
この Codelab では、BigQuery の高度な機能を活用する方法について説明します。
- JavaScript のユーザー定義関数
- パーティション分割テーブル
- Google Cloud Storage や Google ドライブに保存されているデータに対して直接クエリを実行します。
米国連邦選挙委員会からデータを取得してクリーンアップし、BigQuery に読み込みます。そのデータセットについて、興味深い質問を受ける機会もあります。
この Codelab では、BigQuery の使用経験がないことを前提としていますが、SQL を理解しておくと、BigQuery をさらに活用できます。
学習内容
- JavaScript ユーザー定義関数を使用して、SQL では難しい処理を実行します。
- BigQuery を使用して、Google Cloud Storage や Google ドライブなどの他のデータストアにあるデータに対して ETL(抽出、変換、読み込み)オペレーションを行う方法。
必要なもの
- 課金を有効にした Google Cloud プロジェクト
- Google Cloud Storage バケット
- Google Cloud SDK のインストール
このチュートリアルの利用方法をお選びください。
BigQuery の使用経験についてお答えください。
セルフペース型の環境設定
Google アカウント(Gmail または Google Apps)をまだお持ちでない場合は、アカウントを作成する必要があります。Google Cloud Platform Console(console.cloud.google.com)にログインして、新しいプロジェクトを作成します。



プロジェクト ID を忘れないようにしてください。プロジェクト ID はすべての Google Cloud プロジェクトを通じて一意の名前にする必要があります(上記の名前はすでに使用されているので使用できません)。以降、このコードラボでは PROJECT_ID と呼びます。
次に、Google Cloud リソースを使用するために、Cloud Console で課金を有効にする必要があります。
この Codelab を実施した場合、費用は数ドルを超えることはありませんが、より多くのリソースを使用する場合や、実行したままにしておくとさらにコストがかかる場合があります(このドキュメントの最後にある「クリーンアップ」セクションをご覧ください)。
Google Cloud Platform の新規ユーザーは 300 ドル分の無料トライアルをご利用いただけます。
Google Cloud Shell
Google Cloud と BigQuery は、ノートパソコンからリモートで操作できますが、この Codelab では、Cloud 内で動作するコマンドライン環境である Google Cloud Shell を使用します。
この Debian ベースの仮想マシンには、必要な開発ツールがすべて読み込まれています。5 GB の永続的なホーム ディレクトリが Google Cloud 上で動作することで、ネットワーク パフォーマンスと認証が大幅に強化されます。この Codelab に必要なのはブラウザだけです(はい、Chromebook で動作します)。
Google Cloud Shell を有効にするには、デベロッパー コンソールで右上のボタンをクリックします(プロビジョニングと環境への接続にはそれほど時間はかかりません)。

[Cloud Shell の起動] ボタンをクリックします。


Cloud Shell に接続すると、認証が完了していて、プロジェクトが PROJECT_ID に設定されていることがわかります。
gcloud auth list
コマンド出力
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
コマンド出力
[core] project = <PROJECT_ID>
Cloud Shell では、いくつかの環境変数もデフォルトで設定します。これは、今後コマンドを実行するときに役立ちます。
echo $GOOGLE_CLOUD_PROJECT
コマンド出力
<PROJECT_ID>
なんらかの理由でプロジェクトが設定されていない場合は、単に次のコマンドを実行します。
gcloud config set project <PROJECT_ID>
PROJECT_ID が見つからない場合は、設定手順で使用した ID を確認するか、コンソール ダッシュボードで確認します。

重要: 最後に、デフォルトのゾーンとプロジェクトの構成を設定します。
gcloud config set compute/zone us-central1-f
さまざまなゾーンを選択できます。詳しくは、リージョンとゾーンのドキュメントをご覧ください。
この Codelab で BigQuery クエリを実行するには、独自のデータセットが必要です。名前を選択します(campaign_funding など)。シェル(たとえば、CloudShell)で次のコマンドを実行します。
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
データセットが作成されたら、次に進みます。このコマンドを実行すると、bq コマンドライン クライアントが正しく設定されていること、認証が機能していること、操作中のクラウド プロジェクトへの書き込みアクセス権があることを確認できるようになります。複数のプロジェクトがある場合は、確認したいプロジェクトをリストから選択するよう求められます。

米国連邦選挙委員会のキャンペーン ファイナンス データセットは解凍され、GCS バケット gs://campaign-funding/ にコピーされています。
ソースファイルの 1 つをローカルにダウンロードし、どのように表示されるか確認しましょう。コマンド ウィンドウで次のコマンドを実行します。
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
個々の資金提供ファイルの内容が表示されます。この Codelab で取り上げるファイルには、個々の投稿(indiv*.txt)、候補者(cn*.txt)、委員会(cm*.txt)の 3 種類があります。3 つのファイルについては、同じメカニズムを使用して、他のファイルの内容を確認してください。
ここでは元データを BigQuery に直接読み込むのではなく、Google Cloud Storage からクエリを実行します。そのためには、スキーマとスキーマに関する情報が必要です。
データセットは、連邦選挙のウェブサイトでこちらに説明されています。以下で説明するテーブルのスキーマは次のとおりです。
テーブルにリンクするには、スキーマを含むテーブル定義を作成する必要があります。次のコマンドを実行して、個々のテーブル定義を生成します。
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
任意のテキスト エディタで indiv_dev.json ファイルを開き、内容を確認します。このファイルには、FEC データファイルの解釈方法を示す JSON が含まれています。
csvOptions セクションに 2 つの小さな編集を行う必要があります。fieldDelimiter に "|" の値を追加し、quote に ""(空の文字列)の値を追加する。データファイルは実際にはカンマではなく、パイプで区切られているため、この確認が必要になります。
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
indiv_dev.json ファイルは次のようになります。
"fieldDelimiter": "|",
"quote":"",
commit テーブルと候補テーブルのテーブル定義は似ており、スキーマにはある程度のボイラープレートが含まれているため、これらのファイルのダウンロードのみを行います。
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
これらのファイルは、indiv_dev.json ファイルに似ています。適切な値を取得できない場合に備えて、indiv_def.json ファイルをダウンロードすることもできます。
次に、BigQuery テーブルをこれらのファイルにリンクします。次のコマンドを実行します。
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
これにより、トランザクション、委員会、候補の 3 つの BigQuery テーブルが作成されます。これらのテーブルは通常の BigQuery テーブルのようにクエリを実行できますが、実際には BigQuery ではなく、Google Cloud Storage にも格納されています。基になるファイルを更新すると、その更新は実行したクエリにすぐに反映されます。
次に、いくつかのクエリを実行してみましょう。BigQuery ウェブ UI を開きます。

左側のナビゲーション パネルでデータセットを見つけて(左上のプロジェクト プルダウンの変更が必要な場合があります)、大きな赤色の [クエリの作成] ボタンをクリックし、次のクエリをボックスに入力します。
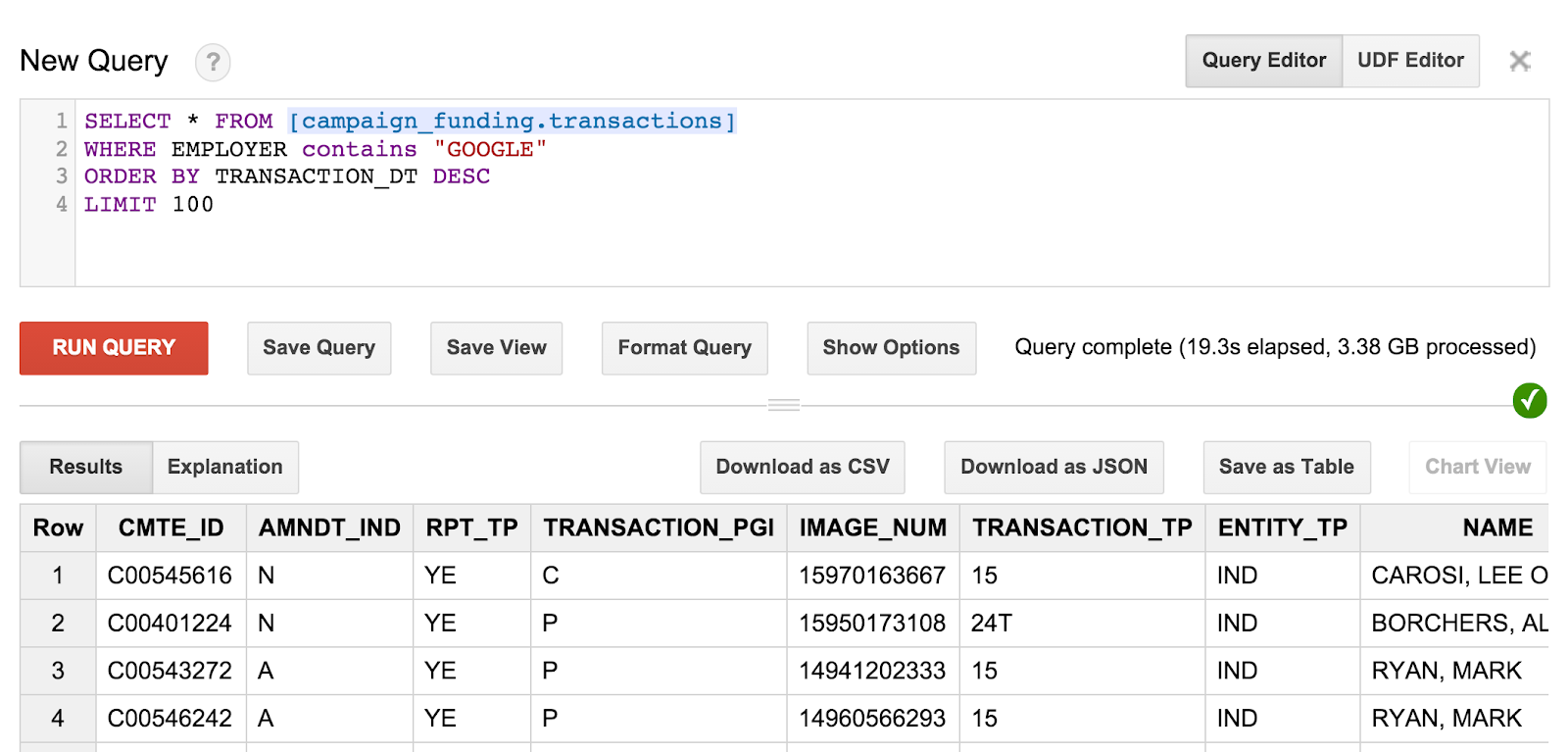
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
これにより、Google 社員による最新のキャンペーン寄付 100 件が検索されます。ご希望の場合は、あちこちで郵便番号をチェックして、都市内で最大の寄付金を見つけましょう。
クエリと結果は次のようになります。
一方で、この寄付の受取人が誰なのかがわかりません。この情報を取得するために、もっと興味深いクエリを考える必要があります。
左側のペインのトランザクション テーブルをクリックし、[スキーマ] タブをクリックします。次に示すスクリーンショットのようになります。
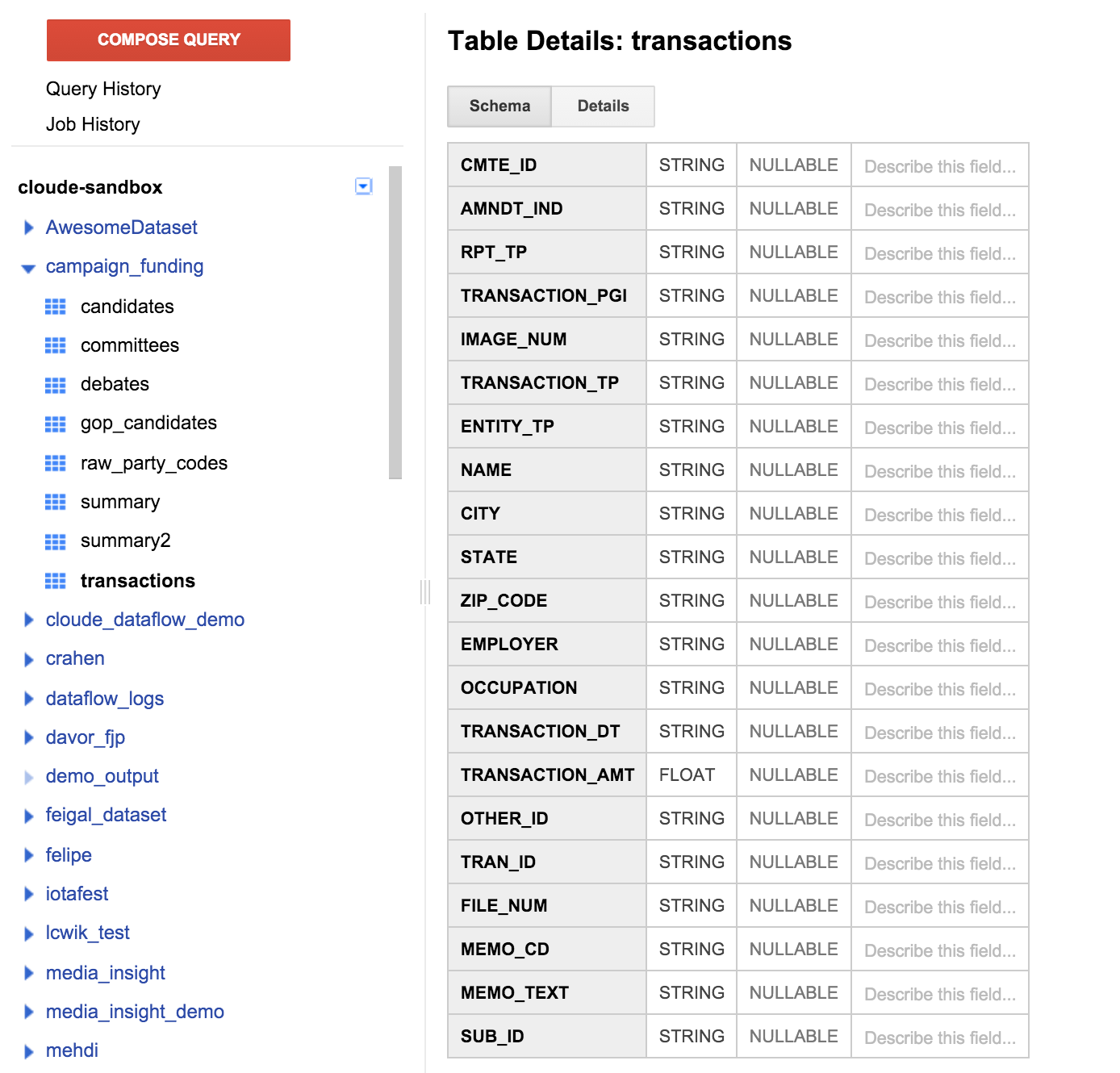
先ほど指定したテーブル定義と一致するフィールドのリストが表示されます。受取人の項目がないか、寄付がサポートされている候補者を見つける方法に気付いていない場合もあります。CMTE_ID というフィールドもあります。これにより、寄付を受け取った委員会が寄付にリンクされます。これでは、まだあまり役に立っていません。
次に、commit テーブルをクリックして、そのスキーマを確認します。CMET_ID を取得したら、トランザクション テーブルに結合できます。別のフィールドは CAND_ID です。これは、候補者テーブルの CAND_ID テーブルと結合できます。最後に、commit テーブルを使用して、トランザクションと候補をリンクします。
GCS ベースのテーブルにはプレビュー タブがありません。これは、データを読み取るために BigQuery が外部データソースから読み取る必要があるためです。候補テーブルに対して単純な「SELECT *」クエリを実行して、データのサンプルを取得します。
SELECT * FROM [campaign_funding.candidates] LIMIT 100
次のような結果が表示されます。
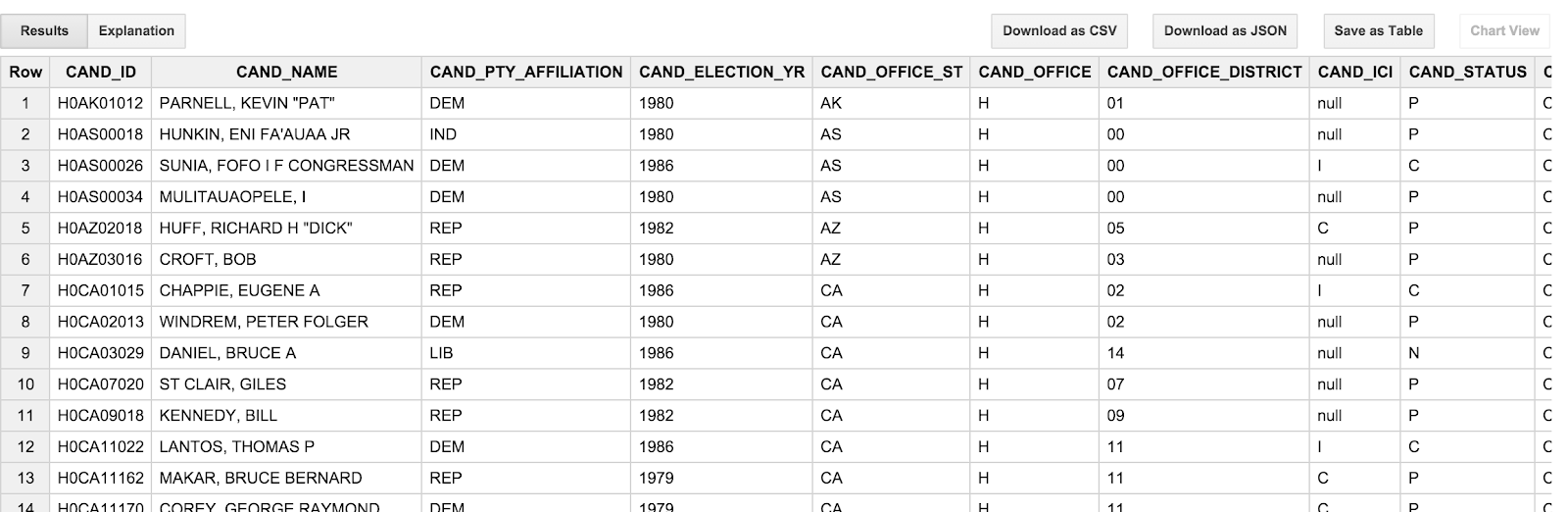
候補名はすべて大文字で、「姓,名」の順番で表示されます。候補者の考え方はあまり違ってしまっているので、少しわずらわしいです。「OBAMA, BARACK」ではなく、「Barack Obama」をご覧ください。また、トランザクション テーブルに記載されているトランザクションの日付(TRANSACTION_DT)にも少し問題があります。YYYYMMDD 形式の文字列値です。これらの問題は、次のセクションで対処します。
取引が候補者にどのように関係するかを理解したところで、誰に報酬を支払っているのかを把握するためにクエリを実行してみましょう。次のクエリを切り取って入力ボックスに貼り付けます。
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
このクエリは、トランザクション テーブルを commit テーブルと結合し、次に候補テーブルに結合します。職業のタイトルに「ENGINEER」という単語を含むユーザーに関する取引のみが確認されます。このクエリは、当事者の所属ごとに結果を集計します。これにより、エンジニア間のさまざまな政党への寄付の分布を確認できます。
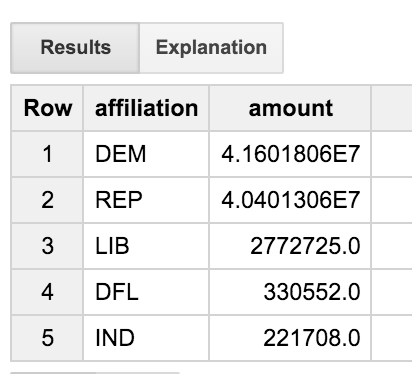
エンジニアは、民主主義者と共和党支持者の割合がほぼ均等にバランスよく調整されていることがわかります。DFL パーティーとは3 文字のコードだけでなく、フルネームを実際に取得できたら良いと思いませんか。
パーティー コードは FEC ウェブサイトで定義されています。パーティー コードがフルネームと一致するテーブルがあります(「DFL' が『Democratic-Farmer-Labor'』である」)。クエリでは手動で変換を行うこともできますが、大変手間がかかり、作業内容の同期も困難です。
クエリの一部として HTML を解析できるとしたらどうでしょう。ページ上の任意の場所を右クリックし、[ページのソースを表示] を確認します。ソースにはヘッダーやボイラープレートの情報が多数含まれていますが、<table> タグを探します。マッピング行はそれぞれ HTML の <tr> 要素内にあり、名前とコードはどちらも <td> 要素内にラップされます。各行は次のようになります。
HTML は次のようになります。
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
BigQuery はウェブから直接ファイルを読み取ることはできません。BigQuery は数千のワーカーから同時にソースを受け取ることができるからです。ランダムなウェブページに対して実行することが許可された場合、基本的には分散型サービス拒否攻撃(DDoS)になります。FEC ウェブページの html ファイルは、gs://campaign-funding バケットに保存されます。
キャンペーンの資金データに基づいてテーブルを作成する必要があります。これは、作成した他の GCS ベースのテーブルと同様です。違いは、スキーマは実際にはないという点です。実際には行ごとに 1 つのフィールドを使用し、「data」という名前にします。CSV ファイルと仮定しますが、カンマではなく、区切り文字(`)を使用し、引用符は使用できません。
パーティー検索の表を作成するには、コマンドラインから次のコマンドを実行します。
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
ここでは JavaScript を使用してファイルを解析します。BigQuery クエリエディタの右上に「UDF Editor」というラベルのボタンがあります。クリックすると、JavaScript UDF の編集に切り替わります。UDF エディタには、コメントアウトされたボイラープレートが入力されます。

コードに含まれるコードを削除し、次のコードを入力します。
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
この JavaScript は 2 つに分かれています。1 つ目は、解析された出力を生成する入力行を取得する関数です。もう 1 つは、その関数を tableParser という名前のユーザー定義関数(UDF)として登録し、「data'」という入力列を受け取って、2 つの列(コードと名前)を出力することを示しています。コード列は 3 文字のコードです。名前列は当事者の完全な名前です。
[クエリエディタ] タブに戻り、次のクエリを入力します。
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
このクエリを実行すると、未加工の HTML ファイルが解析され、フィールド値が構造化形式で出力されます。なかなかうまくいきませんか?「DFL'」が何を意味するのかわかるかもしれません。
パーティー コードを名前に翻訳できるようになったので、これを利用して面白いクエリを見つけてみましょう。次のクエリを実行します。
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
次のクエリでは、キャンペーンへの寄付額が最も多かった候補者が表示され、所属政党のスペルが示されます。
これらのテーブルは大きくなく、クエリには 30 秒ほどかかります。テーブルに対して多くの作業を実行する場合は、テーブルを BigQuery にインポートすることをおすすめします。テーブルに対して ETL クエリを実行し、データを使いやすいように強制変換してから永続テーブルとして保存できます。つまり、パーティー コードの翻訳方法を常に覚えておく必要はなく、間違ったデータをフィルタで除外することもできます。
「オプションを表示」ボタンをクリックしてから、「表」ラベルの横にある [テーブルを選択] ボタンをクリックします。Destination Tablecampaign_funding データセットを選択し、テーブル ID に「summary'」と入力します。[allow large results'] チェックボックスをオンにします。

次のクエリを実行します。
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
このクエリはかなり長く、追加のクリーンアップ オプションがいくつかあります。たとえば、金額が 100 万ドルを超えるものは無視されます。また、正規表現を使って「LASTNAME, FIRSTNAME」を「FIRSTNAME LASTNAME」に変えます。もっと冒険したいような場合は、UDF を作成して大文字の使い方(例: Firstname Lastname)を修正してみてください。
最後に、campaign_funding.summary テーブルに対していくつかのクエリを実行して、そのテーブルに対するクエリが高速化されていることを確認します。まず、宛先テーブルのクエリ オプションを削除する必要があります。削除しないと、サマリー テーブルが上書きされる可能性があります。
これで、FEC ウェブサイトから BigQuery にデータがクリーンアップされ、インポートされました。
学習した内容
- BigQuery で GCS を使用するテーブルを使用する。
- BigQuery でユーザー定義関数を使用する。
次の手順
- 誰に送金するかについては、興味深いクエリをご覧ください。
詳細
- ユーザー定義関数で可能な操作を確認する。
- フェデレーション データソース(GCS を含む)についてお読みください。
- google-bigquery タグを付けて Stack Overflow に質問を投稿したり回答を探したりできます。
フィードバックをお寄せください
- このページの左下にあるリンクから、問題を報告したりフィードバックを送信したりできます。