এই বিভাগে, আমরা আমাদের মডেল তৈরি, প্রশিক্ষণ এবং মূল্যায়নের দিকে কাজ করব। ধাপ 3 এ, আমরা আমাদের S/W অনুপাত ব্যবহার করে একটি n-গ্রাম মডেল বা সিকোয়েন্স মডেল ব্যবহার করতে বেছে নিয়েছি। এখন, আমাদের শ্রেণীবিভাগ অ্যালগরিদম লিখতে এবং এটি প্রশিক্ষণের সময় এসেছে। আমরা এর জন্য tf.keras API এর সাথে TensorFlow ব্যবহার করব।
কেরাসের সাথে মেশিন লার্নিং মডেলগুলি তৈরি করা হল একত্রে স্তরগুলি একত্রিত করা, ডেটা-প্রসেসিং বিল্ডিং ব্লক, অনেকটা যেমন আমরা লেগো ইটগুলিকে একত্রিত করব। এই স্তরগুলি আমাদের ইনপুটটিতে আমরা যে রূপান্তর করতে চাই তার ক্রমটি নির্দিষ্ট করতে দেয়। যেহেতু আমাদের শেখার অ্যালগরিদম একটি একক টেক্সট ইনপুট নেয় এবং একটি একক শ্রেণিবিন্যাস আউটপুট করে, আমরা সিকোয়েন্সিয়াল মডেল API ব্যবহার করে স্তরগুলির একটি রৈখিক স্ট্যাক তৈরি করতে পারি।
চিত্র 9: স্তরগুলির রৈখিক স্ট্যাক
ইনপুট স্তর এবং মধ্যবর্তী স্তরগুলি ভিন্নভাবে নির্মিত হবে, আমরা একটি এন-গ্রাম বা একটি সিকোয়েন্স মডেল তৈরি করছি কিনা তার উপর নির্ভর করে। কিন্তু মডেলের ধরন নির্বিশেষে, প্রদত্ত সমস্যার জন্য শেষ স্তরটি একই হবে।
শেষ স্তর নির্মাণ
যখন আমাদের শুধুমাত্র 2টি ক্লাস (বাইনারী শ্রেণীবিভাগ) থাকে, তখন আমাদের মডেলের একটি একক সম্ভাব্যতা স্কোর আউটপুট করা উচিত। উদাহরণস্বরূপ, প্রদত্ত ইনপুট নমুনার জন্য 0.2 আউটপুট করার অর্থ হল "20% আত্মবিশ্বাস যে এই নমুনাটি প্রথম শ্রেণীতে (শ্রেণী 1), 80% যে এটি দ্বিতীয় শ্রেণীর (শ্রেণী 0)। এই ধরনের সম্ভাব্যতা স্কোর আউটপুট করতে, শেষ স্তরের সক্রিয়করণ ফাংশনটি একটি সিগমায়েড ফাংশন হওয়া উচিত এবং মডেলটিকে প্রশিক্ষণের জন্য ব্যবহৃত ক্ষতি ফাংশনটি বাইনারি ক্রস-এনট্রপি হওয়া উচিত। ( চিত্র 10 , বাম দেখুন)।
যখন 2টির বেশি ক্লাস (মাল্টি-ক্লাস শ্রেণীবিভাগ) থাকে, তখন আমাদের মডেলটি প্রতি ক্লাসে একটি সম্ভাব্যতা স্কোর আউটপুট করা উচিত। এই স্কোরগুলির যোগফল 1 হওয়া উচিত। উদাহরণস্বরূপ, আউটপুট {0: 0.2, 1: 0.7, 2: 0.1} মানে "20% আত্মবিশ্বাস যে এই নমুনাটি 0 শ্রেণীতে রয়েছে, 70% যে এটি ক্লাস 1 এবং 10 এ রয়েছে % যে এটা ক্লাস 2 তে পড়ে।" এই স্কোরগুলি আউটপুট করার জন্য, শেষ স্তরের সক্রিয়করণ ফাংশনটি সফ্টম্যাক্স হওয়া উচিত এবং মডেলটিকে প্রশিক্ষণের জন্য ব্যবহৃত ক্ষতি ফাংশনটি শ্রেণীবদ্ধ ক্রস-এনট্রপি হওয়া উচিত। ( চিত্র 10 , ডানদিকে দেখুন)।
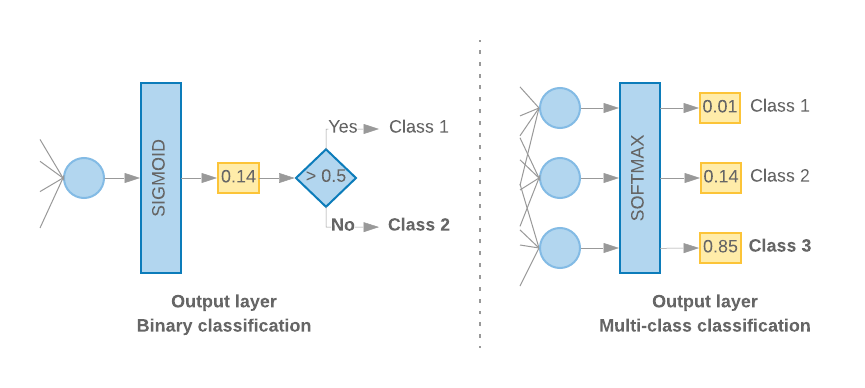
চিত্র 10: শেষ স্তর
নিম্নলিখিত কোডটি এমন একটি ফাংশনকে সংজ্ঞায়িত করে যা ক্লাসের সংখ্যাকে ইনপুট হিসাবে গ্রহণ করে এবং যথাযথ সংখ্যক স্তর ইউনিট (বাইনারী শ্রেণীবিভাগের জন্য 1 ইউনিট; অন্যথায় প্রতিটি শ্রেণীর জন্য 1 ইউনিট) এবং উপযুক্ত অ্যাক্টিভেশন ফাংশন আউটপুট করে:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
নিম্নলিখিত দুটি বিভাগ n-গ্রাম মডেল এবং সিকোয়েন্স মডেলের জন্য অবশিষ্ট মডেল স্তর তৈরির মধ্য দিয়ে চলে।
যখন S/W অনুপাত ছোট হয়, তখন আমরা দেখেছি যে n-গ্রাম মডেলগুলি সিকোয়েন্স মডেলের চেয়ে ভাল পারফর্ম করে। যখন অনেক ছোট, ঘন ভেক্টর থাকে তখন সিকোয়েন্স মডেল ভালো হয়। এর কারণ হল এম্বেডিং সম্পর্কগুলি ঘন স্থানে শেখা হয়, এবং এটি অনেক নমুনার চেয়ে ভাল হয়।
n-গ্রাম মডেল তৈরি করুন [বিকল্প A]
আমরা এমন মডেলগুলিকে উল্লেখ করি যেগুলি টোকেনগুলিকে স্বাধীনভাবে প্রক্রিয়া করে (একাউন্টে ওয়ার্ড অর্ডার না নিয়ে) এন-গ্রাম মডেল হিসাবে। সরল মাল্টি-লেয়ার পারসেপ্টরন ( লজিস্টিক রিগ্রেশন গ্রেডিয়েন্ট বুস্টিং মেশিন এবং সমর্থন ভেক্টর মেশিন মডেল সহ) এই বিভাগের অধীনে পড়ে; তারা টেক্সট অর্ডার সম্পর্কে কোনো তথ্য ব্যবহার করতে পারে না।
আমরা উপরে উল্লিখিত কিছু এন-গ্রাম মডেলের কর্মক্ষমতা তুলনা করেছি এবং লক্ষ্য করেছি যে মাল্টি-লেয়ার পারসেপ্টরন (এমএলপি) সাধারণত অন্যান্য বিকল্পের চেয়ে ভাল পারফর্ম করে । এমএলপিগুলি সংজ্ঞায়িত করা এবং বোঝার জন্য সহজ, ভাল নির্ভুলতা প্রদান করে এবং তুলনামূলকভাবে সামান্য গণনার প্রয়োজন হয়।
নিম্নলিখিত কোডটি tf.keras-এ একটি দ্বি-স্তর MLP মডেলকে সংজ্ঞায়িত করে, প্রশিক্ষণের নমুনাগুলিতে অতিরিক্ত ফিটিং প্রতিরোধ করার জন্য নিয়মিতকরণের জন্য কয়েকটি ড্রপআউট স্তর যুক্ত করে।
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
সিকোয়েন্স মডেল তৈরি করুন [বিকল্প B]
আমরা এমন মডেলগুলিকে উল্লেখ করি যেগুলি সিকোয়েন্স মডেল হিসাবে টোকেনের সংলগ্নতা থেকে শিখতে পারে। এর মধ্যে রয়েছে CNN এবং RNN ক্লাসের মডেল। এই মডেলগুলির জন্য সিকোয়েন্স ভেক্টর হিসাবে ডেটা প্রাক-প্রসেস করা হয়।
সিকোয়েন্স মডেলে সাধারণত অনেক বেশি সংখ্যক পরামিতি শিখতে হয়। এই মডেলগুলির প্রথম স্তরটি একটি এমবেডিং স্তর, যা একটি ঘন ভেক্টর স্থানের মধ্যে শব্দগুলির মধ্যে সম্পর্ক শিখে। শব্দ সম্পর্ক শেখা অনেক নমুনা থেকে ভাল কাজ করে.
একটি প্রদত্ত ডেটাসেটের শব্দগুলি সম্ভবত সেই ডেটাসেটের জন্য অনন্য নয়। এইভাবে আমরা অন্যান্য ডেটাসেট(গুলি) ব্যবহার করে আমাদের ডেটাসেটের শব্দগুলির মধ্যে সম্পর্ক শিখতে পারি। এটি করার জন্য, আমরা আমাদের এমবেডিং স্তরে অন্য ডেটাসেট থেকে শেখা একটি এমবেডিং স্থানান্তর করতে পারি। এই এমবেডিংগুলিকে প্রাক-প্রশিক্ষিত এমবেডিং হিসাবে উল্লেখ করা হয়। একটি প্রাক-প্রশিক্ষিত এম্বেডিং ব্যবহার করা মডেলটিকে শেখার প্রক্রিয়ায় একটি প্রধান সূচনা দেয়।
এখানে প্রাক-প্রশিক্ষিত এম্বেডিং উপলব্ধ রয়েছে যেগুলি বড় কর্পোরা, যেমন গ্লোভ ব্যবহার করে প্রশিক্ষিত হয়েছে। GloVe একাধিক কর্পোরাতে (প্রাথমিকভাবে উইকিপিডিয়া) প্রশিক্ষণপ্রাপ্ত হয়েছে। আমরা গ্লোভ এম্বেডিংয়ের একটি সংস্করণ ব্যবহার করে আমাদের সিকোয়েন্স মডেলগুলিকে প্রশিক্ষণ দিয়ে পরীক্ষা করেছি এবং লক্ষ্য করেছি যে যদি আমরা প্রাক-প্রশিক্ষিত এমবেডিংয়ের ওজন হিমায়িত করি এবং কেবলমাত্র বাকি নেটওয়ার্ককে প্রশিক্ষিত করি তবে মডেলগুলি ভাল পারফর্ম করে না। এটি হতে পারে কারণ যে প্রেক্ষাপটে এমবেডিং স্তরটি প্রশিক্ষিত হয়েছিল তা আমরা যে প্রেক্ষাপটে এটি ব্যবহার করছি তার থেকে আলাদা হতে পারে৷
উইকিপিডিয়া ডেটাতে প্রশিক্ষিত GloVe এম্বেডিংগুলি আমাদের IMDb ডেটাসেটের ভাষার প্যাটার্নগুলির সাথে সারিবদ্ধ নাও হতে পারে। অনুমান করা সম্পর্কগুলির কিছু আপডেটের প্রয়োজন হতে পারে—অর্থাৎ, এমবেডিং ওজনের প্রাসঙ্গিক টিউনিংয়ের প্রয়োজন হতে পারে। আমরা এটি দুটি পর্যায়ে করি:
প্রথম দৌড়ে, এমবেডিং স্তরের ওজন হিমায়িত করে, আমরা বাকি নেটওয়ার্ককে শিখতে দিই। এই দৌড়ের শেষে, মডেলের ওজনগুলি এমন একটি অবস্থায় পৌঁছে যা তাদের অপ্রচলিত মানগুলির চেয়ে অনেক ভাল। দ্বিতীয় রানের জন্য, আমরা নেটওয়ার্কের সমস্ত ওজনে সূক্ষ্ম সমন্বয় করে এমবেডিং স্তরটিকেও শেখার অনুমতি দিই। আমরা এই প্রক্রিয়াটিকে একটি সূক্ষ্ম-টিউনেড এম্বেডিং ব্যবহার হিসাবে উল্লেখ করি।
সূক্ষ্ম-টিউন করা এম্বেডিংগুলি আরও ভাল নির্ভুলতা দেয়। যাইহোক, এটি নেটওয়ার্ককে প্রশিক্ষণের জন্য প্রয়োজনীয় কম্পিউট শক্তির বর্ধিত ব্যয়ে আসে। পর্যাপ্ত সংখ্যক নমুনা দেওয়া হলে, আমরা স্ক্র্যাচ থেকে এমবেডিং শেখার পাশাপাশি করতে পারি। আমরা লক্ষ্য করেছি যে
S/W > 15Kএর জন্য, স্ক্র্যাচ থেকে শুরু করে কার্যকরভাবে ফাইন-টিউনড এম্বেডিং ব্যবহার করার মতো একই নির্ভুলতা পাওয়া যায়।
আমরা বিভিন্ন সিকোয়েন্স মডেল যেমন CNN, sepCNN , RNN (LSTM & GRU), CNN-RNN, এবং স্ট্যাকড RNN, মডেল আর্কিটেকচারের ভিন্নতার সাথে তুলনা করেছি। আমরা দেখতে পেয়েছি যে sepCNNs, একটি কনভোল্যুশনাল নেটওয়ার্ক বৈকল্পিক যা প্রায়শই বেশি ডেটা-দক্ষ এবং গণনা-দক্ষ, অন্যান্য মডেলের তুলনায় ভাল পারফর্ম করে।
নিম্নলিখিত কোড একটি চার-স্তর sepCNN মডেল তৈরি করে:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
আপনার মডেল প্রশিক্ষণ
এখন যেহেতু আমরা মডেল আর্কিটেকচার তৈরি করেছি, আমাদের মডেলটিকে প্রশিক্ষণ দিতে হবে। প্রশিক্ষণের মধ্যে রয়েছে মডেলের বর্তমান অবস্থার উপর ভিত্তি করে একটি ভবিষ্যদ্বাণী করা, ভবিষ্যদ্বাণীটি কতটা ভুল তা গণনা করা এবং এই ত্রুটি কমাতে এবং মডেলটিকে আরও ভালভাবে ভবিষ্যদ্বাণী করতে নেটওয়ার্কের ওজন বা প্যারামিটার আপডেট করা। আমরা এই প্রক্রিয়াটি পুনরাবৃত্তি করি যতক্ষণ না আমাদের মডেল একত্রিত হয় এবং আর শিখতে না পারে। এই প্রক্রিয়াটির জন্য তিনটি মূল পরামিতি বেছে নিতে হবে ( টেবিল 2 দেখুন।)
- মেট্রিক : কিভাবে একটি মেট্রিক ব্যবহার করে আমাদের মডেলের কর্মক্ষমতা পরিমাপ করা যায়। আমরা আমাদের পরীক্ষায় মেট্রিক হিসাবে নির্ভুলতা ব্যবহার করেছি।
- লস ফাংশন : একটি ফাংশন যা একটি ক্ষতির মান গণনা করতে ব্যবহৃত হয় যা প্রশিক্ষণ প্রক্রিয়া তারপর নেটওয়ার্ক ওজন টিউন করার মাধ্যমে হ্রাস করার চেষ্টা করে। শ্রেণীবিন্যাস সমস্যার জন্য, ক্রস-এনট্রপি ক্ষতি ভাল কাজ করে।
- অপ্টিমাইজার : একটি ফাংশন যা স্থির করে যে কীভাবে লস ফাংশনের আউটপুটের উপর ভিত্তি করে নেটওয়ার্ক ওজন আপডেট করা হবে। আমরা আমাদের পরীক্ষায় জনপ্রিয় অ্যাডাম অপ্টিমাইজার ব্যবহার করেছি।
কেরাসে, আমরা কম্পাইল পদ্ধতি ব্যবহার করে এই শেখার পরামিতিগুলিকে একটি মডেলে পাস করতে পারি।
সারণি 2: শেখার পরামিতি
| শেখার পরামিতি | মান |
|---|---|
| মেট্রিক | নির্ভুলতা |
| ক্ষতি ফাংশন - বাইনারি শ্রেণীবিভাগ | binary_crossentropy |
| ক্ষতি ফাংশন - বহু শ্রেণীর শ্রেণীবিভাগ | sparse_categorical_crossentropy |
| অপ্টিমাইজার | আদম |
প্রকৃত প্রশিক্ষণ ফিট পদ্ধতি ব্যবহার করে ঘটে। আপনার ডেটাসেটের আকারের উপর নির্ভর করে, এটি সেই পদ্ধতি যেখানে বেশিরভাগ গণনা চক্র ব্যয় করা হবে। প্রতিটি প্রশিক্ষণের পুনরাবৃত্তিতে, আপনার প্রশিক্ষণ ডেটা থেকে batch_size নমুনাগুলি ক্ষতি গণনা করতে ব্যবহৃত হয় এবং এই মানের উপর ভিত্তি করে ওজনগুলি একবার আপডেট করা হয়। মডেলটি সম্পূর্ণ প্রশিক্ষণ ডেটাসেটটি দেখার পর প্রশিক্ষণ প্রক্রিয়াটি একটি epoch শেষ করে। প্রতিটি যুগের শেষে, মডেলটি কতটা ভালভাবে শিখছে তা মূল্যায়ন করতে আমরা বৈধতা ডেটাসেট ব্যবহার করি। আমরা পূর্বনির্ধারিত সংখ্যক যুগের জন্য ডেটাসেট ব্যবহার করে প্রশিক্ষণের পুনরাবৃত্তি করি। আমরা প্রথম দিকে থামার মাধ্যমে এটিকে অপ্টিমাইজ করতে পারি, যখন পরপর যুগের মধ্যে বৈধতা নির্ভুলতা স্থিতিশীল হয়, দেখায় যে মডেলটি আর প্রশিক্ষণ দিচ্ছে না।
| প্রশিক্ষণ হাইপারপ্যারামিটার | মান |
|---|---|
| শেখার হার | 1e-3 |
| যুগ | 1000 |
| ব্যাচের আকার | 512 |
| তাড়াতাড়ি থামানো | প্যারামিটার: ভাল_লস, ধৈর্য: 1 |
সারণি 3: প্রশিক্ষণ হাইপারপ্যারামিটার
নিম্নলিখিত কেরাস কোড উপরের টেবিল 2 এবং 3 এ নির্বাচিত পরামিতিগুলি ব্যবহার করে প্রশিক্ষণ প্রক্রিয়া প্রয়োগ করে:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
অনুক্রম মডেল প্রশিক্ষণের জন্য কোড উদাহরণ এখানে খুঁজুন.