
Z tego modułu dowiesz się, jak korzystać z zaawansowanych funkcji BigQuery, takich jak:
- Funkcje zdefiniowane przez użytkownika w kodzie JavaScript
- Tabele partycjonowane
- Bezpośrednie zapytania do danych przechowywanych w Google Cloud Storage i na Dysku Google.
Przejmiesz dane Federalnej Komisji Wyborczej USA, wyczyść dane i załadujesz je w BigQuery. Masz też możliwość zadania ciekawych pytań dotyczących tego zbioru danych.
Nie będziemy zakładać, że masz już doświadczenie w korzystaniu z BigQuery, ale niektóre informacje o SQL pomogą Ci go jak najlepiej wykorzystać.
Czego się nauczysz
- Jak używać funkcji zdefiniowanych przez użytkownika JavaScript do wykonywania działań, które są trudne do wykonania w SQL.
- Jak używać BigQuery do wykonywania operacji ETL (wyodrębnianie, przekształcanie, wczytywanie) danych znajdujących się w innych magazynach danych, takich jak Google Cloud Storage czy Dysk Google.
Czego potrzebujesz
- Projekt Google Cloud z włączonymi płatnościami.
- Zasobnik Google Cloud Storage
- Zainstalowano pakiet SDK Google Cloud
Jak będziesz korzystać z tego samouczka?
Jak oceniasz swoje doświadczenie z BigQuery?
Konfiguracja środowiska we własnym tempie
Jeśli nie masz jeszcze konta Google (Gmail lub Google Apps), musisz je utworzyć. Zaloguj się w konsoli Google Cloud Platform (console.cloud.google.com) i utwórz nowy projekt:



Zapamiętaj identyfikator projektu, unikalną nazwę we wszystkich projektach Google Cloud (powyższa nazwa została już użyta i nie będzie działać). W ćwiczeniach nazywamy je później PROJECT_ID.
Aby móc używać zasobów Google Cloud, musisz najpierw włączyć płatności w Cloud Console.
Ćwiczenia z programowania nie powinny kosztować więcej niż kilka dolarów, ale mogą być większe, jeśli zdecydujesz się wykorzystać więcej zasobów lub pozostawisz to uruchomione (zobacz sekcję „Czyszczenie” na końcu tego dokumentu).
Nowi użytkownicy Google Cloud Platform mogą skorzystać z bezpłatnej wersji próbnej o wartości 300 USD.
Google Cloud Shell,
Google Cloud i BigQuery można wykonywać zdalnie z laptopa, ale w trakcie naszych ćwiczeń z programowania będziemy używać Google Cloud Shell – środowiska wiersza poleceń działającego w chmurze.
Ta maszyna wirtualna oparta na Debianie jest wyposażona we wszystkie potrzebne narzędzia dla programistów. Oferuje trwały katalog domowy o pojemności 5 GB oraz działa w Google Cloud, co znacznie zwiększa wydajność sieci i uwierzytelnianie. Oznacza to, że do wykonania tych ćwiczeń z programowania wystarczy przeglądarka (tak, to działa na Chromebooku).
Aby aktywować Google Cloud Shell, w konsoli administracyjnej kliknij przycisk w prawym górnym rogu ekranu. Udostępnienie środowiska i połączenie się z nim powinno potrwać kilka minut:

Kliknij przycisk „Rozpocznij” w Cloud Shell:


Po połączeniu z Cloud Shell zobaczysz, że uwierzytelniono już projekt, a w projekcie ustawiono już PROJECT_ID :
gcloud auth list
Polecenie wyjściowe
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Polecenie wyjściowe
[core] project = <PROJECT_ID>
Cloud Shell domyślnie ustawia też niektóre zmienne środowiskowe, co może być przydatne podczas uruchamiania kolejnych poleceń.
echo $GOOGLE_CLOUD_PROJECT
Polecenie wyjściowe
<PROJECT_ID>
Jeśli z jakiegoś powodu projekt nie jest skonfigurowany, uruchom to polecenie :
gcloud config set project <PROJECT_ID>
Szukasz urządzenia PROJECT_ID? Sprawdź identyfikator użyty w procesie konfiguracji lub znajdź go w panelu konsoli:

WAŻNE: ustaw domyślną strefę i konfigurację projektu:
gcloud config set compute/zone us-central1-f
Możesz wybrać różne strefy. Więcej informacji znajdziesz w dokumentacji regionów i stref.
Aby uruchamiać zapytania BigQuery w ramach tego ćwiczenia z programowania, musisz mieć własny zbiór danych. Wybierz dla niego nazwę, na przykład campaign_funding. Uruchom następujące polecenia w powłoce (na przykład CloudShell):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
Gdy zbiór danych zostanie utworzony, możesz rozpocząć pracę. Uruchomienie tego polecenia powinno pomóc Ci sprawdzić, czy konfiguracja klienta klienta wiersza poleceń bq została poprawnie skonfigurowana, czy uwierzytelnianie działa i czy masz uprawnienia do zapisu w projekcie w chmurze, w którym pracujesz. Jeśli masz więcej niż jeden projekt, pojawi się prośba o wybranie z listy tego, który Cię interesuje.

Zbiór danych kampanii Federalnej Komisji Wyborczej (Federal Election Commission) finansów w USA został zdekompresowany i skopiowany do zasobnika GCS gs://campaign-funding/.
Pobierzmy jeden z plików źródłowych lokalnie, abyśmy mogli zobaczyć, jak to wygląda. Uruchom następujące polecenia w oknie wiersza polecenia:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
Powinna wyświetlić się zawartość pliku z treściami dotyczącymi publikowanych treści. Są 3 rodzaje plików, które będziemy omawiać w ćwiczeniach z programowania: indywidualne zadania (indiv*.txt), kandydaci (cn*.txt) i komitety (cm*.txt). Jeśli chcesz, użyj tego samego mechanizmu, by sprawdzić ich zawartość.
Nie będziemy wczytywać nieprzetworzonych danych bezpośrednio w BigQuery, tylko wysłać je do Google Cloud Storage. Aby to zrobić, musimy znać schemat i kilka informacji o nim.
Zbiór danych opisano na stronie dotyczącej wyborów. Oto schematy tabel, które będziemy oglądać:
Aby utworzyć link do tabel, musisz utworzyć dla nich definicję tabeli zawierającą schematy. Aby wygenerować definicje poszczególnych tabel, uruchom następujące polecenia:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
Otwórz plik indiv_dev.json w ulubionym edytorze tekstu i przyjrzyj się jego zawartości. Będzie on zawierać plik JSON z opisem sposobu interpretowania pliku danych FEC.
Musimy wprowadzić dwie drobne zmiany w sekcji csvOptions. Dodaj wartość fieldDelimiter „"|"” i wartość quote "" (pusty ciąg znaków). Jest to niezbędne, ponieważ plik danych nie jest w rzeczywistości rozdzielany przecinkami, a jest oddzielony pionową kreską:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
Plik indiv_dev.json powinien teraz wyglądać tak :
"fieldDelimiter": "|",
"quote":"",
Definicje tabel komitetu i tabel kandydatów są podobne, a schemat zawiera przyzwoity schemat, wystarczy tylko pobrać te pliki.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
Te pliki będą wyglądać podobnie do pliku indiv_dev.json. Możesz też pobrać plik indiv_def.json na wypadek problemów z uzyskaniem odpowiednich wartości.
Teraz musimy połączyć tabelę BigQuery z tymi plikami. Uruchom te polecenia:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
Spowoduje to utworzenie 3 tabel BigQuery: transakcje, komitety i kandydatów. Możesz tworzyć zapytania do tych tabel, tak jak w przypadku zwykłych tabel BigQuery, ale nie są one przechowywane w BigQuery, tylko w Google Cloud Storage. Jeśli zaktualizujesz pliki bazowe, zmiany te zostaną natychmiast odzwierciedlone w uruchamianych zapytaniach.
Teraz spróbujmy uruchomić kilka zapytań. Otwórz interfejs internetowy BigQuery.

Odszukaj swój zbiór danych w panelu nawigacji po lewej stronie (może być konieczne zmianę menu projektu w lewym górnym rogu), kliknij duży czerwony przycisk „UTWÓRZ ZAPYTANIE” i wpisz w polu następujące zapytanie:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
W ten sposób otrzymasz 100 ostatnich darowizn na kampanię od pracowników Google. Jeśli chcesz, możesz spróbować poszukać darowizn na rzecz kampanii od osób z Twojego kodu pocztowego lub znaleźć największe darowizny w Twoim mieście.
Zapytanie i wyniki będą wyglądać mniej więcej tak:
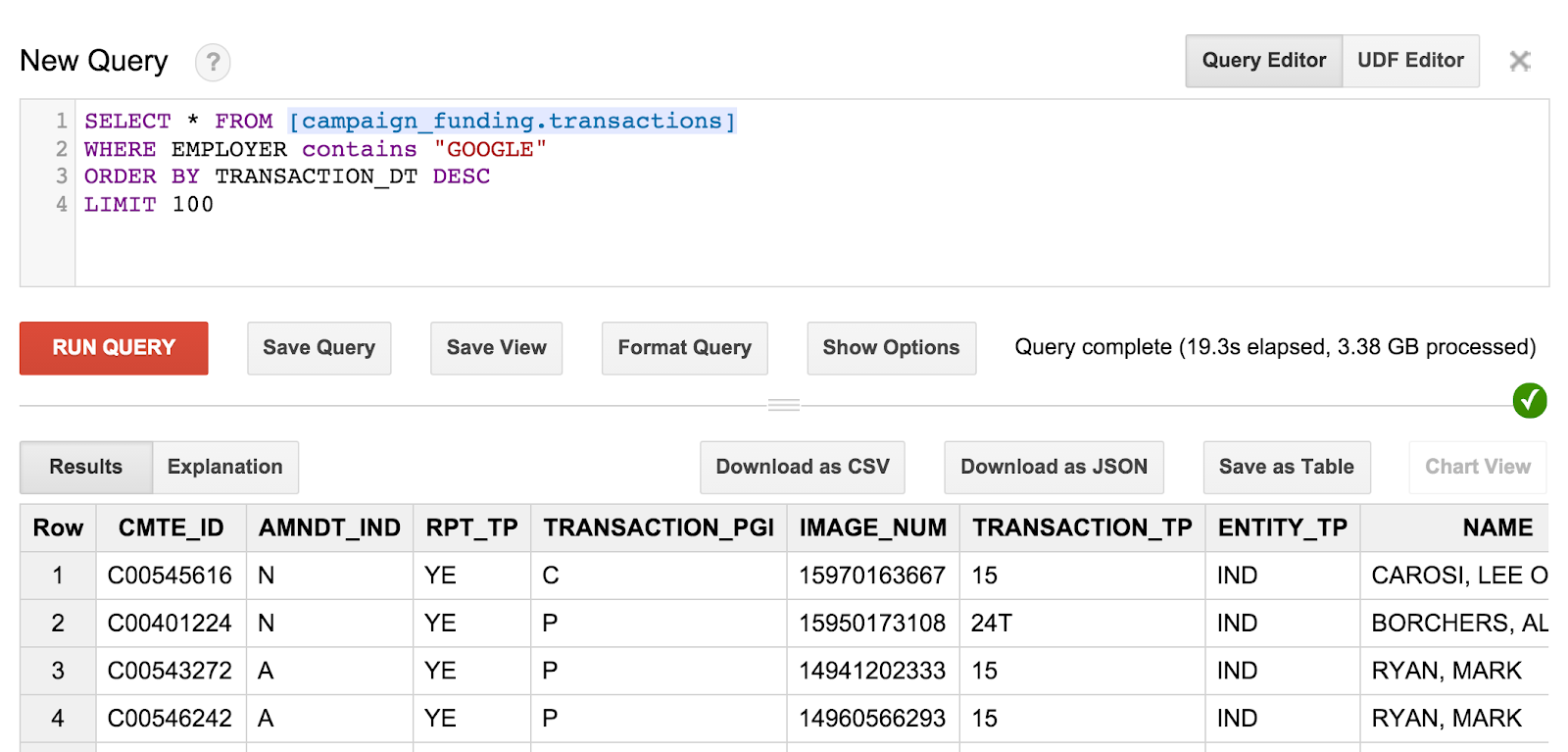
Można jednak zauważyć, że odbiorcy nie są w stanie rozróżnić odbiorców tych darowizn. Aby znaleźć te informacje, musimy opracować bardziej zaawansowane zapytania.
W tabeli po lewej stronie kliknij tabelę transakcji, a następnie kartę schematów. Powinno to wyglądać mniej więcej tak:
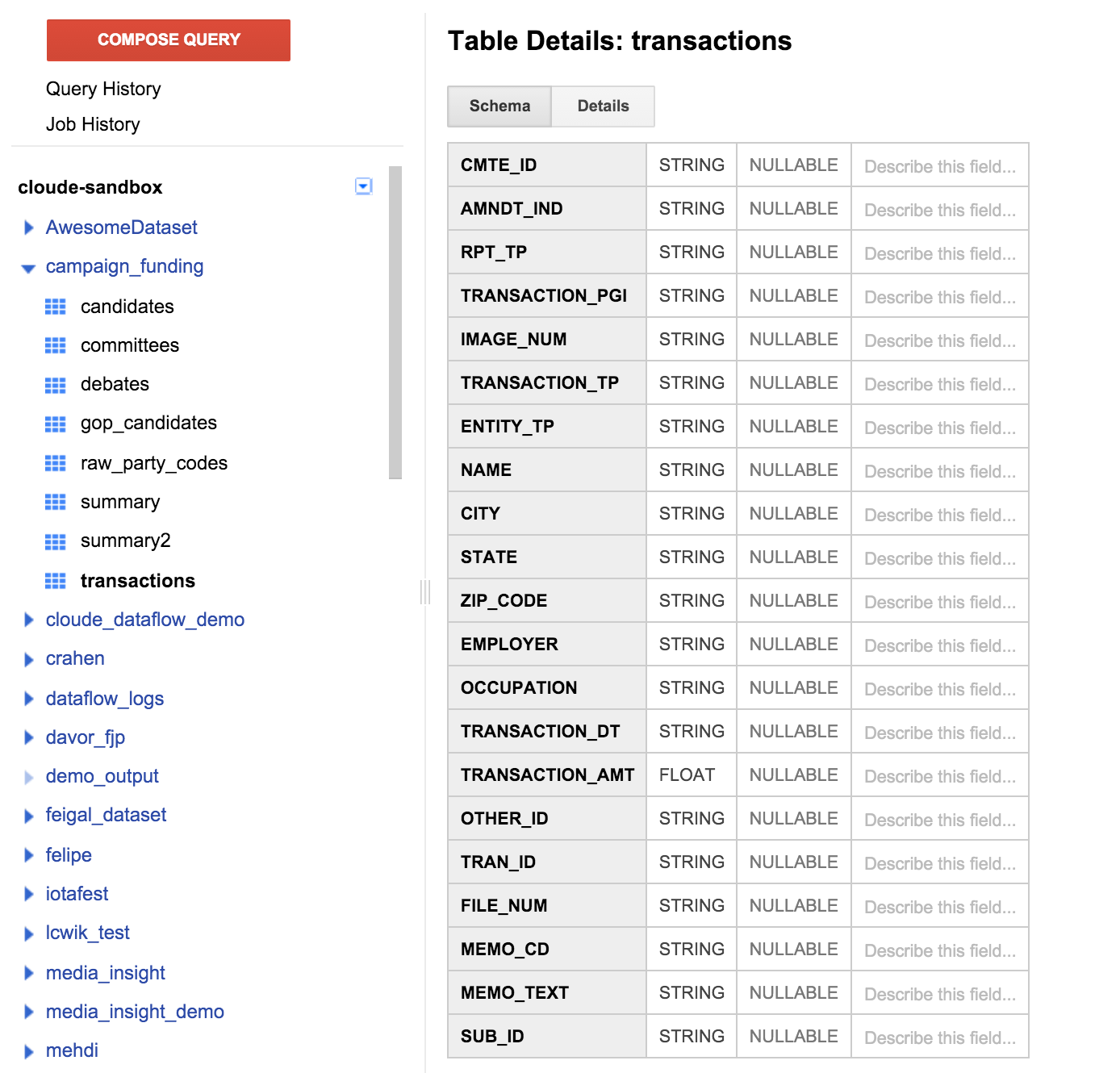
Widzimy listę pól, które pasują do zdefiniowanej wcześniej tabeli. Możesz zauważyć, że nie ma pola odbiorcy, a w jakikolwiek sposób możesz sprawdzić, kto kandyduje w ramach darowizny. Jednak jest pole o nazwie CMTE_ID. Umożliwi nam to połączenie komisji, która otrzymała darowiznę. To jeszcze nie jest przydatne.
Następnie kliknij tabelę komitetów, aby sprawdzić jej schemat. Mamy znak CMET_ID, który umożliwia dołączenie do tabeli transakcji. Inne pole to CAND_ID – można je połączyć z tabelą CAND_ID w tabeli kandydatów. Na koniec prezentujemy powiązanie między transakcjami a kandydatami poprzez tabelę komitetów.
Pamiętaj, że w tabelach opartych na GCS nie ma karty podglądu. Wynika to z tego, że aby odczytać dane, BigQuery musi odczytywać dane z zewnętrznego źródła danych. Aby zobaczyć próbkę danych, uruchom proste zapytanie „SELECT *' w tabeli kandydatów.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
Wynik powinien wyglądać mniej więcej tak:
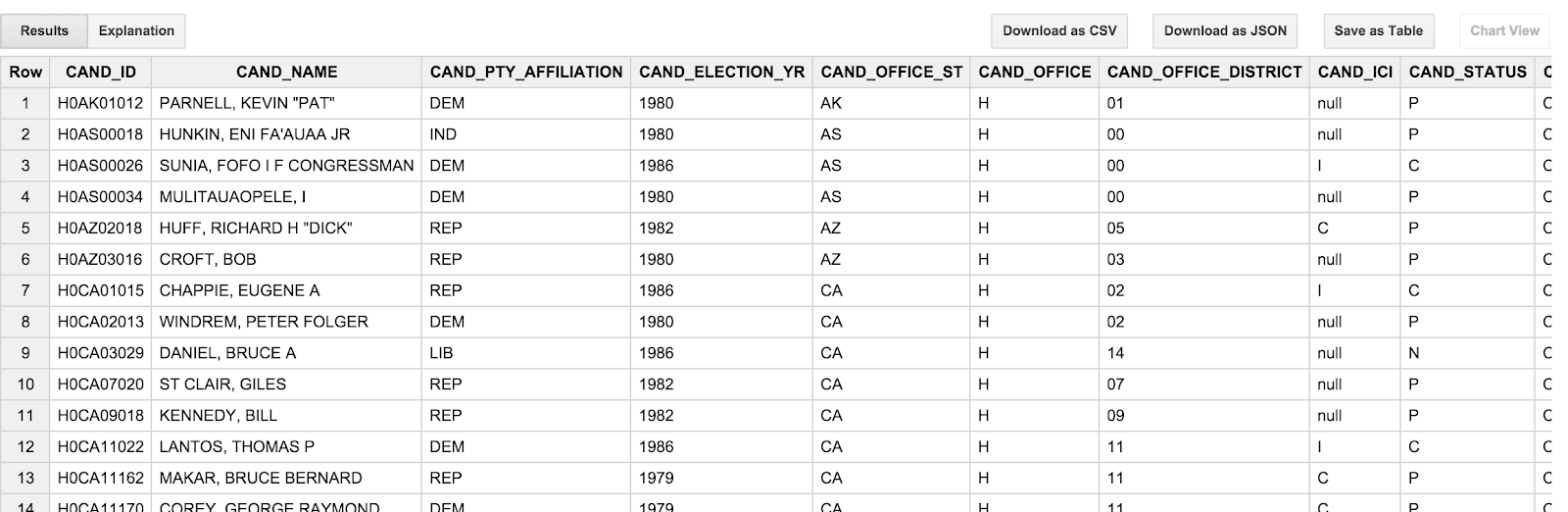
Możesz zauważyć, że imiona i nazwiska kandydatów są WIELKIE WIELKIE LITERY Trochę to irytujące, ponieważ to nie jest takie, jakie uważamy za kandydatów. Wolimy widzieć „Barack Obama” niż „OBAMA, BARACK"”. Co więcej, daty transakcji (TRANSACTION_DT) w tabeli transakcji też są niezrozumiałe. Są to wartości w formacie YYYYMMDD. W następnej sekcji rozwiążemy te problemy.
Skoro już rozumiemy, jak transakcje dotyczą kandydatów, możemy przeprowadzić zapytanie, by określić, komu chcą przekazać pieniądze. Skopiuj i wklej następujące zapytanie w oknie tworzenia wiadomości:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
To zapytanie dołączy tabelę transakcji do tabeli komitetów, a następnie do tabeli kandydatów. Sprawdza tylko transakcje wykonane przez osoby ze słowem „ENGINEER” w stanowisku pracy. Zapytanie agreguje wyniki według przynależności do partii. Dzięki temu możemy zobaczyć, jak przekazywane są darowizny na rzecz różnych partii politycznych wśród inżynierów.
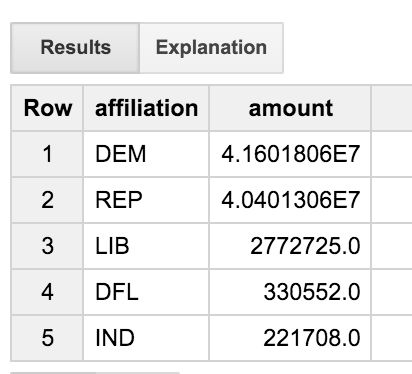
Widzimy, że inżynierów jest dość zrównoważony zespół, który czyni demokratów i republikanów mniej więcej równomiernie. Ale czym jest grupa DFL'? Czy lepiej byłoby uzyskać pełne imiona i nazwiska, a nie tylko trzyliterowy kod?
Kody podmiotów są zdefiniowane na stronie FEC. Jest tabela, która pasuje do pełnego kodu grupy (okazuje się, że „DFL' to „Democratic-Farmer-Labor'”). Ręczne tłumaczenie udało nam się wykonać w zapytaniu, ale wygląda to na bardzo pracochłonne i trudne w synchronizowaniu.
Co w sytuacji, gdy w odpowiedzi na zapytanie możemy przeanalizować kod HTML? Kliknij prawym przyciskiem myszy dowolne miejsce na tej stronie i sprawdź &wyświetl źródło strony. W źródle znajduje się wiele potrzebnych informacji, ale znajdź tag <table>. Każdy wiersz mapowania znajduje się w elemencie HTML <tr>. Nazwa i kod są spakowane w elementach <td>. Każdy wiersz będzie wyglądać mniej więcej tak:
Kod HTML wygląda mniej więcej tak:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
Pamiętaj, że BigQuery nie może odczytać pliku bezpośrednio z internetu. Wynika to z faktu, że BigQuery może korzystać ze źródła z tysiącami instancji roboczych jednocześnie. Gdyby taka strona mogła działać w przypadku losowych stron internetowych, zasadniczo jest to rozproszona odmowa usługi (DDoS). Plik HTML ze strony FEC jest przechowywany w zasobniku gs://campaign-funding.
Musimy utworzyć tabelę na podstawie danych o finansowaniu kampanii. Będzie ona podobna do innych tabel obsługiwanych przez GCS. Różnica polega na tym, że nie mamy schematu. Będziemy używać tylko jednego pola w wierszu i nazwić go „data'”. Uwierzymy, że jest to plik CSV z cudzysłowem (`) i bez znaków cudzysłowu.
Aby utworzyć tabelę wyszukiwania partii, uruchom następujące polecenia z wiersza poleceń:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
Do analizy pliku użyjemy JavaScriptu. W prawym górnym rogu edytora zapytań BigQuery powinien być przycisk z tekstem „Edytor UDF”. Kliknij go, aby przejść do edytowania UDF pliku w języku JavaScript. Edytor UDF zostanie wypełniony kilkoma komentarzami.

Usuń kod, który się w nim znajduje, i wpisz ten kod:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
Kod JavaScript jest tutaj podzielony na dwa elementy. Pierwsza to funkcja, która pobiera wiersz z danymi analizowane przez analizowane dane wyjściowe. Druga to definicja, która służy jako funkcja zdefiniowana przez użytkownika (UDF) o nazwie tableParser i wskazuje, że pobiera ona kolumnę wejściową o nazwie „data'” oraz zwraca 2 kolumny: kod i nazwę. Kolumna kodu będzie zawierać trzyliterowy kod i nazwę grupy.
Wróć do &&;zapytania w Edytorze zapytań i wpisz to zapytanie:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
Uruchomienie tego zapytania przeanalizuje nieprzetworzony plik HTML i wygeneruje wartości pól w uporządkowanym formacie. Świetna robota, prawda? Sprawdź, co oznacza ten skrót „DFL'”.
Teraz, gdy potrafimy przetłumaczyć kody na strony na podstawie nazw, spróbujmy wyszukać coś innego za pomocą tego zapytania. Uruchom następujące zapytanie:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
To zapytanie pokaże, którzy kandydaci zdobyli największe darowizny na potrzeby kampanii, i przedstawicie swój związek.
Te tabele nie są bardzo duże i zabierają około 30 sekund. Jeśli będziesz przeprowadzać dużo pracy z tabelami, prawdopodobnie zechcesz zaimportować je do BigQuery. Możesz uruchomić zapytanie ETL w tabeli, aby skonwertować dane do postaci łatwej w użyciu, a potem zapisać ją jako tabelę stałą. Oznacza to, że nie musisz pamiętać o tłumaczeniu kodów grupy i odfiltrowywać błędne dane.
Kliknij przycisk „Pokaż opcje”, a następnie przycisk „Wybierz tabelę” obok etykiety „Destination Table"”. Wybierz zbiór danych campaign_funding i wpisz identyfikator tabeli jako „summary'”. Zaznacz pole wyboru „allow large results'”.

Teraz uruchom to zapytanie:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
To zapytanie jest znacznie dłuższe i ma więcej opcji czyszczenia. Na przykład ignoruje wszystkie kwoty, które przekraczają 1 mln USD. Wykorzystuje też wyrażenia regularne do przekształcania &"LASTNAME, FIRSTNAME"FIRSTNAME LASTNAME" Jeśli masz ochotę na przygodę, spróbuj napisać UDF, aby zrobić jeszcze więcej, i popraw wielkość liter (np. „"Firstname Lastname"”).
Na koniec spróbuj uruchomić kilka zapytań w odniesieniu do tabeli campaign_funding.summary, aby sprawdzić, czy są one szybsze. Pamiętaj o usunięciu opcji tabeli docelowej tabeli docelowej – w przeciwnym razie może ona zastąpić tabelę podsumowania.
Udało Ci się wyczyścić i zaimportować dane z witryny FEC do BigQuery.
Omawiane zagadnienia
- Używasz tabel opartych na GCS w BigQuery.
- za pomocą funkcji zdefiniowanych przez użytkownika w BigQuery,
Następne kroki
- Wypróbuj kilka interesujących zapytań, aby dowiedzieć się, kto płaci pieniądze w tym cyklu wyborczym.
Więcej informacji
- Dowiedz się więcej o tym, co możesz zrobić za pomocą funkcji zdefiniowanych przez użytkownika.
- Przeczytaj o sfederowanych źródłach danych(w tym o GCS).
- Zadaj pytania i znajdź odpowiedzi na stronie Stackoverflow pod tagiem google-bigquery.
Prześlij nam swoją opinię
- Możesz kliknąć link w lewym dolnym rogu tej strony, aby zgłosić problem lub przesłać opinię.