Page Summary
-
Framing machine learning problems involves defining the desired outcome, identifying the model's output (classification, regression, or generation), and establishing success metrics.
-
Generative AI models can be customized through techniques like distillation, fine-tuning, and prompt engineering to achieve specific tasks.
-
Success metrics should reflect the desired business outcome of the ML implementation and be distinct from model evaluation metrics.
-
Regularly measuring success, analyzing failures, and understanding model improvement potential are crucial for effective ML solutions.
-
When implementing ML solutions, consider problem constraints, proxy labels, and the type of model output needed for the specific task.
After verifying that your problem is best solved using either a predictive ML or a generative AI approach, you're ready to frame your problem in ML terms. You frame a problem in ML terms by completing the following tasks:
- Define the ideal outcome and the model's goal.
- Identify the model's output.
- Define success metrics.
Define the ideal outcome and the model's goal
Independent of the ML model, what's the ideal outcome? In other words, what is the exact task you want your product or feature to perform? This is the same statement you previously defined in the State the goal section.
Connect the model's goal to the ideal outcome by explicitly defining what you want the model to do. The following table states the ideal outcomes and the model's goal for hypothetical apps:
| App | Ideal outcome | Model's goal |
|---|---|---|
| Weather app | Calculate precipitation in six hour increments for a geographic region. | Predict six-hour precipitation amounts for specific geographic regions. |
| Fashion app | Generate a variety of shirt designs. | Generate three varieties of a shirt design from text and an image, where the text states the style and color and the image is the type of shirt (t-shirt, button-up, polo). |
| Video app | Recommend useful videos. | Predict whether a user will click on a video. |
| Mail app | Detect spam. | Predict whether or not an email is spam. |
| Financial app | Summarize financial information from multiple news sources. | Generate 50-word summaries of the major financial trends from the previous seven days. |
| Map app | Calculate travel time. | Predict how long it will take to travel between two points. |
| Banking app | Identify fraudulent transactions. | Predict if a transaction was made by the card holder. |
| Dining app | Identify cuisine by a restaurant's menu. | Predict the type of restaurant. |
| Ecommerce app | Generate customer support replies about the company's products. | Generate replies using sentiment analysis and the organization's knowledge base. |
Identify the output you need
Your choice of model type depends upon the specific context and constraints of your problem. The model's output should accomplish the task defined in the ideal outcome. Thus, the first question to answer is "What type of output do I need to solve my problem?"
If you need to classify something or make a numeric prediction, you'll probably use predictive ML. If you need to generate new content or produce output related to natural language understanding, you'll probably use generative AI.
The following tables list predictive ML and generative AI outputs:
| ML system | Example output | |
|---|---|---|
| Classification | Binary | Classify an email as spam or not spam. |
| Multiclass single-label | Classify an animal in an image. | |
| Multiclass multi-label | Classify all the animals in an image. | |
| Numerical | Unidimensional regression | Predict the number of views a video will get. |
| Multidimensional regression | Predict blood pressure, heart rate, and cholesterol levels for an individual. |
| Model type | Example output |
|---|---|
| Text |
Summarize an article. Reply to customer reviews. Translate documents from English to Mandarin. Write product descriptions. Analyze legal documents.
|
| Image |
Produce marketing images. Apply visual effects to photos. Generate product design variations.
|
| Audio |
Generate dialogue in a specific accent.
Generate a short musical composition in a specific genre, like
jazz.
|
| Video |
Generate realistic-looking videos.
Analyze video footage and apply visual effects.
|
| Multimodal | Produce multiple types of output, like a video with text captions. |
Classification
A classification model predicts what category the input data belongs to, for example, whether an input should be classified as A, B, or C.
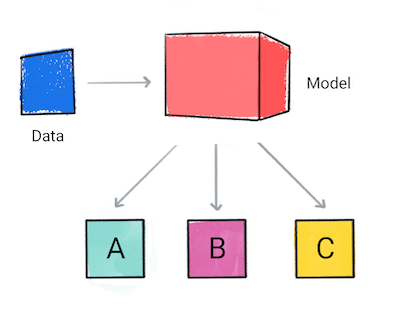
Figure 1. A classification model making predictions.
Based on the model's prediction, your app might make a decision. For example, if the prediction is category A, then do X; if the prediction is category B, then do, Y; if the prediction is category C, then do Z. In some cases, the prediction is the app's output.
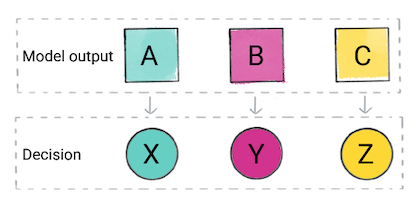
Figure 2. A classification model's output being used in the product code to make a decision.
Regression
A regression model predicts a numerical value.
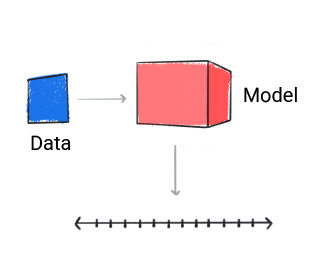
Figure 3. A regression model making a numeric prediction.
Based on the model's prediction, your app might make a decision. For example, if the prediction falls within range A, do X; if the prediction falls within range B, do Y; if the prediction falls within range C, do Z. In some cases, the prediction is the app's output.
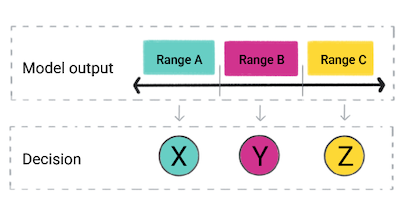
Figure 4. A regression model's output being used in the product code to make a decision.
Consider the following scenario:
You want to cache videos based on their predicted popularity. In other words, if your model predicts that a video will be popular, you want to quickly serve it to users. To do so, you'll use the more effective and expensive cache. For other videos, you'll use a different cache. Your caching criteria is the following:
- If a video is predicted to get 50 or more views, you'll use the expensive cache.
- If a video is predicted to get between 30 and 50 views, you'll use the cheap cache.
- If the video is predicted to get less than 30 views, you won't cache the video.
You think a regression model is the right approach because you'll be predicting a numeric value—the number of views. However, when training the regression model, you realize that it produces the same loss for a prediction of 28 and 32 for videos that have 30 views. In other words, although your app will have very different behavior if the prediction is 28 versus 32, the model considers both predictions equally good.
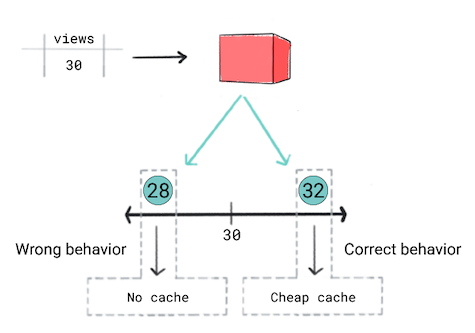
Figure 5. Training a regression model.
Regression models are unaware of product-defined thresholds. Therefore, if your app's behavior changes significantly because of small differences in a regression model's predictions, you should consider implementing a classification model instead.
In this scenario, a classification model would produce the correct behavior because a classification model would produce a higher loss for a prediction of 28 than 32. In a sense, classification models produce thresholds by default.
This scenario highlights two important points:
Predict the decision. When possible, predict the decision your app will take. In the video example, a classification model would predict the decision if the categories it classified videos into were "no cache," "cheap cache," and "expensive cache." Hiding your app's behavior from the model can cause your app to produce the wrong behavior.
Understand the problem's constraints. If your app takes different actions based on different thresholds, determine if those thresholds are fixed or dynamic.
- Dynamic thresholds: If thresholds are dynamic, use a regression model and set the thresholds limits in your app's code. This lets you easily update the thresholds while still having the model make reasonable predictions.
- Fixed thresholds: If thresholds are fixed, use a classification model and label your datasets based on the threshold limits.
In general, most cache provisioning is dynamic and the thresholds change over time. Therefore, because this is specifically a caching problem, a regression model is the best choice. However, for many problems, the thresholds will be fixed, making a classification model the best solution.
Let's take a look at another example. If you're building a weather app whose
ideal outcome is to tell users how much it will rain in the next six hours,
you could use a regression model that predicts the label precipitation_amount.
| Ideal outcome | Ideal label |
|---|---|
| Tell users how much it will rain in their area in the next six hours. | precipitation_amount
|
In the weather app example, the label directly addresses the ideal outcome.
However, in some cases, a one-to-one relationship isn't apparent between the
ideal outcome and the label. For example, in the video app, the ideal outcome is
to recommend useful videos. However, there's no label in the dataset called
useful_to_user.
| Ideal outcome | Ideal label |
|---|---|
| Recommend useful videos. | ? |
Therefore, you must find a proxy label.
Proxy labels
Proxy labels substitute for
labels that aren't in the dataset. Proxy labels are necessary when you can't
directly measure what you want to predict. In the video app, we can't directly
measure whether or not a user will find a video useful. It would be great if the
dataset had a useful feature, and users marked all the videos that they found
useful, but because the dataset doesn't, we'll need a proxy label that
substitutes for usefulness.
A proxy label for usefulness might be whether or not the user will share or like the video.
| Ideal outcome | Proxy label |
|---|---|
| Recommend useful videos. | shared OR liked |
Be cautious with proxy labels because they don't directly measure what you want to predict. For example, the following table outlines issues with potential proxy labels for Recommend useful videos:
| Proxy label | Issue |
|---|---|
| Predict whether the user will click the "like" button. | Most users never click "like." |
| Predict whether a video will be popular. | Not personalized. Some users might not like popular videos. |
| Predict whether the user will share the video. | Some users don't share videos. Sometimes, people share videos because they don't like them. |
| Predict whether the user will click play. | Maximizes clickbait. |
| Predict how long they watch the video. | Favors long videos differentially over short videos. |
| Predict how many times the user will rewatch the video. | Favors "rewatchable" videos over video genres that aren't rewatchable. |
No proxy label can be a perfect substitute for your ideal outcome. All will have potential problems. Pick the one that has the least problems for your use case.
Check Your Understanding
Generation
In most cases, you won't train your own generative model because doing so requires massive amounts of training data and computational resources. Instead, you'll customize a pre-trained generative model. To get a generative model to produce your desired output, you might need to use one or more of the following techniques:
Distillation. To create a smaller version of a larger model, you generate a synthetic labeled dataset from the larger model that you use to train the smaller model. Generative models are typically gigantic and consume substantial resources (like memory and electricity). Distillation allows the smaller, less resource-intensive model to approximate the performance of the larger model.
Fine-tuning or parameter-efficient tuning. To improve the performance of a model on a specific task, you need to further train the model on a dataset that contains examples of the type of output you want to produce.
Prompt engineering. To get the model to perform a specific task or produce output in a specific format, you tell the model the task you want it to do or explain how you want the output formatted. In other words, the prompt can include natural language instructions for how to perform the task or illustrative examples with the desired outputs.
For example, if you want short summaries of articles, you might input the following:
Produce 100-word summaries for each article.If you want the model to generate text for a specific reading level, you might input the following:
All the output should be at a reading level for a 12-year-old.If you want the model to provide its output in a specific format, you might explain how the output should be formatted—for example, "format the results in a table"—or you could demonstrate the task by giving it examples. For instance, you could input the following:
Translate words from English to Spanish. English: Car Spanish: Auto English: Airplane Spanish: Avión English: Home Spanish:______
Distillation and fine-tuning update the model's parameters. Prompt engineering doesn't update the model's parameters. Instead, prompt engineering helps the model learn how to produce a desired output from the context of the prompt.
In some cases, you'll also need a test dataset to evaluate a generative model's output against known values, for example, checking that the model's summaries are similar to human-generated ones, or that humans rate the model's summaries as good.
Generative AI can also be used to implement a predictive ML solution, like classification or regression. For example, because of their deep knowledge of natural language, large language models (LLMs) can frequently perform text classification tasks better than predictive ML trained for the specific task.
Define the success metrics
Define the metrics you'll use to determine whether or not the ML implementation is successful. Success metrics define what you care about, like engagement or helping users take appropriate action, such as watching videos that they'll find useful. Success metrics differ from the model's evaluation metrics, like accuracy, precision, recall, or AUC.
For example, the weather app's success and failure metrics might be defined as the following:
| Success | Users open the "Will it rain?" feature 50 percent more often than they did before. |
|---|---|
| Failure | Users open the "Will it rain?" feature no more often than before. |
The video app metrics might be defined as the following:
| Success | Users spend on average 20 percent more time on the site. |
|---|---|
| Failure | Users spend on average no more time on site than before. |
We recommend defining ambitious success metrics. High ambitions can cause gaps between success and failure though. For example, users spending on average 10 percent more time on the site than before is neither success nor failure. The undefined gap is not what's important.
What's important is your model's capacity to move closer—or exceed—the definition of success. For instance, when analyzing the model's performance, consider the following question: Would improving the model get you closer to your defined success criteria? For example, a model might have great evaluation metrics, but not move you closer to your success criteria, indicating that even with a perfect model, you wouldn't meet the success criteria you defined. On the other hand, a model might have poor evaluation metrics, but get you closer to your success criteria, indicating that improving the model would get you closer to success.
The following are dimensions to consider when determining if the model is worth improving:
Not good enough, but continue. The model shouldn't be used in a production environment, but over time it might be significantly improved.
Good enough, and continue. The model could be used in a production environment, and it might be further improved.
Good enough, but can't be made better. The model is in a production environment, but it is probably as good as it can be.
Not good enough, and never will be. The model shouldn't be used in a production environment and no amount of training will probably get it there.
When deciding to improve the model, re-evaluate if the increase in resources, like engineering time and compute costs, justify the predicted improvement of the model.
After defining the success and failure metrics, you need to determine how often you'll measure them. For instance, you could measure your success metrics six days, six weeks, or six months after implementing the system.
When analyzing failure metrics, try to determine why the system failed. For example, the model might be predicting which videos users will click, but the model might start recommending clickbait titles that cause user engagement to drop off. In the weather app example, the model might accurately predict when it will rain but for too large of a geographic region.
Check Your Understanding
A fashion firm wants to sell more clothes. Someone suggests using ML to determine which clothes the firm should manufacture. They think they can train a model to determine which type of clothes are in fashion. After they train the model, they want to apply it to their catalog to decide which clothes to make.
How should they frame their problem in ML terms?
Ideal outcome: Determine which products to manufacture.
Model's goal: Predict which articles of clothing are in fashion.
Model output: Binary classification, in_fashion,
not_in_fashion
Success metrics: Sell seventy percent or more of the clothes made.
Ideal outcome: Determine how much fabric and supplies to order.
Model's goal: Predict how much of each item to manufacture.
Model output: Binary classification, make,
do_not_make
Success metrics: Sell seventy percent or more of the clothes made.