Le seguenti domande ti aiutano a consolidare la tua comprensione dei concetti di base di ML.
Potere predittivo
I modelli ML supervisionati vengono addestrati utilizzando set di dati con esempi etichettati. Il modello
impara a prevedere l'etichetta dalle caratteristiche. Tuttavia, non tutte le caratteristiche di
un set di dati hanno un potere predittivo. In alcuni casi, solo alcune caratteristiche fungono da
predittori dell'etichetta. Nel set di dati riportato di seguito, utilizza il prezzo come etichetta
e le colonne rimanenti come caratteristiche.

Quali tre caratteristiche ritieni siano i predittori più probabili
del prezzo di un'auto?
Marca_modello, anno, miglia.
La marca/il modello, l'anno e le miglia di un'auto sono probabilmente tra i
predittori più efficaci del suo prezzo.
Colore, altezza, marca_modello.
L'altezza e il colore di un'auto non sono predittori efficaci del prezzo di un'auto.
Miglia, cambio, marca_modello.
Il cambio non è un predittore principale del prezzo.
Dimensione_pneumatici, passo, anno.
La dimensione dei pneumatici e il passo non sono predittori efficaci del prezzo di un'auto.
Apprendimento supervisionato e non supervisionato
A seconda del problema, utilizzerai un approccio supervisionato o non supervisionato.
Ad esempio, se conosci in anticipo il valore o la categoria che vuoi prevedere,
utilizzerai l'apprendimento supervisionato. Tuttavia, se vuoi sapere se il tuo set di dati
contiene segmentazioni o raggruppamenti di esempi correlati, utilizzerai
l'apprendimento non supervisionato.
Supponi di avere un set di dati di utenti per un sito web di shopping online, e che esso
contenga le seguenti colonne:

Se vuoi capire i tipi di utenti che visitano il sito,
utilizzeresti l'apprendimento supervisionato o non supervisionato?
Apprendimento non supervisionato.
Poiché vogliamo che il modello raggruppi i clienti correlati,
utilizzeremo l'apprendimento non supervisionato. Dopo che il modello ha raggruppato gli utenti,
creeremo i nostri nomi per ogni cluster, ad esempio
"cercatori di sconti", "cacciatori di offerte", "surfisti", "fedeli"
e "vagabondi".
Apprendimento supervisionato perché sto cercando di prevedere a quale classe
un utente appartiene.
Nell'apprendimento supervisionato, il set di dati deve contenere l'etichetta che stai
cercando di prevedere. Nel set di dati non esiste un'etichetta che si riferisca a una
categoria di utenti.
Supponi di avere un set di dati sull'utilizzo di energia per le case con le seguenti colonne:
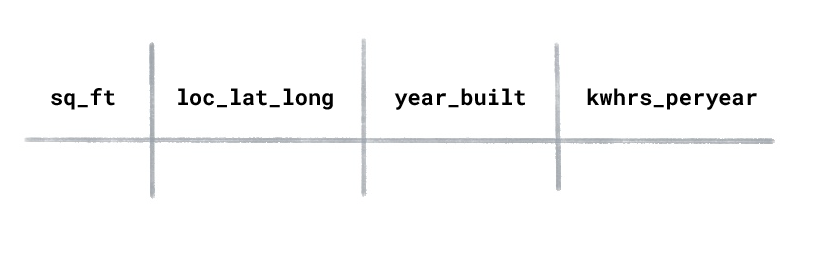
Quale tipo di ML utilizzeresti per prevedere i chilowattora utilizzati all'
anno per una casa di nuova costruzione?
Apprendimento supervisionato.
L'apprendimento supervisionato viene addestrato su esempi etichettati. In questo set di dati
"chilowattora utilizzati all'anno" sarebbe l'etichetta perché è il
valore che vuoi che il modello preveda. Le caratteristiche sarebbero
"metri quadrati", "località" e "anno di costruzione".
Apprendimento non supervisionato.
L'apprendimento non supervisionato utilizza esempi non etichettati. In questo esempio,
"chilowattora utilizzati all'anno" sarebbe l'etichetta perché è il
valore che vuoi che il modello preveda.
Supponi di avere un set di dati sui voli con le seguenti colonne:

Se vuoi prevedere il costo di un biglietto aereo, utilizzeresti la
regressione o la classificazione?
Regressione
L'output di un modello di regressione è un valore numerico.
Classificazione
L'output di un modello di classificazione è un valore discreto,
in genere una parola. In questo caso, il costo di un biglietto aereo è
un valore numerico.
In base al set di dati, potresti addestrare un modello di classificazione
per classificare il costo di un biglietto aereo come
"alto," "medio," o "basso"?
Sì, ma prima dovremmo convertire i valori numerici nella
airplane_ticket_cost colonna in valori categorici.
È possibile creare un modello di classificazione dal set di dati.
Dovresti fare qualcosa di simile a quanto segue:
- Trova il costo medio di un biglietto dall'aeroporto di partenza a
l'aeroporto di destinazione.
- Determina le soglie che costituirebbero "alto", "medio",
e "basso".
- Confronta il costo previsto con le soglie e restituisci la
categoria in cui rientra il valore.
No. Non è possibile creare un modello di classificazione. I valori
airplane_ticket_cost sono numerici, non categorici.
Con un po' di lavoro, potresti creare un modello di classificazione
model.
No. I modelli di classificazione prevedono solo due categorie, ad esempio
spam o not_spam. Questo modello dovrebbe prevedere
tre categorie.
I modelli di classificazione possono prevedere più categorie. Sono chiamati modelli di classificazione multiclasse.
Addestramento e valutazione
Dopo aver addestrato un modello, lo valutiamo utilizzando un set di dati con
esempi etichettati e confrontiamo il valore previsto del modello con il valore
effettivo dell'etichetta.
Seleziona le due risposte migliori alla domanda.
Se le previsioni del modello sono molto lontane, cosa potresti fare per migliorarle
?
Raddestra il modello, ma utilizza solo le caratteristiche che ritieni abbiano il
potere predittivo più efficace per l'etichetta.
Il riaddestramento del modello con meno caratteristiche, ma con un maggiore
potere predittivo, può produrre un modello che fa previsioni migliori.
Non puoi correggere un modello le cui previsioni sono molto lontane.
È possibile correggere un modello le cui previsioni sono errate. La maggior parte dei modelli
richiede più round di addestramento finché non fa
previsioni utili.
Raddestra il modello utilizzando un set di dati più grande e diversificato.
I modelli addestrati su set di dati con più esempi e una gamma più ampia di
valori possono produrre previsioni migliori perché il modello ha una soluzione generalizzata migliore per la relazione tra le caratteristiche e
l'etichetta.
Prova un approccio di addestramento diverso. Ad esempio, se hai utilizzato un
approccio supervisionato, prova un approccio non supervisionato.
Un approccio di addestramento diverso non produrrebbe previsioni migliori.
Ora è tutto pronto per fare il passo successivo nel tuo percorso di ML:
Machine Learning Crash Course. Se sei
pronto per un approccio pratico e approfondito per saperne di più su ML.
Problem Framing. Se stai cercando
un approccio collaudato per creare modelli ML ed evitare gli errori più comuni.
People + AI Guidebook. Se stai cercando indicazioni pratiche per la progettazione di prodotti AI incentrati sulle persone.