Di bagian ini, kita akan berupaya membangun, melatih, dan mengevaluasi
model transformer. Pada Langkah 3, kita
memilih untuk menggunakan model n-gram atau model urutan, menggunakan rasio S/W.
Sekarang, saatnya untuk menulis algoritma klasifikasi kita dan melatihnya. Kita akan menggunakan
TensorFlow dengan
tf.keras
untuk aplikasi ini.
Membangun model machine learning dengan Keras berarti merakit bersama-sama lapisan, blok bangunan pemrosesan data, mirip seperti saat kita merakit Lego dalam batu bata. Lapisan ini memungkinkan kita untuk menentukan urutan transformasi yang kita inginkan lakukan pada input kita. Karena algoritma pembelajaran kami menerima satu input teks dan menghasilkan klasifikasi tunggal, kita bisa membuat stack linear lapisan menggunakan Model sekuensial Compute Engine API.
Gambar 9: Tumpukan linear lapisan
Lapisan input dan lapisan perantara akan dibuat secara berbeda, tergantung pada apakah kita sedang membuat model n-gram atau urutan. Tapi terlepas dari jenis modelnya, lapisan terakhir akan sama untuk masalah tertentu.
Membangun Lapisan Terakhir
Ketika kita hanya memiliki 2 class (klasifikasi biner), model akan menghasilkan output
skor probabilitas tunggal. Misalnya, menghasilkan output 0.2 untuk contoh input tertentu
berarti “20% keyakinan bahwa sampel ini berada di kelas satu (kelas 1), 80% yang
itu ada di kelas dua (kelas 0).” Untuk menghasilkan skor probabilitas seperti itu,
fungsi aktivasi
lapisan terakhir harus berupa
fungsi sigmoid,
dan
fungsi kerugian
digunakan untuk melatih model harus
entropi silang biner.
(Lihat Gambar 10, kiri).
Jika ada lebih dari 2 class (klasifikasi kelas multi-class), model kita
seharusnya menghasilkan satu skor probabilitas per class. Jumlah dari skor ini harus
Akun Layanan 1. Misalnya, menghasilkan {0: 0.2, 1: 0.7, 2: 0.1} berarti “20% keyakinan bahwa
sampel ini berada di kelas 0, 70% berada di kelas 1, dan 10% berada di kelas
kelas 2". Untuk mendapatkan output skor ini, fungsi aktivasi lapisan terakhir
seharusnya softmax, dan fungsi kerugian yang
digunakan untuk melatih model harus
entropi silang kategorik. (Lihat Gambar 10, kanan).
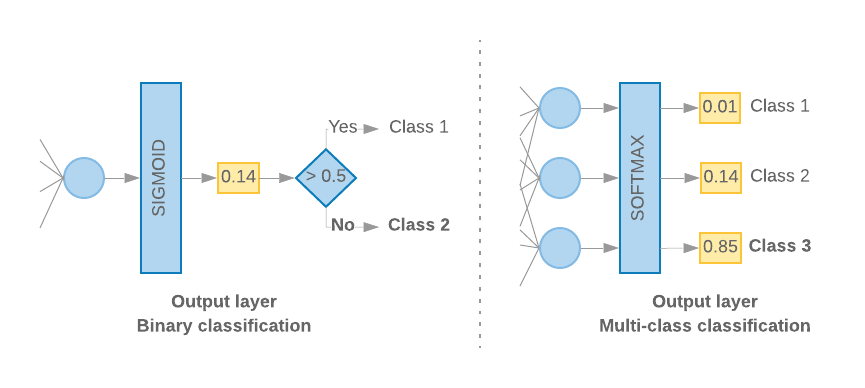
Gambar 10: Lapisan terakhir
Kode berikut menentukan fungsi yang menggunakan jumlah class sebagai input, dan menghasilkan jumlah unit lapisan yang sesuai (1 unit untuk biner klasifikasi; jika tidak, 1 unit untuk setiap class) dan aktivasi yang sesuai {i>function<i}:
def _get_last_layer_units_and_activation(num_classes):
"""Gets the # units and activation function for the last network layer.
# Arguments
num_classes: int, number of classes.
# Returns
units, activation values.
"""
if num_classes == 2:
activation = 'sigmoid'
units = 1
else:
activation = 'softmax'
units = num_classes
return units, activation
Dua bagian berikut akan memandu pembuatan model yang tersisa lapisan untuk model n-gram dan model urutan.
Jika rasio S/W kecil, kami mendapati bahwa model n-gram berperforma lebih baik
daripada model urutan. Model urutan akan lebih baik ketika ada banyak
vektor yang kecil dan padat. Hal ini karena hubungan embedding dipelajari di
ruang padat, dan ini paling baik terjadi
pada banyak sampel.
Membangun model n-gram [Opsi A]
Kami merujuk pada model yang memproses token secara independen (tidak memperhitungkan urutan kata akun) sebagai model n-gram. Perseptron multi-lapisan sederhana (termasuk regresi logistik mesin penguat gradien, dan mendukung model vektor) semuanya termasuk dalam kategori ini; mereka tidak dapat menggunakan informasi tentang pengurutan teks.
Kami membandingkan performa beberapa model n-gram yang disebutkan di atas dan mengamati bahwa perceptron multi-lapisan (MLP) biasanya berperforma lebih baik daripada opsi lainnya. MLP mudah didefinisikan dan dipahami, memberikan akurasi yang baik, dan memerlukan sedikit komputasi yang relatif sedikit.
Kode berikut mendefinisikan model MLP dua lapis di tf.keras, dengan menambahkan beberapa Lapisan pelacur untuk regularisasi untuk mencegah overfitting ke sampel pelatihan.
from tensorflow.python.keras import models
from tensorflow.python.keras.layers import Dense
from tensorflow.python.keras.layers import Dropout
def mlp_model(layers, units, dropout_rate, input_shape, num_classes):
"""Creates an instance of a multi-layer perceptron model.
# Arguments
layers: int, number of `Dense` layers in the model.
units: int, output dimension of the layers.
dropout_rate: float, percentage of input to drop at Dropout layers.
input_shape: tuple, shape of input to the model.
num_classes: int, number of output classes.
# Returns
An MLP model instance.
"""
op_units, op_activation = _get_last_layer_units_and_activation(num_classes)
model = models.Sequential()
model.add(Dropout(rate=dropout_rate, input_shape=input_shape))
for _ in range(layers-1):
model.add(Dense(units=units, activation='relu'))
model.add(Dropout(rate=dropout_rate))
model.add(Dense(units=op_units, activation=op_activation))
return model
Model urutan build [Opsi B]
Kita merujuk model yang bisa belajar dari kedekatan token sebagai urutan jaringan. Ini termasuk class model CNN dan RNN. Data telah diproses sebelumnya sebagai vektor urutan untuk model ini.
Model urutan umumnya memiliki jumlah parameter yang lebih besar untuk dipelajari. Yang pertama lapisan embedding dalam model ini adalah lapisan embedding, di antara kata-kata di ruang vektor padat. Mempelajari hubungan kata terbaik dibandingkan banyak sampel.
Kata dalam {i>dataset<i} tertentu kemungkinan besar tidak unik untuk {i>dataset<i} tersebut. Dengan demikian, kita dapat mempelajari hubungan antara kata-kata di {i>dataset<i} kita dengan menggunakan {i>dataset<i} lain. Untuk melakukannya, kita dapat mentransfer embedding yang dipelajari dari set data lain ke lapisan embedding. Penyematan ini disebut sebagai pra-latihan embedding. Menggunakan penyematan terlatih memberi model awal di awal pembelajaran.
Ada embedding terlatih tersedia yang telah dilatih menggunakan seperti GloVe. GloVe memiliki telah dilatih di berbagai korpora (terutama Wikipedia). Kita telah menguji pelatihan urutan menggunakan versi embeddings GloVe, dan mengamati bahwa jika membekukan bobot embedding yang telah dilatih sebelumnya dan melatih jaringan, model tidak berperforma dengan baik. Hal ini mungkin karena konteks pada lapisan embedding yang dilatih, mungkin berbeda dari di mana kita menggunakannya.
Embedding GloVe yang dilatih dengan data Wikipedia mungkin tidak sesuai dengan bahasa pola yang berbeda dalam {i>dataset<i} IMDb. Hubungan yang disimpulkan mungkin membutuhkan beberapa diperbarui—yaitu, bobot embedding mungkin memerlukan penyesuaian kontekstual. Kita melakukannya dengan dua tahap:
Saat pertama kali dijalankan, setelah bobot lapisan embedding dibekukan, kami mengizinkan sisanya jaringan untuk dipelajari. Di akhir proses ini, bobot model akan mencapai suatu status itu jauh lebih baik daripada nilai-nilainya yang tidak diinisialisasi. Untuk putaran kedua, kita memungkinkan lapisan embedding belajar, melakukan penyesuaian dengan baik pada semua bobot dalam jaringan. Kami menyebut proses ini sebagai menggunakan embedding yang telah di-fine-tune.
Embedding yang di-fine-tune menghasilkan akurasi yang lebih baik. Namun, ini terjadi pada biaya peningkatan daya komputasi yang diperlukan untuk melatih jaringan. Mengingat jumlah sampel yang memadai, kita juga bisa mempelajari embedding dari awal. Kami mengamati bahwa untuk
S/W > 15K, memulai dari awal secara efektif menghasilkan akurasi yang sama dengan penggunaan penyematan yang lebih mendetail.
Kami membandingkan berbagai model urutan seperti CNN, sepCNN, RNN (LSTM &GRU), CNN-RNN, dan RNN bertumpuk, yang memvariasikan arsitektur model. Kita menemukan bahwa sepCNN, varian jaringan konvolusional yang sering kali lebih hemat data dan efisien komputasi, serta memiliki performa yang lebih baik model lainnya.
Kode berikut menyusun model sepCNN empat lapis:
from tensorflow.python.keras import models from tensorflow.python.keras import initializers from tensorflow.python.keras import regularizers from tensorflow.python.keras.layers import Dense from tensorflow.python.keras.layers import Dropout from tensorflow.python.keras.layers import Embedding from tensorflow.python.keras.layers import SeparableConv1D from tensorflow.python.keras.layers import MaxPooling1D from tensorflow.python.keras.layers import GlobalAveragePooling1D def sepcnn_model(blocks, filters, kernel_size, embedding_dim, dropout_rate, pool_size, input_shape, num_classes, num_features, use_pretrained_embedding=False, is_embedding_trainable=False, embedding_matrix=None): """Creates an instance of a separable CNN model. # Arguments blocks: int, number of pairs of sepCNN and pooling blocks in the model. filters: int, output dimension of the layers. kernel_size: int, length of the convolution window. embedding_dim: int, dimension of the embedding vectors. dropout_rate: float, percentage of input to drop at Dropout layers. pool_size: int, factor by which to downscale input at MaxPooling layer. input_shape: tuple, shape of input to the model. num_classes: int, number of output classes. num_features: int, number of words (embedding input dimension). use_pretrained_embedding: bool, true if pre-trained embedding is on. is_embedding_trainable: bool, true if embedding layer is trainable. embedding_matrix: dict, dictionary with embedding coefficients. # Returns A sepCNN model instance. """ op_units, op_activation = _get_last_layer_units_and_activation(num_classes) model = models.Sequential() # Add embedding layer. If pre-trained embedding is used add weights to the # embeddings layer and set trainable to input is_embedding_trainable flag. if use_pretrained_embedding: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0], weights=[embedding_matrix], trainable=is_embedding_trainable)) else: model.add(Embedding(input_dim=num_features, output_dim=embedding_dim, input_length=input_shape[0])) for _ in range(blocks-1): model.add(Dropout(rate=dropout_rate)) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(MaxPooling1D(pool_size=pool_size)) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(SeparableConv1D(filters=filters * 2, kernel_size=kernel_size, activation='relu', bias_initializer='random_uniform', depthwise_initializer='random_uniform', padding='same')) model.add(GlobalAveragePooling1D()) model.add(Dropout(rate=dropout_rate)) model.add(Dense(op_units, activation=op_activation)) return model
Latih Model
Setelah membangun arsitektur model, kita perlu melatih model. Pelatihan melibatkan pembuatan prediksi berdasarkan kondisi model saat ini, menghitung seberapa salah prediksinya, dan memperbarui bobot atau parameter jaringan untuk meminimalkan error ini dan membuat model memprediksi dengan lebih baik. Kita mengulangi proses ini sampai model telah dikonvergensi dan tidak bisa lagi belajar. Ada tiga parameter utama yang harus dipilih untuk proses ini (Lihat Tabel 2.)
- Metrik: Cara mengukur performa model kami menggunakan metrik. Kita menggunakan akurasi sebagai metrik dalam eksperimen.
- Fungsi kerugian: Fungsi yang digunakan untuk menghitung nilai kerugian bahwa proses pelatihan kemudian mencoba untuk meminimalkan dengan menyesuaikan dan bobot jaringan. Untuk masalah klasifikasi, kerugian entropi silang berfungsi dengan baik.
- Optimizer: Fungsi yang menentukan bobot jaringan diperbarui berdasarkan {i>output <i}dari fungsi kerugian. Kami menggunakan Pengoptimal Adam dalam eksperimen kami.
Di Keras, kita dapat meneruskan parameter pembelajaran ini ke model menggunakan kompilasi .
Tabel 2: Parameter pembelajaran
| Parameter pembelajaran | Nilai |
|---|---|
| Metrik | akurasi |
| Fungsi kerugian - klasifikasi biner | binary_crossentropy |
| Fungsi kerugian - klasifikasi multi-kelas | sparse_categorical_crossentropy |
| Taktis | Adam |
Pelatihan yang sebenarnya dilakukan dengan menggunakan
fit.
Tergantung pada ukuran
, ini adalah metode yang digunakan untuk menghabiskan sebagian besar siklus komputasi. Dalam setiap
iterasi pelatihan, batch_size jumlah sampel dari data pelatihan Anda
digunakan untuk menghitung kerugian, dan bobotnya diperbarui sekali, berdasarkan nilai ini.
Proses pelatihan menyelesaikan epoch setelah model melihat seluruh
pelatihan. Di akhir setiap epoch, kami menggunakan
set data validasi untuk
mengevaluasi seberapa baik
model belajar. Kita mengulangi pelatihan menggunakan {i>dataset<i}
untuk jumlah epoch yang telah ditentukan. Kita dapat mengoptimalkan ini
dengan berhenti lebih awal,
ketika akurasi validasi stabil di antara epoch berturut-turut, yang menunjukkan bahwa
model tidak dilatih lagi.
| Melatih hyperparameter | Nilai |
|---|---|
| Kecepatan pembelajaran | 1e-3 |
| Epoch | 1000 |
| Ukuran batch | 512 |
| Penghentian awal | parameter: val_loss, kesabaran: 1 |
Tabel 3: Melatih hyperparameter
Kode Keras berikut mengimplementasikan proses pelatihan menggunakan parameter dipilih pada Tabel 2 & 3 di atas:
def train_ngram_model(data, learning_rate=1e-3, epochs=1000, batch_size=128, layers=2, units=64, dropout_rate=0.2): """Trains n-gram model on the given dataset. # Arguments data: tuples of training and test texts and labels. learning_rate: float, learning rate for training model. epochs: int, number of epochs. batch_size: int, number of samples per batch. layers: int, number of `Dense` layers in the model. units: int, output dimension of Dense layers in the model. dropout_rate: float: percentage of input to drop at Dropout layers. # Raises ValueError: If validation data has label values which were not seen in the training data. """ # Get the data. (train_texts, train_labels), (val_texts, val_labels) = data # Verify that validation labels are in the same range as training labels. num_classes = explore_data.get_num_classes(train_labels) unexpected_labels = [v for v in val_labels if v not in range(num_classes)] if len(unexpected_labels): raise ValueError('Unexpected label values found in the validation set:' ' {unexpected_labels}. Please make sure that the ' 'labels in the validation set are in the same range ' 'as training labels.'.format( unexpected_labels=unexpected_labels)) # Vectorize texts. x_train, x_val = vectorize_data.ngram_vectorize( train_texts, train_labels, val_texts) # Create model instance. model = build_model.mlp_model(layers=layers, units=units, dropout_rate=dropout_rate, input_shape=x_train.shape[1:], num_classes=num_classes) # Compile model with learning parameters. if num_classes == 2: loss = 'binary_crossentropy' else: loss = 'sparse_categorical_crossentropy' optimizer = tf.keras.optimizers.Adam(lr=learning_rate) model.compile(optimizer=optimizer, loss=loss, metrics=['acc']) # Create callback for early stopping on validation loss. If the loss does # not decrease in two consecutive tries, stop training. callbacks = [tf.keras.callbacks.EarlyStopping( monitor='val_loss', patience=2)] # Train and validate model. history = model.fit( x_train, train_labels, epochs=epochs, callbacks=callbacks, validation_data=(x_val, val_labels), verbose=2, # Logs once per epoch. batch_size=batch_size) # Print results. history = history.history print('Validation accuracy: {acc}, loss: {loss}'.format( acc=history['val_acc'][-1], loss=history['val_loss'][-1])) # Save model. model.save('IMDb_mlp_model.h5') return history['val_acc'][-1], history['val_loss'][-1]
Temukan contoh kode untuk melatih model urutan di sini.