
Возвращая ответ в Google Assistant, вы можете использовать в своих ответах подмножество языка разметки синтеза речи ( SSML ). Используя SSML, вы можете сделать ответы вашего разговора более похожими на естественную речь. Ниже показан пример разметки SSML и то, как она считывается Google Assistant.
function saySSML(conv) { const ssml = '<speak>' + 'Here are <say-as interpret-as="characters">SSML</say-as> samples. ' + 'I can pause <break time="3" />. ' + 'I can play a sound <audio src="https://www.example.com/MY_WAVE_FILE.wav">your wave file</audio>. ' + 'I can speak in cardinals. Your position is <say-as interpret-as="cardinal">10</say-as> in line. ' + 'Or I can speak in ordinals. You are <say-as interpret-as="ordinal">10</say-as> in line. ' + 'Or I can even speak in digits. Your position in line is <say-as interpret-as="digits">10</say-as>. ' + 'I can also substitute phrases, like the <sub alias="World Wide Web Consortium">W3C</sub>. ' + 'Finally, I can speak a paragraph with two sentences. ' + '<p><s>This is sentence one.</s><s>This is sentence two.</s></p>' + '</speak>'; conv.ask(ssml); }
{ "expectUserResponse": true, "expectedInputs": [ { "possibleIntents": [ { "intent": "actions.intent.TEXT" } ], "inputPrompt": { "richInitialPrompt": { "items": [ { "simpleResponse": { "textToSpeech": "<speak>Here are <say-as interpret-as=\"characters\">SSML</say-as> samples. I can pause <break time=\"3\" />. I can play a sound <audio src=\"https://www.example.com/MY_WAVE_FILE.wav\">your wave file</audio>. I can speak in cardinals. Your position is <say-as interpret-as=\"cardinal\">10</say-as> in line. Or I can speak in ordinals. You are <say-as interpret-as=\"ordinal\">10</say-as> in line. Or I can even speak in digits. Your position in line is <say-as interpret-as=\"digits\">10</say-as>. I can also substitute phrases, like the <sub alias=\"World Wide Web Consortium\">W3C</sub>. Finally, I can speak a paragraph with two sentences. <p><s>This is sentence one.</s><s>This is sentence two.</s></p></speak>" } } ] } } } ] }
Аудио
SSML поддерживается в симуляторе Actions , но не в симуляторе Dialogflow.
URL-адреса в SSML
При определении ответа SSML, который включает только URL-адрес, амперсанды в этом URL-адресе могут вызвать проблемы из-за форматирования XML. Чтобы обеспечить правильную ссылку на URL-адрес, замените экземпляры & на & .
Даже если ваш ответ SSML содержит только URL-адрес, Actions on Google требует отображать текст ответа. Поскольку текст внутри тега <audio> не будет озвучен Ассистентом, вы можете вставить текст-заполнитель или краткое описание в тег <audio> , чтобы удовлетворить этому требованию. Текст внутри тега <audio> не будет произноситься Ассистентом после воспроизведения звука и соответствует требованию Action on Google для отображаемой текстовой версии вашего SSML.
Вот пример проблемного ответа SSML:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
</audio>
</speak>
В приведенном выше примере не используется знак & для правильного форматирования XML.
Фиксированная версия того же ответа SSML выглядит следующим образом:
<speak>
<audio src="https://firebasestorage.googleapis.com/v0/b/project-name.appspot.com/o/audio-file-name.ogg?alt=media&token=XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX">
text
</audio>
</speak>
Поддержка элементов SSML
В следующих разделах описаны элементы и параметры SSML, которые можно использовать в ваших действиях.
<speak>
Корневой элемент ответа SSML.
Дополнительные сведения об элементе speak см. в спецификации W3 .
Пример
<speak> my SSML content </speak>
<break>
Пустой элемент, управляющий паузой или другими просодическими границами между словами. Использование <break> между любой парой токенов не является обязательным. Если этот элемент отсутствует между словами, разрыв определяется автоматически на основе лингвистического контекста.
Чтобы узнать больше об элементе break , смотрите спецификацию W3 .
Атрибуты
| Атрибут | Описание |
|---|---|
time | Устанавливает продолжительность перерыва в секундах или миллисекундах (например, «3 с» или «250 мс»). |
strength | Устанавливает силу просодического разрыва вывода в относительных терминах. Допустимые значения: «x-слабый», «слабый», «средний», «сильный» и «x-сильный». Значение «нет» указывает на то, что граница просодического разрыва не выводится, что можно использовать для предотвращения просодический разрыв, который в противном случае произвел бы процессор. Другие значения указывают монотонно неубывающую (концептуально возрастающую) силу разрыва между токенами. Более сильные границы обычно сопровождаются паузами. |
Пример
В следующем примере показано, как использовать элемент <break> для паузы между шагами:
<speak> Step 1, take a deep breath. <break time="200ms"/> Step 2, exhale. Step 3, take a deep breath again. <break strength="weak"/> Step 4, exhale. </speak>
<say‑as>
Этот элемент позволяет указать информацию о типе текстовой конструкции, содержащейся внутри элемента. Это также помогает указать уровень детализации для рендеринга содержащегося текста.
Элемент <say‑as> имеет обязательный атрибут interpret-as , который определяет, как произносится значение. format и detail необязательных атрибутов могут использоваться в зависимости от конкретного значения interpret-as .
Примеры
Атрибут interpret-as поддерживает следующие значения:
-
currencyСледующий пример произносится как «сорок два доллара и один цент». Если атрибут языка опущен, используется текущая локаль.
<speak> <say-as interpret-as='currency' language='en-US'>$42.01</say-as> </speak> telephoneСм. описание
interpret-as='telephone'в примечании WG к значениям атрибута Say-as W3C SSML 1.0.Следующий пример произносится как «один восемь ноль ноль два ноль два один два один два». Если атрибут «google:style» опущен, он обозначает ноль как букву О.
Атрибут «google:style='zero-as-zero'» в настоящее время работает только в языковых стандартах EN.
<speak> <say-as interpret-as='telephone' google:style='zero-as-zero'>1800-202-1212</say-as> </speak>verbatimилиspell-outСледующий пример пишется по буквам:
<speak> <say-as interpret-as="verbatim">abcdefg</say-as> </speak>-
dateАтрибут
formatпредставляет собой последовательность кодов символов поля даты. Поддерживаемые коды символов поля вformat: {y,m,d} для года, месяца и дня (месяца) соответственно. Если код поля появляется один раз для года, месяца или дня, то ожидаемое количество цифр равно 4, 2 и 2 соответственно. Если код поля повторяется, то количество ожидаемых цифр равно количеству повторений кода. Поля в тексте даты могут быть разделены знаками препинания и/или пробелами.Атрибут
detailуправляет устной формой даты. Дляdetail='1'обязательны только поля дня и одно из полей месяца или года, хотя можно указать оба. Это значение по умолчанию, если задано меньше всех трех полей. Разговорная форма: «{порядковый день} {месяца}, {года}».Следующий пример произносится как «Десятое сентября тысяча девятьсот шестьдесят»:
<speak> <say-as interpret-as="date" format="yyyymmdd" detail="1"> 1960-09-10 </say-as> </speak>Следующий пример называется «Десятое сентября»:
<speak> <say-as interpret-as="date" format="dm">10-9</say-as> </speak>Для
detail='2'поля дня, месяца и года являются обязательными, и это значение по умолчанию, когда указаны все три поля. Разговорная форма: «{месяц} {порядковый день}, {год}».Следующий пример произносится как «десятое сентября тысяча девятьсот шестьдесят»:
<speak> <say-as interpret-as="date" format="dmy" detail="2"> 10-9-1960 </say-as> </speak> -
charactersСледующий пример произносится как «CAN»:
<speak> <say-as interpret-as="characters">can</say-as> </speak> -
cardinalСледующий пример произносится как «Двенадцать тысяч триста сорок пять» (для американского английского) или «Двенадцать тысяч триста сорок пять (для британского английского)»:
<speak> <say-as interpret-as="cardinal">12345</say-as> </speak> -
ordinalСледующий пример произносится как «Первый»:
<speak> <say-as interpret-as="ordinal">1</say-as> </speak> -
fractionСледующий пример произносится как «пять с половиной»:
<speak> <say-as interpret-as="fraction">5+1/2</say-as> </speak> -
expletiveилиbleepСледующий пример звучит как звуковой сигнал, как будто он был подвергнут цензуре:
<speak> <say-as interpret-as="expletive">censor this</say-as> </speak> -
unitПреобразует единицы измерения в единственное или множественное число в зависимости от числа. Следующий пример произносится как «10 футов»:
<speak> <say-as interpret-as="unit">10 foot</say-as> </speak> -
timeСледующий пример произносится как «два тридцать вечера»:
<speak> <say-as interpret-as="time" format="hms12">2:30pm</say-as> </speak>Атрибут
formatпредставляет собой последовательность кодов символов поля времени. Поддерживаемые коды символов полей вformat: {h,m,s,Z,12,24} для часов, минут (часов), секунд (минут), часового пояса, 12-часового времени и 24-часового времени. соответственно. Если код поля появляется один раз для часов, минут или секунд, то ожидаемое количество цифр равно 1, 2 и 2 соответственно. Если код поля повторяется, то количество ожидаемых цифр равно количеству повторений кода. Поля в тексте времени могут быть разделены знаками препинания и/или пробелами. Если в формате не указаны час, минута или секунда или нет совпадающих цифр, поле рассматривается как нулевое значение.formatпо умолчанию — «hms12».Атрибут
detailопределяет, является ли устная форма времени 12-часовой или 24-часовой. Разговорная форма — 24-часовое время, еслиdetail='1'или еслиdetailопущена и формат времени — 24-часовое. Разговорная форма — 12-часовое время, еслиdetail='2'или еслиdetailопущена и формат времени — 12-часовое.
Дополнительные сведения об элементе say-as см. в спецификации W3 .
<audio>
Поддерживает вставку записанных аудиофайлов и вставку других аудиоформатов в сочетании с выводом синтезированной речи.
Атрибуты
| Атрибут | Необходимый | По умолчанию | Ценности |
|---|---|---|---|
src | да | н/д | URI, ссылающийся на источник аудиомедиа. Поддерживаемый протокол https . |
clipBegin | нет | 0 | Обозначение TimeDesignation , которое представляет собой смещение от начала источника звука, с которого начинается воспроизведение. Если это значение больше или равно фактической продолжительности источника звука, звук не вставляется. |
clipEnd | нет | бесконечность | Обозначение TimeDesignation , которое представляет собой смещение от начала аудиоисточника до окончания воспроизведения. Если фактическая продолжительность источника звука меньше этого значения, воспроизведение заканчивается в это время. Если clipBegin больше или равно clipEnd , звук не вставляется. |
speed | нет | 100% | Отношение выходной скорости воспроизведения к нормальной входной скорости, выраженное в процентах. Формат: положительное действительное число, за которым следует %. В настоящее время поддерживается диапазон [50% (медленно – половинная скорость), 200% (быстро – двойная скорость)]. Значения за пределами этого диапазона могут (а могут и не быть) скорректированы так, чтобы оказаться внутри него. |
repeatCount | нет | 1 или 10, если установлен repeatDur . | Действительное число, указывающее, сколько раз вставлять звук (после обрезки, если таковая имеется, с помощью clipBegin и/или clipEnd ). Дробные повторения не поддерживаются, поэтому значение будет округлено до ближайшего целого числа. Ноль не является допустимым значением и поэтому считается неопределенным и в этом случае имеет значение по умолчанию. |
repeatDur | нет | бесконечность | Обозначение TimeDesignation , которое является ограничением продолжительности вставленного звука после обработки источника для атрибутов clipBegin , clipEnd , repeatCount и speed (а не обычной длительности воспроизведения). Если продолжительность обработанного звука меньше этого значения, воспроизведение заканчивается в это время. |
soundLevel | нет | +0 дБ | Отрегулируйте уровень звука звука в децибелах soundLevel . Максимальный диапазон составляет +/-40 дБ, но фактический диапазон может быть меньше, а качество выходного сигнала может не дать хороших результатов во всем диапазоне. |
Ниже приведены поддерживаемые в настоящее время настройки звука:
- Формат: MP3 (MPEG v2)
- 24 тыс. выборок в секунду
- 24–96 000 бит в секунду, фиксированная скорость
- Формат: Opus в Ogg.
- 24 тыс. выборок в секунду (сверхширокополосный)
- 24–96 000 бит в секунду, фиксированная скорость
- Формат (устаревший): WAV (RIFF).
- PCM 16-битный, с прямым порядком байтов
- 24 тыс. выборок в секунду
- Для всех форматов:
- Предпочтителен один канал, но допускается стерео.
- Максимальная продолжительность 240 секунд. Если вы хотите воспроизводить аудио более продолжительное время, рассмотрите возможность реализации медиа-ответа .
- Ограничение размера файла 5 мегабайт.
- Исходный URL-адрес должен использовать протокол HTTPS.
- Нашим UserAgent при получении аудио является «Google-Speech-Actions».
Содержимое элемента <audio> не является обязательным и используется, если аудиофайл не может быть воспроизведен или устройство вывода не поддерживает звук. Содержимое может включать элемент <desc> и в этом случае для отображения используется текстовое содержимое этого элемента. Дополнительную информацию см. в разделе «Записанное аудио» в Контрольном списке ответов .
URL- src также должен быть URL-адресом https ( Google Cloud Storage может размещать ваши аудиофайлы по URL-адресу https).
Дополнительную информацию о реакциях СМИ см. в разделе «Ответы СМИ» в руководстве «Ответы».
Чтобы узнать больше об элементе audio , смотрите спецификацию W3 .
Пример
<speak> <audio src="cat_purr_close.ogg"> <desc>a cat purring</desc> PURR (sound didn't load) </audio> </speak>
<p>,<s>
Элементы предложения и абзаца.
Чтобы узнать больше об элементах p и s , смотрите спецификацию W3 .
Пример
<p><s>This is sentence one.</s><s>This is sentence two.</s></p>
Лучшие практики
- Используйте теги <s>...</s> для переноса полных предложений, особенно если они содержат элементы SSML, изменяющие просодию (то есть <audio>, <break>, <emphasis>, <par>, <prosody>, <say-as>, <seq> и <sub>).
- Если пауза в речи должна быть достаточно длинной, чтобы вы могли ее услышать, используйте теги <s>...</s> и поместите эту паузу между предложениями.
<sub>
Укажите, что текст в значении атрибута псевдонима заменяет содержащийся в нем текст для произношения.
Вы также можете использовать sub , чтобы обеспечить упрощенное произношение трудночитаемого слова. Последний пример ниже демонстрирует этот вариант использования на японском языке.
Подробнее о sub можно узнать в спецификации W3 .
Примеры
<sub alias="World Wide Web Consortium">W3C</sub>
<sub alias="にっぽんばし">日本橋</sub>
<mark>
Пустой элемент, который помещает маркер в текст или последовательность тегов. Его можно использовать для ссылки на определенное место в последовательности или для вставки маркера в выходной поток для асинхронного уведомления.
| Атрибут | Описание | ||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
name | Идентификатор строки для каждой метки. | ||||||||||||||||||||||||||||||||||||||||||
| Вариант | Описание |
|---|---|
| Родственник | Укажите относительное значение (например, «низкий», «средний», «высокий» и т. д.), где «средний» — это высота звука по умолчанию. |
| Полутона | Увеличьте или уменьшите высоту звука на « N » полутонов, используя «+ N st» или «- N st» соответственно. Обратите внимание, что «+/-» и «st» являются обязательными. |
| Процент | Увеличьте или уменьшите шаг на « N » процентов, используя «+ N %» или «- N %» соответственно. Обратите внимание, что «%» является обязательным, а «+/-» не является обязательным. |
Подробнее об элементе prosody можно узнать в спецификации W3 .
Пример
В следующем примере элемент <prosody> используется для медленной речи на 2 полутона ниже обычного:
<prosody rate="slow" pitch="-2st">Can you hear me now?</prosody>
<emphasis>
Используется для добавления или удаления выделения из текста, содержащегося в элементе. Элемент <emphasis> изменяет речь аналогично <prosody> , но без необходимости устанавливать отдельные атрибуты речи.
Этот элемент поддерживает необязательный атрибут «уровень» со следующими допустимыми значениями:
-
strong -
moderate -
none -
reduced
Подробнее об элементе emphasis см. в спецификации W3 .
Пример
В следующем примере для объявления используется элемент <emphasis> :
<emphasis level="moderate">This is an important announcement</emphasis>
<par>
Параллельный медиа-контейнер, позволяющий одновременно воспроизводить несколько медиа-элементов. Единственное разрешенное содержимое — это набор из одного или нескольких элементов <par> , <seq> и <media> . Порядок элементов <media> не имеет значения.
Если дочерний элемент не указывает другое время начала, неявное время начала для элемента такое же, как и для контейнера <par> . Если дочерний элемент имеет значение смещения, установленное для его атрибута начала или конца , смещение элемента будет относительно времени начала контейнера <par> . Для корневого элемента <par> атрибут начала игнорируется, и время начала наступает тогда, когда процесс синтеза речи SSML начинает генерировать выходные данные для корневого элемента <par> (т. е. фактически время «нулевое»).
Пример
<speak>
<par>
<media xml:id="question" begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media xml:id="answer" begin="question.end+2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media begin="answer.end-0.2s" soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</par>
</speak> <seq>
Последовательный медиаконтейнер, позволяющий воспроизводить медиаэлементы один за другим. Единственное разрешенное содержимое — это набор из одного или нескольких элементов <seq> , <par> и <media> . Порядок медиа-элементов — это порядок, в котором они отображаются.
Атрибутам начала и конца дочерних элементов можно задать значения смещения (см. Спецификацию времени ниже). Значения смещения этих дочерних элементов будут относиться к концу предыдущего элемента в последовательности или, в случае первого элемента в последовательности, относительно начала его контейнера <seq> .
Пример
<speak>
<seq>
<media begin="0.5s">
<speak>Who invented the Internet?</speak>
</media>
<media begin="2.0s">
<speak>The Internet was invented by cats.</speak>
</media>
<media soundLevel="-6dB">
<audio
src="https://actions.google.com/.../cartoon_boing.ogg"/>
</media>
<media repeatCount="3" soundLevel="+2.28dB"
fadeInDur="2s" fadeOutDur="0.2s">
<audio
src="https://actions.google.com/.../cat_purr_close.ogg"/>
</media>
</seq>
</speak> <media>
Представляет уровень мультимедиа внутри элемента <par> или <seq> . Разрешенным содержимым элемента <media> является элемент SSML <speak> или <audio> . В следующей таблице описаны допустимые атрибуты элемента <media> .
Атрибуты
| Атрибут | Необходимый | По умолчанию | Ценности |
|---|---|---|---|
| xml:идентификатор | нет | нет значения | Уникальный идентификатор XML для этого элемента. Закодированные объекты не поддерживаются. Разрешенные значения идентификатора соответствуют регулярному выражению "([-_#]|\p{L}|\p{D})+" . См. XML-ID для получения дополнительной информации. |
| начинать | нет | 0 | Время начала для этого медиаконтейнера. Игнорируется, если это корневой элемент медиаконтейнера (трактуется так же, как значение по умолчанию «0»). Допустимые строковые значения см. в разделе «Спецификация времени» ниже. |
| конец | нет | нет значения | Спецификация времени окончания для этого медиаконтейнера. Допустимые строковые значения см. в разделе «Спецификация времени» ниже. |
| повторениеCount | нет | 1 | Действительное число, указывающее, сколько раз вставлять носитель. Дробные повторения не поддерживаются, поэтому значение будет округлено до ближайшего целого числа. Ноль не является допустимым значением и поэтому считается неопределенным и в этом случае имеет значение по умолчанию. |
| Повторить Длительность | нет | нет значения | Обозначение TimeDesignation , которое является ограничением продолжительности вставленного мультимедиа. Если продолжительность мультимедиа меньше этого значения, воспроизведение заканчивается в это время. |
| уровень звука | нет | +0 дБ | Отрегулируйте уровень звука звука в децибелах soundLevel . Максимальный диапазон составляет +/-40 дБ, но фактический диапазон может быть меньше, а качество выходного сигнала может не дать хороших результатов во всем диапазоне. |
| FadeInDur | нет | 0 с | Обозначение TimeDesignation , по которому медиафайлы будут плавно переходить от тихого к дополнительно указанному soundLevel . Если продолжительность мультимедиа меньше этого значения, постепенное появление прекратится в конце воспроизведения, и уровень звука не достигнет заданного уровня звука. |
| FadeOutDur | нет | 0 с | Обозначение TimeDesignation , в течение которого медиафайлы будут постепенно исчезать по сравнению с необязательно указанным soundLevel , пока не наступит тишина. Если продолжительность мультимедиа меньше этого значения, для уровня звука устанавливается более низкое значение, чтобы обеспечить тишину в конце воспроизведения. |
Указание времени
Спецификация времени, используемая для значения атрибутов `begin` и `end` элементов <media> и медиа-контейнеров (элементы <par> и <seq> ), представляет собой либо значение смещения (например, +2.5s ), либо значение базы синхронизации (например, foo_id.end-250ms ).
- Значение смещения . Значение смещения по времени представляет собой значение SMIL Timecount, которое допускает значения, соответствующие регулярному выражению:
"\s\*(+|-)?\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Первая строка цифр представляет собой целую часть десятичного числа, а вторая строка цифр представляет собой десятичную дробную часть. Знак по умолчанию (т.е. «(+|-)?») — «+». Единичные значения соответствуют часам, минутам, секундам и миллисекундам соответственно. По умолчанию используются единицы измерения «s» (секунды).
- Значение базы синхронизации . Значение базы синхронизации — это значение базы синхронизации SMIL, которое допускает значения, соответствующие регулярному выражению:
"([-_#]|\p{L}|\p{D})+\.(begin|end)\s\*(+|-)\s\*(\d+)(\.\d+)?(h|min|s|ms)?\s\*"Цифры и единицы интерпретируются так же, как и значение смещения.
Симулятор ТТС
Консоль действий включает в себя симулятор TTS, который можно использовать для тестирования SSML с любым из вышеперечисленных элементов. Симулятор TTS можно найти в консоли в разделе «Симулятор» > «Аудио» . Введите текст и SSML в симуляторе и нажмите «Обновить и прослушать», чтобы услышать вывод TTS.
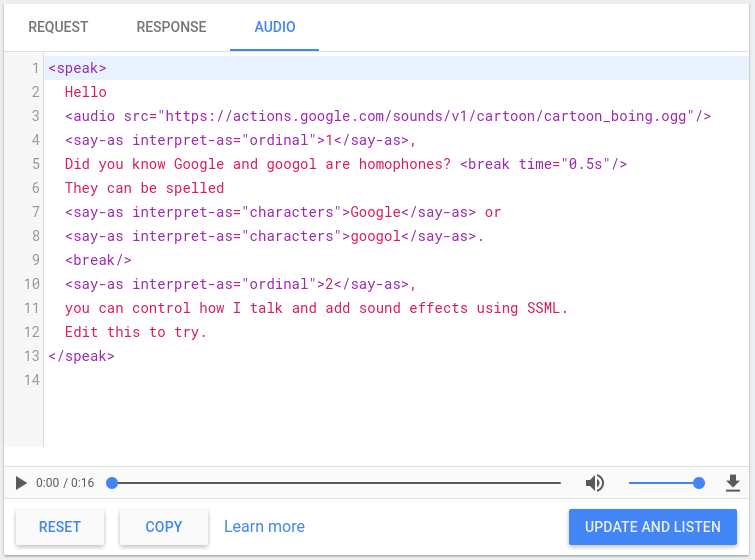
Вы также можете нажать кнопку загрузки, чтобы сохранить файл .mp3 с результатом TTS.
Если не указано иное, контент на этой странице предоставляется по лицензии Creative Commons "С указанием авторства 4.0", а примеры кода – по лицензии Apache 2.0. Подробнее об этом написано в правилах сайта. Java – это зарегистрированный товарный знак корпорации Oracle и ее аффилированных лиц.
Последнее обновление: 2026-04-18 UTC.