
In questo codelab, imparerai a utilizzare alcune funzionalità avanzate di BigQuery, tra cui:
- Funzioni definite dall'utente in JavaScript
- Tabelle partizionate
- Query dirette per i dati che risiedono in Google Cloud Storage e Google Drive.
Utilizzerai i dati della Commissione elettorale federale degli Stati Uniti, li pulisci e li caricherai su BigQuery. Avrai anche la possibilità di porre alcune domande interessanti su tale set di dati.
Anche se questo codelab non presuppone alcuna esperienza precedente con BigQuery, alcune conoscenze di SQL ti aiuteranno a sfruttarlo al meglio.
Obiettivi didattici
- Come utilizzare le funzioni definite dall'utente di JavaScript per eseguire operazioni difficili da eseguire in SQL.
- Come utilizzare BigQuery per eseguire operazioni ETL (Extract, Transform, Load) su dati che si trovano in altri datastore, come Google Cloud Storage e Google Drive.
Che cosa ti serve
- Un progetto Google Cloud con fatturazione abilitata.
- un bucket Google Cloud Storage
- Google Cloud SDK installato
Come utilizzerai questo tutorial?
Come valuteresti il tuo livello di esperienza con BigQuery?
Configurazione automatica dell'ambiente
Se non hai ancora un Account Google (Gmail o Google Apps), devi crearne uno. Accedi alla console di Google Cloud Platform (console.cloud.google.com) e crea un nuovo progetto.



Ricorda l'ID progetto, un nome univoco in tutti i progetti Google Cloud (il nome sopra riportato è già stato utilizzato e non funzionerà per te). Vi verrà fatto riferimento più avanti in questo codelab come PROJECT_ID.
Il prossimo passaggio consiste nell'attivare la fatturazione in Cloud Console per utilizzare le risorse di Google Cloud.
L'esecuzione di questo codelab non dovrebbe costare più di qualche euro, ma potrebbe essere di più se decidi di utilizzare più risorse o se le lasci in esecuzione (vedi la sezione "pulizia" alla fine di questo documento).
I nuovi utenti di Google Cloud Platform sono idonei per una prova senza costi di 300 $.
Google Cloud Shell
Sebbene Google Cloud e Big Query possano essere utilizzati a distanza dal tuo laptop, in questo codelab utilizzeremo Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Questa macchina virtuale basata su Debian viene caricata con tutti gli strumenti di sviluppo di cui hai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Ciò significa che ti servirà solo un browser (sì, funziona su Chromebook).
Per attivare Google Cloud Shell, nella Console per gli sviluppatori basta fare clic sul pulsante in alto a destra (il provisioning e la connessione all'ambiente devono essere pochi minuti):

Fai clic sul pulsante "Avvia Cloud Shell":


Dopo aver effettuato la connessione a Cloud Shell, dovresti vedere che sei già autenticato e che il progetto è già impostato su PROJECT_ID:
gcloud auth list
Output comando
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
Output comando
[core] project = <PROJECT_ID>
Per impostazione predefinita, Cloud Shell imposta anche alcune variabili di ambiente, che possono essere utili durante l'esecuzione di comandi futuri.
echo $GOOGLE_CLOUD_PROJECT
Output comando
<PROJECT_ID>
Se per qualche motivo il progetto non è configurato, esegui semplicemente il seguente comando :
gcloud config set project <PROJECT_ID>
Stai cercando il tuo dispositivo PROJECT_ID? Controlla quale ID hai utilizzato nei passaggi di configurazione o cercalo nella dashboard della console:

IMPORTANTE: infine, imposta la zona e la configurazione del progetto predefinite:
gcloud config set compute/zone us-central1-f
Puoi scegliere una varietà di zone. Scopri di più nella documentazione relativa ad aree geografiche e zone.
Per eseguire le query BigQuery in questo codelab, avrai bisogno del tuo set di dati. Scegli un nome, ad esempio campaign_funding. Esegui questi comandi nella shell (ad esempio Cloud Shell):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
Dopo aver creato il set di dati, dovresti essere in grado di iniziare. L'esecuzione di questo comando dovrebbe inoltre aiutarti a verificare che la configurazione del client a riga di comando bq sia corretta, che l'autenticazione funzioni e che tu disponga dell'accesso in scrittura al progetto cloud su cui utilizzi. Se hai più di un progetto, ti verrà chiesto di selezionarne uno da un elenco.

Il set di dati finanziario della Federal Election Commission è stato decompresso e copiato nel bucket GCS gs://campaign-funding/.
Scarica localmente uno dei file di origine in modo da poterne visualizzare l'aspetto. Esegui i seguenti comandi da una finestra dei comandi:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
In questo modo, verranno visualizzati i contenuti del singolo file di contributi. Ci sono tre tipi di file che cercheremo in questo codelab: contributi individuali (indiv*.txt), candidati (cn*.txt) e commissioni (cm*.txt). Se ti interessa, utilizza lo stesso meccanismo per verificare cosa c'è in questi altri file.
Non caricheremo i dati non elaborati direttamente in BigQuery, ma eseguiremo una query da Google Cloud Storage. Per farlo, dobbiamo conoscere lo schema e alcune informazioni a riguardo.
Puoi trovare il set di dati sul sito web delle elezioni federali qui. Gli schemi per le tabelle che esamineremo sono:
Per creare un collegamento alle tabelle, dobbiamo creare una definizione della tabella che includa gli schemi. Esegui i comandi seguenti per generare le singole definizioni della tabella:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
Apri il file indiv_dev.json con il tuo editor di testo preferito e dai un'occhiata ai contenuti; conterrà un file json che descrive come interpretare il file di dati FEC.
Dovremo apportare due piccole modifiche alla sezione csvOptions. Aggiungi un valore fieldDelimiter di "|" e un valore quote di "" (la stringa vuota). Questo è necessario perché il file di dati non è separato da virgole, ma è barrato:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
A questo punto, il file indiv_dev.json dovrebbe essere :
"fieldDelimiter": "|",
"quote":"",
Poiché la creazione delle definizioni di tabella per il comitato e le tabelle candidati è simile e lo schema contiene un valore di boilerplate discreto, scaricare questi file.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
Questi file saranno simili al file indiv_dev.json. Tieni presente che puoi anche scaricare il file indiv_def.json, nel caso in cui avessi problemi a ottenere i valori giusti.
Ora creiamo un collegamento tra una tabella BigQuery e questi file. Esegui i seguenti comandi:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
Verranno create tre tabelle BigQuery: transazioni, commissioni e candidati. Puoi eseguire query su queste tabelle come si tratta di normali tabelle BigQuery, ma in realtà non sono memorizzate in BigQuery, ma in Google Cloud Storage. Se aggiorni i file sottostanti, gli aggiornamenti verranno immediatamente visualizzati nelle query che esegui.
Ora proviamo a eseguire un paio di query. Apri l'interfaccia utente web di BigQuery.

Trova il tuo set di dati nel riquadro di navigazione a sinistra (potrebbe essere necessario modificare il menu a discesa del progetto nell'angolo in alto a sinistra), fai clic sul pulsante rosso "COMPOSE QUERY' e inserisci la seguente query nella casella:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
In questo modo troverai le ultime 100 donazioni di campagne da parte dei dipendenti di Google. Se vuoi, prova a giocare e a trovare donazioni di campagna per i residenti del tuo codice postale o trova le donazioni più importanti nella tua città.
La query e i risultati avranno un aspetto simile al seguente:
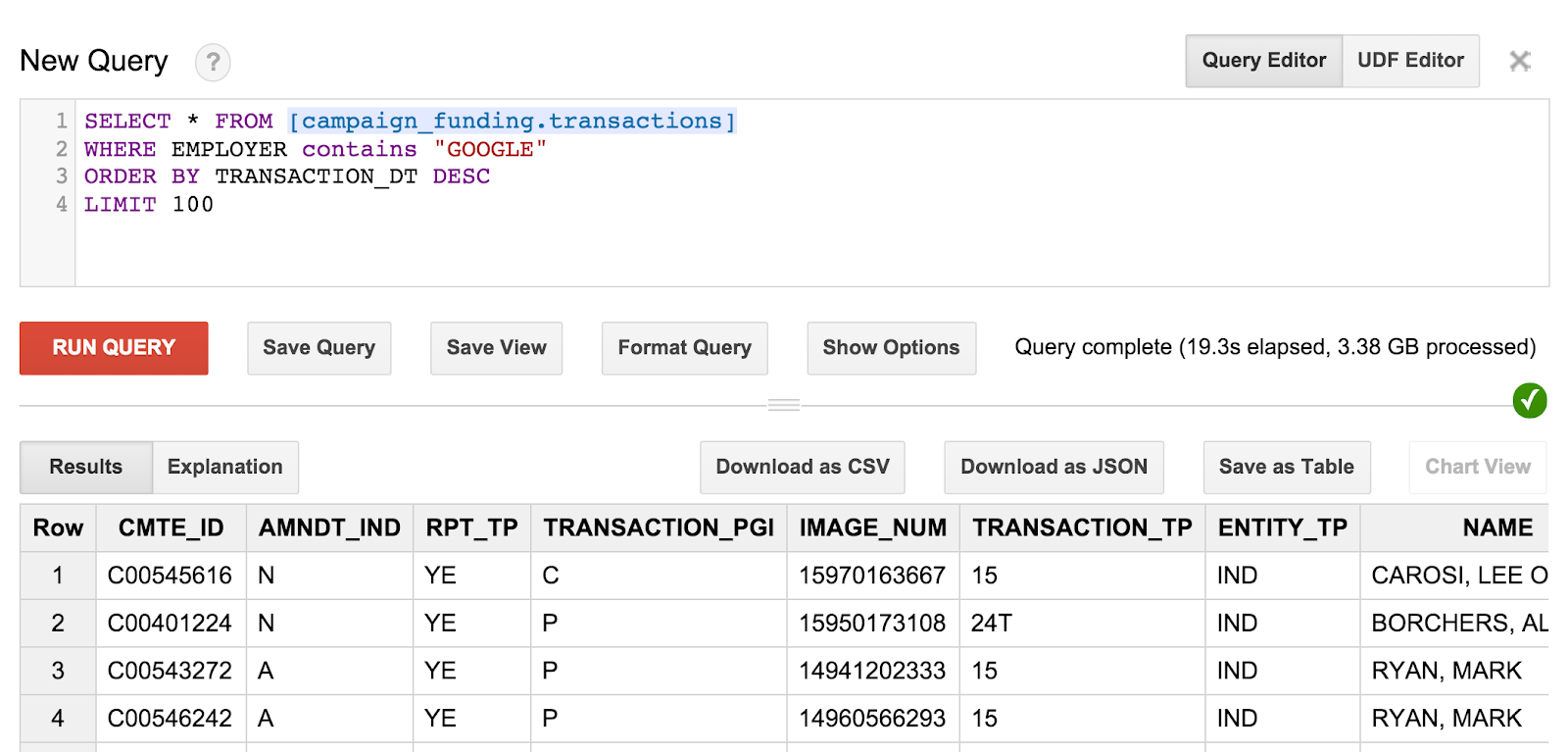
Una cosa che potresti notare, tuttavia, è che non puoi veramente sapere chi era il destinatario di queste donazioni. Dobbiamo capire quali sono le query più elaborate per ottenere queste informazioni.
Fai clic sulla tabella delle transazioni nel riquadro a sinistra, quindi fai clic sulla scheda Schema. Dovrebbe avere lo screenshot seguente:
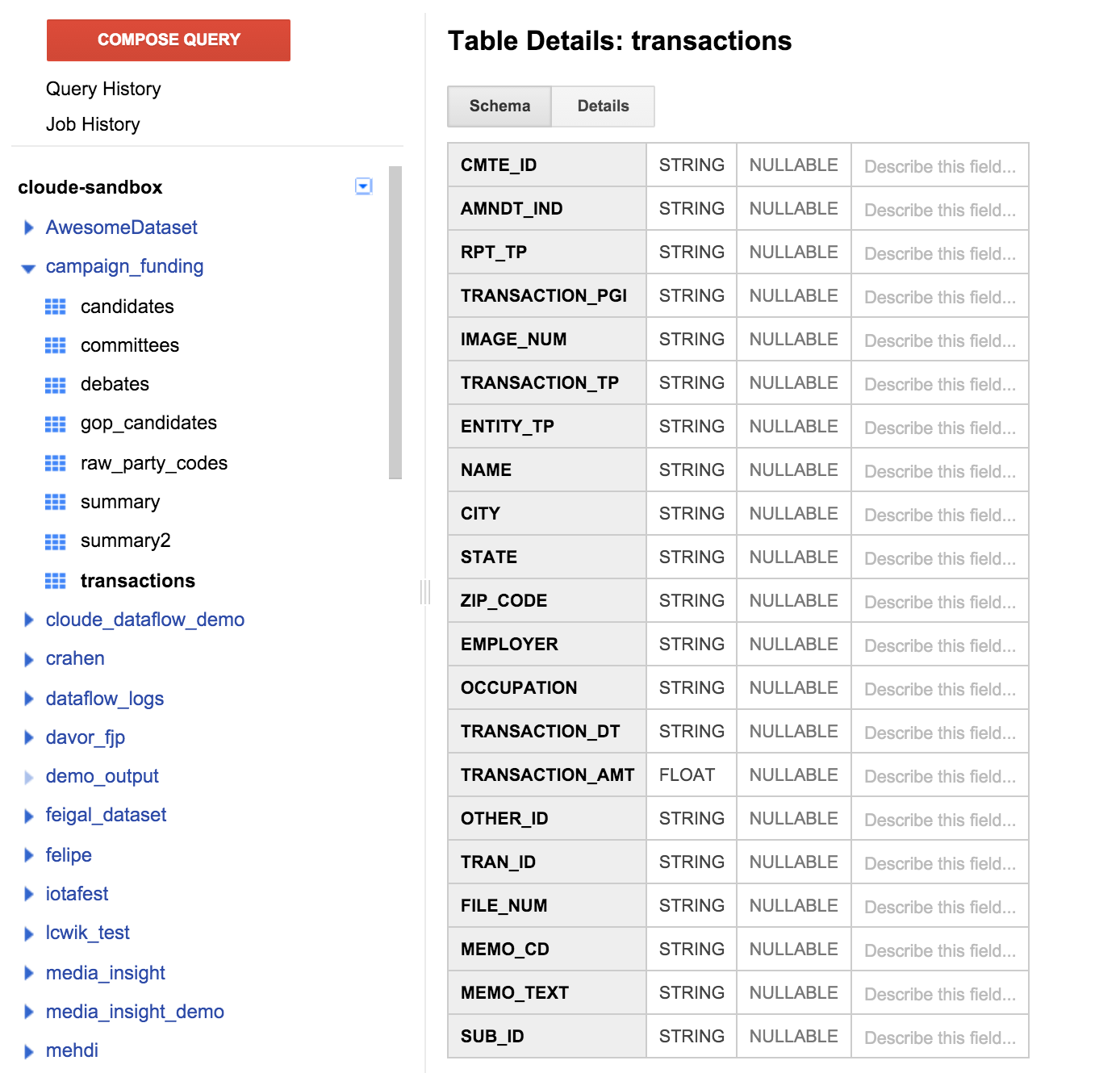
Possiamo visualizzare un elenco di campi che corrispondono alla definizione della tabella specificata in precedenza. Potresti notare che non è presente alcun campo destinatario o se è possibile stabilire quale sia il candidato supportato per la donazione. Tuttavia, è presente un campo chiamato CMTE_ID. In questo modo potremo collegare il comitato che ha ricevuto la donazione alla donazione. Non è ancora utile.
Successivamente, fai clic sulla tabella delle commissioni per controllare lo schema. Abbiamo un CMET_ID, che può partecipare alla tabella delle transazioni. Un altro campo è CAND_ID, a cui è possibile unire una tabella CAND_ID nella tabella dei candidati. Infine, abbiamo un collegamento tra le transazioni e i candidati tramite la tabella delle commissioni.
Tieni presente che non è presente una scheda di anteprima per le tabelle basate su GCS. Questo perché, per leggere i dati, BigQuery deve eseguire la lettura da un'origine dati esterna. Facciamo un esempio dei dati eseguendo una semplice query "SELECT *' nella tabella dei candidati.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
Il risultato dovrebbe essere simile al seguente:
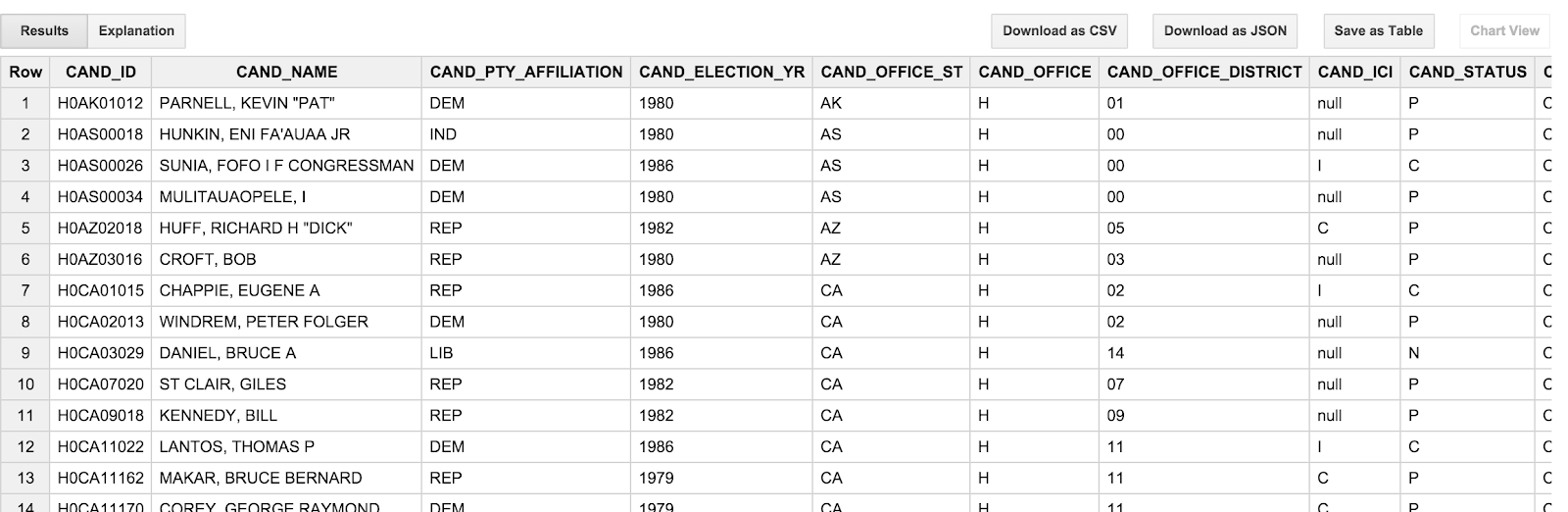
Una cosa che potresti notare è che i nomi dei candidati sono TUTTI MAIUSCOLI e sono presentati in ordine "cognome, nome". È un po' fastidioso, perché in questo modo tendiamo a pensare ai candidati; vediamo piuttosto "Barack Obama" che "OBAMA, BARACK". Inoltre, le date delle transazioni (TRANSACTION_DT) nella tabella delle transazioni sono un po' imbarazzo. Sono valori stringa nel formato YYYYMMDD. Analizzeremo queste peculiarità nella sezione successiva.
Ora che abbiamo capito come le transazioni sono correlate ai candidati, eseguiamo una query per capire chi sta dando dei soldi. Taglia e incolla la seguente query nella casella di scrittura:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
Questa query unisce la tabella delle transazioni alla tabella dei comitati e poi alla tabella dei candidati. ma tiene conto solo delle transazioni effettuate da persone che contengono la parola"ENGINEER"nel titolo. La query aggrega i risultati per affiliazione del partito; questo ci consente di vedere la distribuzione dei contributi ai vari partiti politici tra gli ingegneri.
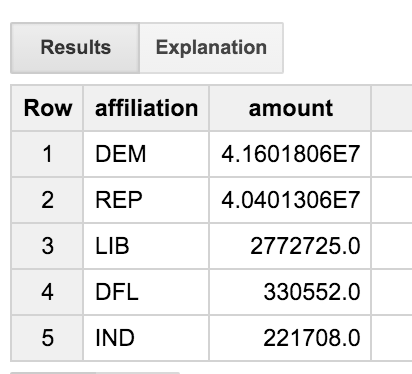
Possiamo notare che gli ingegneri sono un gruppo piuttosto equilibrato, che offre in modo più o meno uniforme ai democratici e ai repubblicani. Ma cos'è il gruppo DFL'? Non sarebbe bello avere nomi completi, invece di un codice di tre lettere?
I codici del gruppo sono definiti sul sito web della FEC. C'è una tabella che corrisponde al codice del partito con il nome completo (lo risulta "DFL' è "Democratic-Farmer-Labor'";). Sebbene sia possibile eseguire manualmente le traduzioni nella query, questo sembra essere un lavoro impegnativo e difficile da sincronizzare.
E se volessimo analizzare l'HTML come parte della query? Fai clic con il pulsante destro del mouse in un punto qualsiasi della pagina e controlla "Sorgente pagina di visualizzazione". Le informazioni sull'intestazione/boilerplate sono molte nell'origine, ma trova il tag <table>. Ogni riga di mappatura si trova in un elemento HTML <tr> e il nome e il codice sono entrambi aggregati negli elementi <td>. Ogni riga sarà simile a questa:
L'HTML ha un aspetto simile al seguente:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
Tieni presente che BigQuery non può leggere il file direttamente dal Web, perché BigQuery è in grado di raggiungere un'origine da migliaia di worker contemporaneamente. Se fosse consentita l'esecuzione su pagine web casuali, si tratterebbe essenzialmente di un attacco denial of service (DDoS). Il file HTML della pagina web FEC viene archiviato nel bucket gs://campaign-funding.
Dobbiamo fare una tabella basata sui dati di finanziamento della campagna. Questo campo sarà simile a quello delle altre tabelle supportate da GCS. La differenza qui è che non abbiamo in effetti uno schema; utilizzeremo un solo campo per riga e lo chiameremo "data' Si suppone che si tratti di un file CSV, con la virgola ma non la virgola, ma utilizzeremo un delimitatore fasullo (`) e nessuna citazione.
Per creare la tabella di ricerca del gruppo, esegui questi comandi dalla riga di comando:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
Ora utilizzeremo JavaScript per analizzare il file. In alto a destra in BigQuery Query Editor deve essere presente un pulsante con l'etichetta "UDF Editor". Fai clic sull'opzione per passare alla modifica di una UDF JavaScript. L'editor dell'UDF verrà completato con alcuni boilerplate commentati.

Elimina il codice che contiene e inserisci il seguente codice:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
Il codice JavaScript qui è diviso in due parti: la prima è una funzione che usa una riga di input emette un output analizzato. L'altra è una definizione che registra tale funzione come Funzione definita dall'utente (UDF) con il nome tableParser e indica che richiede una colonna di input chiamata "data' e genera due colonne, codice e nome. La colonna del codice sarà il codice di tre lettere, mentre la colonna del nome è il nome completo del gruppo.
Torna alla scheda "Editor query" e inserisci la query seguente:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
Questa query analizza il file HTML non elaborato e restituisce i valori dei campi in formato strutturato. Fantastico, eh? Prova a capire cosa significa "DFL'".
Ora che possiamo tradurre i codici di terze parti in nomi, proviamo un'altra query che utilizza questo codice per scoprire qualcosa di interessante. Esegui la seguente query:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
Questa query mostra quali candidati hanno ricevuto il maggior numero di donazioni alla campagna e sottolineano l'affiliazione del gruppo.
Queste tabelle non sono molto grandi e richiedono circa 30 secondi per essere query. Se hai intenzione di fare molto lavoro con le tabelle, probabilmente dovrai importarle in BigQuery. Puoi eseguire una query ETL in base alla tabella per obbligare i dati a qualcosa di facile da usare e poi salvarla come tabella permanente. Ciò significa che non devi sempre ricordare come tradurre i codici del gruppo e puoi anche filtrare i dati errati mentre lo fai.
Fai clic sul pulsante "Mostra opzioni" e poi sul pulsante "Seleziona tabella" accanto all'etichetta "Destination Table". Scegli il set di dati campaign_funding e inserisci l'ID tabella come "summary'. Seleziona la casella di controllo "allow large results'".

Ora esegui la seguente query:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
Questa query è molto più lunga e ha alcune opzioni di pulizia aggiuntive. Ad esempio, ignora tutto ciò in cui l'importo è superiore a 1.000.000 $. Usa anche espressioni regolari per trasformare "LASTNAME, FIRSTNAME" in "FIRSTNAME LASTNAME". Se ti senti in vena di avventure, prova a scrivere una funzione definita dall'utente per fare ancora di più e correggi le lettere maiuscole (ad esempio "Firstname Lastname";
Infine, prova a eseguire un paio di query sulla tabella campaign_funding.summary per verificare che le query correlate alla tabella siano più veloci. Non dimenticare di rimuovere prima l'opzione di query della tabella di destinazione, altrimenti potresti sovrascrivere la tabella di riepilogo.
Hai cancellato e importato i dati dal sito web della FEC in BigQuery.
Cosa abbiamo trattato
- Utilizzo di tabelle supportate da GCS in BigQuery.
- Utilizzo delle funzioni definite dall'utente in BigQuery.
Passaggi successivi
- Prova a rispondere a qualche domanda interessante per scoprire chi sta dando i suoi frutti a questo ciclo elettorale.
Scopri di più
- Scopri di più su cosa puoi fare con le funzioni definite dall'utente.
- Ulteriori informazioni sulle origini dati federate(tra cui GCS).
- Pubblica le domande e trova le risposte su Stackoverflow sotto il tag google-bigquery.
Inviaci il tuo feedback
- Non esitare a utilizzare il link in basso a sinistra in questa pagina per segnalare problemi o condividere feedback.