Trước khi có thể cấp dữ liệu cho một mô hình, bạn cần chuyển dữ liệu đó sang một định dạng mô hình đó có thể hiểu được.
Trước tiên, các mẫu dữ liệu mà chúng tôi đã thu thập có thể được sắp xếp theo thứ tự cụ thể. Chúng tôi không muốn bất kỳ thông tin nào liên quan đến thứ tự của các mẫu ảnh hưởng đến mối quan hệ giữa văn bản và nhãn. Ví dụ: nếu một tập dữ liệu được sắp xếp theo lớp và sau đó được chia thành các tập huấn luyện/xác thực, các tập hợp này sẽ không được đại diện cho toàn bộ phân phối dữ liệu.
Phương pháp hay nhất đơn giản để đảm bảo mô hình không bị ảnh hưởng bởi thứ tự dữ liệu là luôn xáo trộn dữ liệu trước khi làm bất kỳ điều gì khác. Nếu dữ liệu của bạn đã được chia thành nhóm huấn luyện và xác thực, hãy đảm bảo biến đổi việc xác thực giống như cách bạn chuyển đổi dữ liệu huấn luyện. Nếu bạn chưa có tập huấn luyện và xác thực riêng biệt, bạn có thể chia các mẫu sau đang xáo trộn; thông thường sẽ sử dụng 80% mẫu cho việc huấn luyện và 20% cho xác thực.
Thứ hai, các thuật toán học máy lấy các con số làm dữ liệu đầu vào. Điều này có nghĩa là chúng tôi sẽ cần chuyển đổi văn bản thành vectơ số. Có hai bước để quy trình này:
Mã hoá kỹ thuật số: Chia văn bản thành các từ hoặc văn bản phụ nhỏ hơn. Nhờ vậy, cho phép khái quát hoá tốt mối quan hệ giữa văn bản và nhãn. Phần này xác định "từ vựng" của tập dữ liệu (tập hợp các mã thông báo duy nhất có trong dữ liệu).
Vector hoá: Xác định giá trị đo lường số phù hợp để mô tả các giá trị này văn bản.
Hãy xem cách thực hiện hai bước này cho cả vectơ và chuỗi n-gam vectơ, cũng như cách tối ưu hoá biểu diễn vectơ bằng cách sử dụng tính năng kỹ thuật lựa chọn và chuẩn hoá.
Vectơ N gam [Cách A]
Trong các đoạn tiếp theo, chúng ta sẽ tìm hiểu cách tiến hành mã hoá và vectơ hoá cho mô hình n-gram. Chúng tôi cũng sẽ đề cập đến cách tối ưu hoá n- bằng cách sử dụng kỹ thuật lựa chọn đối tượng và chuẩn hoá.
Trong vectơ n-gram, văn bản được biểu diễn dưới dạng tập hợp n-gram duy nhất:
các nhóm n mã liền kề (thông thường là từ). Hãy xem xét văn bản The mouse ran
up the clock. Tại đây:
- Từ unigram (n = 1) là
['the', 'mouse', 'ran', 'up', 'clock']. - Từ Bigrams (n = 2) là
['the mouse', 'mouse ran', 'ran up', 'up the', 'the clock'] - Và tương tự như vậy.
Mã hoá
Chúng tôi thấy rằng việc tạo mã thông báo thành các biểu ngữ hình chữ thập và chữ tượng hình đại diện mang lại hiệu quả cao chính xác hơn mà vẫn mất ít thời gian tính toán hơn.
Vectơ hoá
Khi chúng ta đã chia mẫu văn bản thành n-gam, chúng ta cần biến những n-gam này thành các vectơ số mà các mô hình học máy của chúng tôi có thể xử lý. Ví dụ phần dưới đây biểu thị các chỉ số được gán cho các biểu tượng đồng đồ và các đại lượng lớn được tạo ra cho hai văn bản.
Texts: 'The mouse ran up the clock' and 'The mouse ran down' Index assigned for every token: {'the': 7, 'mouse': 2, 'ran': 4, 'up': 10, 'clock': 0, 'the mouse': 9, 'mouse ran': 3, 'ran up': 6, 'up the': 11, 'the clock': 8, 'down': 1, 'ran down': 5}
Khi các chỉ mục được gán cho n-gram, chúng ta thường vectơ hoá bằng cách sử dụng một trong các tuỳ chọn sau đây.
Mã hoá một nóng: Mỗi văn bản mẫu được biểu thị dưới dạng một vectơ cho biết sự có mặt hay không có mã thông báo trong văn bản.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1]
Mã hoá số lượng: Mỗi văn bản mẫu được biểu thị dưới dạng một vectơ cho biết
số lượng mã thông báo trong văn bản. Xin lưu ý rằng phần tử tương ứng với
unigram "the" hiện được biểu thị là 2 vì từ "the"
xuất hiện hai lần trong văn bản.
'The mouse ran up the clock' = [1, 0, 1, 1, 1, 0, 1, 2, 1, 1, 1, 1]
Mã hoá Tf-idf: Vấn đề với hai cách tiếp cận ở trên là các từ phổ biến xuất hiện theo cách tương tự tần suất trong tất cả tài liệu (nghĩa là các từ không đặc biệt riêng biệt đối với các mẫu văn bản trong tập dữ liệu) sẽ không bị phạt. Ví dụ: Những từ như "a" sẽ xuất hiện rất thường xuyên trong tất cả văn bản. Vì vậy, số lượng mã thông báo cho "the" cao hơn so với cho những từ khác có ý nghĩa hơn thì không hề hữu ích.
'The mouse ran up the clock' = [0.33, 0, 0.23, 0.23, 0.23, 0, 0.33, 0.47, 0.33, 0.23, 0.33, 0.33]
(Xem bài viết Scikit-learn TfidfTransformer)
Có nhiều cách biểu diễn vectơ khác, nhưng 3 cách biểu diễn trên là thường dùng nhất.
Chúng tôi quan sát thấy phương thức mã hoá tf-idf tốt hơn một chút so với hai phương thức còn lại trong độ chính xác (trung bình: cao hơn 0,25-15%), và khuyến nghị sử dụng phương pháp này để vectơ hoá n-gam. Tuy nhiên, xin lưu ý rằng việc này sẽ chiếm nhiều bộ nhớ hơn (như phương pháp này sử dụng biểu diễn dấu phẩy động) và mất nhiều thời gian hơn để tính toán, đặc biệt đối với các tập dữ liệu lớn (có thể mất gấp đôi trong một số trường hợp).
Lựa chọn tính năng
Khi chúng tôi chuyển đổi tất cả văn bản trong một tập dữ liệu thành mã thông báo uni+bigram, chúng tôi có thể nhận được hàng chục nghìn mã thông báo. Không phải tất cả các mã thông báo/tính năng này đóng góp vào thông tin dự đoán về nhãn. Ví dụ: chúng ta có thể bỏ một số mã thông báo những việc xảy ra rất hiếm khi xảy ra trên tập dữ liệu. Chúng tôi cũng có thể đo lường tầm quan trọng của tính năng (mức đóng góp của mỗi mã thông báo vào việc dự đoán nhãn) và chỉ nên nhập những mã thông báo có nhiều thông tin nhất.
Có nhiều hàm thống kê nhận các tính năng và hàm thống kê tương ứng và xuất điểm mức độ quan trọng của tính năng. Hai hàm thường dùng là f_classif và chi2. thử nghiệm cho thấy cả hai chức năng này đều hoạt động hiệu quả như nhau.
Quan trọng hơn, chúng tôi nhận thấy rằng độ chính xác đạt tối đa ở khoảng 20.000 tính năng đối với nhiều (Xem Hình 6). Việc thêm các tính năng khác vượt quá ngưỡng này sẽ góp phần rất ít và đôi khi thậm chí dẫn đến trang bị quá mức và làm giảm hiệu suất.

Hình 6: Các tính năng hàng đầu K so với Độ chính xác. Trên các tập dữ liệu, độ chính xác không thay đổi ở khoảng 20 nghìn tính năng hàng đầu.
Chuẩn hoá
Chuẩn hoá sẽ chuyển đổi tất cả giá trị mẫu/tính năng thành các giá trị nhỏ và tương tự nhau. Việc này giúp đơn giản hoá quy trình hội tụ hiệu ứng giảm độ dốc trong các thuật toán học. Từ những gì như chúng ta đã thấy, việc chuẩn hoá trong quá trình xử lý trước dữ liệu dường như không mang lại nhiều giá trị trong bài toán phân loại văn bản; bạn nên bỏ qua bước này.
Đoạn mã sau đây tổng hợp tất cả các bước trên:
- Mã hoá mẫu văn bản thành uni+bigram từ,
- Vectơ hoá bằng phương thức mã hoá tf-idf,
- Chỉ chọn 20.000 đối tượng hàng đầu trong vectơ mã thông báo bằng cách loại bỏ mã thông báo xuất hiện ít hơn 2 lần và sử dụng f_classif để tính toán tính năng tầm quan trọng của chúng.
from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.feature_selection import SelectKBest from sklearn.feature_selection import f_classif # Vectorization parameters # Range (inclusive) of n-gram sizes for tokenizing text. NGRAM_RANGE = (1, 2) # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Whether text should be split into word or character n-grams. # One of 'word', 'char'. TOKEN_MODE = 'word' # Minimum document/corpus frequency below which a token will be discarded. MIN_DOCUMENT_FREQUENCY = 2 def ngram_vectorize(train_texts, train_labels, val_texts): """Vectorizes texts as n-gram vectors. 1 text = 1 tf-idf vector the length of vocabulary of unigrams + bigrams. # Arguments train_texts: list, training text strings. train_labels: np.ndarray, training labels. val_texts: list, validation text strings. # Returns x_train, x_val: vectorized training and validation texts """ # Create keyword arguments to pass to the 'tf-idf' vectorizer. kwargs = { 'ngram_range': NGRAM_RANGE, # Use 1-grams + 2-grams. 'dtype': 'int32', 'strip_accents': 'unicode', 'decode_error': 'replace', 'analyzer': TOKEN_MODE, # Split text into word tokens. 'min_df': MIN_DOCUMENT_FREQUENCY, } vectorizer = TfidfVectorizer(**kwargs) # Learn vocabulary from training texts and vectorize training texts. x_train = vectorizer.fit_transform(train_texts) # Vectorize validation texts. x_val = vectorizer.transform(val_texts) # Select top 'k' of the vectorized features. selector = SelectKBest(f_classif, k=min(TOP_K, x_train.shape[1])) selector.fit(x_train, train_labels) x_train = selector.transform(x_train).astype('float32') x_val = selector.transform(x_val).astype('float32') return x_train, x_val
Với biểu diễn vectơ n-gram, chúng tôi loại bỏ nhiều thông tin về từ đơn đặt hàng và ngữ pháp (tốt nhất chúng tôi có thể giữ lại một phần thông tin đặt hàng khi n > 1). Đây được gọi là phương pháp chọn từ. Biểu diễn này được sử dụng kết hợp với các mô hình không tính đến thứ tự, chẳng hạn như hồi quy logistic, perceptron nhiều lớp, máy tăng độ dốc, hỗ trợ máy vectơ.
Vectơ chuỗi [Phương án B]
Trong các đoạn tiếp theo, chúng ta sẽ tìm hiểu cách tiến hành mã hoá và vectơ hoá cho mô hình chuỗi. Chúng tôi cũng sẽ đề cập đến cách tối ưu hoá biểu diễn trình tự bằng cách sử dụng kỹ thuật lựa chọn đối tượng và chuẩn hoá.
Đối với một số mẫu văn bản, thứ tự từ rất quan trọng đối với ý nghĩa của văn bản. Cho ví dụ: các câu “Tôi từng ghét việc đi làm. Chiếc xe đạp mới của tôi đã thay đổi điều đó hoàn toàn" chỉ có thể hiểu được khi được đọc theo thứ tự. Các mô hình như CNN/RNN có thể suy ra ý nghĩa từ thứ tự từ trong một mẫu. Đối với các mô hình này, chúng tôi biểu thị văn bản dưới dạng chuỗi mã thông báo, duy trì thứ tự.
Mã hoá
Văn bản có thể được biểu thị dưới dạng một chuỗi ký tự hoặc một chuỗi các từ. Chúng tôi nhận thấy rằng việc sử dụng cách trình bày ở cấp từ ngữ mang lại hiệu quả cao hơn hơn là mã thông báo ký tự. Đây cũng là một quy tắc chung tiếp theo là ngành. Việc sử dụng mã thông báo ký tự chỉ hợp lý nếu văn bản có nhiều lỗi chính tả, đây thường không phải là trường hợp như vậy.
Vectơ hoá
Khi đã chuyển đổi mẫu văn bản thành các chuỗi từ, chúng ta cần biến các chuỗi này thành vectơ số. Ví dụ bên dưới cho thấy các chỉ mục được gán cho các unigram được tạo cho hai văn bản và sau đó là chuỗi mã thông báo chỉ mục mà văn bản đầu tiên được chuyển đổi.
Texts: 'The mouse ran up the clock' and 'The mouse ran down'
Đã chỉ định chỉ mục cho mọi mã thông báo:
{'clock': 5, 'ran': 3, 'up': 4, 'down': 6, 'the': 1, 'mouse': 2}
LƯU Ý: Từ "the" xảy ra thường xuyên nhất, vì vậy giá trị chỉ số của 1 là được giao cho cuộc trò chuyện đó. Một số thư viện dành riêng chỉ mục 0 cho các mã thông báo không xác định, như hiện tại trường hợp ở đây.
Trình tự chỉ mục mã thông báo:
'The mouse ran up the clock' = [1, 2, 3, 4, 1, 5]
Có hai tuỳ chọn để vectơ hoá trình tự mã thông báo:
Mã hoá một nóng: Các trình tự được biểu diễn bằng các vectơ từ trong n- không gian chiều, trong đó n = số lượng từ vựng. Cách trình bày này rất phù hợp khi chúng ta tạo mã thông báo dưới dạng các ký tự và do đó, vốn từ vựng khá nhỏ. Khi chúng ta chuyển đổi thành từ vựng, từ vựng thường có hàng chục hàng nghìn mã thông báo, làm cho vectơ một điểm rất thưa thớt và không hiệu quả. Ví dụ:
'The mouse ran up the clock' = [
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 1, 0, 0, 0, 0],
[0, 0, 0, 1, 0, 0, 0],
[0, 0, 0, 0, 1, 0, 0],
[0, 1, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 1, 0]
]
Nhúng từ: Từ có(các) ý nghĩa tương ứng. Kết quả là chúng tôi có thể biểu diễn mã thông báo từ trong không gian vectơ dày đặc (~vài trăm số thực), trong đó vị trí và khoảng cách giữa các từ cho biết mức độ giống nhau của các từ đó về mặt ngữ nghĩa (Xem Hình 7). Biểu diễn này được gọi là Nhúng từ.
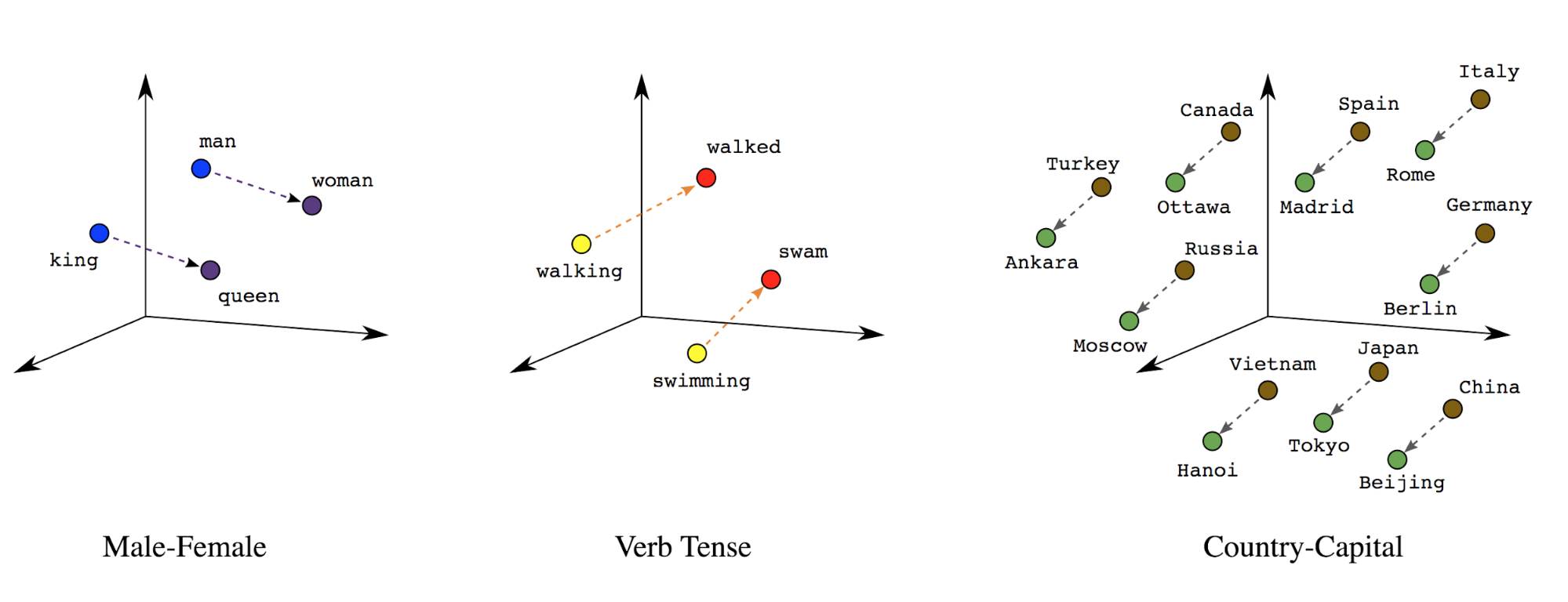
Hình 7: Các mục nhúng từ
Mô hình trình tự thường có một lớp nhúng như lớp đầu tiên. Chiến dịch này lớp này học cách biến các chuỗi chỉ mục từ thành các vectơ nhúng từ trong quá trình huấn luyện, sao cho mỗi chỉ mục từ được ánh xạ tới một vectơ dày đặc giá trị thực đại diện cho vị trí của từ đó trong không gian ngữ nghĩa (Xem Hình 8).
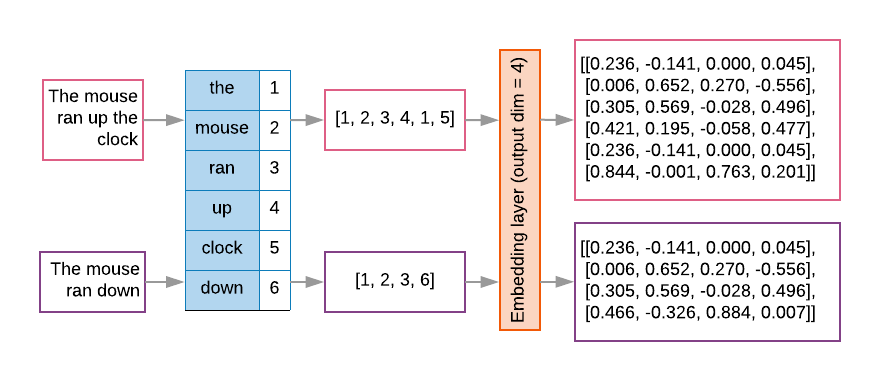
Hình 8: Lớp nhúng
Lựa chọn tính năng
Không phải tất cả các từ trong dữ liệu của chúng tôi đều đóng góp vào cụm từ gợi ý về nhãn. Chúng tôi có thể tối ưu hoá quá trình học tập bằng cách loại bỏ những từ hiếm hoặc không liên quan khỏi vốn từ vựng của chúng tôi. Trong trên thực tế, chúng tôi quan sát thấy rằng việc sử dụng 20.000 tính năng thường xuyên nhất thường được là đủ. Điều này cũng đúng với các mô hình n-gram (Xem Hình 6).
Hãy đặt tất cả các bước ở trên vào vectơ hoá trình tự cùng nhau. Chiến lược phát hành đĩa đơn đoạn mã sau sẽ thực hiện những tác vụ này:
- Mã hoá văn bản thành từ
- Tạo từ vựng bằng 20.000 token hàng đầu
- Chuyển đổi mã thông báo thành vectơ trình tự
- Lồng các trình tự theo độ dài trình tự cố định
from tensorflow.python.keras.preprocessing import sequence from tensorflow.python.keras.preprocessing import text # Vectorization parameters # Limit on the number of features. We use the top 20K features. TOP_K = 20000 # Limit on the length of text sequences. Sequences longer than this # will be truncated. MAX_SEQUENCE_LENGTH = 500 def sequence_vectorize(train_texts, val_texts): """Vectorizes texts as sequence vectors. 1 text = 1 sequence vector with fixed length. # Arguments train_texts: list, training text strings. val_texts: list, validation text strings. # Returns x_train, x_val, word_index: vectorized training and validation texts and word index dictionary. """ # Create vocabulary with training texts. tokenizer = text.Tokenizer(num_words=TOP_K) tokenizer.fit_on_texts(train_texts) # Vectorize training and validation texts. x_train = tokenizer.texts_to_sequences(train_texts) x_val = tokenizer.texts_to_sequences(val_texts) # Get max sequence length. max_length = len(max(x_train, key=len)) if max_length > MAX_SEQUENCE_LENGTH: max_length = MAX_SEQUENCE_LENGTH # Fix sequence length to max value. Sequences shorter than the length are # padded in the beginning and sequences longer are truncated # at the beginning. x_train = sequence.pad_sequences(x_train, maxlen=max_length) x_val = sequence.pad_sequences(x_val, maxlen=max_length) return x_train, x_val, tokenizer.word_index
Vectơ hoá nhãn
Chúng ta đã thấy cách chuyển đổi dữ liệu văn bản mẫu thành vectơ số. Quy trình tương tự
phải được áp dụng cho các nhãn. Chúng ta có thể chỉ cần chuyển đổi nhãn thành các giá trị trong phạm vi
[0, num_classes - 1]. Ví dụ: nếu có 3 lớp, chúng ta chỉ cần sử dụng
các giá trị 0, 1 và 2 để biểu thị chúng. Trong nội bộ, mạng sẽ sử dụng
các vectơ biểu diễn các giá trị này (để tránh suy ra mối quan hệ không chính xác
giữa các nhãn). Cách biểu diễn này phụ thuộc vào hàm mất mát và giá trị cuối cùng
mà chúng tôi sử dụng trong mạng nơron của mình. Chúng ta sẽ tìm hiểu thêm về
những điều này trong phần tiếp theo.