このセクションでは、メリディアンをシナリオ プランニングに使用する方法について説明します。将来に関するデータと仮定を予算の最適化シナリオに組み込む方法についても取り上げます。
将来の予算の最適化のために、メリディアンは将来に関する一連の仮定に基づいて増分結果を予測します。メリディアンが予測するのは、将来の結果の値そのものではなく、増分のみです。詳しくは、メリディアンが結果を予測しない理由をご覧ください。
シナリオ プランニングとは
シナリオ プランニングは、将来に関する仮定を組み込むことができるマーケティング ミックス モデリング(MMM)分析です。費用対効果(ROI)、応答曲線、予算の最適化などのモデリング後分析においては、メリディアンはデフォルトの仮定に過去のデータを使用します。これらの仮定は、将来の計画に対して必ずしも妥当ではないため、必要に応じて新しいデータを分析に取り込んで変更できます。
たとえば、以下については将来と過去で戦略が異なる場合があります。
- メディア ユニット単価: チャネルのメディア ユニット単価が変化したか、これから変化する可能性があります(コーディングの例 1 と例 2 を参照)。
- KPI 単位あたりの収益: KPI あたりの収益(単価やライフタイム バリューなど)が変化したか、これから変化する可能性があります(コーディングの例 3 を参照)。
- フライティング パターン: 過去と将来のフライティング パターンが一致するとは限りません。たとえば、モデルのトレーニング期間中に新しいメディア チャネルが導入された可能性があります。新しいチャネルの過去のフライティング パターンにゼロが含まれる場合や、「増加」傾向が示されていてもそれが続かないと予想される場合があります(コーディングの例 4 を参照)。
モデリング後分析の指標
シナリオ プランニングは、指標の定義には影響しますが、パラメータの推定には影響しません。これらのコンセプトを説明するために、最小二乗法を使用して薬の処置効果を推定する架空のケースを考えてみましょう。このケースでは、モデルのように、mg 単位の用量(X)が結果(Y)に線形に影響すると仮定します。
\[ Y = \alpha + X \beta + \epsilon \ . \]
処置効果は、用量係数 $\beta$ に依存します。用量係数 $\beta$ は、観測されたデータセットから推定されるパラメータです。処置効果には、定義可能な指標が多数あります。たとえば、薬の効果を、10 mg($10 \beta$)または 15 mg の容量($15 \beta$)によって生じると予想される結果の変化として定義できます。また、同じモデルと係数推定値 $\hat{\beta}$ を使用して、両方の処置効果の定義を推定できます。
メリディアンでは、モデリング後分析の指標の定義は特定のデータ特性に依存します。たとえば ROI は、指定された期間、地域のセット、フライティング パターン(地域と期間全体のメディア ユニットの相対的な分布)、チャネルごとのメディア ユニットの合計数、メディア ユニット単価、KPI あたりの収益に依存します。モデリング後分析の指標には、想定される結果、増分結果、限界費用対効果、CPIK、応答曲線、最適な予算配分などがあります。デフォルトでは、これらの指標は Meridian に渡された input_data を使用して定義されますが、new_data を提供して別の指標を定義することもできます。表 1 は、各指標の定義に影響するデータ プロパティを示しています。
| 期間 | 地域のセット | フライティング パターン | チャネルごとのメディア ユニットの合計数 | メディア ユニット単価 | KPI あたりの収益(該当する場合) | コントロール値 | |
|---|---|---|---|---|---|---|---|
expected_outcome |
X | X | X | X | X | X | |
incremental_outcome |
X | X | X | X | X | ||
roi、marginal_roi、cpik |
X | X | X | X | X | X | |
response_curves |
X | X | X | X | X | ||
BudgetOptimizer.optimize |
X | X | X | ‡ | X | X |
‡ 予算の最適化では、チャネルごとのメディア ユニットの合計数を(固定フライティング パターンとメディア ユニット単価の仮定と組み合わせて)使用し、デフォルトの合計予算(固定予算の最適化のみ)とチャネルレベルの予算制約を割り当てます。
BudgetOptimizer.optimizeのbudget引数とpct_of_spend引数を使用してこれらの設定がオーバーライドされる場合、チャネルごとのメディア ユニットの合計数は最適化に影響しません。
モデリング後分析の各指標の推定値は、モデル パラメータの事後分布に依存します。事後分布は、Meridian オブジェクト コンストラクタに渡された input_data に依存します(ModelSpec.holdout_id で指定された地域と期間の KPI を除く)。事後分布は sample_posterior の呼び出し時に推定され、この推定はすべてのモデリング後分析に使用されます。
new_data 引数
表 1 の各データ プロパティのデフォルト値は、Meridian に渡される input_data から導出されます。モデリング後分析では、ほとんどのメソッドで利用できる new_data 引数を使用して入力データをオーバーライドできます。各メソッドでは、new_data 属性のサブセットのみを使用します。表 2 は、各メソッドで使用される new_data 属性を示しています。
new_data 属性のリスト。
media、reach、frequency |
revenue_per_kpi |
media_spend、rf_spend |
organic_media、organic_reach、organic_frequency、non_media_treatments |
controls |
time |
時間ディメンションと input_data の一致 |
|
|---|---|---|---|---|---|---|---|
expected_outcome |
X | X | X | X | 必須 | ||
incremental_outcome |
X | X | X | 任意 | |||
roi、cpik、marginal_roi |
X | X | X | 任意 | |||
response_curves |
X | X | X | X | 任意 | ||
BudgetOptimizer.optimize |
X | X | X | X | 任意 |
データ プロパティは、new_data からも、入力データからと同じ方法で導出されます。たとえば、メディア ユニット単価は、地域および期間ごとに費用をメディア ユニット数で割って計算されます。
new_data の期間が入力データの期間と一致する場合、呼び出すメソッドで使用される new_data 属性をすべて指定する必要はありません。属性のサブセットを指定すると、残りの属性は入力データから取得されます。
ただし、new_data の期間が入力データと異なる場合は、呼び出すメソッドで使用される new_data 属性をすべて渡す必要があります。その際、すべての new_data 属性の時間ディメンションは同じでなければなりません。なお、expected_outcome メソッドに限り、時間ディメンションは入力データと一致している必要があります。
response_curves メソッドと optimize メソッドについては、時間ディメンションが入力データと一致していない場合、日付ラベルを new_data.time に渡す必要もあります。データラベルは計算には影響しませんが、特定のグラフの軸ラベルに使用されます。
予算の最適化用の new_data を作成するヘルパー メソッド
チャネルレベルの費用が BudgetOptimizer.optimize の出力と new_data 入力の両方であることは、直感的にはわかりにくいかもしれません。出力は最適な費用配分です。一方、入力費用は、メディア ユニットの入力とともに、各地域と期間で想定されるメディア ユニット単価の設定に使用されます。入力費用は、固定予算の最適化シナリオの合計予算の設定や、チャネルレベルの予算制約の設定にも使用されますが、これらは budget 引数と pct_of_spend 引数を使用してオーバーライドできます。
optimizer.create_optimization_tensors メソッドは、メディア ユニット単価データを直接入力する場合に利用できます。このメソッドは、次の入力データ オプションを使用して BudgetOptimizer.optimize メソッドに渡すための new_data オブジェクトを作成します。
R&F 以外のチャネル:
- メディア ユニットとメディア ユニット単価
- 費用とメディア ユニット単価
use_optimal_frequency=True の場合の R&F チャネル:
- インプレッション数とインプレッション単価
- 費用とインプレッション単価
use_optimal_frequency=False の場合の R&F チャネル:
- インプレッション数、フリークエンシー、インプレッション単価
- 費用、フリークエンシー、インプレッション単価
例
このセクションでは、最も重要なモデリング後分析の関数(Analyzer.incremental_outcome、Analyzer.roi、Analyzer.response_curves、BudgetOptimizer.optimize)の計算方法について説明します。
特にこれらの例は、input_data と new_data を使用して各メソッドの計算を行う方法を示しています。これらの例では、input_data にはメディア ユニット データの「モデリング前期間」が含まれていますが、new_data には含まれていません。「モデリング前期間」には、最初の「モデリング期間」より前のメディア ユニット データが含まれます。これにより、モデルでこれらのユニットの遅延効果を適切に考慮できます。new_data が(これらの例のように)input_data とは異なる期間を対象とする場合、メディア ユニット データの期間数は、他のすべての新規データと同じなければなりません。
これらの各メソッドには、new_data に加えて、selected_times 引数があります。これらの引数は、パラメータ推定ではなく、出力指標の定義をカスタマイズするものです(詳しくはシナリオ プランニングとはをご覧ください)。
また、Analyzer.incremental_outcome メソッドには、増分結果の定義をより詳細にカスタマイズできる media_selected_times 引数もあります。この引数により、Analyzer.incremental_outcome は他のメソッドよりも柔軟に使用できます。他のメソッドにはこの引数がありません。他のメソッドの計算では増分結果を関連費用と照合しますが、selected_times と media_selected_times の両方をカスタマイズできてしまうと、正確に照合できない可能性があるためです。ただし、たとえば incremental_outcome 出力と費用データを手動でペア設定して、ROI 定義をカスタマイズすることはできます。
地域レベルのモデルでは、各地域に独自の増分結果、ROI、応答曲線があります。各例が 1 つの地域を表しています。全国レベルの結果は、すべての地域を集計したものです。これらの各メソッドには selected_geos 引数があり、ユーザーは指標定義に含める地域のサブセットを指定できます。
増分結果
incremental_outcome メソッドでは、メディア チャネルごとに 2 つの反事実的シナリオに基づいて想定結果を比較します。1 つのシナリオでは、メディア ユニットには過去の値が設定されます。もう 1 つのシナリオでは、一部またはすべての期間でメディア ユニットにゼロが設定されます。
media_selected_times 引数によって、メディア ユニットがゼロに設定される期間が決まります。
selected_times 引数では、増分結果が測定される期間が決まります。
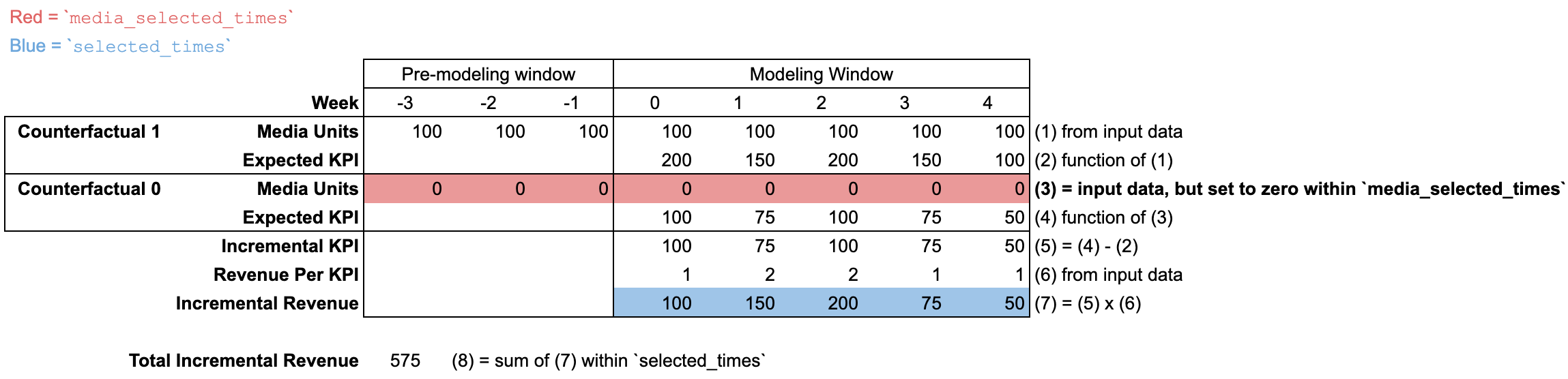
input_data を使用する
増分結果のデフォルト定義では、media_selected_times は「モデリング期間」と「モデリング前期間」の両方を含むすべての期間に設定されます(input_data メディア ユニットにオプションで「モデリング前期間」を含め、モデルでこれらのユニットの遅延効果を適切に考慮することができます)。
デフォルトの selected_times は「モデリング期間」内のすべての期間であり、増分結果は「モデリング期間」内のすべての期間を含めて集計されます。
input_data には、遅延効果を考慮するために「モデリング前期間」のメディア ユニットが含まれる場合があります。「モデリング前期間」にはメディア ユニット以外のデータが含まれていないため、図のセルは空白になっています。
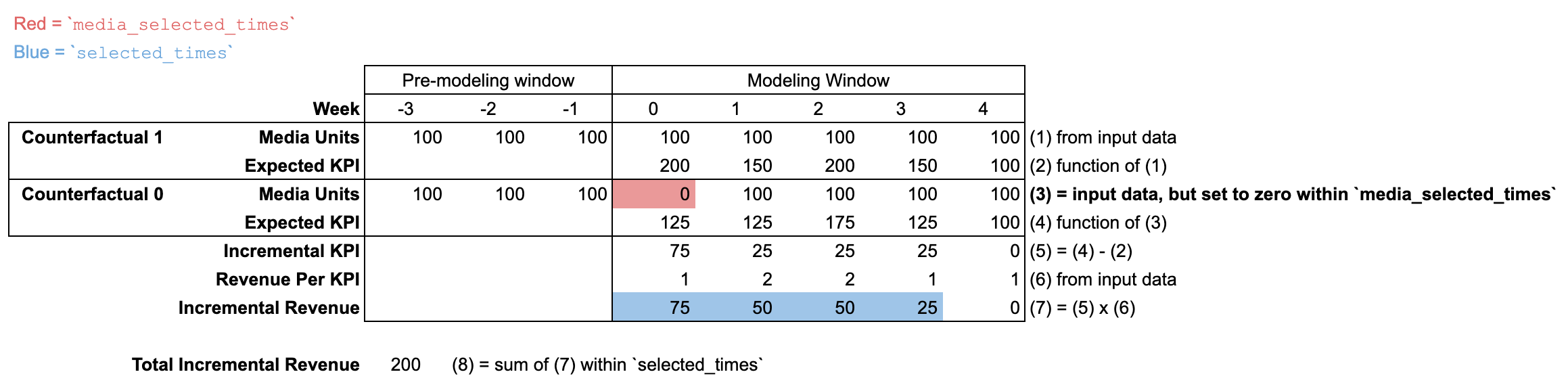
selected_times と media_selected_times が変更された input_data を使用する
incremental_outcome やその他のメソッドでの new_data の使用方法を理解するには、selected_times 引数と media_selected_times 引数を理解することが重要です。
この例では、media_selected_times は単一の期間(週 0)に設定されています。一方、selected_times は週 0~3 に設定されています。また、ModelSpec で max_lag が 3 に設定されているため、週 4 以降の増分結果は 0 になります。その結果、media_selected_times と selected_times のこの組み合わせにより、週 0 のメディア ユニットの長期的な影響が完全にキャプチャされます。
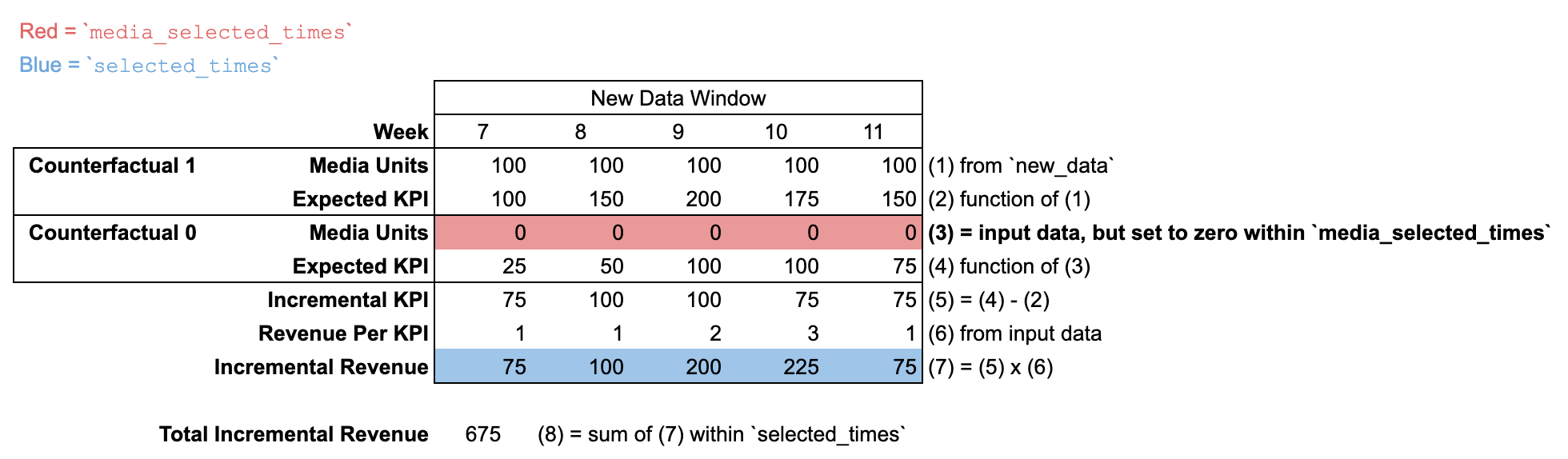
new_data を新しい期間で使用する
new_data が input_data とは異なる期間数で渡される場合、「モデリング前期間」はありません。new_data 期間より前のすべての期間で、メディア ユニットは 0 であると想定されます。
増分結果のデフォルト定義では、media_selected_times と selected_times の両方が new_data 期間内のすべての期間に設定されます。
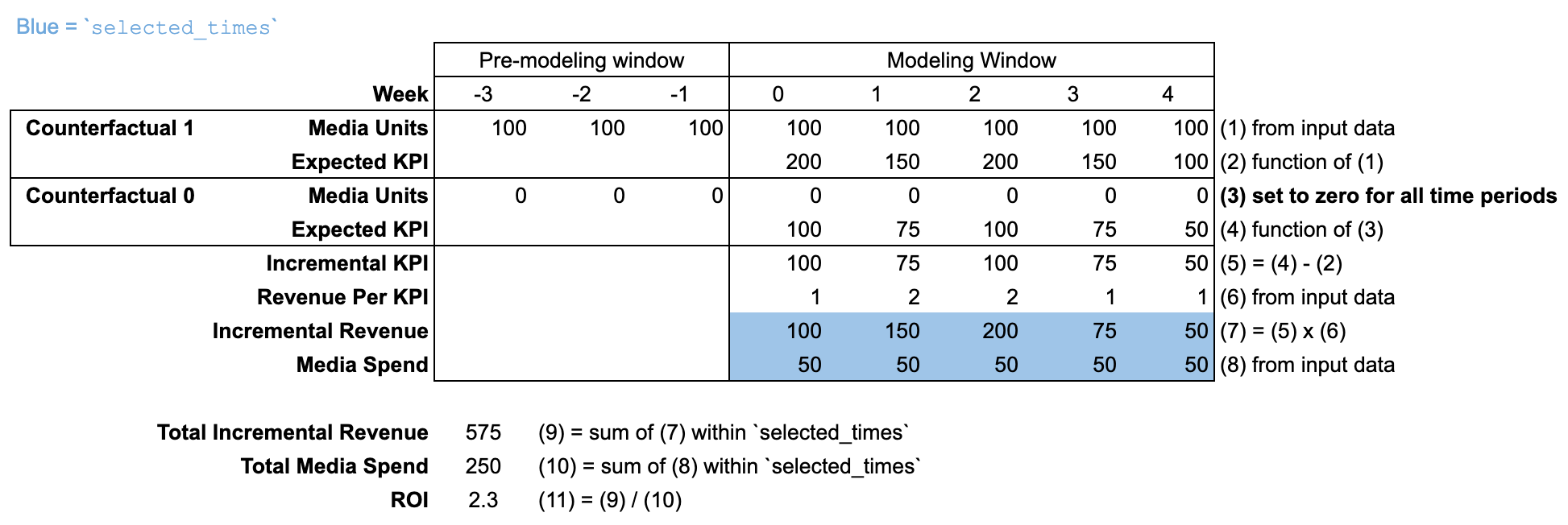
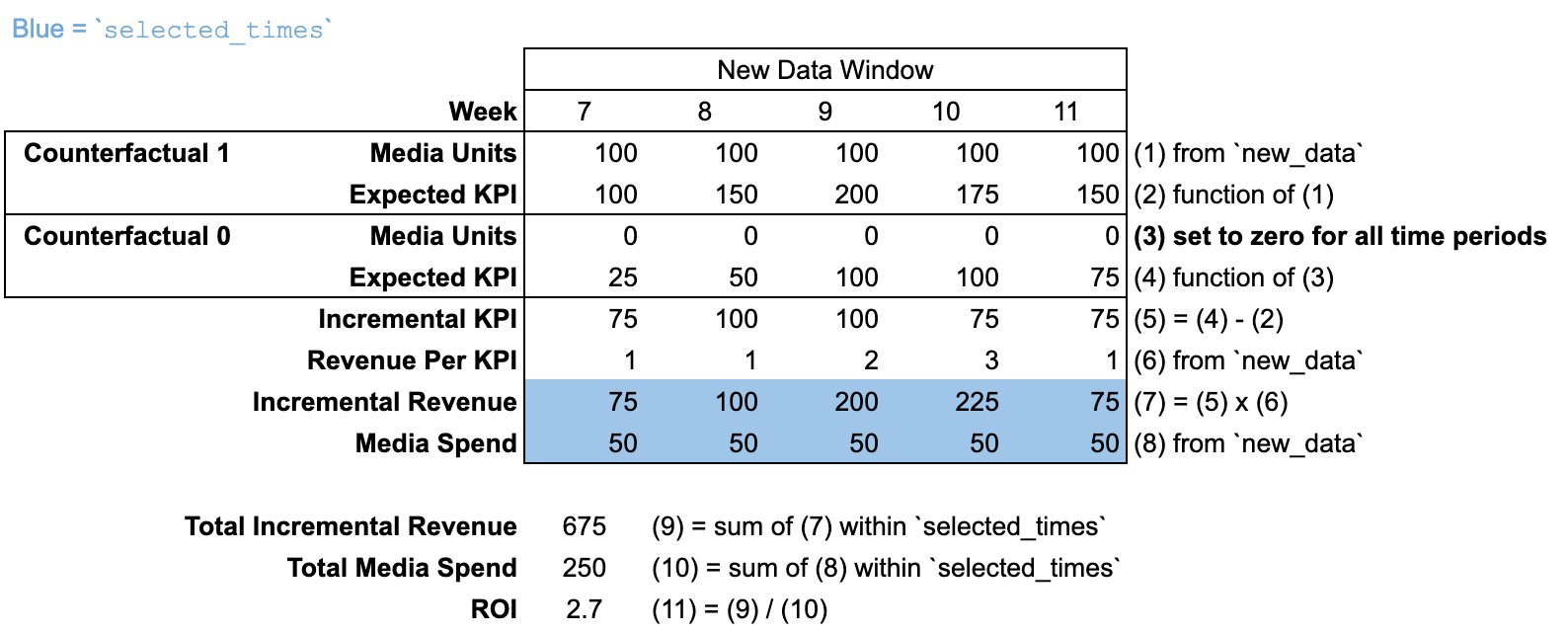
ROI
roi メソッドでは、メディア チャネルごとに selected_times の期間中に発生した増分結果を selected_times の期間中の費用で割ります。roi メソッドには media_selected_times 引数はありません。増分結果では、メディア ユニットが過去の値に設定されている反事実と、メディア ユニットがすべての期間でゼロに設定されている反事実が比較されます。
input_data を使用する
selected_times は、デフォルトでは「モデリング期間」全体に設定されています。反事実では、「モデリング期間」と「モデリング前期間」の両方で、すべての期間のメディア ユニットにゼロが設定されます。
new_data を新しい期間で使用する
new_data が input_data とは異なる期間数で渡される場合、「モデリング前期間」はありません。new_data 期間より前のすべての期間で、メディア ユニットは 0 であると想定されます。
応答曲線と予算の最適化
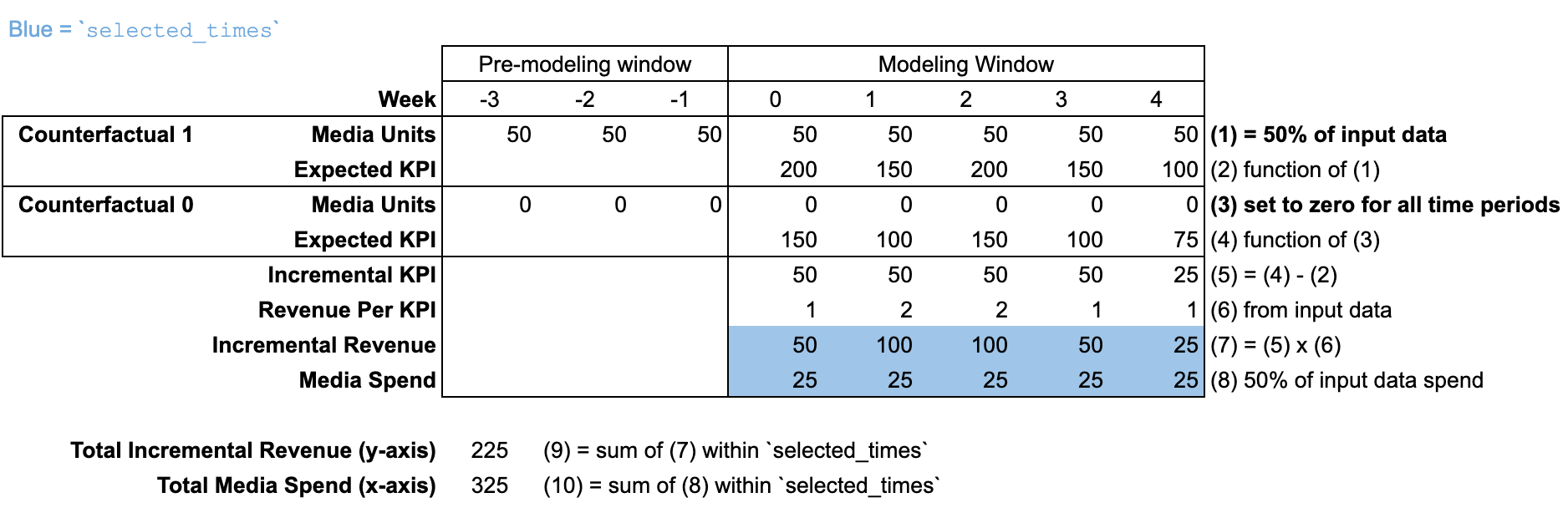
response_curves メソッドは、増分結果と費用が両方とも selected_times(デフォルトで「モデリング期間」全体)を通じて集計されるという点で roi と似ています。応答曲線の x 軸の各ポイントは、selected_times の範囲内における過去の費用の割合です。このメソッドでは、過去のメディア ユニットを同じ係数でスケーリングして、対応する増分結果(y 軸)を計算します。スケーリング ファクタは、「モデリング期間」と「モデリング前期間」の両方のメディア ユニットに適用されます。
予算の最適化は応答曲線に基づくため、同じ図が応答曲線と予算の最適化の両方に適用されます。なお、BudgetOptimizer.optimize では selected_times 引数が非推奨となり、代わりに start_date 引数と end_date 引数が使用されるようになりました。
input_data を使用する
selected_times は、デフォルトでは「モデリング期間」全体に設定されています。反事実では、「モデリング期間」と「モデリング前期間」の両方において、メディア ユニットがすべての期間でスケーリングされます。
この図では、応答曲線は input_data 予算の 50% で計算されています。
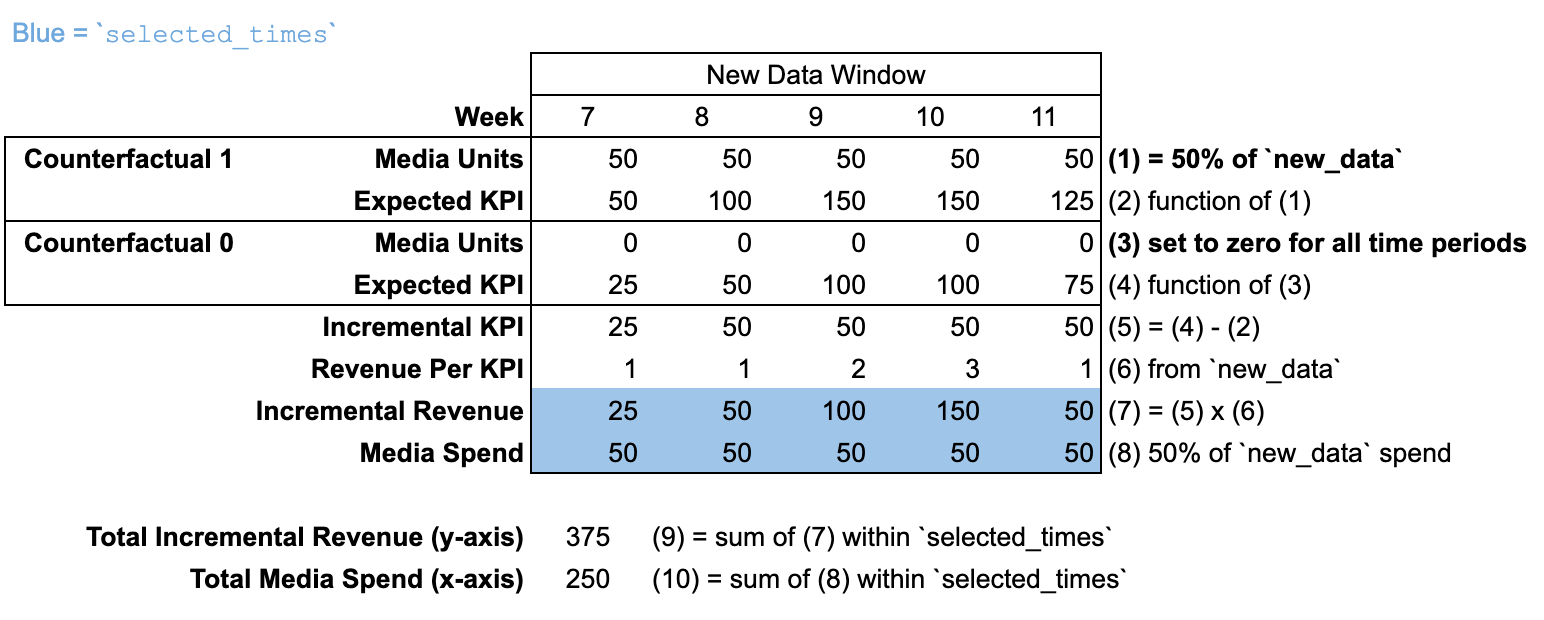
new_data を新しい期間で使用する
new_data が input_data とは異なる期間数で渡される場合、「モデリング前期間」はありません。new_data 期間より前のすべての期間で、メディア ユニットは 0 であると想定されます。
この図では、応答曲線は new_data 予算の 50% で計算されています。
予算の最適化のコード例
次の例は、予算の最適化と将来のシナリオ プランニングに対する new_data の影響を示しています。各例では、new_data を使用して変更できる、入力データの 1 つのキー属性に焦点を当てています。ただし、これらを含むすべての仮定を 1 つの最適化シナリオにまとめることができます。
ここで、入力データの最終四半期と同様のフライティング パターン、メディア ユニット単価、KPI あたりの収益が見込まれる、将来の四半期の予算を最適化するとします。入力データの最終四半期を使用して将来のシナリオを表し、変化が予想される要素を調整できます。これが、各例で示されています。
より複雑な将来のシナリオでは、入力データを新しいデータに完全に置き換える方がよい場合があります。そのために、Python で配列を構築するか、CSV ファイルからデータを読み込むことができます。
これらの例では、3 つのメディア チャネルがあります。KPI は販売単位で、revenue_per_kpi が指定されています。説明のため、各例では 2024 年第 4 四半期に基づく最適化シナリオを実行します。各例でシナリオのキー要素が変更され、new_data 引数に基づいて変更が組み込まれます。
各例のコードは、Meridian モデルが mmm として初期化されて sample_posterior メソッドが呼び出され、BudgetOptimizer が opt として初期化されていることを前提としています。
mmm = model.Meridian(...)
mmm.sample_posterior(...)
opt = optimizer.BudgetOptimizer(mmm)
例 1 - 単一チャネルの新しいメディア ユニット単価
たとえば、最初のチャネルのメディア ユニット単価が近い将来に 2 倍になると予想されるため、最適化でこのチャネルの想定メディア ユニット単価を 2 倍にするとします。そのためには、入力データと一致する費用配列を作成し、最初のチャネルの費用のみを 2 倍にします。配列は DataTensors コンストラクタに渡され、次に最適化の new_data 引数に渡されます。
media_spend を変更すると、固定予算の最適化のデフォルト合計予算と、デフォルト費用制約にも影響します。これらのデフォルトは、budget 最適化引数と pct_of_spend 最適化引数を使用してオーバーライドできます。これらの引数を認識し、必要に応じてカスタマイズすることが重要です。
# Create `new_data` from `input_data`, but double the spend for channel 0.
new_spend = mmm.input_data.media_spend
new_spend[:, :, 0] *= 2
new_data = analyzer.DataTensors(media_spend=new_spend)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
例 2 - すべてのチャネルの新しいメディア単価
すべてのチャネルでメディア ユニット単価が近い将来に変化すると予想されるため、最適化ですべてのチャネルのメディア ユニット単価の想定値を変更するとします。各チャネルの予測費用は既知の定数であり、地域と期間を問わず一定です。このタスクでは、メディア ユニット単価(cpmu)が直接入力されるため、DataTensors オブジェクトを作成する create_optimization_tensors ヘルパー メソッドが便利です。
create_optimization_tensors メソッドでは、すべての最適化引数を渡す必要があります。media または media_spend(地域と時間のディメンションを含む)を渡して、フライティング パターンを指定できます。その際、create_optimization_tensors のすべての引数の時間ディメンションが一致している必要があります(media に遅延効果の追加期間を含めることはできません)。
# Create `new_data` using the helper method. The cost per media unit (cpmu) is
# set to a constant value for each channel.
new_cpmu = np.array([0.1, 0.2, 0.5])
media_excl_lag = mmm.input_data.media[:, -mmm.n_times:, :]
new_data = opt.create_optimization_tensors(
time=mmm.input_data.time,
cpmu=new_cpmu,
media=media_excl_lag,
revenue_per_kpi=mmm.input_data.revenue_per_kpi,
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
同じタスクを、DataTensors オブジェクトを直接作成して実行することもできます。そのために、各チャネルのメディア ユニットにそのチャネルのメディア ユニット単価を掛けて、費用を計算します。
# Create `new_data` without the helper method.
# In this example, `mmm.n_media_times > mmm.n_times` because the `media` data
# contains additional lag history. These time periods are discarded to create
# the new spend data.
media_excl_lag = mmm.input_data.media[:, -mmm.n_times:, :]
new_spend = media_excl_lag * np.array([0.1, 0.2, 0.5])
new_data = analyzer.DataTensors(media_spend=new_spend)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
例 3 - 新しい KPI あたりの収益
KPI あたりの収益(単価やライフタイム バリューなど)の変化が近い将来に予想される場合は、新しい KPI あたりの収益の仮定を最適化に組み込むことができます。これにより、増分 KPI 単位あたりの想定収益は変わりますが、KPI 自体のモデル適合度は変わりません。
# Create `new_data` from `input_data`, but double the revenue per kpi.
new_data = analyzer.DataTensors(
revenue_per_kpi=mmm.input_data.revenue_per_kpi * 2
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
例 4 - 新しいフライティング パターン
将来の異なるフライティング パターン(地域や期間をまたがるメディア ユニットの相対的な割り当て)の検討が必要な場合があります。一般的な理由としては、地域間の予算移行などが挙げられます。また、データの入力期間中に導入された新しいメディア チャネルを考慮することが必要になる場合もあります。新しいチャネルが導入されると、過去のフライティング パターンでは、そのチャネルが導入された期間より前のメディア ユニット数がゼロになります。今後、新しいチャネルを継続する予定の場合は、フライティング パターン内のゼロを他の値に置き換えて、将来予定されているフライティング パターンをより的確に反映する必要があります。
この例では、最初のメディア チャネルが 2024 年の第 4 四半期に導入されたと想定しています。費用は最初がゼロで、その後、四半期を通して増加しましたが、今後はすべての地域や期間で 1 人あたりのメディア ユニットを一定に設定することを予定しています。DataTensors の media 引数は、フライティング パターンを指定するために使用されます。地域モデルでこの引数を指定する場合は、1 人あたりのメディア ユニットの観点でフライティング パターンを検討することをおすすめします。
1 人あたりのメディア ユニットの数自体(この例では 100)は、フライティング パターンに影響しません。フライティング パターンは、地域や期間をまたがるメディア ユニットの相対的な割り当てです。たとえば、1 人あたり 10 ユニットを割り当てることで、同じフライティング パターンを実現できます。ただしメディア ユニットの数は、各地域および期間内のメディア ユニットあたりの費用比率から導き出されるメディア ユニット単価の仮定にも影響します。この例では、すべての地域と期間でメディア ユニット単価を 0.1 にするために、新しい費用データが渡されます。
media_spend を変更すると、固定予算の最適化のデフォルト合計予算と、デフォルト費用制約にも影響します。これらのデフォルトは、budget 最適化引数と pct_of_spend 最適化引数を使用してオーバーライドできます。これらの引数を認識し、必要に応じてカスタマイズすることが重要です。
# Create new media units data from the input data, but set the media units per
# capita to 100 for channel 0 for all geos and time periods.
new_media = mmm.input_data.media.values
new_media[:, :, 0] = 100 * mmm.input_data.population.values[:, None]
# Set a cost per media unit of 0.1 for channel 0 for all geos and time periods.
new_media_spend = mmm.input_data.media_spend.values
new_media_spend[:, :, 0] = 0.1 * new_media[:, -mmm.n_times:, 0]
new_data = analyzer.DataTensors(
media=new_media,
media_spend=new_spend,
)
# Run fixed budget optimization on the last quarter of 2024, using customized
# total budget and constraints.
opt_results = opt.optimize(
new_data=new_data,
budget=100,
pct_of_spend=[0.3, 0.3, 0.4],
start_date="2024-10-07",
end_date="2024-12-30",
)
メリディアンが結果を予測しない理由
メリディアンでは、因果推論を将来の計画に役立てるために、想定される結果を将来にわたって予測する必要はありません。実際メリディアンには、Optimizer クラスや roi、marginal_roi、incremental_outcome など、将来の計画に役立つ多くのメソッドがあります。これらのメソッドの new_data 引数を使用すると、メリディアンの因果推論を使用して、将来の施策を含め、仮のメディア施策やフライティング パターンの数量を推定できます。
メリディアンの目標は因果推論です。より正確に言うと、介入変数が結果に及ぼす増分結果の推論です。用語集の用語を使用した増分結果の簡単な定義は次のとおりです。
\[ \text{Incremental Outcome} = \text{Expected Outcome} - \text{Counterfactual} \]
ここで、反事実の意味は介入群の種類によって異なります(詳細は用語集、より正確な定義は増分結果の定義をご覧ください)。
コントロール変数は想定される結果に影響しますが、増分結果には影響しません(コントロールがメディア効果のバイアス除去に与える影響を除く)。これは、メリディアン モデルで、コントロール変数が「想定される結果」と「反事実」の両方に加法効果を持つと指定されているためです。この効果は差分で相殺されます。想定される結果を予測するには、コントロール データを予測する必要があります。多くのコントロールはノイズが多く、予測不可能で、広告主が制御できないため、この予測は非常に難しい可能性があります。コントロール データの予測は、メリディアンの因果推論の目標とは関連性がありません。これは、想定される結果を予測しなくても、増分結果を推論して最適化できるためです。
同様に、ノットでパラメータ化された時間効果は加法的です。その結果、「想定される結果」と「反事実」はノット値に依存しますが、「増分結果」は依存しません。時間パターンをモデル化するメリディアンのノットベースのアプローチは、予測を目的としたものではありません。代わりに、時間パターンのモデルの柔軟性を大幅に高めるように設計されているため、因果推論の問題に適しています。