
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على كيفية استخدام بعض الميزات المتقدّمة في BigQuery، بما في ذلك:
- الدوال من تحديد المستخدم في JavaScript
- الجداول المقسّمة
- طلبات البحث المباشرة مقابل البيانات الموجودة في Google Cloud Storage وGoogle Drive.
ستتمكّن من جمع بيانات من لجنة الانتخابات الفيدرالية الأمريكية وتنظيفها وتحميلها إلى BigQuery. وستتاح لك أيضًا فرصة لطرح بعض الأسئلة المثيرة للاهتمام بشأن مجموعة البيانات هذه.
على الرغم من أنّ هذا الدرس التطبيقي البرمجي لا يفترض أي خبرة سابقة في BigQuery، سيساعدك بعض فهم لغة الاستعلامات البنيوية (SQL) على الاستفادة منها بشكل أكبر.
ما ستتعرَّف عليه
- كيفية استخدام "الدوال المحدّدة من قِبل المستخدم" لتنفيذ العمليات التي يصعب تنفيذها في SQL.
- كيفية استخدام BigQuery لإجراء عمليات ETL (الاستخراج والتحويل والتحميل) على البيانات المتوفرة في متاجر بيانات أخرى، مثل Google Cloud Storage وGoogle Drive.
الأشياء التي تحتاج إليها
- مشروع على Google Cloud تم تفعيل الفوترة به
- حزمة Google Cloud Storage
- تم تثبيت Google Cloud SDK
كيف ستستخدم هذا البرنامج التعليمي؟
كيف تقيّم مستوى تجربتك في BigQuery؟
إعداد البيئة الذاتية
إذا لم يكن لديك حساب على Google (Gmail أو Google Apps)، يجب إنشاء حساب. تسجيل الدخول إلى وحدة تحكُّم Google Cloud Platform (console.cloud.google.com) وإنشاء مشروع جديد:



عذرًا! وسيُشار إليه لاحقًا في هذا الدرس التطبيقي بعنوان PROJECT_ID.
بعد ذلك، ستحتاج إلى تفعيل الفوترة في Cloud Console لاستخدام موارد Google Cloud.
من المفترض ألا يكلفك العمل على هذا الدرس التطبيقي أكثر من بضعة دولارات، ولكن قد يترتّب عليك أكثر إذا قررت استخدام المزيد من الموارد أو إذا تركتها قيد التشغيل (راجع قسم "عرض الأسعار التقديري" في نهاية هذا المستند).
يكون المستخدمون الجدد لخدمة Google Cloud Platform مؤهَّلين للاستفادة من فترة تجريبية مجانية تبلغ 300 دولار أمريكي.
Google Cloud Shell
على الرغم من إمكانية تشغيل Google Cloud وBig Query عن بُعد من الكمبيوتر المحمول، فإننا في هذا الدرس التطبيقي سنستخدم Google Cloud Shell، وهو عبارة عن بيئة سطر أوامر يتم تشغيلها في السحابة الإلكترونية.
يتم تحميل هذا الجهاز الافتراضي الذي يعمل بنظام التشغيل Debian بكل أدوات التطوير التي ستحتاج إليها. وتوفِّر هذه الآلة دليلاً رئيسيًا دائمًا بسعة 5 غيغابايت ويتمّ تشغيله على Google Cloud، ما يحسّن كثيرًا أداء الشبكة والمصادقة. ويعني ذلك أنّ كل ما ستحتاج إليه في هذا الدرس التطبيقي هو متصفّح (نعم، يعمل على جهاز Chromebook).
لتفعيل Google Cloud Shell، من وحدة تحكّم مطوّري البرامج، انقر على الزر في أعلى يسار الصفحة (من المفترض أن تستغرق إدارة الحسابات والاتصال بضع لحظات فقط):

انقر على الزر &بدء؛ Cloud Shell &":


بعد الاتصال بواجهة السحابة الإلكترونية، من المفترض أن ترى أنه قد تمت المصادقة عليك وأن المشروع قد سبق وتم ضبطه على PROJECT_ID :
gcloud auth list
مخرجات الأوامر
Credentialed accounts: - <myaccount>@<mydomain>.com (active)
gcloud config list project
مخرجات الأوامر
[core] project = <PROJECT_ID>
تضبط Cloud Shell أيضًا بعض متغيّرات البيئة تلقائيًا والتي قد تكون مفيدة عند تشغيل الأوامر المستقبلية.
echo $GOOGLE_CLOUD_PROJECT
مخرجات الأوامر
<PROJECT_ID>
إذا لم يتم إعداد المشروع لسبب ما، فما عليك سوى إصدار الأمر التالي :
gcloud config set project <PROJECT_ID>
هل تبحث عن PROJECT_ID؟ تحقق من رقم التعريف الذي استخدمته في خطوات الإعداد أو ابحث عنه في لوحة بيانات وحدة التحكم:

ملاحظة مهمة: وأخيرًا، يمكنك ضبط المنطقة التلقائية وإعدادات المشروع:
gcloud config set compute/zone us-central1-f
يمكنك اختيار مجموعة متنوعة من المناطق المختلفة. اطّلع على مزيد من المعلومات في وثائق المناطق والمناطق؛
لتنفيذ طلبات بحث BigQuery في هذا الدرس التطبيقي حول الترميز، ستحتاج إلى مجموعة بيانات خاصة بك. اختَر اسمًا له، مثل campaign_funding. شغِّل الأوامر التالية في واجهة المستخدم (على سبيل المثال، CloudShell):
$ DATASET=campaign_funding
$ bq mk -d ${DATASET}
Dataset 'bq-campaign:campaign_funding' successfully created.
بعد إنشاء مجموعة البيانات، يجب أن تكون جاهزًا للبدء. من المفترض أن يساعد تشغيل هذا الأمر أيضًا في التحقق من أنك أعددت برنامج سطر الأوامر bq بشكل صحيح وأن المصادقة تعمل وأنه لديك إمكانية الدخول إلى مشروع السحابة الإلكترونية الذي تعمل بموجبه. إذا كان لديك أكثر من مشروع واحد، سيُطلب منك اختيار المشروع الذي يهمّك من قائمة.

تم إلغاء ضغط مجموعة البيانات المالية في حملة لجنة الانتخابات الفيدرالية الأمريكية ونسخها إلى حزمة GCS gs://campaign-funding/.
لنبدأ بتنزيل أحد ملفات المصدر محليًا حتى نتمكن من معرفة الشكل الذي تظهر به. شغِّل الأوامر التالية من نافذة أوامر:
$ gsutil cp gs://campaign-funding/indiv16.txt . $ tail indiv16.txt
ويجب أن يتم عرض محتوى ملف المساهمات الفردية. هناك ثلاثة أنواع من الملفات التي سندرسها في هذا الدرس التطبيقي حول الترميز: المساهمات الفردية (indiv*.txt) والمرشحون (cn*.txt) واللجان (cm*.txt). إذا كنت مهتمًا، استخدِم الآلية نفسها للاطّلاع على محتوى هذه الملفات الأخرى.
لن نحمِّل البيانات الأولية مباشرةً إلى BigQuery، وبدلاً من ذلك سنجري طلب بحث من Google Cloud Storage. لإجراء ذلك، نحتاج إلى معرفة المخطط وبعض المعلومات عنه.
يتم وصف مجموعة البيانات على الموقع الإلكتروني للانتخابات الفيدرالية هنا. مخططات الجداول التي سنستعرضها هي:
للربط بالجداول، يجب إنشاء تعريف لها يتضمّن المخططات. شغِّل الأوامر التالية لإنشاء تعريفات جدول فردية:
$ bq mkdef --source_format=CSV \
gs://campaign-funding/indiv*.txt \
"CMTE_ID, AMNDT_IND, RPT_TP, TRANSACTION_PGI, IMAGE_NUM, TRANSACTION_TP, ENTITY_TP, NAME, CITY, STATE, ZIP_CODE, EMPLOYER, OCCUPATION, TRANSACTION_DT, TRANSACTION_AMT:FLOAT, OTHER_ID, TRAN_ID, FILE_NUM, MEMO_CD, MEMO_TEXT, SUB_ID" \
> indiv_def.json
افتح الملف indiv_dev.json باستخدام محرِّر النصوص المفضّل لديك وألقِ نظرة على المحتوى، لأنه يحتوي على ملف json يصف كيفية تفسير ملف بيانات FEC.
سنحتاج إلى إجراء تعديلين صغيرين في القسم csvOptions. أضف قيمة fieldDelimiter لـ "|" وقيمة quote لـ "" (السلسلة الفارغة). ويُعدّ هذا الإجراء ضروريًا لأنّ ملف البيانات غير مفصول بفواصل، لأنه مفصول بفواصل:
$ sed -i 's/"fieldDelimiter": ","/"fieldDelimiter": "|"/g; s/"quote": "\\""/"quote":""/g' indiv_def.json
يجب أن يكون ملف indiv_dev.json على النحو التالي :
"fieldDelimiter": "|",
"quote":"",
ونظرًا لأن إنشاء تعريفات الجدول لجداول اللجنة والمرشحين متشابهة، ويحتوي المخطط على جزء مناسب من النص النموذجي، فلنبدأ في تنزيل هذه الملفات فقط.
$ gsutil cp gs://campaign-funding/candidate_def.json . Copying gs://campaign-funding/candidate_def.json... / [1 files][ 945.0 B/ 945.0 B] Operation completed over 1 objects/945.0 B. $ gsutil cp gs://campaign-funding/committee_def.json . Copying gs://campaign-funding/committee_def.json... / [1 files][ 949.0 B/ 949.0 B] Operation completed over 1 objects/949.0 B.
ستبدو هذه الملفات على غرار ملف indiv_dev.json. ملاحظة: يمكنك أيضًا تنزيل ملف indiv_def.json، في حال واجهت مشكلة في الحصول على القيم الصحيحة.
بعد ذلك، لنربط جدول BigQuery بهذه الملفات فعليًا. شغِّل الأوامر التالية:
$ bq mk --external_table_definition=indiv_def.json -t ${DATASET}.transactions
Table 'bq-campaign:campaign_funding.transactions' successfully created.
$ bq mk --external_table_definition=committee_def.json -t ${DATASET}.committees
Table 'bq-campaign:campaign_funding.committees' successfully created.
$ bq mk --external_table_definition=candidate_def.json -t ${DATASET}.candidates
Table 'bq-campaign:campaign_funding.candidates' successfully created.
سيؤدي هذا إلى إنشاء ثلاثة جداول Bigquery: المعاملات واللجان والمرشحون. يمكنك إجراء طلب بحث في هذه الجداول كما هي جداول BigQuery العادية، ولكن لا يتم تخزينها فعليًا في BigQuery، بل يتم تخزينها في Google Cloud Storage. إذا حدّثت الملفات الأساسية، ستنعكس التحديثات على الفور في طلبات البحث التي تجريها.
بعد ذلك، لنجرّب إجراء طلبي بحث. افتح واجهة مستخدم BigQuery على الويب.

ابحث عن مجموعة البيانات في مساحة الروابط على اليمين (قد تحتاج إلى تغيير القائمة المنسدلة للمشروع في أعلى يمين الصفحة)، ثم انقر على الزر الكبير "COMPOSE QUERY' " وأدخِل طلب البحث التالي في المربع:
SELECT * FROM [campaign_funding.transactions] WHERE EMPLOYER contains "GOOGLE" ORDER BY TRANSACTION_DT DESC LIMIT 100
يمكنك الاطّلاع على أحدث 100 تبرّع أجراه موظفو Google في الحملة. يمكنك تجربة التنقّل في الحملات والعثور على التبرّعات من المقيمين في رمزك البريدي أو البحث عن أكبر التبرّعات في مدينتك.
سيبدو طلب البحث والنتائج على النحو التالي:
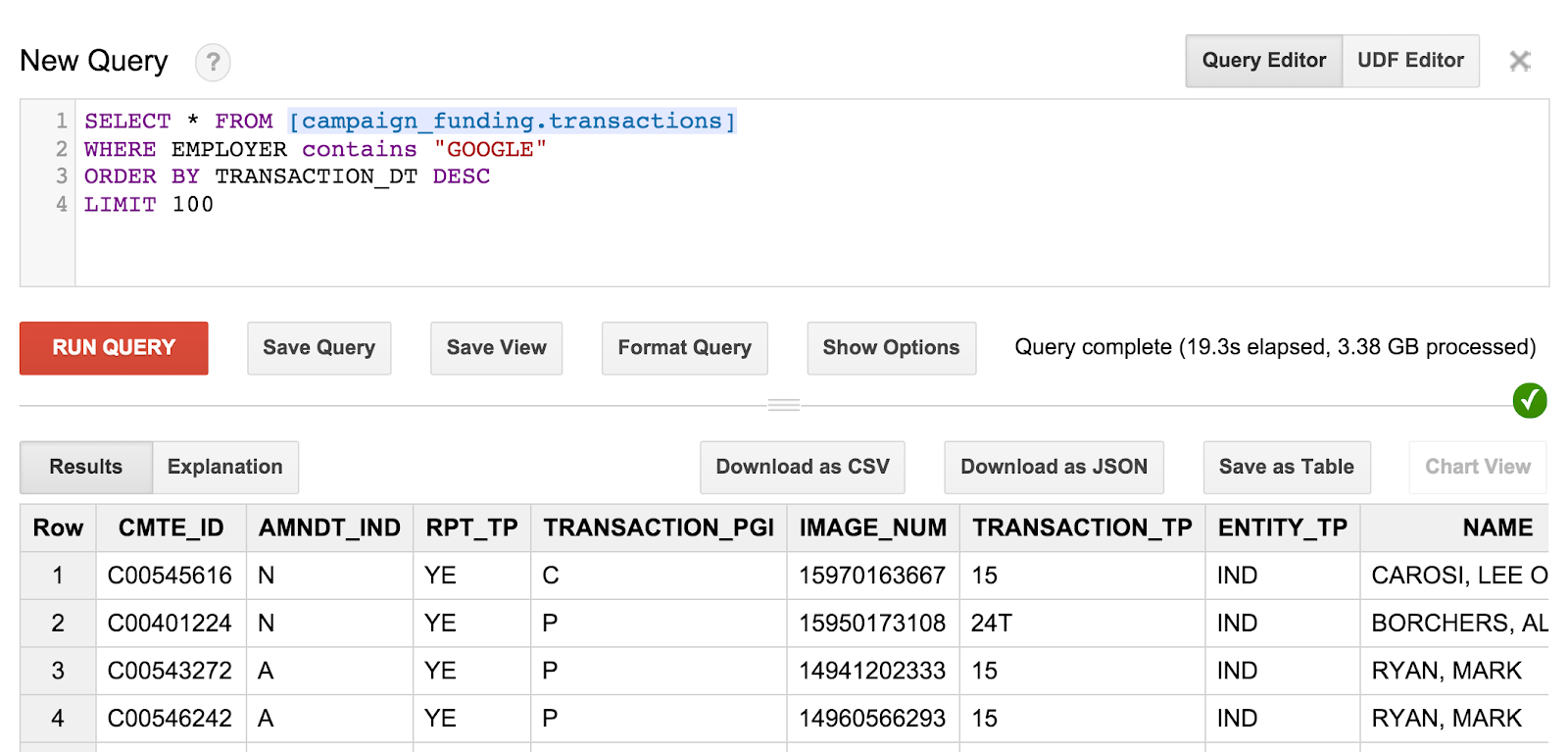
لكن إحدى الأمور التي قد تلاحظها هي أنه لا يمكنك معرفة مستلم هذه التبرعات. يجب أن تتوفّر لدينا بعض الطلبات الأكثر فائدةً للحصول على تلك المعلومات.
انقر على جدول المعاملات في اللوحة اليمنى، ثم انقر على علامة التبويب "المخطط". ومن المفترض أن يظهر محتوى لقطة الشاشة أدناه:
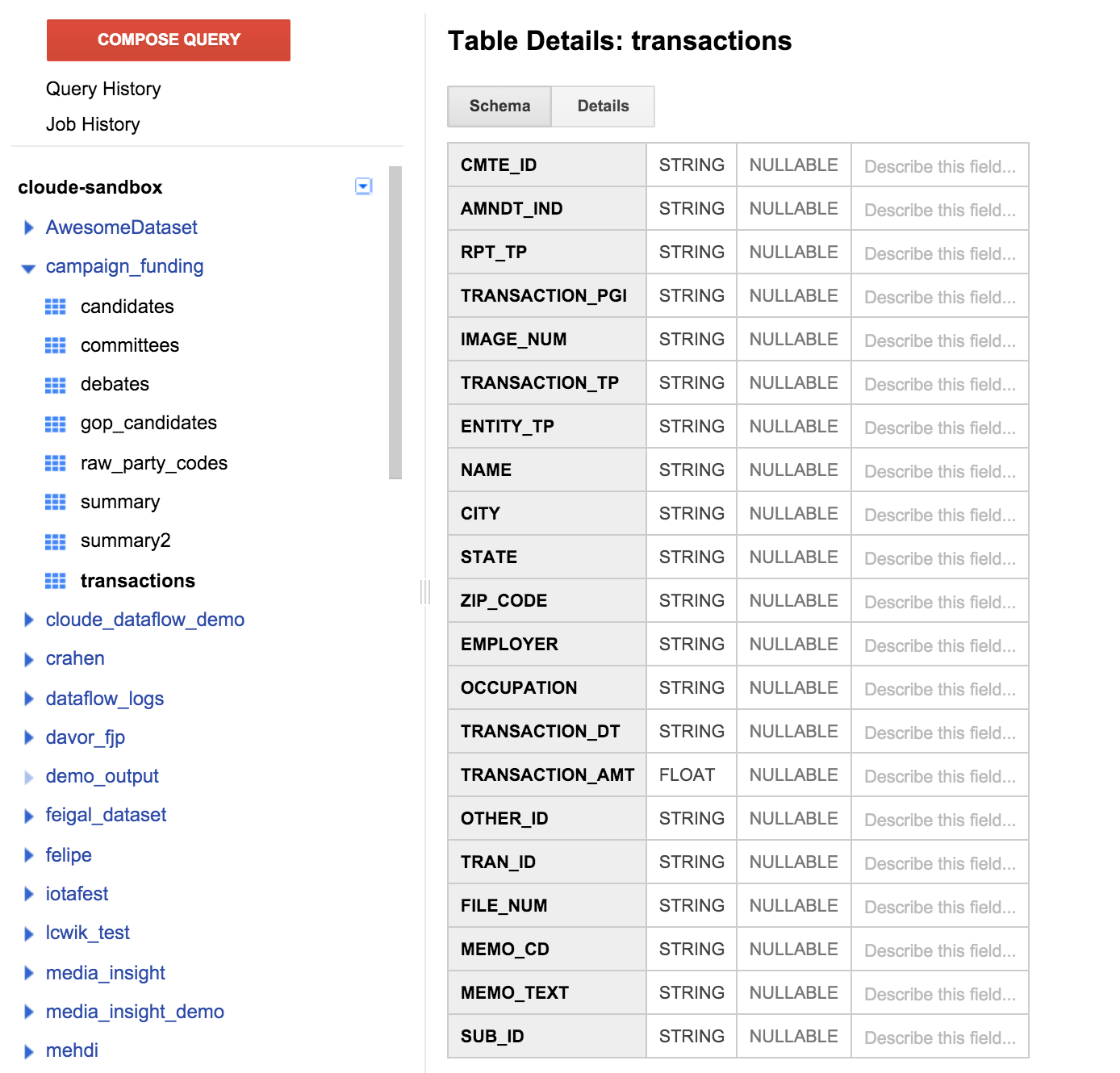
يمكننا عرض قائمة بالحقول التي تطابق تعريف الجدول الذي حدّدته سابقًا. قد تلاحظ عدم توفّر حقل للمستلِم أو أي طريقة لمعرفة المرشح الذي يدعم التبرّع. ومع ذلك، هناك حقل باسم CMTE_ID. وسيسمح لنا ذلك بربط اللجنة التي تلقت التبرّع بالتبرّع. لا يزال هذا غير مفيد.
بعد ذلك، انقر على جدول اللجان للاطّلاع على مخططها. لقد حصلت على CMET_ID الذي يمكن أن ينضم إلى جدول المعاملات. هناك حقل آخر هو CAND_ID. ويمكن ضم هذا الجدول باستخدام جدول CAND_ID في جدول المرشّحين. أخيرًا، لدينا رابط بين المعاملات والمرشحين من خلال مراجعة جدول اللجان.
ملاحظة: لا توجد علامة تبويب للمعاينة للجداول المستندة إلى GCS. ويرجع ذلك إلى أنه يجب قراءة BigQuery من مصدر بيانات خارجي لقراءة البيانات. لنبدأ الحصول على عيّنة من البيانات عن طريق تشغيل طلب بحث بسيط من "SELECT *'؛ في جدول العناصر المرشّحة.
SELECT * FROM [campaign_funding.candidates] LIMIT 100
ومن المفترض أن تظهر النتيجة على النحو التالي:
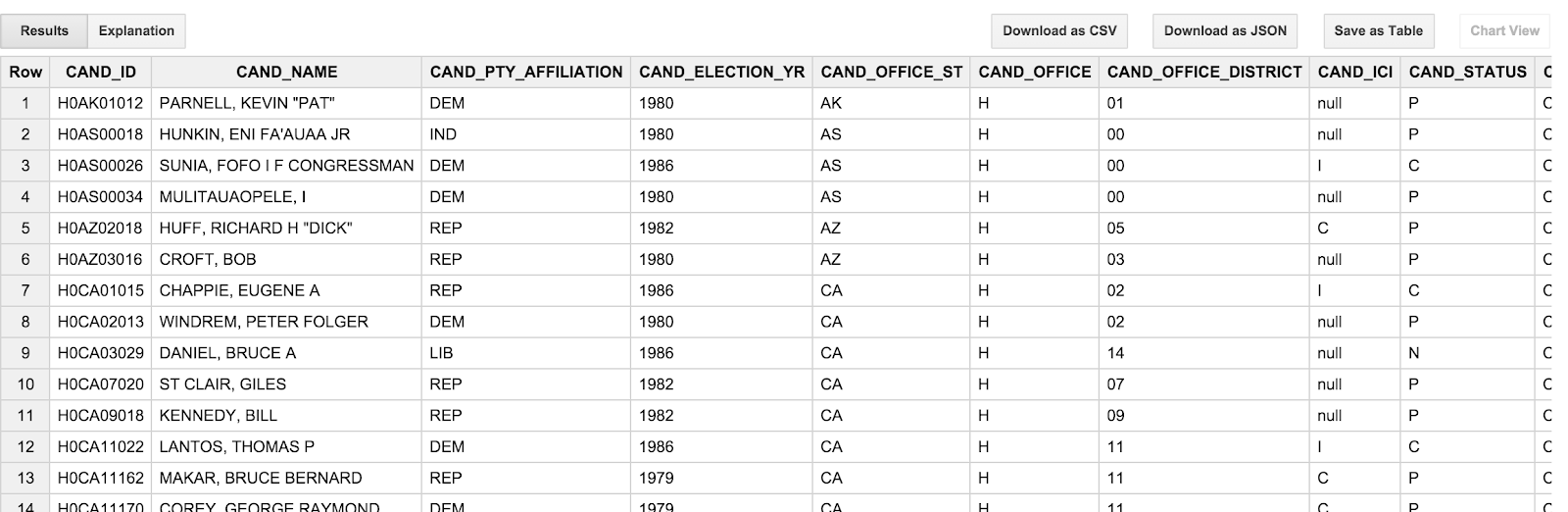
إنّ إحدى الكلمات الرئيسية التي قد تلاحظها هي أنّ أسماء المرشحين هي أحرف كبيرة بالكامل وتظهر في الترتيب "lastname, firstname". هذا مزعج إلى حد ما، ذلك لأن ذلك لا يفكّر عادةً في المرشحين بالإضافة إلى ذلك، فإنّ تواريخ المعاملات (TRANSACTION_DT) في جدول المعاملات غير مناسبة إلى حد ما. وهي قيم السلاسل بتنسيق YYYYMMDD. وسنتناول هذه الحالات في القسم التالي.
الآن بعد أن فهمنا كيفية ارتباط المعاملات بالمرشحين، لنجرّب طلب بحث لمعرفة الجهة التي تقدم الأموال لها. قص الطلب التالي والصقه في مربّع الإنشاء:
SELECT affiliation, SUM(amount) AS amount
FROM (
SELECT *
FROM (
SELECT
t.amt AS amount,
t.occupation AS occupation,
c.affiliation AS affiliation,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
trans.OCCUPATION AS occupation,
cmte.CAND_ID AS CAND_ID
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS CAND_ID
FROM [campaign_funding.committees]
GROUP EACH BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FROM [campaign_funding.candidates]
GROUP EACH BY CAND_ID) c
ON t.CAND_ID = c.CAND_ID )
WHERE occupation CONTAINS "ENGINEER")
GROUP BY affiliation
ORDER BY amount DESC
يؤدي هذا الطلب إلى ربط جدول المعاملات بجدول اللجان، ثم إلى جدول المرشحين. وهو ينظر فقط إلى المعاملات التي يجريها الأشخاص الذين يحملون الكلمة &قول:ENGINEER"؛ في مسمى المهنة. يجمع الطلب النتائج حسب الانتماء الحزبي، ويتيح لنا ذلك معرفة كيفية توزيع التبرّعات على مختلف الأحزاب السياسية بين المهندسين.
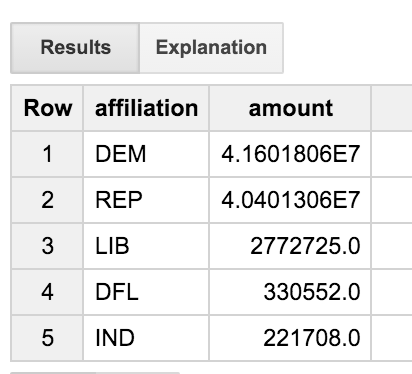
نلاحظ أنّ المهندسين يعبّرون عن مجموعة متوازنة نوعًا ما ويمنحون الديمقراطيين الجمهوريين قدرًا أكبر أو أقل من ذلك. ما هو المقصود بـ DFL'؟ أليس من الرائع أن تحصل على الأسماء الكاملة، وليس مجرد رمز من ثلاثة أحرف؟
يتم تحديد رموز الجهات على موقع لجنة الانتخابات الفيدرالية. هناك جدول يتطابق مع رمز الحزب مع الاسم الكامل (اتضح أن "DFL' هو "Democratic-Farmer-Labor'"). بينما يمكننا إجراء الترجمات يدويًا في طلب البحث، يبدو أن هذا يتطلب الكثير من العمل ويصعب الحفاظ على تزامنها.
ماذا لو كان بإمكاننا تحليل HTML كجزء من طلب البحث؟ انقر بزر الماوس الأيمن على أي مكان في هذه الصفحة، واطلّع على &عرض مصدر الصفحة. وثمة الكثير من المعلومات حول العناوين / النماذج النموذجية في المصدر، ولكن ابحث عن العلامة <table>. يظهر كل صف ربط في عنصر HTML <tr>، ويتم تضمين الاسم والرمز في عناصر <td>. سيبدو كل صف على النحو التالي:
تظهر لغة HTML على النحو التالي:
<tr bgcolor="#F5F0FF">
<td scope="row"><div align="left">ACE</div></td>
<td scope="row">Ace Party</td>
<td scope="row"></td>
</tr>
تجدر الإشارة إلى أن BigQuery لا يمكنه قراءة الملف مباشرةً من الويب، وذلك لأن Bigquery قادر على الوصول إلى مصدر من آلاف العاملين في آنٍ واحد. وبالتالي، إذا كان مسموحًا بتشغيل هذه الصفحات على صفحات ويب عشوائية، قد يكون هذا سببًا أساسيًا لهجوم رفض الخدمة (DDoS). يتم تخزين ملف HTML من صفحة الويب التابعة للجنة الانتخابات الفيدرالية في حزمة gs://campaign-funding.
وسنحتاج إلى إنشاء جدول استنادًا إلى بيانات تمويل الحملة. سيكون هذا مشابهًا للجداول الأخرى التي تم إنشاؤها باستخدام GCS التي أنشأناها. ويكمن الاختلاف هنا في أنه ليس لدينا مخطط في الواقع، فلن نستخدم إلا حقلًا واحدًا لكل صف وسنطلق عليه اسم "data'؛ وسنتعرّف على أنه ملف CSV، ونشير إلى أنه بدلاً من إلغاء تحديد الفاصلة، سنستخدم مُحدِّدًا مزيَّفًا (`) بدون حرف اقتباس.
ولإنشاء جدول بحث الطرف، شغِّل الأوامر التالية من سطر الأوامر:
$ echo '{"csvOptions": {"allowJaggedRows": false, "skipLeadingRows": 0, "quote": "", "encoding": "UTF-8", "fieldDelimiter": "`", "allowQuotedNewlines": false}, "ignoreUnknownValues": true, "sourceFormat": "CSV", "sourceUris": ["gs://campaign-funding/party_codes.shtml"], "schema": {"fields": [{"type": "STRING", "name": "data"}]}}' > party_raw_def.json
$ bq mk --external_table_definition=party_raw_def.json \
-t ${DATASET}.raw_party_codes
Table 'bq-campaign:campaign_funding.raw_party_codes' successfully created.
سنستخدم الآن JavaScript لتحليل الملف. في أعلى يسار الصفحة في "محرّر طلب بحث BigQuery"، يجب أن يظهر زر مُسمَّى "UDF Editor". انقر عليها للتبديل إلى تعديل UDF في JavaScript. ستتم تعبئة محرر UDF ببعض النماذج النموذجية التي تم التعليق عليها.

يُرجى حذف الرمز الذي تحتوي عليه وإدخال الرمز التالي:
function tableParserFun(row, emitFn) {
if (row.data != null && row.data.match(/<tr.*<\/tr>/) !== null) {
var txt = row.data
var re = />\s*(\w[^\t<]*)\t*<.*>\s*(\w[^\t<]*)\t*</;
matches = txt.match(re);
if (matches !== null && matches.length > 2) {
var result = {code: matches[1], name: matches[2]};
emitFn(result);
} else {
var result = { code: 'ERROR', name: matches};
emitFn(result);
}
}
}
bigquery.defineFunction(
'tableParser', // Name of the function exported to SQL
['data'], // Names of input columns
[{'name': 'code', 'type': 'string'}, // Output schema
{'name': 'name', 'type': 'string'}],
tableParserFun // Reference to JavaScript UDF
);
وينقسم JavaScript إلى قسمين، الأول هو وظيفة تأخذ صف إدخال من الإخراج الذي تم تحليله. والآخر هو تعريف يسجّل الدالة كدالة من تحديد المستخدم (UDF) بالاسم tableParser، ويشير إلى أنّه يأخذ عمود إدخال يُسمى "data'، ويتم عرض عمودَين ورمز واسم. سيكون عمود الرمز هو الرمز المكوّن من ثلاثة أحرف، ويكون عمود الاسم هو الاسم الكامل للطرف.
انتقِل مرة أخرى إلى &علامة التبويب "محرّر طلب البحث"، وأدخِل طلب البحث التالي:
SELECT code, name FROM tableParser([campaign_funding.raw_party_codes]) ORDER BY code
وسيؤدي تنفيذ هذا الطلب إلى تحليل ملف HTML الأولي وإخراج قيم الحقل بتنسيق منظّم. أليس كذلك؟ تحقّق ممّا إذا كان بإمكانك التعرّف على "DFL'".
الآن وبعد أن تمكننا من ترجمة رموز الحفلات إلى أسماء، فلنجرّب طلب بحث آخر يستخدم ذلك لمعرفة شيء مثير للاهتمام. تنفيذ طلب البحث التالي:
SELECT
candidate,
election_year,
FIRST(candidate_affiliation) AS affiliation,
SUM(amount) AS amount
FROM (
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ',
REGEXP_EXTRACT(c.candidate_name,r'(\w+),')) AS candidate,
pty.candidate_affiliation_name AS candidate_affiliation,
c.election_year AS election_year,
t.amt AS amount,
FROM (
SELECT
trans.TRANSACTION_AMT AS amt,
cmte.committee_candidate_id AS committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CAND_ID) AS committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID ) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) AS t
RIGHT OUTER JOIN EACH (
SELECT
CAND_ID AS candidate_id,
FIRST(CAND_NAME) AS candidate_name,
FIRST(CAND_PTY_AFFILIATION) AS affiliation,
FIRST(CAND_ELECTION_YR) AS election_year,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT
code,
name AS candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation )
GROUP BY candidate, election_year
ORDER BY amount DESC
LIMIT 100
وسيعرض طلب البحث هذا المرشّحين الذين حصلوا على أكبر المبالغ التي تم التبرع بها في الحملة، كما سيوضح معلومات ارتباطهم الحزبي.
هذه الجداول ليست كبيرة جدًا، ويستغرق طلب البحث 30 ثانية تقريبًا. إذا كنت ستنجز الكثير من العمل باستخدام الجداول، فمن المحتمل أن تحتاج إلى استيرادها إلى BigQuery. يمكنك تنفيذ طلب بحث ETL مقابل الجدول لفرض البيانات على شيء سهل الاستخدام، ثم حفظه كجدول دائم. وهذا يعني أنك لن تضطر دائمًا إلى تذكّر كيفية ترجمة رموز الحفلات، كما يمكنك أيضًا فلترة البيانات الخاطئة أثناء إجراء ذلك.
انقر على الزر "عرض خيارات&العرض"، ثم الزر "اختيار جدول'؛ بجانب علامة الاقتباس &Destination Table". اختَر مجموعة بيانات campaign_funding، وأدخِل رقم تعريف الجدول على النحو التالي: "summary'، ضَع علامة في مربّع الاختيار "allow large results'؛".

شغِّل الآن طلب البحث التالي:
SELECT
CONCAT(REGEXP_EXTRACT(c.candidate_name,r'\w+,[ ]+([\w ]+)'), ' ', REGEXP_EXTRACT(c.candidate_name,r'(\w+),'))
AS candidate,
pty.candidate_affiliation_name as candidate_affiliation,
INTEGER(c.election_year) as election_year,
c.candidate_state as candidate_state,
c.office as candidate_office,
t.name as name,
t.city as city,
t.amt as amount,
c.district as candidate_district,
c.ici as candidate_ici,
c.status as candidate_status,
t.memo as memo,
t.state as state,
LEFT(t.zip_code, 5) as zip_code,
t.employer as employer,
t.occupation as occupation,
USEC_TO_TIMESTAMP(PARSE_UTC_USEC(
CONCAT(RIGHT(t.transaction_date, 4), "-",
LEFT(t.transaction_date,2), "-",
RIGHT(LEFT(t.transaction_date,4), 2),
" 00:00:00"))) as transaction_date,
t.committee_name as committee_name,
t.committe_designation as committee_designation,
t.committee_type as committee_type,
pty_cmte.committee_affiliation_name as committee_affiliation,
t.committee_org_type as committee_organization_type,
t.committee_connected_org_name as committee_organization_name,
t.entity_type as entity_type,
FROM (
SELECT
trans.ENTITY_TP as entity_type,
trans.NAME as name,
trans.CITY as city,
trans.STATE as state,
trans.ZIP_CODE as zip_code,
trans.EMPLOYER as employer,
trans.OCCUPATION as occupation,
trans.TRANSACTION_DT as transaction_date,
trans.TRANSACTION_AMT as amt,
trans.MEMO_TEXT as memo,
cmte.committee_name as committee_name,
cmte.committe_designation as committe_designation,
cmte.committee_type as committee_type,
cmte.committee_affiliation as committee_affiliation,
cmte.committee_org_type as committee_org_type,
cmte.committee_connected_org_name as committee_connected_org_name,
cmte.committee_candidate_id as committee_candidate_id
FROM [campaign_funding.transactions] trans
RIGHT OUTER JOIN EACH (
SELECT
CMTE_ID,
FIRST(CMTE_NM) as committee_name,
FIRST(CMTE_DSGN) as committe_designation,
FIRST(CMTE_TP) as committee_type,
FIRST(CMTE_PTY_AFFILIATION) as committee_affiliation,
FIRST(ORG_TP) as committee_org_type,
FIRST(CONNECTED_ORG_NM) as committee_connected_org_name,
FIRST(CAND_ID) as committee_candidate_id
FROM [campaign_funding.committees]
GROUP BY CMTE_ID
) cmte
ON trans.CMTE_ID = cmte.CMTE_ID) as t
RIGHT OUTER JOIN EACH
(SELECT CAND_ID as candidate_id,
FIRST(CAND_NAME) as candidate_name,
FIRST(CAND_PTY_AFFILIATION) as affiliation,
INTEGER(FIRST(CAND_ELECTION_YR)) as election_year,
FIRST(CAND_OFFICE_ST) as candidate_state,
FIRST(CAND_OFFICE) as office,
FIRST(CAND_OFFICE_DISTRICT) as district,
FIRST(CAND_ICI) as ici,
FIRST(CAND_STATUS) as status,
FROM [campaign_funding.candidates]
GROUP BY candidate_id) c
ON t.committee_candidate_id = c.candidate_id
JOIN (
SELECT code, name as candidate_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty
ON pty.code = c.affiliation
JOIN (
SELECT code, name as committee_affiliation_name
FROM (tableParser([campaign_funding.raw_party_codes]))) pty_cmte
ON pty_cmte.code = t.committee_affiliation
WHERE t.amt > 0.0 and REGEXP_MATCH(t.state, "^[A-Z]{2}$") and t.amt < 1000000.0
هذا الطلب أطول بكثير، ويحتوي على بعض خيارات الإزالة الإضافية. على سبيل المثال، تتجاهل أي قيمة أكبر من مليون دولار. وتستخدم أيضًا التعبيرات العادية لتحويل &&LASTNAME, FIRSTNAME;quot;إلى &"FIRSTNAME LASTNAME". وإذا كنت تتمتع بروح المغامرة، جرّب كتابة UDF لتحسين الأداء وإصلاح الأحرف الكبيرة (على سبيل المثال &"Firstname Lastname").
وأخيرًا، حاوِل تنفيذ بعض طلبات البحث في مقابل جدول campaign_funding.summary للتحقّق من أن طلبات البحث مقابل هذا الجدول أسرع. لا تنسَ إزالة خيار طلب جدول الوجهة أولاً، أو قد ينتهي بك الأمر باستبدال جدول الملخّص!
لقد أكملت الآن مسح البيانات واستيرادها من موقع لجنة الانتخابات الفيدرالية إلى BigQuery.
المواضيع التي تناولناها
- استخدام الجداول المستندة إلى GCS في BigQuery
- استخدام الدوال من تحديد المستخدم في BigQuery.
الخطوات التالية
- جرِّب بعض طلبات البحث المثيرة للاهتمام لمعرفة الجهة التي ستقدّم مبالغ مالية لهذه الدورة الانتخابية.
مزيد من المعلومات
- اطّلِع على مزيد من المعلومات عن الإجراءات التي يمكنك تنفيذها باستخدام الدوال التي يحدّدها المستخدم.
- اطّلع على مصادر البيانات الموحّدة (بما في ذلك GCS).
- يمكنك نشر أسئلة والعثور على إجابات على Stack Overflow ضمن علامة google-bigquery.
يُرجى إرسال ملاحظاتك إلينا.
- يمكنك استخدام الرابط في أسفل يمين هذه الصفحة لإرسال المشاكل أو مشاركة الملاحظات.