Po sprawdzeniu, czy najlepiej rozwiązać problem za pomocą funkcji przewidywania ML, czyli generatywną AI – chcesz przedstawić swój problem w perspektywie ML. Przedstaw problem w ramach systemów uczących się, wykonując te zadania:
- Zdefiniuj idealny wynik i cel modelu.
- Określ dane wyjściowe modelu.
- Określenie wyznaczników sukcesu.
Zdefiniuj idealny wynik i cel modelu
Jaki jest idealny rezultat niezależnie od modelu ML? Innymi słowy, dokładnie określić zadanie, które ma wykonać dany produkt lub funkcja? Nie ma żadnej zdefiniowaną wcześniej w sekcji Określ cel. .
Połącz cel modelu z idealnym wynikiem, wyraźnie określając, co od modelu. W tabeli poniżej znajdziesz idealne wyniki oraz dla hipotetycznych aplikacji:
| Aplikacja | Idealny wynik | Cel modelu |
|---|---|---|
| Aplikacja Pogoda | Oblicz opady w poszczególnych 6-godzinnych odstępach czasu w danym regionie geograficznym. | Przewiduj sześciogodzinne opady w określonych regionach geograficznych. |
| Aplikacja Moda | Generowanie różnych wzorów koszul. | Wygeneruj 3 wersje projektu koszulki na podstawie tekstu i obrazu. gdzie tekst określa styl i kolor, a obraz jest typem koszula (koszulka, zapinka, polo). |
| Aplikacja wideo | Polecanie przydatnych filmów. | Przewidują, czy użytkownik kliknie film. |
| Aplikacja Poczta | Wykrywaj spam. | Określanie, czy e-mail to spam. |
| Aplikacja finansowa | Otrzymuj streszczenia informacji finansowych z różnych źródeł wiadomości. | Wygeneruj 50-wyrazowe podsumowania głównych trendów finansowych w ciągu ostatnich 7 dni. |
| Aplikacja do map | Oblicz czas podróży. | Określ, jak długo potrwa podróż między dwoma punktami. |
| Aplikacja bankowa | Rozpoznawanie fałszywych transakcji. | Pozwala określać, czy transakcja została dokonana przez właściciela karty. |
| Aplikacja Jedzenie | Określ rodzaj kuchni na podstawie menu restauracji. | Prognozowanie rodzaju restauracji. |
| Aplikacja e-commerce | Generuj odpowiedzi obsługi klienta na temat produktów firmy. | Generuj odpowiedzi przy użyciu analizy nastawienia i bazy wiedzy. |
Określenie potrzebnych danych wyjściowych
Wybór typu modelu zależy od kontekstu i ograniczeń Twoim problemom. Dane wyjściowe modelu powinny spełniać zadanie zdefiniowane w z idealnym wynikiem. Pierwsze pytanie, na które należy odpowiedzieć, to: „Jakiego rodzaju danych wyjściowych potrzebuję, aby rozwiązać mój problem?”
Jeśli chcesz coś sklasyfikować lub wykonać prognozę liczbową, prawdopodobnie wykorzystują predykcyjne systemy uczące się. Jeśli musisz wygenerować nową treść lub dane wyjściowe związanych ze rozumieniem języka naturalnego, prawdopodobnie wybierzesz generatywną AI.
W tabelach poniżej znajdziesz dane wyjściowe prognozowanych systemów uczących się i generatywnej AI:
| System ML | Przykładowe dane wyjściowe | |
|---|---|---|
| Klasyfikacja | Binarne | Sklasyfikować e-maila jako spam lub nie spam. |
| Jednoklasowa etykieta wieloklasowa | Sklasyfikuj zwierzę na zdjęciu. | |
| Etykiety wieloklasowe | Sklasyfikuj wszystkie zwierzęta na obrazku. | |
| Liczbowe | Regresja jednowymiarowa | Określ przewidywaną liczbę wyświetleń filmu. |
| Regresja wielowymiarowa | Przewiduj ciśnienie krwi, tętno i poziom cholesterolu danej osoby. |
| Typ modelu | Przykładowe dane wyjściowe |
|---|---|
| Tekst |
Streść artykuł. Odpowiadaj na opinie klientów. Tłumacz dokumenty z języka angielskiego na mandaryński. Twórz opisy produktów. Analiza dokumentów prawnych
|
| Obraz |
Twórz obrazy marketingowe. Stosowanie efektów wizualnych do zdjęć. Wygeneruj odmiany projektu produktu.
|
| Dźwięk |
Generuj dialogi z określonym akcentem.
generowania krótkiej kompozycji muzycznej z określonego gatunku, np.
jazz.
|
| Wideo |
Twórz realistycznie wyglądające filmy.
Analizuj materiał wideo i stosuj efekty wizualne.
|
| Tryb multimodalny | Generuj różnego rodzaju dane wyjściowe, np. film z napisami tekstowymi. |
Klasyfikacja
Model klasyfikacji prognozuje, do której kategorii należą dane wejściowe, np. czy dane wejściowe należy sklasyfikować jako A, B lub C.
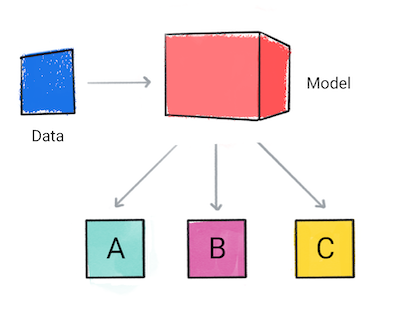
Rysunek 1. Model klasyfikacji tworzący prognozy.
Na podstawie prognozy modelu aplikacja może podjąć decyzję. Na przykład, jeśli prognozą jest kategoria A, a następnie działanie X; jeśli prognoza należy do kategorii B, to do, Y; jeśli prognoza należy do kategorii C, wykonaj operację Z. W niektórych przypadkach przewidywanie to dane wyjściowe aplikacji.
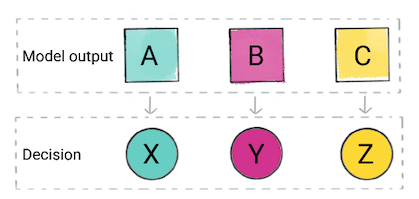
Rysunek 2. Dane wyjściowe modelu klasyfikacji używane w kodzie usługi do podjąć decyzję.
Regresja
Model regresji prognozuje wartość liczbową.
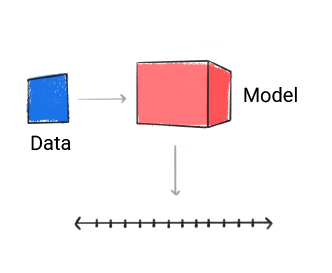
Rysunek 3. Model regresji przygotowujący prognozę liczbową.
Na podstawie prognozy modelu aplikacja może podjąć decyzję. Na przykład, jeśli prognoza należy do zakresu A do X; jeśli prognoza mieści się w zakresie B do Y; jeśli prognoza mieści się w zakresie C, należy zrobić Z. W niektórych przypadkach prognoza to wynik aplikacji.
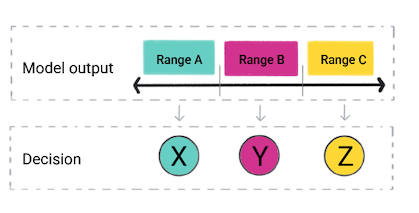
Rysunek 4. Dane wyjściowe modelu regresji używane w kodzie usługi do podjąć decyzję.
Przyjrzyjmy się temu scenariuszowi:
Chcesz zapisać w pamięci podręcznej. filmów na podstawie ich przewidywanej popularności. Innymi słowy, jeśli model zgodnie z przewidywaniami, że film będzie popularny, chcesz jak najszybciej go wyświetlić użytkownikom. Do korzystasz z wydajniejszej i kosztowniejszej pamięci podręcznej. W przypadku innych filmów używasz innej pamięci podręcznej. Kryteria buforowania:
- Jeśli według prognozy film będzie miał co najmniej 50 wyświetleń, użyj opcji pamięci podręcznej.
- Jeśli według prognozy film ma od 30 do 50 wyświetleń, użyj opcji „taniej” pamięci podręcznej.
- Jeśli według prognozy film ma mniej niż 30 wyświetleń, nie będą zapisywane w pamięci podręcznej film.
Uważasz, że model regresji jest właściwym podejściem, ponieważ będziesz prognozować wartość liczbowa, czyli liczba wyświetleń. Jednak podczas trenowania regresji model generuje ten sam efekt strata dla prognozy na 28 i 32 w przypadku filmów, które mają 30 wyświetleń. Innymi słowy, chociaż aplikacja ma bardzo jeśli prognoza to 28 i 32, model uwzględnia obie prognozy są równie dobre.
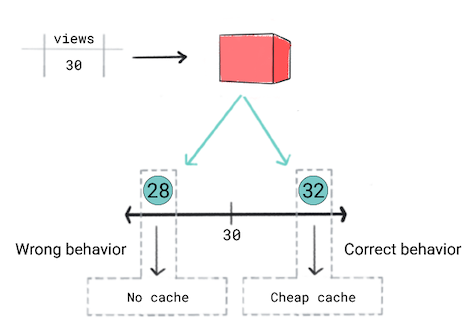
Rysunek 5. Trenuję model regresji.
Modele regresji nie uwzględniają progów zdefiniowanych przez produkty. Dlatego, jeśli zachowanie aplikacji znacznie się zmienia ze względu na niewielkie różnice w do prognoz modelu regresji, rozważ wdrożenie model klasyfikacji.
W tym scenariuszu model klasyfikacji wygenerowałby prawidłowe zachowanie ponieważ model klasyfikacji generowałby większą stratę dla prognozy 28 niż 32. W pewnym sensie modele klasyfikacji domyślnie generują progi.
Ten scenariusz podkreśla 2 ważne kwestie:
Przygotuj prognozę decyzji. W miarę możliwości możesz przewidzieć decyzję, jaką podejmuje Twoja aplikacja i podjąć. W przykładzie wideo model klasyfikacji przewidywałby jeśli kategoriami, do których sklasyfikował filmy, są „brak pamięci podręcznej”, „tani” pamięć podręczną”, i „droga pamięć podręczna”. Ukrycie zachowania aplikacji przed modelem może powoduje nieprawidłowe zachowanie aplikacji.
Zapoznaj się z ograniczeniami problemu. Jeśli aplikacja ma inne działania na podstawie różnych progów, określ, czy są one stały lub dynamiczny.
- Progi dynamiczne: jeśli progi są dynamiczne, użyj modelu regresji. i ustaw limity progów w kodzie aplikacji. Dzięki temu możesz łatwo aktualizować progi, jednocześnie dbając o to, aby model i generowanie prognoz.
- Stałe progi: jeśli progi są stałe, użyj modelu klasyfikacji i oznaczaj zbiory danych etykietami na podstawie limitów progowych.
Ogólnie większość obsługi pamięci podręcznej ma charakter dynamiczny, a progi zmieniają się w czasie. Ponieważ jest to w szczególności problem buforowania, model regresji jest najlepszym wyborem. Jednak w przypadku wielu problemów progi zostaną ustalone, dzięki czemu model klasyfikacji będzie najlepszym rozwiązaniem.
Przeanalizujmy kolejny przykład. Jeśli tworzysz aplikację pogodową,
idealnym rozwiązaniem jest poinformowanie użytkowników, ile będzie padać w ciągu najbliższych 6 godzin,
możesz użyć modelu regresji, który prognozuje etykietę precipitation_amount.
| Idealny wynik | Idealna etykieta |
|---|---|
| Poinformuj użytkowników, jak bardzo będzie padać w ich okolicy w ciągu następnych 6 godzin. | precipitation_amount
|
W przykładzie w aplikacji Pogoda etykieta bezpośrednio odnosi się do idealnego wyniku.
Jednak w niektórych przypadkach relacja 1:1 nie jest widoczna między
i etykietę. Na przykład w przypadku aplikacji wideo idealny wynik to
do polecania przydatnych filmów. W zbiorze danych nie ma jednak etykiety o nazwie
useful_to_user.
| Idealny wynik | Idealna etykieta |
|---|---|
| Polecaj przydatne filmy. | ? |
Dlatego musisz znaleźć etykietę serwera proxy.
Etykiety serwera proxy
Zamiennik etykiet serwera proxy
etykiet, których nie ma w zbiorze danych. Etykiety serwera proxy są potrzebne, gdy nie możesz
mierzyć bezpośrednio to, co chcesz prognozować. W aplikacji wideo nie możemy
pozwalają ocenić, czy film będzie przydatny dla użytkownika. Byłoby wspaniale, gdyby
w zbiorze danych miał funkcję useful, a użytkownicy oznaczali wszystkie znalezione filmy.
przydatne, ale ponieważ zbiór danych tego nie robi, będziemy potrzebować etykiety serwera proxy,
i innych metod.
Etykieta proxy dotycząca przydatności to informacja, czy użytkownik udostępni lub polubi w filmie.
| Idealny wynik | Etykieta serwera proxy |
|---|---|
| Polecaj przydatne filmy. | shared OR liked |
Zachowaj ostrożność w przypadku etykiet serwerów proxy, ponieważ nie mierzą one bezpośrednio tego, co chcesz do prognozowania. Na przykład w poniższej tabeli podano problemy z potencjalną etykiety proxy dla opcji Poleć przydatne filmy:
| Etykieta serwera proxy | Problem |
|---|---|
| Przewidują, czy użytkownik kliknie przycisk „Podoba mi się” Przycisk | Większość użytkowników nigdy nie klika „Podoba mi się”. |
| Przewidują, czy film będzie popularny. | Niespersonalizowane. Niektórzy użytkownicy mogą nie lubić popularnych filmów. |
| Przewidują, czy użytkownik udostępni film. | Niektórzy użytkownicy nie udostępniają filmów. Czasami inni udostępniają filmy, których nie lubią. |
| Przewidują, czy użytkownik kliknie przycisk odtwarzania. | Maksymalizuje clickbait. |
| Przewidywać, jak długo będą oglądać film. | W przeciwieństwie do krótkich wolą długie filmy. |
| Przewidują, ile razy użytkownik ponownie obejrzy film | Zachęcanie do wielokrotnego oglądania w porównaniu z gatunkami, których nie da się oglądać ponownie. |
Żadna etykieta pośrednia nie może idealnie zastąpić idealnego wyniku. Wszyscy mogą powodować problemy. Wybierz tę, która będzie najmniej sprawiać problemy dla każdego przypadku użycia.
Sprawdź swoją wiedzę
Generacja
W większości przypadków nie da się wytrenować własnego modelu generatywnego, wymaga ogromnych ilości danych treningowych i zasobów obliczeniowych. Zamiast tego: dostosujesz już wytrenowany model generatywny. Aby model generatywny w celu wygenerowania pożądanych wyników, może być konieczne użycie co najmniej jednej z tych metod techniki:
Oczyszczanie. Aby utworzyć mniejsza wersja większego modelu, generujesz zbiór danych z etykietami syntetycznymi, z większego modelu używanego do trenowania mniejszego modelu. Generatywne modele są zwykle gigantyczne i pochłaniają znaczne zasoby (takie jak pamięć) i elektryczność). Oczyszczanie umożliwia mniejsze i mniej wymagające zasobów aby oszacować wydajność większego modelu.
Dostrajanie lub dostrajanie i optymalizowanie pod kątem wydajności. Aby poprawić wydajność modelu w konkretnym zadaniu, musisz dodatkowo wytrenuj model na zbiorze danych zawierającym przykłady typu danych wyjściowych które chcemy produkować.
Inżynieria promptów. Do pobierz model do wykonania określonego zadania lub w którym generujesz dane wyjściowe w określonym formacie, mówisz modelowi, jakiego działania wyjaśnić, jak sformatować dane wyjściowe. Innymi słowy, prompt może zawierać instrukcje w języku naturalnym, aby wykonać zadanie lub ilustracyjnych przykładów z odpowiednimi wynikami.
Jeśli na przykład potrzebujesz krótkich streszczeń artykułów, możesz wpisać parametr :
Produce 100-word summaries for each article.Jeśli chcesz, aby model generował tekst dla konkretnego poziomu języka, możesz wpisać:
All the output should be at a reading level for a 12-year-old.Jeśli chcesz, aby model dostarczał dane wyjściowe w określonym formacie, możesz wyjaśnić, jak powinny być sformatowane dane wyjściowe, na przykład „formatować w tabeli” – albo możesz zademonstrować zadanie, podając przykłady. Możesz na przykład wpisać:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
Oczyszczanie i dostrajanie aktualizuje model parameters. Inżynieria promptów nie aktualizuje parametrów modelu. Inżynieria promptów pomaga model uczy się, jak uzyskać pożądane dane wyjściowe na podstawie kontekstu promptu.
W niektórych przypadkach trzeba też testowego zbioru danych do oceny danych wyjściowych modelu generatywnego względem znanych wartości, na przykład podsumowania modelu są podobne do podsumowań wygenerowanych przez człowieka lub że ludzie podsumowania modelu są tak dobre.
Generatywnej AI można też wykorzystać do wdrożenia predykcyjnych systemów uczących się takich jak klasyfikacja czy regresja. Na przykład ze względu na dogłębną znajomość języka naturalnego dużych modeli językowych (LLM) mogą często wykonywać zadania klasyfikacji tekstu lepiej niż uczenie predykcyjne i wytrenowanych pod kątem konkretnego zadania.
Określenie wyznaczników sukcesu
Zdefiniuj wskaźniki, które będą używane do określania, czy implementacja systemów uczących się uda się. Wskaźniki sukcesu określają, na czym Ci zależy, np. zaangażowanie lub pomaganie użytkownikom w podejmowaniu odpowiednich działań, np. oglądaniu filmów, które znajdą przydatne. Wskaźniki sukcesu różnią się od wskaźników oceny modelu, takich jak accuracy, precyzja, recall, AUC.
Na przykład dane o sukcesie i niepowodzeniu aplikacji pogodowej mogą być zdefiniowane jako następujące:
| Sukces | Użytkownicy otwierają okno „Czy będzie padać?” polecaj o 50% częściej niż wcześniej. |
|---|---|
| Błąd | Użytkownicy otwierają okno „Czy będzie padać?” nie częściej niż wcześniej. |
Dane dotyczące aplikacji wideo mogą być zdefiniowane w ten sposób:
| Sukces | Użytkownicy spędzają w witrynie średnio 20% więcej czasu. |
|---|---|
| Błąd | Użytkownicy nie spędzają w witrynie więcej czasu niż wcześniej. |
Zalecamy określenie ambitnych wyznaczników sukcesu. Wysokie ambicje mogą powodować rozbieżności między sukcesem a porażką. Na przykład użytkownicy wydają średnio 10% więcej czasu w witrynie niż wcześniej to ani sukces, ani porażka. Niezdefiniowana przerwa nie jest istotna.
Ważne jest, aby model mógł przybić się do „przekracza” – definicję sukcesu. Na przykład podczas analizowania modelu Rozważ następujące pytanie: Czy ulepszenie modelu przyniesie są bliżej zdefiniowanych kryteriów sukcesu? Model może mieć na przykład świetne wyniki oceny skuteczności, ale nie przybliżają do kryteriów sukcesu, że nawet idealny model nie spełni kryteriów sukcesu, zdefiniowano jego definicję. Z drugiej strony model może mieć słabe wskaźniki oceny, ale bliżej kryteriów sukcesu, co oznacza, że ulepszenie modelu przybliżają Cię do sukcesu.
Oto wymiary, które należy wziąć pod uwagę przy określaniu, czy model jest wart ulepszanie:
Niewystarczająco dobre, ale kontynuuj. Modelu nie należy używać w funkcji ale z czasem możemy je znacznie ulepszyć.
Wystarczająco dobrze, i kontynuuj. Modelu można użyć w środowisku produkcyjnym i można go jeszcze ulepszyć.
Wystarczająco dobrze, ale nie można go ulepszyć. Model jest w wersji produkcyjnej ale jest ona już chyba najlepsza.
Niewystarczająco dobre i nigdy nie będzie. Modelu nie należy używać w funkcji bez konieczności trenowania i ćwiczenia.
Zanim zdecydujesz się na ulepszenie modelu, zastanów się, czy wzrost zasobów, np. czas pracy inżynierskiej i koszty obliczeniowe, uzasadniają przewidywaną poprawę w modelu.
Po zdefiniowaniu wyznaczników sukcesu i niepowodzeń musisz określić, jak często aby je mierzyć. Możesz na przykład mierzyć wskaźniki sukcesu 6 dni, 6 tygodni lub 6 miesięcy od wdrożenia systemu.
Analizując wskaźniki błędów, spróbuj ustalić przyczyny niepowodzenia systemu. Dla: model może np. przewidzieć, które filmy użytkownicy klikną, ale może zacząć rekomendować tytuły clickbait, które powodują zaangażowanie użytkowników rezygnuje z oglądania. W przykładzie aplikacji Pogoda model może dokładnie przewidzieć, kiedy będzie padać, ale w zbyt dużym regionie geograficznym.
Sprawdź swoją wiedzę
Firma odzieżowa chce sprzedawać więcej ubrań. Ktoś sugeruje wykorzystanie systemów uczących się do określić, jakie ubrania powinna produkować firma. Sądzi, że mogą wytrenować modelkę, aby określić, jakie rodzaje ubrań są modne. Po gdy trenują model, chcą zastosować go do katalogu, które ubrania wybrać.
Jak powinna przedstawić swój problem w rozumieniu ML?
Idealny wynik: określenie, które produkty chcesz wyprodukować.
Cel modelu: przewidywanie, które artykuły odzieży są w w świecie mody.
Dane wyjściowe modelu: klasyfikacja binarna, in_fashion,
not_in_fashion
Wskaźniki sukcesu: sprzedawaj co najmniej 70% odzieży. podjętych działań.
Idealny wynik: ustal, ile tkanin i materiałów chcesz zamówić.
Cel modelu: możesz przewidzieć, jaką część każdego produktu chcesz wyprodukować.
Dane wyjściowe modelu: klasyfikacja binarna, make,
do_not_make
Wskaźniki sukcesu: sprzedawaj co najmniej 70% odzieży. podjętych działań.