doações de campanha mais recentes por funcionários do Google. Se quiser, teste as doações de campanhas de residentes do seu CEP ou encontre as maiores doações na sua cidade.
A consulta e os resultados terão esta aparência:
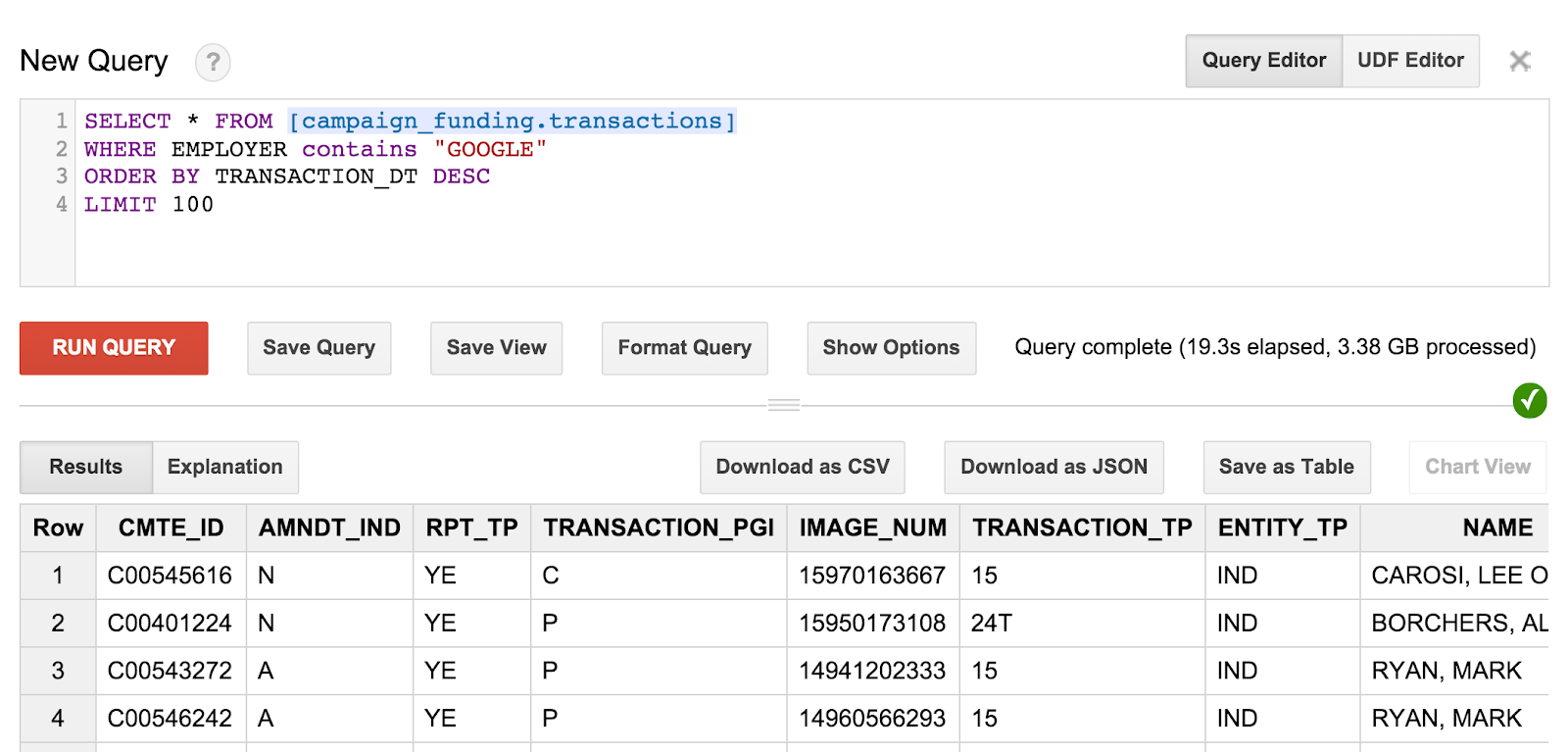
No entanto, talvez você perceba que não é possível saber quem recebeu essas doações. Precisamos criar algumas consultas mais detalhadas para conseguir essas informações.
Clique na tabela "Transações" no painel à esquerda e, depois, na guia "Esquema". Ele será semelhante a esta captura de tela:
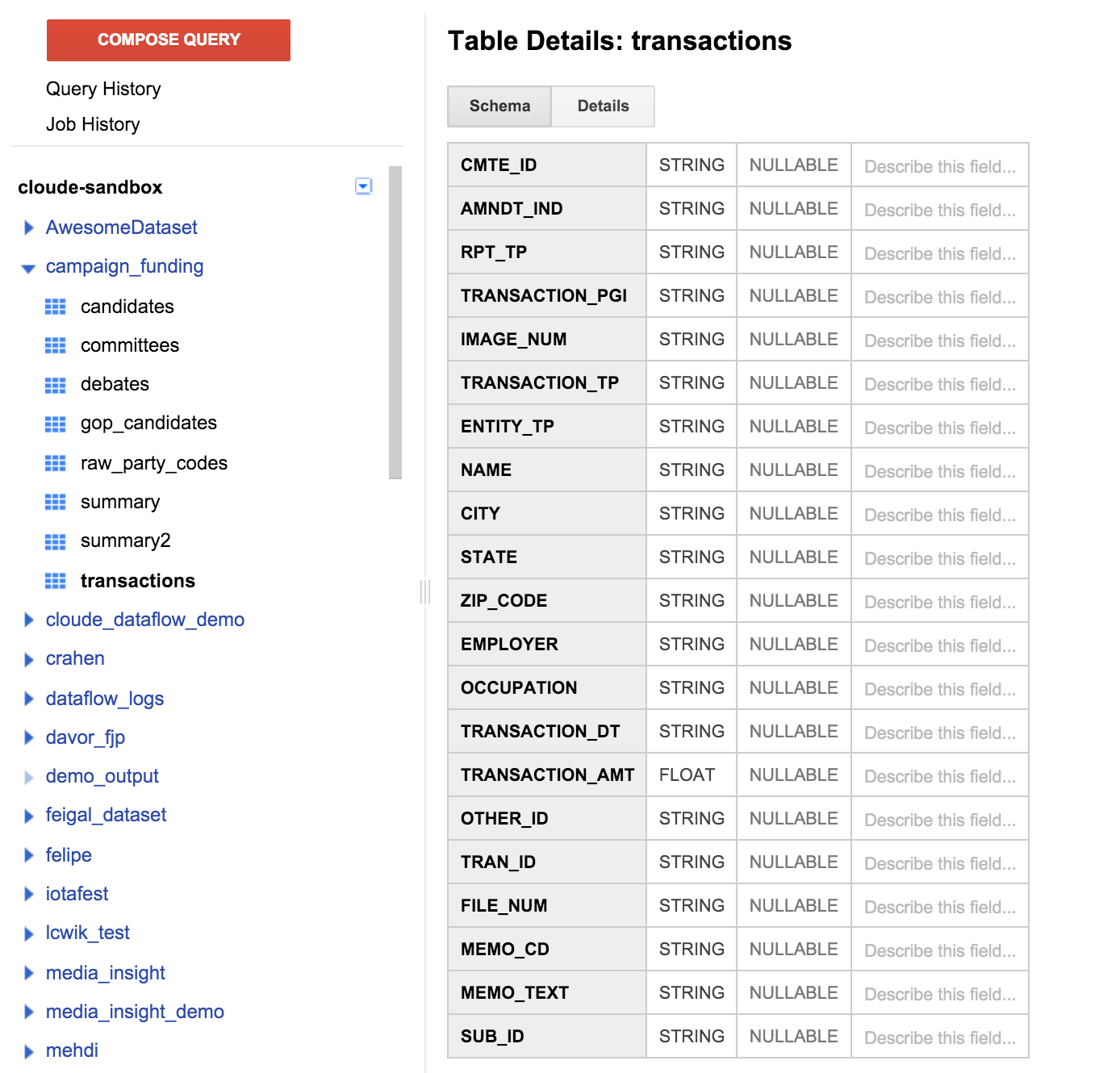
Veja uma lista de campos que correspondem à definição da tabela especificada anteriormente. Você verá que não há um campo de destinatário ou há alguma maneira de descobrir qual candidato era compatível com a doação. No entanto, há um campo chamado CMTE_ID. Assim poderemos vincular o comitê que foi o destinatário da doação à doação. Isso ainda não é tão útil.
Em seguida, clique na tabela de comitês para conferir o esquema. Temos um CMET_ID, que pode ser mesclado à tabela de transações. Outro campo é CAND_ID, que pode ser mesclado com uma tabela CAND_ID na tabela candidata. Por fim, temos uma ligação entre as transações e os candidatos na tabela de comitês.
Não há uma guia de visualização para tabelas com base no GCS. Isso acontece porque, para ler os dados, o BigQuery precisa fazer a leitura em uma fonte de dados externa. Vamos analisar uma amostra dos dados executando uma consulta "SELECT *' simples na tabela de candidatos.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
O resultado deve ser parecido com este:
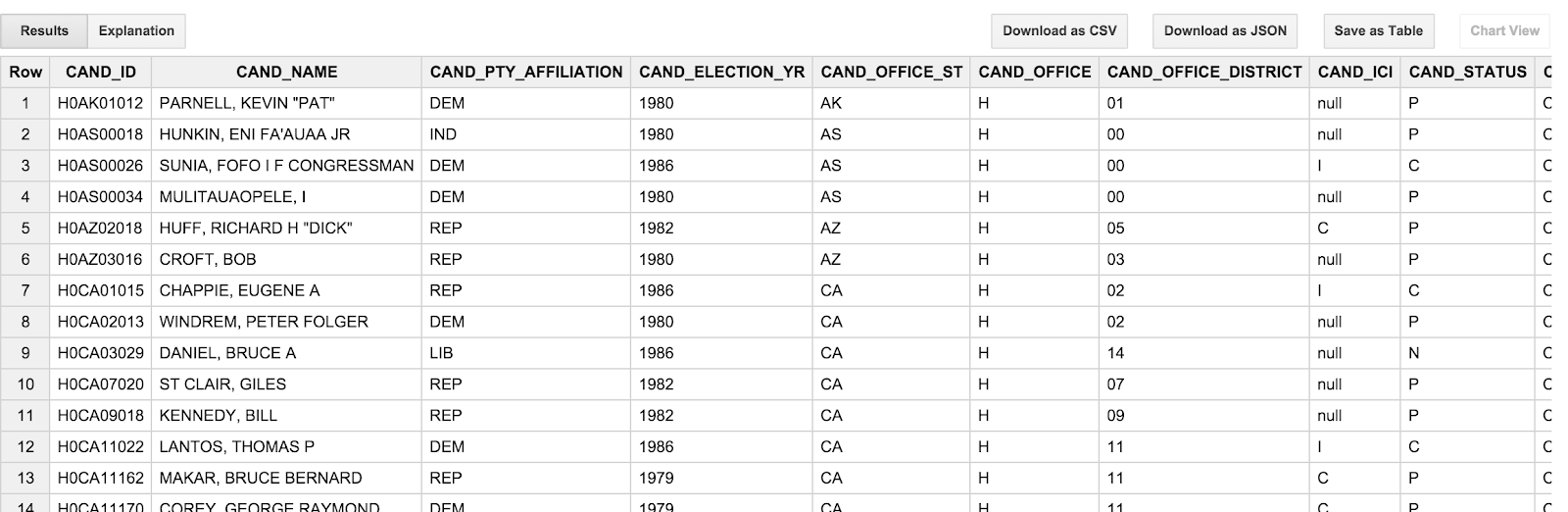
Algo que você pode perceber é que os nomes dos candidatos são LETRAS MAIÚSCULAS e são apresentados em ordem "lastname, firstname". Isso é um pouco incômodo, já que não pensamos nos candidatos de uma só vez. Preferimos ver "Barack Obama" em vez de "OBAMA, BARACK". Além disso, as datas da transação (TRANSACTION_DT) na tabela de transações também são um pouco estranhas. Eles são valores de string no formato YYYYMMDD. Falaremos sobre essas peculiaridades na próxima seção.
Agora que entendemos como as transações se relacionam com os candidatos, vamos executar uma consulta para descobrir quem está distribuindo dinheiro a quem. Recorte e cole a seguinte consulta na caixa de texto:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
Essa consulta mescla a tabela de transações com a tabela de comitês e depois com a tabela de candidatos. Ele só analisa as transações de pessoas com a palavra"quot;ENGINEER"no título da profissão. A consulta agrega resultados por afiliação de partidos. Isso permite ver a distribuição de doações a vários partidos políticos entre engenheiros.
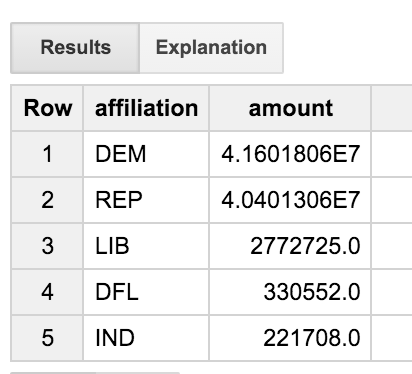
É possível ver que os engenheiros são um grupo bastante equilibrado, que oferece, de maneira mais ou menos uniforme, a democratas e republicanos. Mas o que é a festa "DFL'? Não seria bom conseguir nomes completos em vez de apenas um código de três letras?
Os códigos de grupo são definidos no site da FEC. Há uma tabela que corresponde o código da festa ao nome completo. Acontece que "DFL' é "Democratic-Farmer-Labor'". Poderíamos fazer manualmente as traduções na nossa consulta, mas isso parece ser muito trabalhoso e difícil de manter sincronizado.
E se analisarmos o HTML como parte da consulta? Clique com o botão direito em qualquer lugar da página e analise a opção "Mostrar fonte da página". Há muitas informações de cabeçalho / boilerplate na origem, mas encontre a tag <table>. Cada linha de mapeamento está em um elemento HTML <tr>. O nome e o código são agrupados em elementos <td>. Cada linha ficará assim:
O HTML tem esta aparência:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
Observe que o BigQuery não consegue ler o arquivo diretamente da Web; isso acontece porque o BigQuery é capaz de atingir uma origem de milhares de workers simultaneamente. Se isso fosse permitido em páginas da Web aleatórias, seria basicamente um ataque distribuído de negação de serviço (DDoS). O arquivo HTML da página da FEC é armazenado no bucket gs://campaign-funding.
Precisaremos criar uma tabela com base nos dados de financiamento da campanha. Isso é semelhante às outras tabelas compatíveis com o GCS que criamos. A diferença aqui é que não temos um esquema. Só usamos um campo por linha e o chamamos de "data". Vamos fingir que se trata de um arquivo CSV, mas em vez de delimitado por vírgulas, usamos um delimitador falso (`) e sem aspas.
Para criar a tabela de consulta de terceiros, execute os seguintes comandos na linha de comando:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
Agora usaremos o JavaScript para analisar o arquivo. No canto superior direito do editor de consultas do BigQuery, há um botão chamado "UDF Editor". Clique nela para editar uma UDF em JavaScript. O editor de UDF será preenchido com alguns código clichê comentado.

Exclua o código que ele contém e digite o seguinte:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
O JavaScript aqui é dividido em duas partes. A primeira é uma função que usa uma linha de entrada para emitir uma saída analisada. A outra é uma definição que registra essa função como uma função definida pelo usuário (UDF) com o nome tableParser e indica que ela usa uma coluna de entrada chamada "data'" e gera duas colunas: código e nome. A coluna de código será o código de três letras e a coluna de nome é o nome completo da parte.
Volte para a guia "Editor de consultas" e faça esta consulta:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
Essa consulta vai analisar o arquivo HTML bruto e gerar os valores dos campos no formato estruturado. É muito legal, não é? Tente entender o que "DFL' significa.
Agora que podemos traduzir códigos de festa para nomes, vamos testar outra consulta que usa isso para descobrir algo interessante. Execute a seguinte consulta:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
Essa consulta mostrará quais candidatos receberam a maior quantidade de doações para a campanha e escreverão afiliações de partidos.
Essas tabelas não são muito grandes e levam 30 segundos para serem consultadas. Se você vai fazer muito trabalho com as tabelas, provavelmente as importará para o BigQuery. Você pode executar uma consulta ETL na tabela para transformar os dados em algo fácil de usar e, em seguida, salvá-los como uma tabela permanente. Isso significa que você não precisa sempre lembrar como traduzir códigos de festa e pode filtrar os dados com erros enquanto faz isso.
Clique no botão "Mostrar opções", depois no botão "Selecionar tabela" ao lado do rótulo "quot;Destination Table". Escolha seu conjunto de dados campaign_funding e insira o ID da tabela como "summary'. Marque a caixa de seleção "allow large results'".

Agora execute esta consulta:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
Essa consulta é significativamente mais longa e tem algumas opções de limpeza adicionais. Por exemplo, ele ignora tudo em que o valor é maior que US $1 milhão. Ela também usa expressões regulares para transformar "LASTNAME, FIRSTNAME" em "FIRSTNAME LASTNAME". Se você gosta de aventuras, escreva uma UDF para melhorar e corrigir as letras maiúsculas (por exemplo, "Firstname Lastname").
Por fim, tente executar algumas consultas na tabela campaign_funding.summary para verificar se as consultas nessa tabela são mais rápidas. Não se esqueça de remover a opção de consulta da tabela de destino primeiro, ou você poderá substituir a tabela de resumo.
Você limpou e importou dados do site da FEC para o BigQuery.
O que vimos
- Usando tabelas compatíveis com o GCS no BigQuery.
- Como usar funções definidas pelo usuário no BigQuery.
Próximas etapas
- Faça algumas consultas interessantes para descobrir quem está concedendo dinheiro a quem durante este ciclo eleitoral.
Saiba mais
- Saiba mais sobre o que você pode fazer com as funções definidas pelo usuário.
- Leia sobre as fontes de dados federadas (incluindo GCS).
- Poste perguntas e encontre respostas no Stack Overflow com a tag google-bigquery.
Envie um feedback
- Se quiser, use o link no canto inferior esquerdo desta página para enviar feedback ou enviar feedback.