Die Aufgaben des Supervised Learning sind klar definiert und können auf eine Vielzahl von Szenarien angewendet werden, z. B. auf die Erkennung von Spam oder die Vorhersage von Niederschlag.
Grundlegende Konzepte des überwachten Lernens
Supervisiertes maschinelles Lernen basiert auf den folgenden Kernkonzepten:
- Daten
- Modell
- Training
- Wird bewertet
- Inferenz
Daten
Daten sind die treibende Kraft des maschinellen Lernens. Daten können in Form von Wörtern und Zahlen in Tabellen oder als Pixelwerte und Wellenformen in Bildern und Audiodateien vorliegen. Wir speichern zugehörige Daten in Datensätzen. Angenommen, wir haben einen Datensatz mit den folgenden Daten:
- Fotos von Katzen
- Wohnraumkosten
- Wetterinformationen
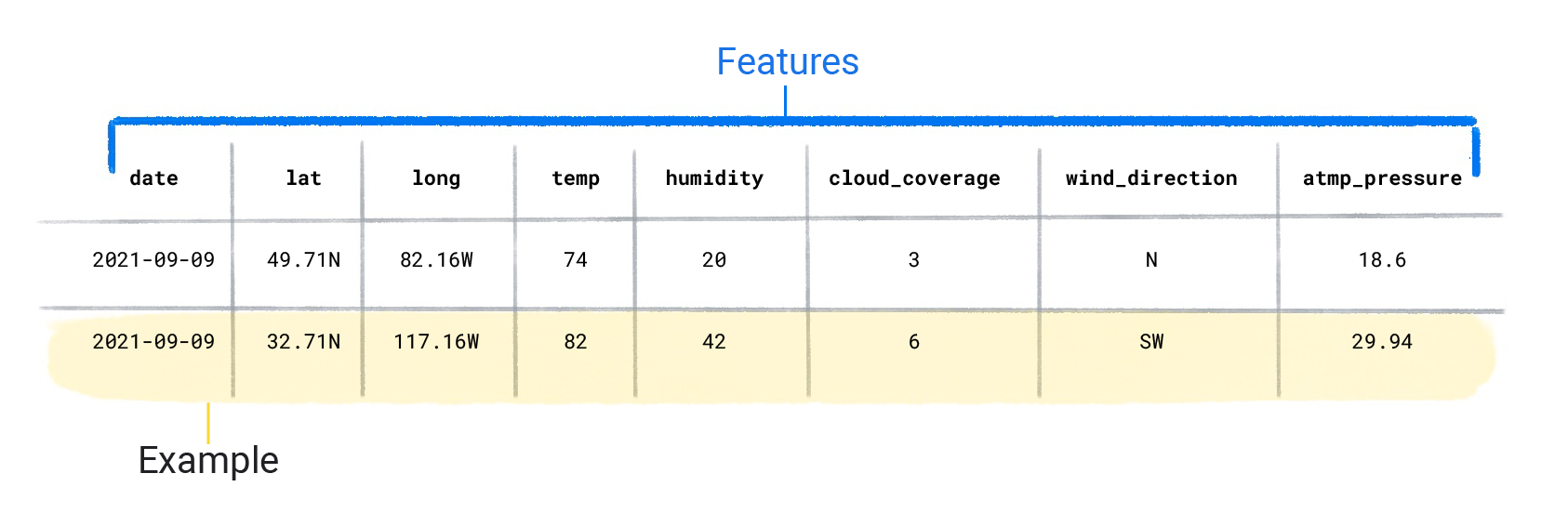
Datasets bestehen aus einzelnen Beispielen, die Features und ein Label enthalten. Sie können sich ein Beispiel als analog zu einer einzelnen Zeile in einer Tabelle vorstellen. Merkmale sind die Werte, mit denen ein überwachtes Modell das Label vorhersagt. Das Label ist die „Antwort“ oder der Wert, den das Modell vorhersagen soll. In einem Wettermodell, das Niederschlag vorhersagt, könnten die Merkmale Breitengrad, Längengrad, Temperatur, Luftfeuchtigkeit, Wolkenbedeckung, Windrichtung und Luftdruck sein. Das Label wäre Niederschlagsmenge.
Beispiele, die sowohl Features als auch ein Label enthalten, werden als beschriftete Beispiele bezeichnet.
Zwei Beispiele mit Labels

Beispiele ohne Labels enthalten dagegen Funktionen, aber kein Label. Nachdem Sie ein Modell erstellt haben, wird das Label anhand der Features vorhergesagt.
Zwei Beispiele ohne Labels
Dataset-Eigenschaften
Ein Datensatz zeichnet sich durch seine Größe und Vielfalt aus. „Größe“ gibt die Anzahl der Beispiele an. Vielfalt gibt an, welchen Bereich diese Beispiele abdecken. Gute Datensätze sind sowohl groß als auch sehr vielfältig.
Datensätze können groß und vielfältig, groß aber nicht vielfältig oder klein aber sehr vielfältig sein. Mit anderen Worten: Ein großer Datensatz ist keine Garantie für ausreichende Vielfalt und ein sehr vielfältiger Datensatz ist keine Garantie für ausreichende Beispiele.
Ein Datensatz kann beispielsweise Daten aus 100 Jahren enthalten, aber nur für den Monat Juli. Wenn Sie mit diesem Datensatz den Niederschlag im Januar vorhersagen, sind die Ergebnisse nicht sehr aussagekräftig. Umgekehrt kann ein Datensatz nur wenige Jahre umfassen, aber jeden Monat enthalten. Mit diesem Datensatz können möglicherweise keine guten Vorhersagen getroffen werden, da er nicht genügend Jahre enthält, um die Variabilität zu berücksichtigen.
Wissen testen
Ein Datensatz kann auch durch die Anzahl seiner Features gekennzeichnet werden. Einige Wetterdatensätze können beispielsweise Hunderte von Elementen enthalten, von Satellitenbildern bis hin zu Werten für die Wolkenbedeckung. Andere Datasets enthalten möglicherweise nur drei oder vier Merkmale, z. B. Luftfeuchtigkeit, Luftdruck und Temperatur. Mit Datensätzen mit mehr Funktionen kann ein Modell zusätzliche Muster erkennen und bessere Vorhersagen treffen. Datasets mit mehr Features führen jedoch nicht immer zu Modellen, die bessere Vorhersagen treffen, da einige Features möglicherweise keinen kausalen Zusammenhang mit dem Label haben.
Modell
Beim überwachten Lernen ist ein Modell die komplexe Sammlung von Zahlen, die die mathematische Beziehung zwischen bestimmten Eingabemerkmalen und bestimmten Ausgabelabelwerten definieren. Das Modell erkennt diese Muster durch Training.
Training
Bevor ein Modell mit beaufsichtigtem Lernen Vorhersagen treffen kann, muss es trainiert werden. Zum Trainieren eines Modells geben wir ihm ein Dataset mit gekennzeichneten Beispielen. Ziel des Modells ist es, die beste Lösung für die Vorhersage der Labels anhand der Merkmale zu finden. Das Modell findet die beste Lösung, indem es den vorhergesagten Wert mit dem tatsächlichen Wert des Labels vergleicht. Basierend auf der Differenz zwischen den prognostizierten und den tatsächlichen Werten, die als Verlust definiert ist, aktualisiert das Modell seine Lösung nach und nach. Mit anderen Worten: Das Modell lernt die mathematische Beziehung zwischen den Features und dem Label, damit es die besten Vorhersagen für nicht beobachtete Daten treffen kann.
Wenn das Modell beispielsweise 1.15 inches mm Regen vorhergesagt hat, der tatsächliche Wert aber .75 inches mm war, ändert das Modell seine Lösung so, dass die Vorhersage näher an .75 inches mm liegt. Nachdem das Modell jedes Beispiel im Datensatz betrachtet hat – in einigen Fällen mehrmals –, wird eine Lösung gefunden, mit der im Durchschnitt die besten Vorhersagen für jedes der Beispiele getroffen werden.
Im Folgenden wird das Training eines Modells veranschaulicht:
Das Modell nimmt ein einzelnes Beispiel mit Label als Eingabe und liefert eine Vorhersage.
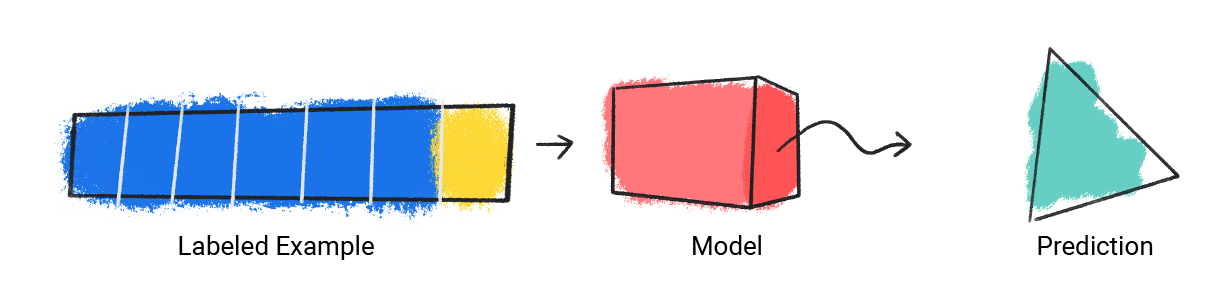
Abbildung 1. Ein ML-Modell, das eine Vorhersage anhand eines gekennzeichneten Beispiels trifft.
Das Modell vergleicht den vorhergesagten Wert mit dem tatsächlichen Wert und aktualisiert die Lösung.
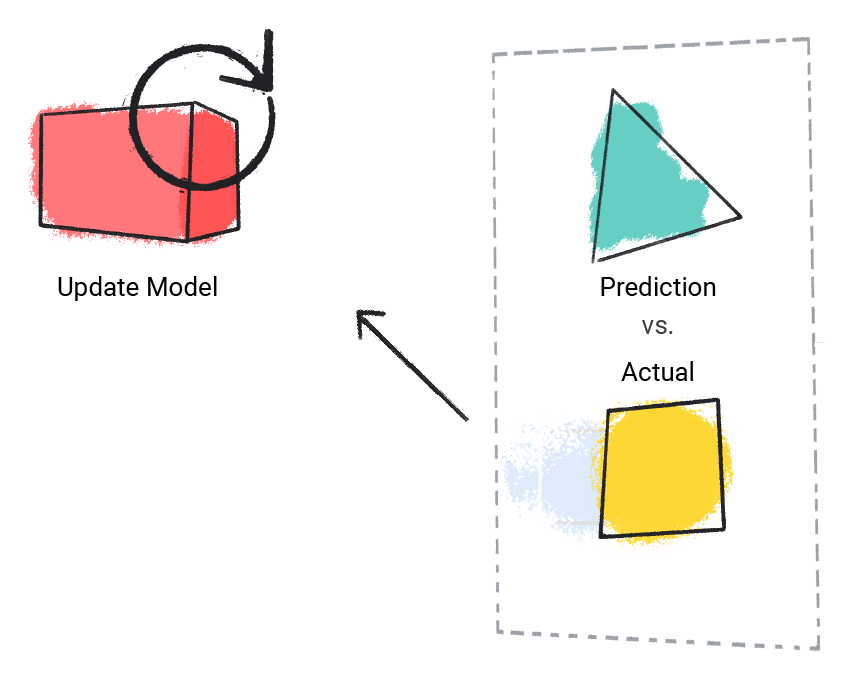
Abbildung 2. Ein ML-Modell aktualisiert seinen vorhergesagten Wert.
Das Modell wiederholt diesen Vorgang für jedes beschriftete Beispiel im Dataset.
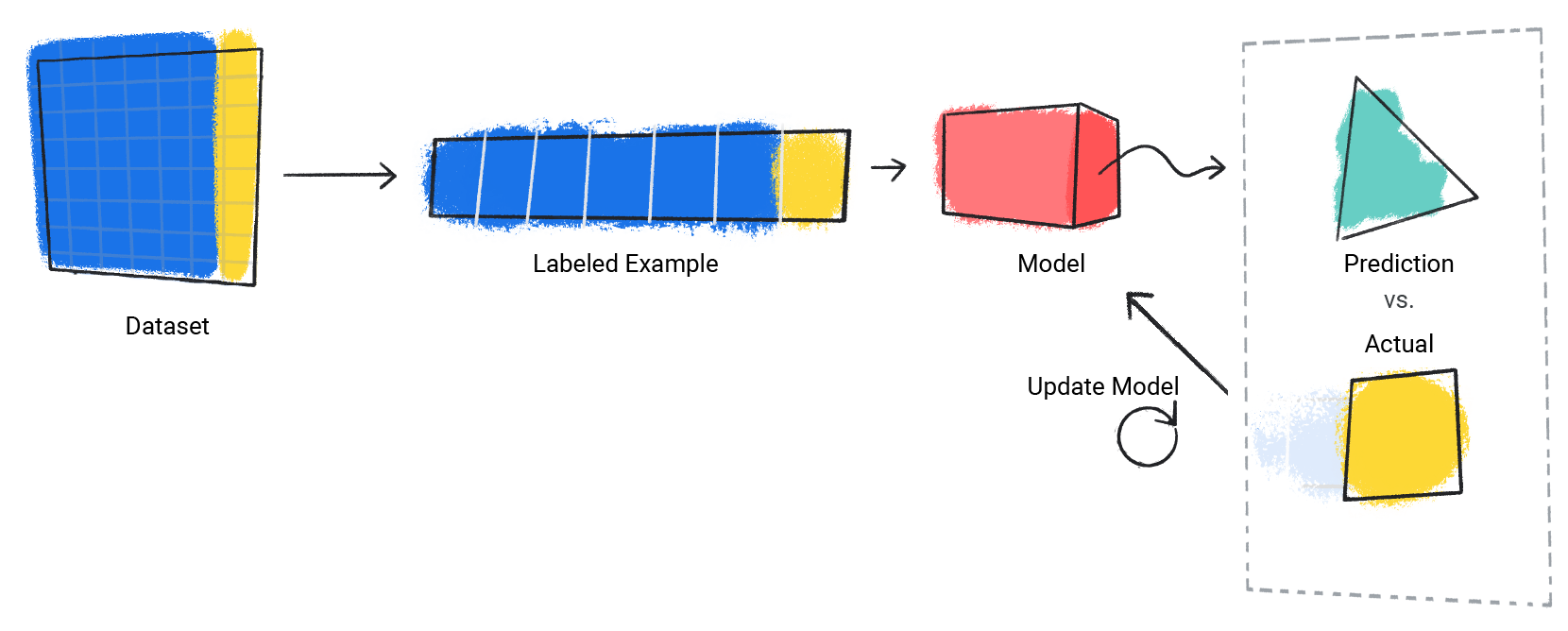
Abbildung 3. Ein ML-Modell, das seine Vorhersagen für jedes Beispiel mit Label im Trainingsdatensatz aktualisiert.
So lernt das Modell nach und nach die richtige Beziehung zwischen den Merkmalen und dem Label. Aus diesem Grund führen große und vielfältige Datensätze auch zu einem besseren Modell. Das Modell hat mehr Daten mit einem breiteren Wertebereich gesehen und die Beziehung zwischen den Features und dem Label optimiert.
Während des Trainings können ML-Experten die Konfigurationen und Funktionen, die das Modell für Vorhersagen verwendet, geringfügig anpassen. Beispielsweise haben bestimmte Merkmale eine höhere Vorhersagekraft als andere. Daher können ML-Experten auswählen, welche Funktionen das Modell während des Trainings verwendet. Angenommen, ein Wetter-Dataset enthält time_of_day als Feature. In diesem Fall kann ein ML-Experte time_of_day während des Trainings hinzufügen oder entfernen, um zu sehen, ob das Modell mit oder ohne time_of_day bessere Vorhersagen macht.
Wird bewertet
Wir bewerten ein trainiertes Modell, um festzustellen, wie gut es gelernt hat. Bei der Bewertung eines Modells verwenden wir ein beschriftetes Dataset, geben dem Modell aber nur die Merkmale des Datasets. Anschließend vergleichen wir die Vorhersagen des Modells mit den tatsächlichen Werten des Labels.
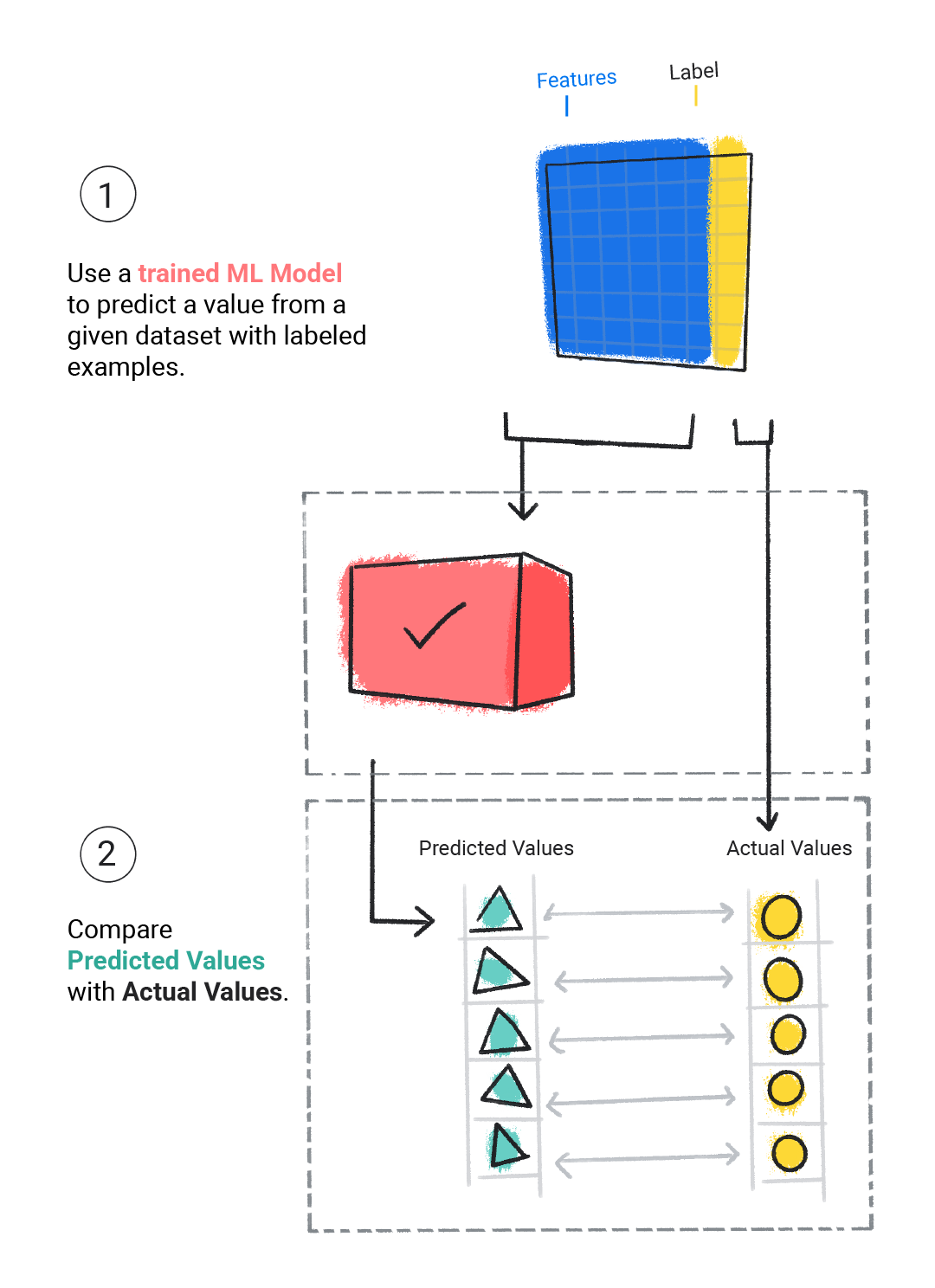
Abbildung 4. Ein ML-Modell wird bewertet, indem seine Vorhersagen mit den tatsächlichen Werten verglichen werden.
Je nach den Vorhersagen des Modells führen wir möglicherweise weitere Trainings- und Bewertungsschritte durch, bevor wir das Modell in einer realen Anwendung bereitstellen.
Wissen testen
Inferenz
Sobald wir mit den Ergebnissen der Modellbewertung zufrieden sind, können wir mit dem Modell Vorhersagen (Inferenzen) für nicht beschriftete Beispiele treffen. Im Beispiel der Wetter-App würden wir dem Modell die aktuellen Wetterbedingungen wie Temperatur, Luftdruck und relative Luftfeuchtigkeit geben und es würde die Regenmenge vorhersagen.