Узнайте, как Google разработал современную модель классификации изображений, обеспечивающую поиск в Google Фото. Пройдите ускоренный курс по сверточным нейронным сетям, а затем создайте свой собственный классификатор изображений, чтобы отличать фотографии кошек от фотографий собак.
Предварительные условия
Ускоренный курс машинного обученияили аналогичный опыт работы с основами ML
Знание основ программирования и некоторый опыт программирования на Python.
Введение
В мае 2013 года Google выпустила функцию поиска личных фотографий , предоставив пользователям возможность находить фотографии в своих библиотеках на основе объектов, присутствующих на изображениях.
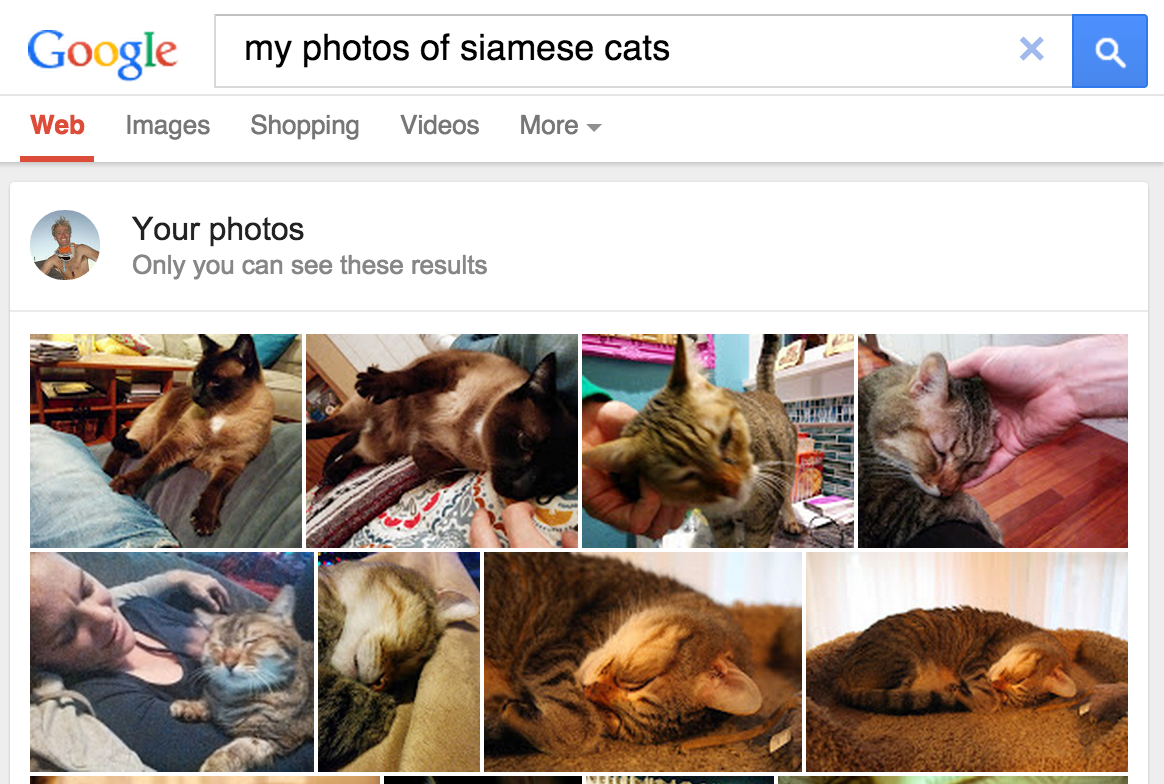 Рисунок 1. Поиск сиамских кошек в Google Фото дает результат!
Рисунок 1. Поиск сиамских кошек в Google Фото дает результат!
Эта функция, позже включенная в Google Photos в 2015 году, была широко воспринята как переломный момент, доказательство концепции того, что программное обеспечение компьютерного зрения может классифицировать изображения в соответствии с человеческими стандартами, увеличивая ценность несколькими способами:
- Пользователям больше не нужно было помечать фотографии такими ярлыками, как «пляж», чтобы классифицировать содержимое изображений, что устраняло ручную задачу, которая могла стать довольно утомительной при управлении наборами из сотен или тысяч изображений.
- Пользователи могли по-новому исследовать свою коллекцию фотографий, используя поисковые запросы для поиска фотографий с объектами, которые они, возможно, никогда не отмечали. Например, они могли бы ввести в поиск «пальма», чтобы просмотреть все свои фотографии из отпуска, на заднем плане которых были пальмы.
- Программное обеспечение потенциально может «видеть» таксономические различия, которые сами конечные пользователи могут не заметить (например, различать сиамских и абиссинских кошек), эффективно расширяя знания пользователей в предметной области.
Как работает классификация изображений
Классификация изображений — это контролируемая задача обучения: определите набор целевых классов (объектов для идентификации на изображениях) и обучите модель распознавать их, используя помеченные примеры фотографий. Ранние модели компьютерного зрения полагались на необработанные пиксельные данные в качестве входных данных для модели. Однако, как показано на рисунке 2, одни только необработанные пиксельные данные не обеспечивают достаточно стабильного представления, чтобы охватить множество вариаций объекта, запечатленного на изображении. Положение объекта, фон за объектом, окружающее освещение, угол камеры и фокус камеры — все это может вызывать колебания необработанных пиксельных данных; эти различия настолько значительны, что их нельзя скорректировать путем взвешивания средних значений RGB пикселей.
 Рисунок 2. Слева : кошек можно запечатлеть на фотографии в разных позах, на разном фоне и в условиях освещения. Справа : усреднение данных пикселей для учета этого разнообразия не дает никакой значимой информации.
Рисунок 2. Слева : кошек можно запечатлеть на фотографии в разных позах, на разном фоне и в условиях освещения. Справа : усреднение данных пикселей для учета этого разнообразия не дает никакой значимой информации.
Чтобы моделировать объекты более гибко, в классические модели компьютерного зрения были добавлены новые функции, полученные на основе данных пикселей, такие как цветовые гистограммы , текстуры и формы. Обратной стороной этого подхода было то, что разработка функций стала настоящим бременем, поскольку нужно было настроить очень много входных данных. Какие цвета были наиболее актуальными для классификатора кошек? Насколько гибкими должны быть определения форм? Поскольку функции необходимо было настраивать очень точно, построение надежных моделей было довольно сложной задачей, и точность страдала.