
Un schéma Google Cloud Search est une structure JSON qui définit les objets, les propriétés et les options pour l'indexation et l'interrogation des données. Votre connecteur de contenu utilise le schéma enregistré pour structurer et indexer les données du dépôt.
Pour créer un schéma, fournissez un objet de schéma JSON à l'API. Vous devez enregistrer un schéma pour chaque dépôt avant d'indexer les données.
Ce document décrit les bases de la création de schémas. Pour optimiser l'expérience de recherche, consultez Améliorer la qualité de la recherche.
Créer un schéma
Pour créer votre schéma Cloud Search, procédez comme suit :
- Identifier le comportement attendu des utilisateurs
- Initialiser une source de données
- Définir vos objets
- Définir les propriétés des objets
- Enregistrer votre schéma
- Indexer vos données
- Tester votre schéma
- Ajuster votre schéma
Identifier le comportement attendu des utilisateurs
Anticiper la façon dont les utilisateurs effectuent leurs recherches vous aide à définir votre stratégie de schéma. Pour une base de données de films, les utilisateurs peuvent rechercher "films avec Robert Redford". Votre schéma doit être compatible avec les requêtes de films avec un acteur particulier.
Pour aligner votre schéma sur le comportement des utilisateurs :
- Évaluer diverses requêtes émanant de différents utilisateurs.
- Identifiez les ensembles de données logiques, ou objets, tels qu'un "film".
- Identifiez les propriétés (attributs) telles que le titre ou la date de sortie.
- Identifiez les valeurs valides pour les propriétés, comme "Les Aventuriers de l'arche perdue".
- Déterminez les besoins de tri et de classement, comme l'ordre chronologique ou les notes de l'audience.
- Identifiez les propriétés du contexte, telles que le poste, pour améliorer les suggestions de saisie semi-automatique.
- Énumérez ces objets, propriétés et exemples de valeurs. Utilisez cette liste pour définir les options d'opérateur.
Initialiser votre source de données
Une source de données représente les données de dépôt indexées stockées dans Google Cloud. Consultez Gérer les sources de données tierces. Lorsqu'un utilisateur clique sur un résultat, Cloud Search le redirige vers l'élément à l'aide de l'URL de la requête d'indexation.
Définir vos objets
L'objet est l'unité fondamentale d'un schéma. Les structures logiques telles que "film" ou "personne" sont des objets. Chaque objet possède des propriétés telles que le titre, la durée ou le nom.
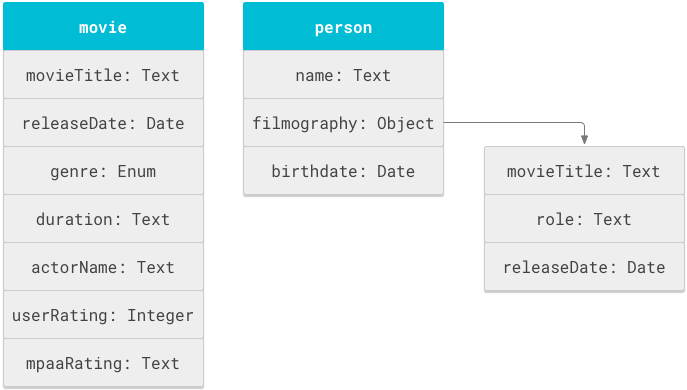
Un schéma est une liste de définitions d'objets dans la balise objectDefinitions.
{
"objectDefinitions": [
{ "name": "movie" },
{ "name": "person" }
]
}
Utilisez des noms uniques pour chaque objet, comme movie. Le service de schéma utilise ces noms comme clés. Consultez ObjectDefinition.
Définir les propriétés des objets
Définissez des propriétés, comme le titre et la date de sortie, dans la section propertyDefinitions. Utilisez options pour freshnessOptions (classement) et displayOptions (libellés d'interface utilisateur).
{
"objectDefinitions": [{
"name": "movie",
"propertyDefinitions": [
{
"name": "movieTitle",
"isReturnable": true,
"textPropertyOptions": {
"retrievalImportance": { "importance": "HIGHEST" },
"operatorOptions": { "operatorName": "title" }
},
"displayOptions": { "displayLabel": "Title" }
},
{
"name": "releaseDate",
"isReturnable": true,
"isSortable": true,
"datePropertyOptions": {
"operatorOptions": {
"operatorName": "released",
"lessThanOperatorName": "releasedbefore",
"greaterThanOperatorName": "releasedafter"
}
}
}
]
}]
}
Une PropertyDefinition inclut les éléments suivants :
- Chaîne
name. - Options non spécifiques au type (par exemple,
isReturnable). - Un type et des options spécifiques au type (par exemple,
textPropertyOptions). operatorOptionspour les opérateurs de recherche.displayOptionspour les libellés d'UI.
Vous pouvez réutiliser les noms de propriétés dans différents objets. Par exemple, movieTitle peut apparaître à la fois dans un objet movie et dans la filmographie d'un objet person.
Ajouter des options indépendantes du type
PropertyDefinition inclut des options booléennes permettant de configurer la fonctionnalité de recherche pour une propriété, quel que soit son type. Ces options sont définies sur false par défaut et doivent être définies sur true pour être utilisées.
isReturnable: défini surtruesi les données de la propriété doivent être renvoyées dans les résultats de recherche à l'aide de l'API Query. Les propriétés non renvoyables peuvent être utilisées pour la recherche ou le classement sans apparaître dans les résultats.isRepeatable: définissez surtruesi la propriété peut avoir plusieurs valeurs. Par exemple, un film a une seule date de sortie, mais peut avoir plusieurs acteurs.isSortable: définissez la valeur surtruesi la propriété peut être utilisée pour le tri. Ne peut pas êtretruesiisRepeatableesttrueou si la propriété se trouve dans un sous-objet reproductible.isFacetable: défini surtruesi la propriété peut être utilisée pour générer des facettes (attributs utilisés pour affiner les résultats de recherche).- Nécessite que
isReturnablesoit défini surtrue. - Disponible uniquement pour les propriétés "Enum", "Boolean" et "Text".
- Nécessite que
isWildcardSearchable: définissez surtruepour autoriser les utilisateurs à effectuer des recherches avec caractère générique sur cette propriété. Cette option n'est disponible que pour les propriétés de texte et son comportement dépend du paramètreexactMatchWithOperator:- Si
exactMatchWithOperatorest défini surtrue: la valeur de texte est traitée comme un jeton unique. Une requête telle quescience-*correspond à la valeurscience-fiction. - Si
exactMatchWithOperatorest défini surfalse: la valeur textuelle est tokenisée. Une requête telle quesci*oufi*correspond àscience-fiction, mais passcience-*.
- Si
Définir le type
Définissez le type de données en définissant l'objet d'options de propriété approprié (par exemple, textPropertyOptions). Utilisez des énumérations (enumPropertyOptions) si vous connaissez toutes les valeurs possibles. Une propriété ne peut avoir qu'un seul type de données.
Définir les options d'opérateur
operatorOptions décrire comment une propriété fonctionne en tant qu'opérateur de recherche.
Chaque operatorOptions a besoin d'un operatorName (par exemple, title). Il s'agit du paramètre que les utilisateurs saisissent dans les requêtes (par exemple, title:titanic). Utilisez des noms intuitifs et exposez-les aux utilisateurs.
Vous pouvez partager un operatorName entre des propriétés du même type. Les requêtes utilisant ce nom récupèrent les résultats de toutes les propriétés correspondantes.
Les propriétés triables peuvent inclure lessThanOperatorName et greaterThanOperatorName pour les requêtes de comparaison. Les propriétés de texte peuvent utiliser exactMatchWithOperator pour traiter l'intégralité de la valeur comme un jeton unique.
Ajouter des options d'affichage
La section facultative displayOptions contient un displayLabel. Il s'agit d'un libellé convivial affiché dans les résultats de recherche.
Ajouter des opérateurs de filtrage des suggestions
Utilisez suggestionFilteringOperators[] pour définir une propriété qui filtre les suggestions de saisie semi-automatique (par exemple, en filtrant les suggestions de films par genre préféré d'un utilisateur). Vous ne pouvez définir qu'un seul filtre de suggestions.
Enregistrer votre schéma
Enregistrez votre schéma auprès du service de schéma à l'aide de l'ID de votre source de données. Envoyez une requête UpdateSchema :
PUT https://cloudsearch.googleapis.com/v1/indexing/{name=datasources/*}/schema
Utilisez validateOnly: true pour tester votre schéma sans l'enregistrer.
Indexer vos données
Une fois la source de données enregistrée, remplissez-la à l'aide d'appels d'index, généralement avec un connecteur.
Exemple de requête d'indexation :
{
"name": "datasource/<data_source_id>/items/titanic",
"metadata": {
"title": "Titanic",
"objectType": "movie"
},
"structuredData": {
"object": {
"properties": [{
"name": "movieTitle",
"textValues": { "values": ["Titanic"] }
}]
}
},
"itemType": "CONTENT_ITEM"
}
Tester votre schéma
Testez avec un petit dépôt avant la production. Créez une LCA qui limite les résultats à un utilisateur test.
- Requête générique : recherchez une chaîne (par exemple, "titanic") pour afficher tous les éléments correspondants.
- Requête avec opérateur : utilisez un opérateur (par exemple,
actor:Zane) pour limiter les résultats.
Ajuster votre schéma
Surveillez les commentaires des utilisateurs et ajustez votre schéma. Vous pouvez indexer de nouveaux champs ou renommer des opérateurs pour les rendre plus intuitifs.
Réindexer après une modification du schéma
Vous n'avez pas besoin de réindexer les modifications suivantes :
- Noms d'opérateurs
- Limites numériques.
- Classement ordonné.
- Options d'actualisation ou d'affichage
Vous devez réindexer pour :
- Ajout ou suppression de propriétés ou d'objets
- Remplacement de
isReturnable,isFacetableouisSortablepartrue. - Marquer une propriété
isSuggestable.
Modifications de propriété non autorisées
Les modifications qui corrompent l'index ou entraînent des résultats incohérents ne sont pas autorisées, y compris :
- Type de données ou nom de la propriété.
- Paramètres
exactMatchWithOperatorouretrievalImportance.
Effectuer une modification de schéma complexe
Pour effectuer une modification non autorisée, migrez les propriétés d'une ancienne définition vers une nouvelle :
- Ajoutez une nouvelle propriété avec un nom différent au schéma.
- Enregistrez le schéma avec les nouvelles et les anciennes propriétés.
- Remplissez l'index en utilisant uniquement la nouvelle propriété.
- Supprimez l'ancienne propriété du schéma.
- Mettez à jour le code de votre requête pour utiliser le nouveau nom de propriété.
Cloud Search enregistre les éléments supprimés pendant 30 jours pour éviter les problèmes de réutilisation.
Limites de taille
- Maximum 10 objets de premier niveau.
- Profondeur maximale de 10 niveaux.
- Maximum de 1 000 champs par objet (y compris les champs imbriqués).
Étapes suivantes
- Créez une interface de recherche.
- Améliorer la qualité de la recherche :
- Structurez un schéma pour une interprétation optimale des requêtes.
- Définir des synonymes