Page Summary
-
DNS lookups significantly impact website loading speed, especially with resource-heavy pages referencing multiple domains.
-
DNS latency stems from network factors between clients and resolvers and between resolvers and other name servers, with cache misses being a primary contributor.
-
Cache misses are difficult to avoid due to the Internet's vastness, short DNS record lifespans, and isolated caching systems across servers.
-
Google Public DNS employs strategies like global server distribution, load balancing, and security measures to mitigate DNS latency and enhance performance.
Introduction: causes and mitigations of DNS latency
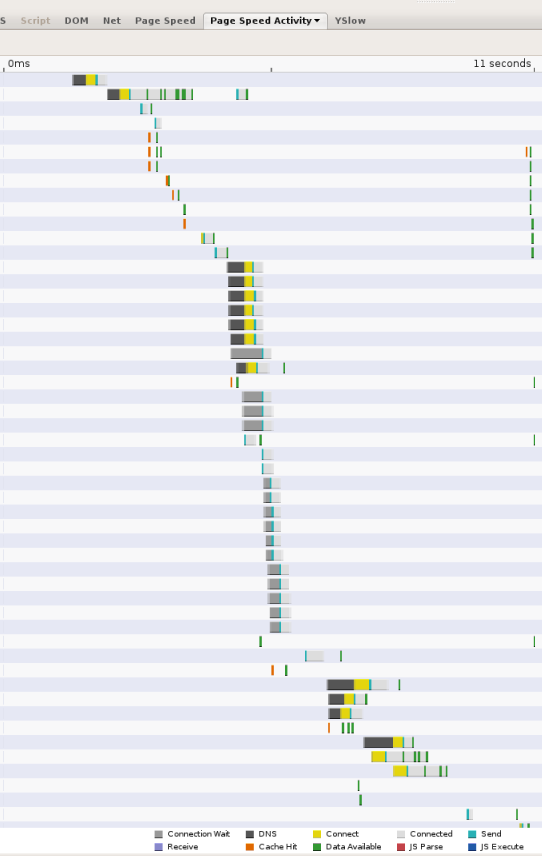
As web pages become more complex, referencing resources from numerous domains, DNS lookups can become a significant bottleneck in the browsing experience. Whenever a client needs to query a DNS resolver over the network, the latency introduced can be significant, depending on the proximity and number of name servers the resolver has to query (more than 2 is rare, but it can happen). As an example, the following screen shot shows the timings reported by the Page Speed web performance measurement tool. Each bar represents a resource referenced from the page; the black segments indicate DNS lookups. In this page, 13 lookups are made in the first 11 seconds in which the page is loaded. Although several of the lookups are done in parallel, the screen shot shows that 5 serial lookup times are required, accounting for several seconds of the total 11 seconds page load time.
There are two components to DNS latency:
- Latency between the client (user) and DNS resolving server. In most cases this is largely due to the usual round-trip time (RTT) constraints in networked systems: geographical distance between client and server machines; network congestion; packet loss and long retransmit delays (one second on average); overloaded servers, denial-of-service attacks and so on.
- Latency between resolving servers and other name servers.
This source of latency is caused primarily by the following factors:
- Cache misses. If a response cannot be served from a resolver's cache, but requires recursively querying other name servers, the added network latency is considerable, especially if the authoritative servers are geographically remote.
- Underprovisioning. If DNS resolvers are overloaded, they must queue DNS resolution requests and responses, and may begin dropping and retransmitting packets.
- Malicious traffic. Even if a DNS service is overprovisioned, DoS traffic can place undue load on the servers. Similarly, Kaminsky-style attacks can involve flooding resolvers with queries that are guaranteed to bypass the cache and require outgoing requests for resolution.
We believe that the cache miss factor is the most dominant cause of DNS latency, and discuss it further below.
Cache misses
Even if a resolver has abundant local resources, the fundamental delays associated with talking to remote name servers are hard to avoid. In other words, assuming the resolver is provisioned well enough so that cache hits take zero time on the server-side, cache misses remain very expensive in terms of latency. To handle a miss, a resolver has to talk to at least one, but often two or more external name servers. Operating the Googlebot web crawler, we have observed an average resolution time of 130 ms for name servers that respond. However, a full 4-6% of requests simply time out, due to UDP packet loss and servers being unreachable. If we take into account failures such as packet loss, dead name servers, DNS configuration errors, etc., the actual average end-to-end resolution time is 300-400 ms. However, there is high variance and a long tail.
Though the cache miss rate may vary among DNS servers, cache misses are fundamentally difficult to avoid, for the following reasons:
- Internet size and growth. Quite simply, as the Internet grows, both through the addition of new users and of new sites, most content is of marginal interest. While a few sites (and consequently DNS names) are very popular, most are of interest to only a few users and are accessed rarely; so the majority of requests result in cache misses.
- Low time-to-live (TTL) values. The trend towards lower DNS TTL values means that resolutions need more frequent lookups.
- Cache isolation. DNS servers are typically deployed behind load balancers which assign queries to different machines at random. This results in each individual server maintaining a separate cache rather than being able to reuse cached resolutions from a shared pool.
Mitigations
In Google Public DNS, we have implemented several approaches to speeding up DNS lookup times. Some of these approaches are fairly standard; others are experimental:
- Provisioning servers adequately to handle the load from client traffic, including malicious traffic.
- Preventing DoS and amplification attacks. Although this is mostly a security issue, and affects closed resolvers less than open ones, preventing DoS attacks also has a benefit for performance by eliminating the extra traffic burden placed on DNS servers. For information on the approaches we are using to minimize the chance of attacks, see the page on security benefits.
- Load-balancing for shared caching, to improve the aggregated cache hit rate across the serving cluster.
- Providing global coverage for proximity to all users.
Provisioning serving clusters adequately
Caching DNS resolvers have to perform more expensive operations than authoritative name servers, since many responses cannot be served from memory; instead, they require communication with other name servers and thus demand a lot of network input/output. Furthermore, open resolvers are highly vulnerable to cache poisoning attempts, which increase the cache miss rate (such attacks specifically send requests for bogus names that can't be resolved from cache), and to DoS attacks, which add to the traffic load. If resolvers are not provisioned adequately and cannot keep up with the load, this can have a very negative impact on performance. Packets get dropped and need to be retransmitted, name server requests have to be queued, and so on. All of these factors add to delays.
Therefore, it's important for DNS resolvers to be provisioned for high-volume input/output. This includes handling possible DDoS attacks, for which the only effective solution is to over-provision with many machines. At the same time, however, it's important not to reduce the cache hit rate when you add machines; this requires implementing an effective load-balancing policy, which we discuss below.
Load-balancing for shared caching
Scaling resolver infrastructure by adding machines can actually backfire and reduce the cache hit rate if load balancing is not done properly. In a typical deployment, multiple machines sit behind a load balancer that equally distributes traffic to each machine, using a simple algorithm such as round robin. The result of this is that each machine maintains its own independent cache, so that the cached content is isolated across machines. If each incoming query is distributed to a random machine, depending on the nature of the traffic, the effective cache miss rate can be increased proportionally. For example, for names with long TTLs that are queried repeatedly, the cache miss rate can be increased by the number of machines in the cluster. (For names with very short TTLs, that are queried very infrequently, or that result in uncacheable responses (0 TTL and errors), the cache miss rate is not really affected by adding machines.)
To boost the hit rate for cacheable names, it's important to load-balance servers so that the cache is not fragmented. In Google Public DNS, we have two levels of caching. In one pool of machines, very close to the user, a small per-machine cache contains the most popular names. If a query cannot be satisfied from this cache, it is sent to another pool of machines that partition the cache by names. For this second level cache, all queries for the same name are sent to the same machine, where the name is either cached or it isn't.
Distributing serving clusters for wide geographical coverage
For closed resolvers, this is not really an issue. For open resolvers, the closer your servers are located to your users, the less latency they will see at the client end. In addition, having sufficient geographical coverage can indirectly improve end-to-end latency, as name servers typically return results optimized for the DNS resolver's location. That is, if a content provider hosts mirrored sites around the world, that provider's name servers will return the IP address in closest proximity to the DNS resolver.
Google Public DNS is hosted in data centers worldwide, and uses anycast routing to send users to the geographically closest data center.
In addition, Google Public DNS supports EDNS client subnet (ECS), a DNS protocol extension for resolvers to forward client location to name servers, which can return location-sensitive responses optimized for the actual client IP address, rather than the resolver's IP address. Please read this FAQ for details. Google Public DNS automatically detects name servers that support EDNS Client Subnet.