Le attività di apprendimento supervisionato sono ben definite e possono essere applicate a una moltitudine di scenari, come l'identificazione dello spam o la previsione delle precipitazioni.
Concetti fondamentali di apprendimento supervisionato
Il machine learning supervisionato si basa sui seguenti concetti fondamentali:
- Dati
- Modello
- Formazione
- Valutazione
- Inferenza
Dati
I dati sono la forza trainante del machine learning. I dati si presentano sotto forma di parole e numeri memorizzati in tabelle o come valori di pixel e forme d'onda acquisiti in immagini e file audio. Archiviiamo i dati correlati nei set di dati. Ad esempio, potremmo avere un set di dati costituito da quanto segue:
- Images of cats
- Prezzi delle abitazioni
- Informazioni sul meteo
I set di dati sono costituiti da singoli esempi contenenti funzionalità e un' etichetta. Puoi considerare un esempio come analogo a una singola riga in un foglio di lavoro. Le caratteristiche sono i valori utilizzati da un modello supervisionato per prevedere l'etichetta. L'etichetta è la "risposta" o il valore che vogliamo che il modello preveda. In un modello meteorologico che prevede le precipitazioni, le caratteristiche potrebbero essere latitudine, longitudine, temperatura, umidità, copertura nuvolosa, direzione del vento e pressione atmosferica. L'etichetta sarà quantità di pioggia.
Gli esempi che contengono sia elementi che un'etichetta sono chiamati esempi etichettati.
Due esempi con etichetta

Al contrario, gli esempi non etichettati contengono elementi, ma nessuna etichetta. Dopo aver creato un modello, questo prevede l'etichetta dalle funzionalità.
Due esempi non etichettati
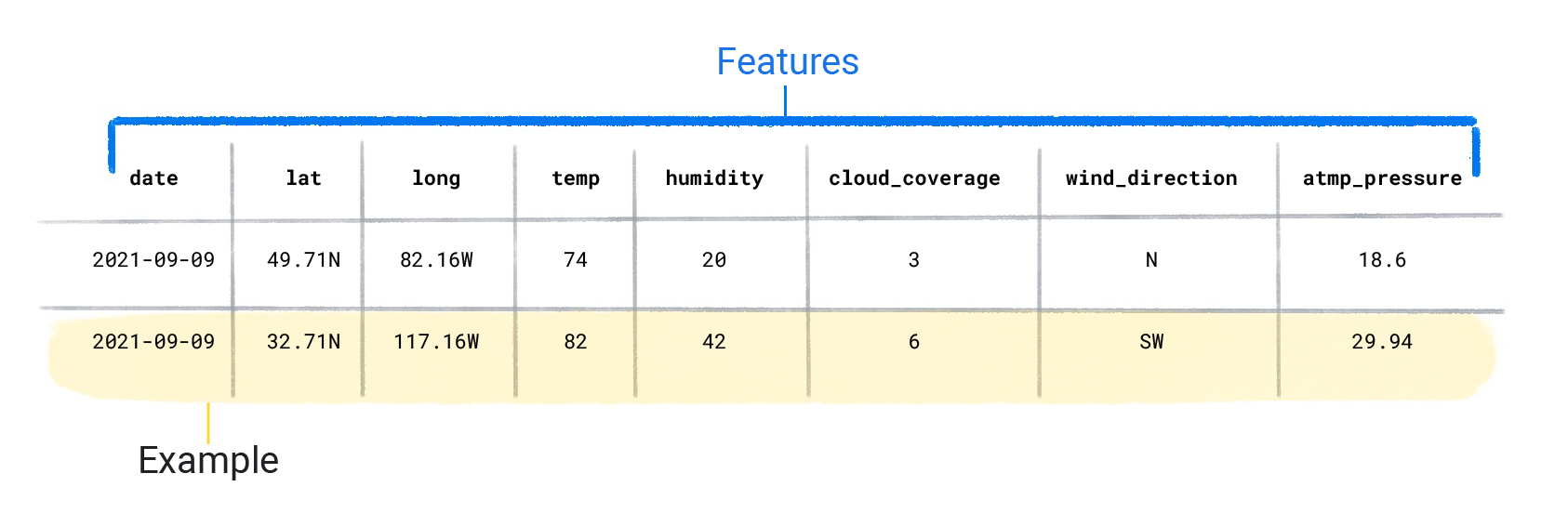
Caratteristiche del set di dati
Un set di dati è caratterizzato dalle sue dimensioni e dalla sua diversità. La dimensione indica il numero di esempi. La diversità indica l'intervallo coperto da questi esempi. I set di dati di buona qualità sono di grandi dimensioni e molto diversi.
I set di dati possono essere grandi e diversificati, grandi ma non diversificati o piccoli ma molto diversificati. In altre parole, un set di dati grande non garantisce una diversità sufficiente e un set di dati molto diversificato non garantisce esempi sufficienti.
Ad esempio, un set di dati potrebbe contenere dati relativi a 100 anni, ma solo per il mese di luglio. L'utilizzo di questo set di dati per prevedere le precipitazioni a gennaio produrrebbe predizioni poco accurate. Al contrario, un set di dati potrebbe coprire solo alcuni anni, ma contenere ogni mese. Questo set di dati potrebbe produrre previsioni imprecise perché non contiene un numero sufficiente di anni per tenere conto della variabilità.
Verifica di aver compreso
Un set di dati può essere caratterizzato anche dal numero di elementi. Ad esempio, alcuni set di dati meteo potrebbero contenere centinaia di elementi, dalle immagini satellitari ai valori di copertura delle nuvole. Altri set di dati potrebbero contenere solo tre o quattro elementi, come umidità, pressione atmosferica e temperatura. I set di dati con più funzionalità possono aiutare un modello a scoprire pattern aggiuntivi e fare previsioni migliori. Tuttavia, i set di dati con più funzionalità non producono sempre modelli che fanno previsioni migliori perché alcune funzionalità potrebbero non avere alcuna relazione causale con l'etichetta.
Modello
Nell'apprendimento supervisionato, un modello è la raccolta complessa di numeri che definisce la relazione matematica da pattern di caratteristiche di input specifici a valori specifici delle etichette di output. Il modello li scopre durante l'addestramento.
Formazione
Prima che un modello supervisionato possa fare previsioni, deve essere addestrato. Per addestrare un modello, forniamo un set di dati con esempi etichettati. L'obiettivo del modello è trovare la soluzione migliore per prevedere le etichette dalle funzionalità. Il modello trova la soluzione migliore confrontando il suo valore previsto con il valore effettivo dell'etichetta. In base alla differenza tra i valori previsti e quelli effettivi, definita come perdita, il modello aggiorna gradualmente la sua soluzione. In altre parole, il modello apprende la relazione matematica tra le caratteristiche e l'etichetta in modo da poter fare le migliori previsioni sui dati non considerati.
Ad esempio, se il modello ha previsto 1.15 inches di pioggia, ma il valore effettivo era .75 inches, il modello modifica la sua soluzione in modo che la previsione sia più vicina a .75 inches. Dopo aver esaminato ogni esempio nel set di dati, in alcuni casi più volte, il modello arriva a una soluzione che genera le migliori previsioni, in media, per ciascuno degli esempi.
Di seguito viene mostrato l'addestramento di un modello:
Il modello prende un singolo esempio etichettato e fornisce una previsione.
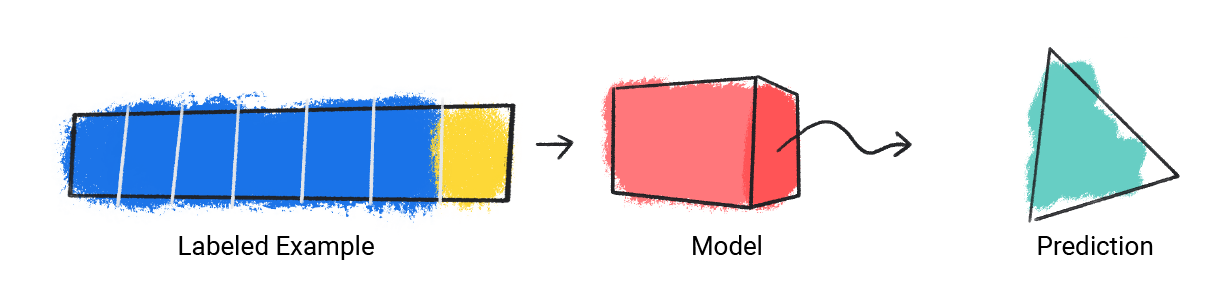
Figura 1. Un modello ML che fa una previsione da un esempio etichettato.
Il modello confronta il valore previsto con quello effettivo e aggiorna la soluzione.
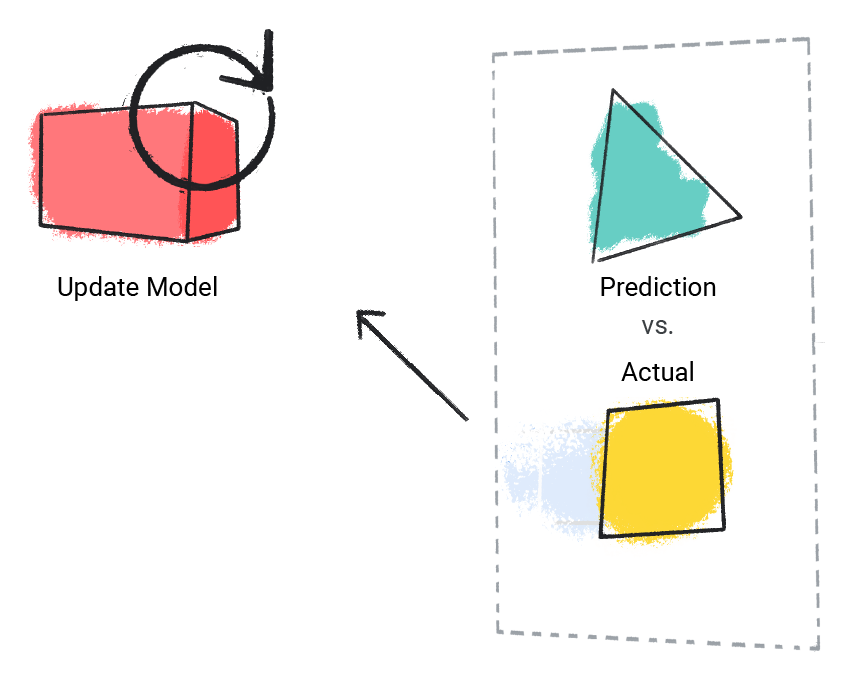
Figura 2. Un modello ML che aggiorna il valore previsto.
Il modello ripete questa procedura per ogni esempio etichettato nel set di dati.
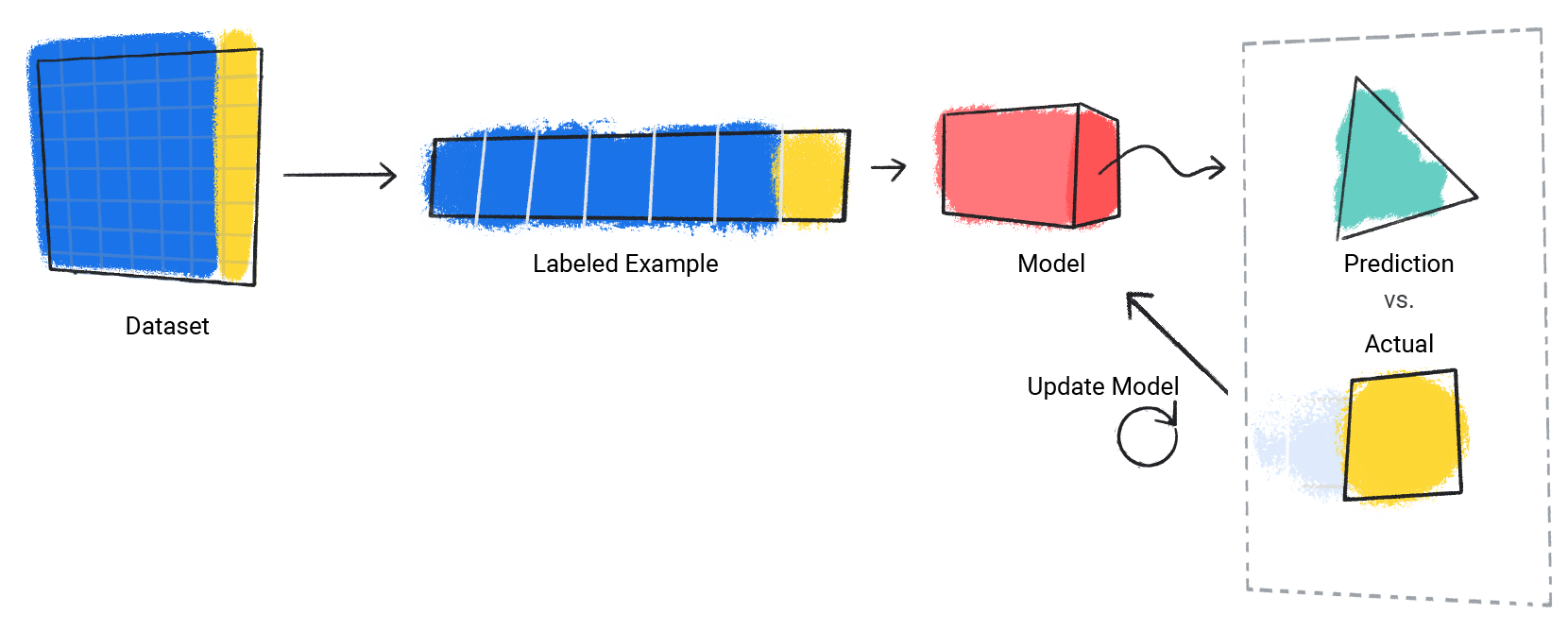
Figura 3. Un modello ML che aggiorna le sue previsioni per ogni esempio etichettato nel set di dati di addestramento.
In questo modo, il modello apprende gradualmente la relazione corretta tra le caratteristiche e l'etichetta. Questa comprensione graduale è anche il motivo per cui set di dati di grandi dimensioni e diversificati producono un modello migliore. Il modello ha visto più dati con un intervallo più ampio di valori e ha perfezionato la comprensione della relazione tra le caratteristiche e l'etichetta.
Durante l'addestramento, gli esperti di ML possono apportare piccoli aggiustamenti alle configurazioni e alle funzionalità utilizzate dal modello per fare previsioni. Ad esempio, alcune funzionalità hanno un potere predittivo maggiore rispetto ad altre. Pertanto, gli esperti di ML possono selezionare le funzionalità utilizzate dal modello durante l'addestramento. Ad esempio, supponiamo che un set di dati meteo contengatime_of_day come caratteristica. In questo
caso, un professionista dell'ML può aggiungere o rimuovere time_of_day durante l'addestramento per vedere
se il modello fa previsioni migliori con o senza.
Valutazione
Valutiamo un modello addestrato per determinare il livello di apprendimento. Quando valutiamo un modello, utilizziamo un set di dati etichettato, ma forniamo al modello solo le caratteristiche del set di dati. Poi confrontiamo le previsioni del modello con i valori veri dell'etichetta.
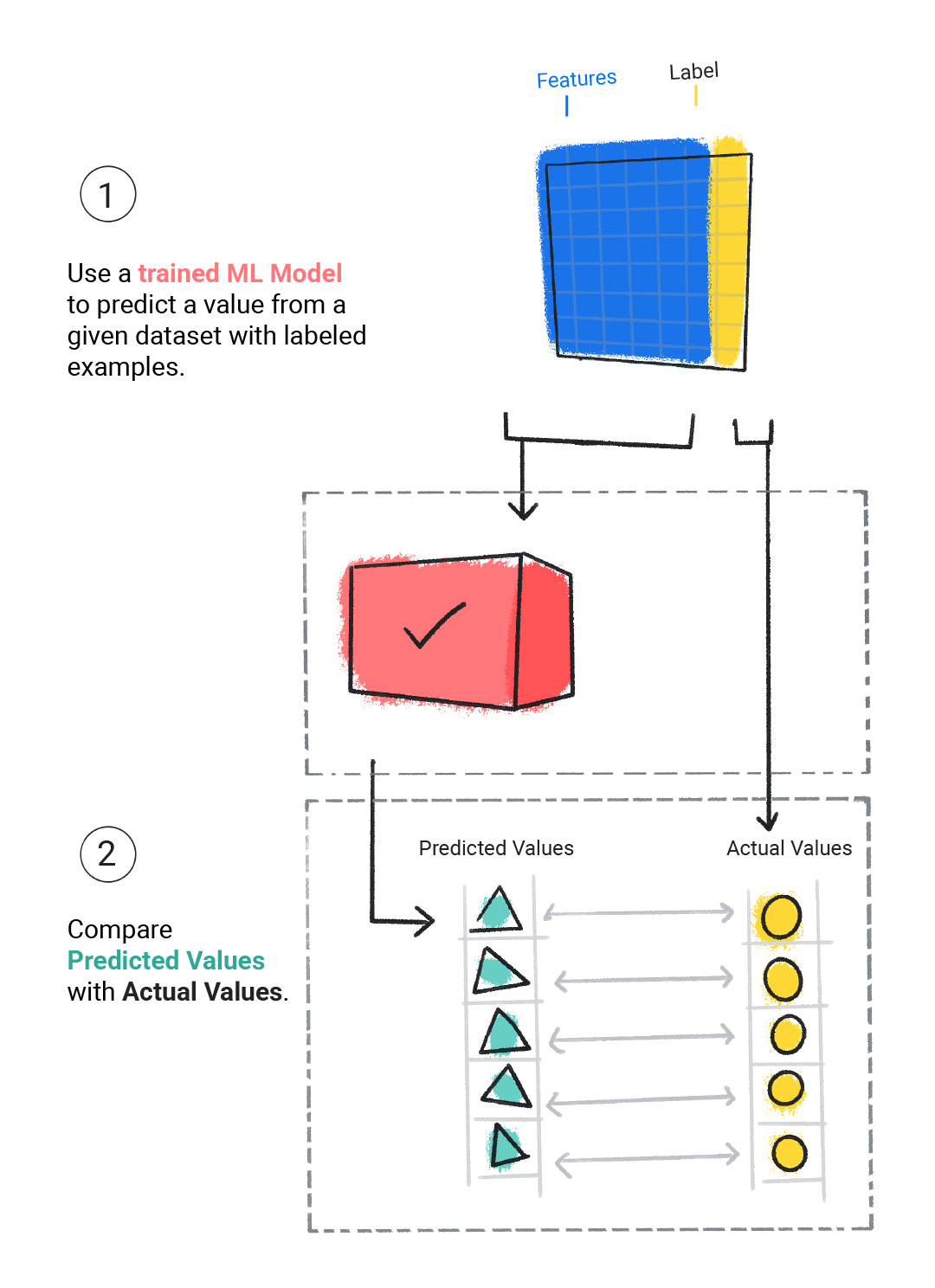
Figura 4. Valutare un modello ML confrontando le sue previsioni con i valori effettivi.
A seconda delle previsioni del modello, potremmo eseguire ulteriore addestramento e valutazione prima di eseguire il deployment del modello in un'applicazione reale.
Verifica di aver compreso
Inferenza
Una volta soddisfatti dei risultati della valutazione del modello, possiamo utilizzarlo per fare previsioni, chiamate inferenze, su esempi non etichettati. Nell'esempio dell'app meteo, forniremo al modello le condizioni meteorologiche attuali, come temperatura, pressione atmosferica e umidità relativa, e il modello predirrà la quantità di pioggia.