सुपरवाइज़्ड लर्निंग के टास्क अच्छी तरह से तय होते हैं और इन्हें कई तरह के मामलों में लागू किया जा सकता है. जैसे, स्पैम की पहचान करना या बारिश का अनुमान लगाना.
सुपरवाइज़्ड लर्निंग के बुनियादी कॉन्सेप्ट
सुपरवाइज़्ड मशीन लर्निंग इन मुख्य कॉन्सेप्ट पर आधारित है:
- Data
- मॉडल
- ट्रेनिंग
- मूल्यांकन हो रहा है
- अनुमान
Data
डेटा, मशीन लर्निंग की मुख्य ताकत है. डेटा, टेबल में सेव किए गए शब्दों और संख्याओं के तौर पर आता है. इसके अलावा, यह इमेज और ऑडियो फ़ाइलों में कैप्चर किए गए पिक्सल और वेवफ़ॉर्म की वैल्यू के तौर पर भी आता है. हम मिलते-जुलते डेटा को डेटासेट में सेव करते हैं. उदाहरण के लिए, हमारे पास इनका डेटासेट हो सकता है:
- बिल्लियों के चित्र
- घर की कीमतें
- मौसम की जानकारी
डेटासेट, अलग-अलग उदाहरणों से बने होते हैं. इनमें सुविधाएं और लेबल शामिल होते हैं. उदाहरण के लिए, स्प्रेडशीट में एक पंक्ति को सुविधाएं वे वैल्यू होती हैं जिनका इस्तेमाल, सुपरवाइज़्ड मॉडल, लेबल का अनुमान लगाने के लिए करता है. लेबल,"जवाब" या वह वैल्यू होती है जिसका अनुमान मॉडल को लगाना होता है. बारिश का अनुमान लगाने वाले मौसम मॉडल में, अक्षांश, देशांतर, तापमान, नमी, बादलों का दायरा, हवा की दिशा, और वायुमंडलीय दबाव जैसी सुविधाएं हो सकती हैं. लेबल बारिश की मात्रा होगा.
जिन उदाहरणों में सुविधाएं और लेबल, दोनों शामिल होते हैं उन्हें लेबल वाले उदाहरण कहा जाता है.
लेबल किए गए दो उदाहरण

इसके उलट, लेबल नहीं किए गए उदाहरणों में सुविधाएं तो होती हैं, लेकिन कोई लेबल नहीं होता. मॉडल बनाने के बाद, मॉडल सुविधाओं से लेबल का अनुमान लगाता है.
बिना लेबल वाले दो उदाहरण
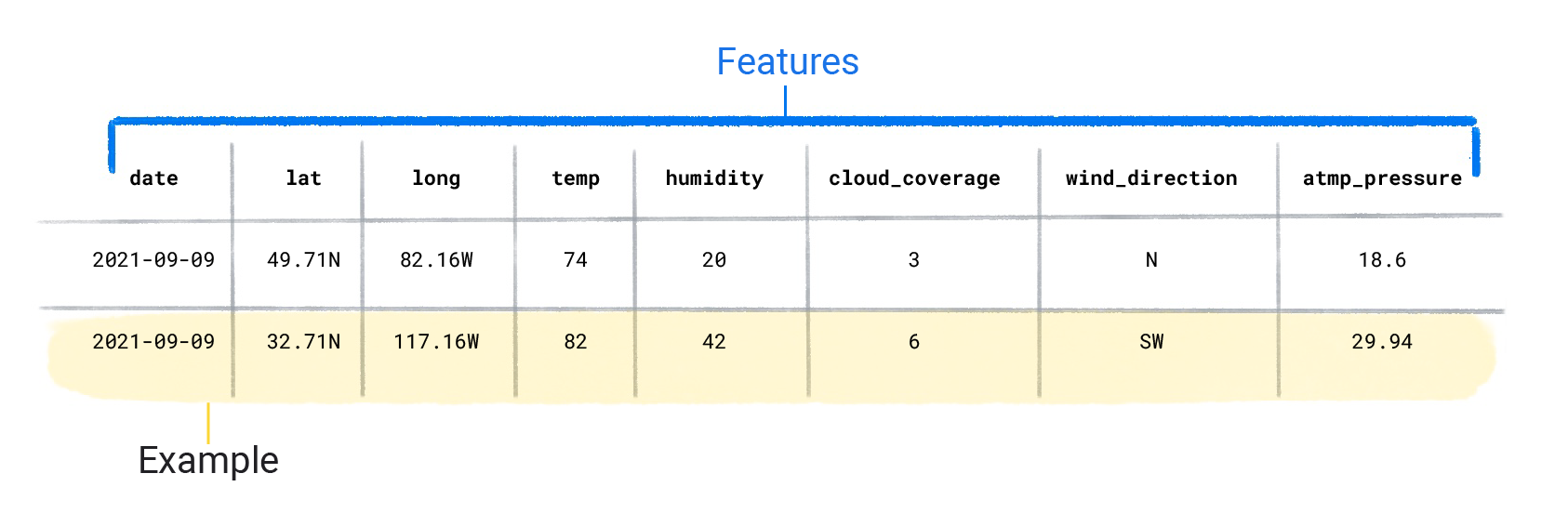
डेटासेट की विशेषताएं
डेटासेट का साइज़ और उसमें मौजूद डेटा की वैरायटी, उसके बारे में बताती है. साइज़ से उदाहरणों की संख्या का पता चलता है. 'विविधता' से पता चलता है कि उदाहरणों में कौनसी रेंज शामिल है. अच्छे डेटासेट बड़े और अलग-अलग तरह के होते हैं.
डेटासेट बड़े और अलग-अलग हो सकते हैं. इसके अलावा, वे बड़े और एक जैसे भी हो सकते हैं. इसके अलावा, वे छोटे और अलग-अलग भी हो सकते हैं. दूसरे शब्दों में, बड़े डेटासेट में अलग-अलग तरह के डेटा का होना ज़रूरी नहीं है. साथ ही, अलग-अलग तरह के डेटा वाले डेटासेट में ज़रूरत के मुताबिक उदाहरण नहीं मिल सकते.
उदाहरण के लिए, किसी डेटासेट में 100 साल का डेटा हो सकता है, लेकिन सिर्फ़ जुलाई महीने का. जनवरी में बारिश का अनुमान लगाने के लिए, इस डेटासेट का इस्तेमाल करने से, अनुमान खराब होंगे. इसके उलट, हो सकता है कि कोई डेटासेट सिर्फ़ कुछ साल का हो, लेकिन उसमें हर महीने का डेटा हो. इस डेटासेट से खराब अनुमान मिल सकते हैं, क्योंकि इसमें वैरिएबल के हिसाब से ज़रूरत के मुताबिक साल नहीं हैं.
देखें कि आपको विषय की कितनी समझ है
डेटासेट की विशेषताओं की संख्या से भी उसके बारे में पता चलता है. उदाहरण के लिए, मौसम के कुछ डेटासेट में सैकड़ों सुविधाएं हो सकती हैं. इनमें सैटलाइट इमेज से लेकर, बादल के कवरेज की वैल्यू तक शामिल हो सकती हैं. अन्य डेटासेट में सिर्फ़ तीन या चार सुविधाएं हो सकती हैं, जैसे कि आर्द्रता, वातावरण का दबाव, और तापमान. ज़्यादा सुविधाओं वाले डेटासेट से, मॉडल को अन्य पैटर्न खोजने और बेहतर अनुमान लगाने में मदद मिल सकती है. हालांकि, ज़्यादा सुविधाओं वाले डेटासेट से हमेशा बेहतर अनुमान लगाने वाले मॉडल नहीं बनते. ऐसा इसलिए, क्योंकि हो सकता है कि कुछ सुविधाओं का लेबल से कोई संबंध न हो.
मॉडल
सुपरवाइज़्ड लर्निंग में, मॉडल संख्याओं का एक जटिल कलेक्शन होता है. यह किसी खास इनपुट फ़ीचर पैटर्न से, किसी खास आउटपुट लेबल वैल्यू तक के गणितीय संबंध को तय करता है. मॉडल, ट्रेनिंग के दौरान इन पैटर्न का पता लगाता है.
ट्रेनिंग
सुपरवाइज़्ड मॉडल को अनुमान लगाने से पहले, उसे ट्रेनिंग देना ज़रूरी है. किसी मॉडल को ट्रेन करने के लिए, हम उसे लेबल किए गए उदाहरणों वाला डेटासेट देते हैं. मॉडल का लक्ष्य, सुविधाओं से लेबल का अनुमान लगाने के लिए सबसे अच्छा समाधान ढूंढना है. मॉडल, अपनी अनुमानित वैल्यू की तुलना लेबल की असल वैल्यू से करके सबसे अच्छा समाधान ढूंढता है. अनुमानित और असल वैल्यू के बीच के अंतर के आधार पर, मॉडल धीरे-धीरे अपना समाधान अपडेट करता है. इस अंतर को लॉस कहा जाता है. दूसरे शब्दों में, मॉडल, फ़ीचर और लेबल के बीच के गणितीय संबंध को समझता है, ताकि वह नया डेटा मिलने पर सबसे अच्छा अनुमान लगा सके.
उदाहरण के लिए, अगर मॉडल ने बारिश के लिए 1.15 inches का अनुमान लगाया, लेकिन असल वैल्यू .75 inches थी, तो मॉडल अपने समाधान में बदलाव करता है, ताकि उसका अनुमान .75 inches के करीब हो. मॉडल, डेटासेट में मौजूद हर उदाहरण को देखता है. कुछ मामलों में, वह हर उदाहरण को कई बार देखता है. इसके बाद, वह एक ऐसा समाधान निकालता है जो हर उदाहरण के लिए, औसतन सबसे अच्छी भविष्यवाणियां करता है.
यहां मॉडल को ट्रेनिंग देने का तरीका बताया गया है:
मॉडल, लेबल किए गए एक उदाहरण को लेता है और अनुमान देता है.
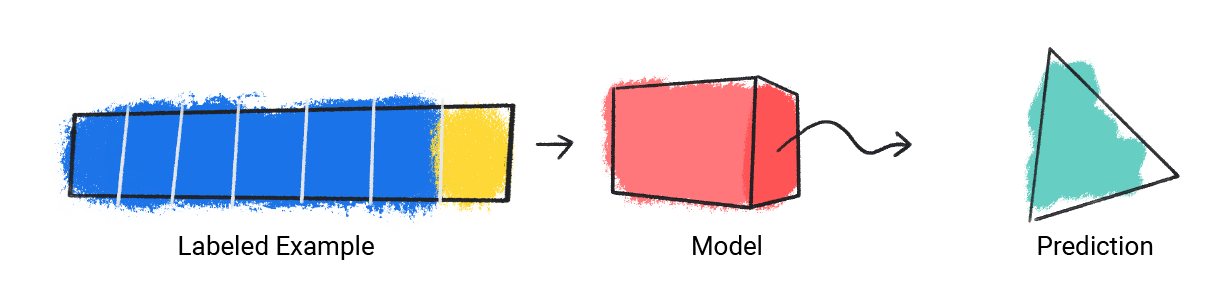
पहली इमेज. लेबल किए गए उदाहरण से अनुमान लगाने वाला एमएल मॉडल.
मॉडल, अनुमानित वैल्यू की तुलना असल वैल्यू से करता है और अपना समाधान अपडेट करता है.
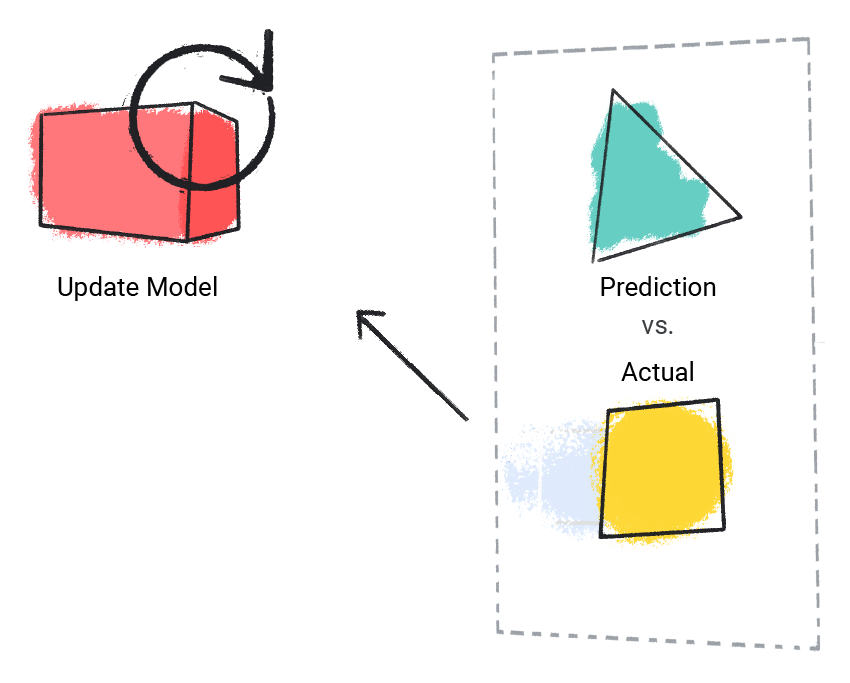
दूसरी इमेज. अनुमानित वैल्यू को अपडेट करने वाला एमएल मॉडल.
मॉडल, डेटासेट में मौजूद हर लेबल किए गए उदाहरण के लिए यह प्रोसेस दोहराता है.
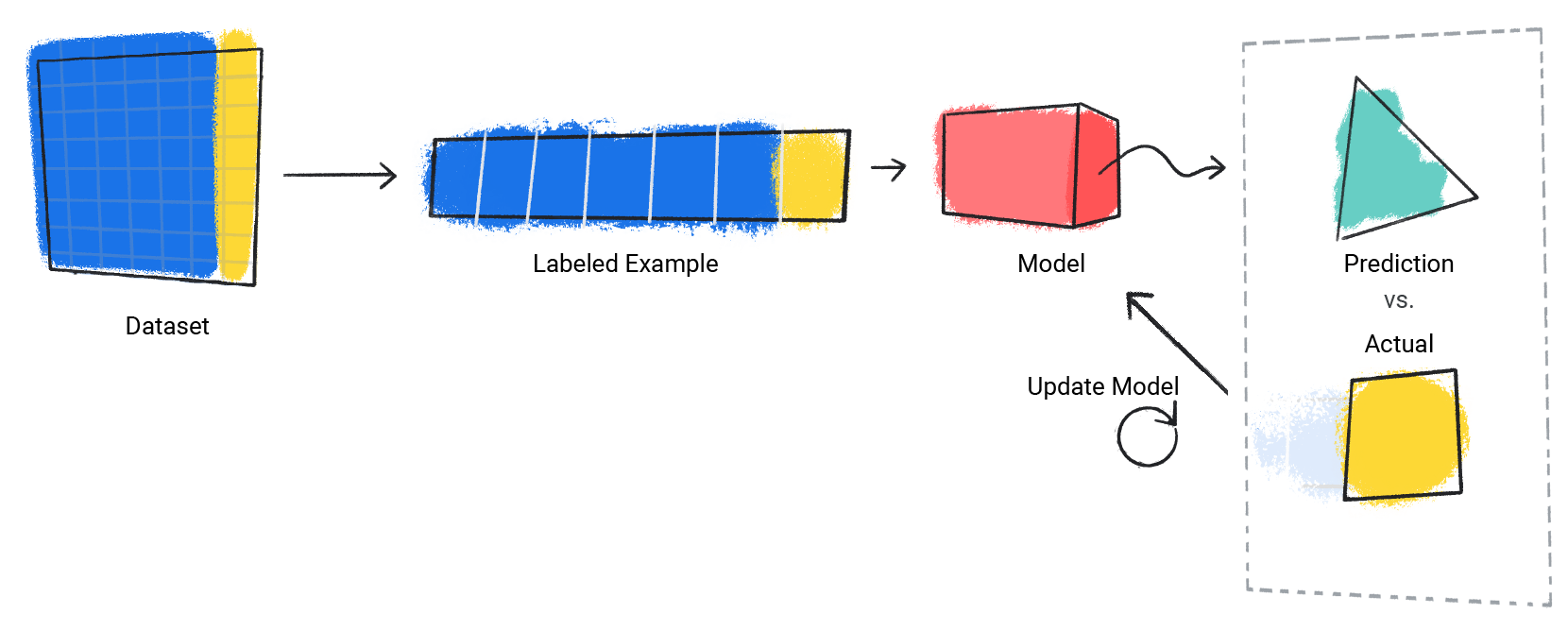
तीसरी इमेज. ट्रेनिंग डेटासेट में, लेबल किए गए हर उदाहरण के लिए, एमएल मॉडल अपने अनुमान अपडेट कर रहा है.
इस तरह, मॉडल धीरे-धीरे फ़ीचर और लेबल के बीच सही संबंध को समझता है. धीरे-धीरे समझने की इस प्रोसेस की वजह से ही बड़े और अलग-अलग तरह के डेटासेट से बेहतर मॉडल बनता है. मॉडल को वैल्यू की ज़्यादा रेंज वाला ज़्यादा डेटा मिला है. साथ ही, सुविधाओं और लेबल के बीच के संबंध को बेहतर तरीके से समझा है.
ट्रेनिंग के दौरान, मशीन लर्निंग के विशेषज्ञ, कॉन्फ़िगरेशन और उन सुविधाओं में छोटे बदलाव कर सकते हैं जिनका इस्तेमाल मॉडल, अनुमान लगाने के लिए करता है. उदाहरण के लिए, कुछ सुविधाओं में, दूसरों की तुलना में अनुमान लगाने की क्षमता ज़्यादा होती है. इसलिए, एमएल विशेषज्ञ यह चुन सकते हैं कि मॉडल, ट्रेनिंग के दौरान किन सुविधाओं का इस्तेमाल करे. उदाहरण के लिए, मान लें कि मौसम के डेटासेट में time_of_day एक सुविधा के तौर पर मौजूद है. इस मामले में, मशीन लर्निंग का इस्तेमाल करने वाला कोई व्यक्ति, ट्रेनिंग के दौरान time_of_day को जोड़ या हटा सकता है. इससे यह पता चलता है कि मॉडल, इस एट्रिब्यूट के साथ या इसके बिना बेहतर अनुमान लगाता है या नहीं.
मूल्यांकन हो रहा है
हम ट्रेन किए गए मॉडल का आकलन करके यह तय करते हैं कि उसने कितना अच्छा सीखा है. किसी मॉडल का आकलन करते समय, हम लेबल किए गए डेटासेट का इस्तेमाल करते हैं. हालांकि, हम मॉडल को सिर्फ़ डेटासेट की सुविधाएं देते हैं. इसके बाद, हम मॉडल के अनुमान की तुलना लेबल की सही वैल्यू से करते हैं.
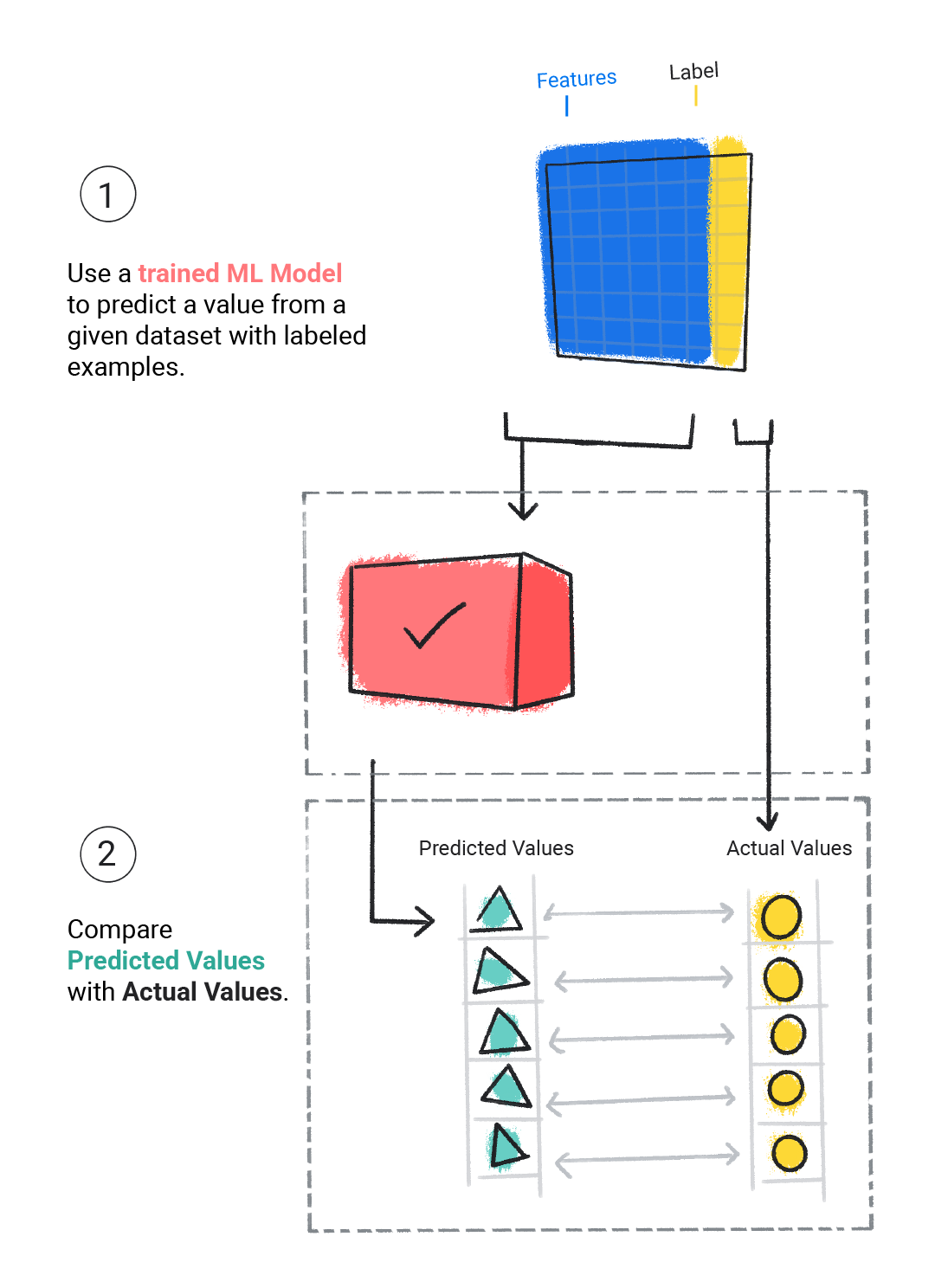
चौथी इमेज. एमएल मॉडल के अनुमानों की तुलना असल वैल्यू से करके, उसका आकलन करना.
मॉडल के अनुमानों के आधार पर, हम असल दुनिया के किसी ऐप्लिकेशन में मॉडल को डिप्लॉय करने से पहले, ज़्यादा ट्रेनिंग और आकलन कर सकते हैं.
देखें कि आपको विषय की कितनी समझ है
अनुमान
मॉडल का आकलन करने के बाद, हम बिना लेबल वाले उदाहरणों के लिए, अनुमान लगाने के लिए मॉडल का इस्तेमाल कर सकते हैं. मौसम के ऐप्लिकेशन के उदाहरण में, हम मॉडल को मौसम की मौजूदा स्थितियों की जानकारी देंगे. जैसे, तापमान, वातावरण का दबाव, और सापेक्ष आर्द्रता. इससे, मॉडल बारिश की मात्रा का अनुमान लगाएगा.