
השיטות המומלצות הבאות יספקו לכם טכניקות לפיתוח שאילתות שמתמקדות בפרטיות ופועלות בצורה יעילה. למידע על שיטות מומלצות להרצת שאילתות במצב רעש, אפשר לעיין בקטעים בנושא דפוסי שאילתות נתמכים ולא נתמכים במאמר החדרת רעש.
פרטיות ודיוק נתונים
פיתוח שאילתות על נתונים ב-Sandbox
שיטה מומלצת: כדאי לשלוח שאילתות לנתוני ייצור רק כשאתם בסביבת ייצור.
מומלץ להשתמש בנתוני Sandbox במהלך פיתוח השאילתה, בכל הזדמנות שמתאפשרת. משימות שמשתמשות בנתוני Sandbox לא יוצרות הזדמנויות נוספות לבדיקות הבדלים כדי לסנן את תוצאות השאילתה. בנוסף, בגלל היעדר בדיקות פרטיות, שאילתות בסביבת ארגז חול רצות מהר יותר, מה שמאפשר איטרציה מהירה יותר במהלך פיתוח השאילתה.
אם אתם צריכים לפתח שאילתות על הנתונים בפועל (למשל כשמשתמשים בטבלאות התאמה), כדי להקטין את הסיכוי לחפיפה בין שורות, כדאי לבחור טווחי תאריכים ופרמטרים אחרים שלא צפוי שתהיה ביניהם חפיפה בכל איטרציה של השאילתה. לבסוף, מריצים את השאילתה על טווח הנתונים הרצוי.
חשוב להתייחס בזהירות לתוצאות היסטוריות
שיטה מומלצת: כדי להקטין את הסיכוי לחפיפה בין קבוצות התוצאות של שאילתות שהורצו לאחרונה,
חשוב לזכור שקצב השינוי בין תוצאות השאילתות ישפיע על הסיכוי שתוצאות יושמטו בהמשך בגלל בדיקות פרטיות. סביר להניח שקבוצת תוצאות שנייה שדומה מאוד לקבוצת תוצאות שהוחזרה לאחרונה תיפסל.
במקום זאת, כדאי לשנות פרמטרים מרכזיים בשאילתה, כמו טווחי תאריכים או מזהי קמפיינים, כדי לצמצם את הסיכוי לחפיפה משמעותית.
לא לבצע שאילתה על הנתונים של היום
שיטה מומלצת: לא מומלץ להריץ כמה שאילתות שבהן תאריך הסיום הוא היום.
הפעלת כמה שאילתות עם תאריכי סיום ששווים לתאריך של היום תוביל בדרך כלל לסינון של שורות. ההנחיות האלה רלוונטיות גם להרצת שאילתות זמן קצר אחרי חצות על הנתונים של אתמול.
אל תריצו שאילתות על אותם נתונים יותר מהנדרש
שיטות מומלצות:
- בוחרים תאריכי התחלה וסיום קרובים.
- במקום להריץ שאילתות על חלונות חופפים, מריצים את השאילתות על קבוצות נתונים נפרדות, ואז מסכמים את התוצאות ב-BigQuery.
- להשתמש בתוצאות שמורות במקום להריץ מחדש את השאילתה.
- יוצרים טבלאות זמניות לכל טווח תאריכים שרוצים לבצע עליו שאילתה.
ב-Ads Data Hub יש הגבלה על מספר הפעמים הכולל שבהן אפשר להריץ שאילתות על אותם נתונים. לכן, כדאי לנסות להגביל את מספר הפעמים שבהן אתם ניגשים לפריט נתונים מסוים.
לא להשתמש ביותר צבירות מהנדרש באותה שאילתה
שיטות מומלצות:
- צמצום מספר הצבירות בשאילתה
- שינוי שאילתות כדי לשלב צבירות כשזה אפשרי
ב-Ads Data Hub, מספר הצבירות של נתונים של משתמשים שונים שאפשר להשתמש בהן בשאילתת משנה מוגבל ל-100. לכן, באופן כללי, מומלץ לכתוב שאילתות שמפיקות יותר שורות עם מפתחות קיבוץ ממוקדים וצבירות פשוטות, במקום יותר עמודות עם מפתחות קיבוץ רחבים וצבירות מורכבות. אין להשתמש בדפוס הבא:
SELECT
COUNTIF(field_1 = a_1 AND field_2 = b_1) AS cnt_1,
COUNTIF(field_1 = a_2 AND field_2 = b_2) AS cnt_2
FROM
table
צריך לשכתב שאילתות שסופרות אירועים בהתאם לאותה קבוצת שדות באמצעות ההצהרה GROUP BY.
SELECT
field_1,
field_2,
COUNT(1) AS cnt
FROM
table
GROUP BY
1, 2
אפשר לצבור את התוצאה באותו אופן ב-BigQuery.
צריך לשכתב שאילתות שיוצרות עמודות ממערך ואז מצטברות לאחר מכן כדי למזג את השלבים האלה.
SELECT
COUNTIF(a_1) AS cnt_1,
COUNTIF(a_2) AS cnt_2
FROM
(SELECT
1 IN UNNEST(field) AS a_1,
2 IN UNNEST(field) AS a_2,
FROM
table)
אפשר לשכתב את השאילתה הקודמת כך:
SELECT f, COUNT(1) FROM table, UNNEST(field) AS f GROUP BY 1
אפשר לשכתב שאילתות שמשתמשות בשילובים שונים של שדות בצבירות שונות לכמה שאילתות ממוקדות יותר.
SELECT
COUNTIF(field_1 = a_1) AS cnt_a_1,
COUNTIF(field_1 = b_1) AS cnt_b_1,
COUNTIF(field_2 = a_2) AS cnt_a_2,
COUNTIF(field_2 = b_2) AS cnt_b_2,
FROM table
אפשר לפצל את השאילתה הקודמת לשתי שאילתות:
SELECT
field_1, COUNT(*) AS cnt
FROM table
GROUP BY 1
וגם
SELECT
field_2, COUNT(*) AS cnt
FROM table
GROUP BY 1
אפשר לפצל את התוצאות האלה לשאילתות נפרדות, ליצור את הטבלאות ולצרף אותן בשאילתה אחת, או לשלב אותן באמצעות UNION אם הסכימות תואמות.
אופטימיזציה והבנה של פעולות הצטרפות
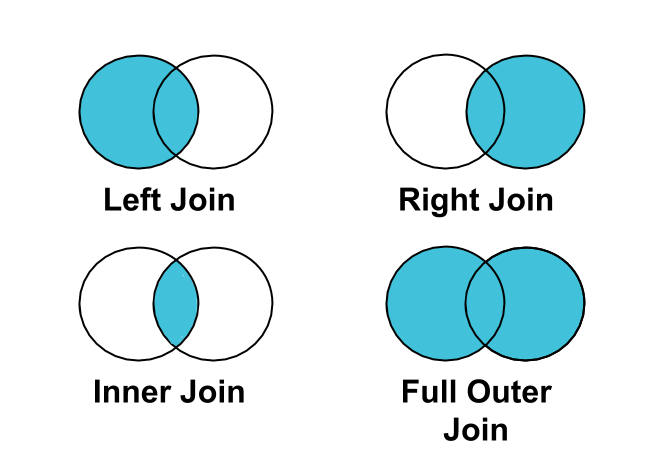
שיטה מומלצת: כדי לשייך קליקים או המרות לחשיפות, כדאי להשתמש ב-LEFT JOIN במקום ב-INNER JOIN.
לא כל החשיפות משויכות לקליקים או להמרות. לכן, אם תבחרו INNER JOIN קליקים או המרות בחשיפות, חשיפות שלא קשורות לקליקים או להמרות יסוננו מהתוצאות.
צירוף של חלק מהתוצאות הסופיות ב-BigQuery
שיטה מומלצת: מומלץ להימנע משאילתות ב-Ads Data Hub שמצטרפות לתוצאות מצטברות. במקום זאת, כותבים 2 שאילתות נפרדות ומצטרפים לתוצאות ב-BigQuery.
שורות שלא עומדות בדרישות הצבירה מסוננות מהתוצאות. לכן, אם השאילתה מצטרפת לשורה עם צבירה לא מספקת לשורה עם צבירה מספקת, השורה שמתקבלת תסונן. בנוסף, שאילתות עם כמה צבירות פועלות פחות טוב ב-Ads Data Hub.
אפשר לצרף תוצאות (ב-BigQuery) מכמה שאילתות צבירה (מ-Ads Data Hub). תוצאות שמחושבות באמצעות שאילתות נפוצות ישתמשו בסכימות סופיות משותפות.
השאילתה הבאה לוקחת תוצאות נפרדות של Ads Data Hub (campaign_data_123 ו-campaign_data_456) ומצטרפת אליהן ב-BigQuery:
SELECT t1.campaign_id, t1.city, t1.X, t2.Y
FROM `campaign_data_123` AS t1
FULL JOIN `campaign_data_456` AS t2
USING (campaign_id, city)
שימוש בסיכומי שורות מסוננות
שיטה מומלצת: כדאי להוסיף לשאילתות סיכומים של שורות מסוננות.
סיכומי שורות מסוננות מסכמים נתונים שסוננו בגלל בדיקות לאימות הפרטיות. הנתונים מהשורות המסוננות מסוכמים ומוספים לשורה כללית. אי אפשר לנתח את הנתונים המסוננים, אבל אפשר לראות סיכום של כמות הנתונים שסוננו מהתוצאות.
התייחסות למזהי משתמשים שהערך שלהם הוא אפס
שיטה מומלצת: צריך לקחת בחשבון את מזהי המשתמשים שהערך שלהם הוא אפס בתוצאות.
יכול להיות שמזהה של משתמש קצה יוגדר כ-0 מכמה סיבות, כולל ביטול ההסכמה להתאמה אישית של מודעות, סיבות רגולטוריות וכו'. לכן, נתונים שמגיעים מכמה משתמשים יקבלו את הערך user_id של 0.
אם אתם רוצים להבין את סיכומי הנתונים, כמו סך החשיפות או הקליקים, כדאי לכלול את האירועים האלה. עם זאת, הנתונים האלה לא יעזרו לכם להפיק תובנות לגבי הלקוחות, וכדאי לסנן אותם אם אתם מבצעים ניתוח כזה.
כדי להחריג את הנתונים האלה מהתוצאות, מוסיפים WHERE user_id != "0" לשאילתות.
ביצועים
הימנעות מצירוף מחדש
שיטה מומלצת: מומלץ להימנע ממספר שכבות של צבירה בין משתמשים.
שאילתות שמשלבות תוצאות שכבר צורפו, כמו במקרה של שאילתה עם כמה GROUP BY או צירוף מקונן, דורשות יותר משאבים לעיבוד.
לעתים קרובות, אפשר לפצל שאילתות עם כמה שכבות של צבירה כדי לשפר את הביצועים. מומלץ לנסות לשמור על השורות ברמת האירוע או המשתמש במהלך העיבוד, ואז לשלב אותן עם צבירה אחת.
אין להשתמש בדפוסים הבאים:
SELECT SUM(count)
FROM
(SELECT campaign_id, COUNT(0) AS count FROM ... GROUP BY 1)
צריך לשכתב שאילתות שמשתמשות בכמה שכבות של אגרגציה כך שישתמשו בשכבה אחת של אגרגציה.
(SELECT ... GROUP BY ... )
JOIN USING (...)
(SELECT ... GROUP BY ... )
צריך לפצל שאילתות שאפשר לפצל בקלות. אפשר לצרף תוצאות ב-BigQuery.
אופטימיזציה ל-BigQuery
בדרך כלל, שאילתות שמבצעות פחות פעולות מניבות ביצועים טובים יותר. כשמעריכים את ביצועי השאילתות, כמות העבודה הנדרשת תלויה בגורמים הבאים:
- נתוני קלט ומקורות נתונים (I/O): כמה בייטים השאילתה קוראת?
- תקשורת בין צמתים (ערבוב): כמה בייטים השאילתה מעבירה לשלב הבא?
- חישוב: כמה עבודת מעבד נדרשת לשאילתה?
- פלטים (יצירת תצוגה חומרית): כמה בייטים נכתבים על ידי השאילתה?
- דפוסי שאילתות שגויים: האם השאילתות שלכם פועלות לפי השיטות המומלצות של SQL?
אם ביצוע השאילתות לא עומד בהסכמי רמת השירות שלכם, או אם אתם נתקלים בשגיאות בגלל מיצוי משאבים או פסק זמן, כדאי לשקול:
- שימוש בתוצאות משאילתות קודמות במקום לבצע חישוב מחדש. לדוגמה, הסכום הכולל השבועי יכול להיות הסכום שמחושב ב-BigQuery של 7 שאילתות מצטברות של יום אחד.
- פירוק שאילתות לשאילתות משנה לוגיות (למשל, פיצול של כמה הצטרפויות לכמה שאילתות), או הגבלה של מערך הנתונים שעובר עיבוד. אפשר לשלב תוצאות מעבודות נפרדות למערך נתונים יחיד ב-BigQuery. הפעולה הזו עשויה לעזור במקרים של מיצוי משאבים, אבל היא עלולה להאט את השאילתה.
- אם אתם נתקלים בשגיאות שקשורות לחריגה ממגבלות המשאבים ב-BigQuery, נסו להשתמש בטבלאות זמניות כדי לפצל את השאילתה לכמה שאילתות BigQuery.
- הפניה לפחות טבלאות בשאילתה אחת, כי הפעולה הזו צורכת כמויות גדולות של זיכרון ועלולה לגרום לכך שהשאילתה תיכשל.
- לשכתב את השאילתות כך שיצטרפו לפחות טבלאות משתמשים.
- לשכתב את השאילתות כדי להימנע מאיחוד של אותה טבלה עם עצמה.
יועץ לשאילתות
אם שאילתת ה-SQL תקינה אבל עלולה לגרום לבעיות שקשורות לפרטיות, יועץ השאילתות יציג המלצות מעשיות במהלך פיתוח השאילתה, כדי לעזור לכם להימנע מתוצאות לא רצויות.
כדי להשתמש בכלי לייעוץ לגבי שאילתות:
- ממשק משתמש. ההמלצות יוצגו בעורך השאילתות, מעל טקסט השאילתה.
- API. משתמשים בשיטה
customers.analysisQueries.validate.