Hiện tại, chúng tôi đã tập hợp tập dữ liệu và có được thông tin chi tiết về các đặc điểm chính của dữ liệu. Tiếp theo, dựa trên các chỉ số đã thu thập được ở Bước 2, chúng ta nên suy nghĩ về mô hình phân loại mình nên sử dụng. Điều này có nghĩa là bạn có thể đặt các câu hỏi như:
- Làm cách nào để trình bày dữ liệu văn bản cho thuật toán yêu cầu dữ liệu đầu vào dạng số? (Đây được gọi là tiền xử lý và vectơ hoá dữ liệu).
- Bạn sẽ sử dụng loại mô hình nào?
- Bạn nên sử dụng thông số cấu hình nào cho mô hình của mình?
Nhờ trải qua nhiều thập kỷ nghiên cứu, chúng tôi có quyền truy cập vào một lượng lớn các lựa chọn cấu hình mô hình và xử lý trước dữ liệu. Tuy nhiên, với rất nhiều lựa chọn khả thi, có thể làm tăng đáng kể độ phức tạp và phạm vi của một vấn đề cụ thể. Do các lựa chọn tốt nhất có thể không rõ ràng, nên một giải pháp đơn thuần là thử mọi phương án có thể một cách toàn diện, cắt giảm một số lựa chọn thông qua trực giác. Tuy nhiên, việc đó sẽ cực kỳ tốn kém.
Trong hướng dẫn này, chúng tôi cố gắng đơn giản hoá đáng kể quy trình chọn mô hình phân loại văn bản. Đối với một tập dữ liệu nhất định, mục tiêu của chúng tôi là tìm ra thuật toán đạt được độ chính xác gần với độ chính xác tối đa, đồng thời giảm thiểu thời gian tính toán cần thiết cho việc huấn luyện. Chúng tôi đã chạy một số lượng lớn (~450 nghìn) thử nghiệm cho các vấn đề thuộc nhiều loại (đặc biệt là các vấn đề phân tích quan điểm và phân loại chủ đề), sử dụng 12 tập dữ liệu, xen kẽ cho mỗi tập dữ liệu giữa các kỹ thuật tiền xử lý dữ liệu và cấu trúc mô hình khác nhau. Điều này đã giúp chúng tôi xác định các tham số của tập dữ liệu ảnh hưởng đến các lựa chọn tối ưu.
Thuật toán chọn mô hình và lưu đồ dưới đây là bản tóm tắt về thử nghiệm của chúng tôi. Đừng lo lắng nếu bạn chưa hiểu tất cả các thuật ngữ được sử dụng trong đó; các phần sau của hướng dẫn này sẽ giải thích chi tiết về những thuật ngữ này.
Thuật toán cho việc chuẩn bị dữ liệu và xây dựng mô hình
- Tính số lượng mẫu/số từ trên mỗi tỷ lệ mẫu.
- Nếu tỷ lệ này nhỏ hơn 1500, hãy mã hoá văn bản dưới dạng n-gram và sử dụng một mô hình perceptron nhiều lớp (MLP) đơn giản để phân loại chúng (nhánh trái trong lưu đồ bên dưới):
- Chia các mẫu thành từ n-gam; chuyển đổi n-gam thành vectơ.
- Cho điểm mức độ quan trọng của vectơ rồi chọn 20 nghìn vectơ hàng đầu bằng cách sử dụng điểm số.
- Xây dựng mô hình MLP.
- Nếu tỷ lệ này lớn hơn 1500, hãy mã hoá văn bản thành trình tự và sử dụng mô hình sepCNN để phân loại chúng (nhánh bên phải trong sơ đồ quy trình dưới đây):
- Chia các mẫu thành từ rồi chọn 20 nghìn từ hàng đầu dựa trên tần suất của các từ đó.
- Chuyển đổi các mẫu thành vectơ chuỗi từ.
- Nếu số mẫu/số từ ban đầu trên mỗi tỷ lệ mẫu nhỏ hơn 15.000, thì việc sử dụng quy trình nhúng được huấn luyện trước bằng mô hình sepCNN có thể mang lại kết quả tốt nhất.
- Đo lường hiệu suất của mô hình với các giá trị siêu tham số khác nhau để tìm cấu hình mô hình tốt nhất cho tập dữ liệu.
Trong sơ đồ quy trình dưới đây, các hộp màu vàng biểu thị quy trình chuẩn bị dữ liệu và mô hình. Hộp màu xám và hộp màu xanh lục cho biết các lựa chọn mà chúng tôi đã xem xét cho mỗi quy trình. Các hộp xanh lục cho biết lựa chọn chúng tôi đề xuất cho từng quy trình.
Bạn có thể sử dụng lưu đồ này làm điểm bắt đầu để xây dựng thử nghiệm đầu tiên, vì sơ đồ này sẽ mang lại độ chính xác cao với chi phí tính toán thấp. Sau đó, bạn có thể tiếp tục cải thiện mô hình ban đầu trong các vòng lặp tiếp theo.
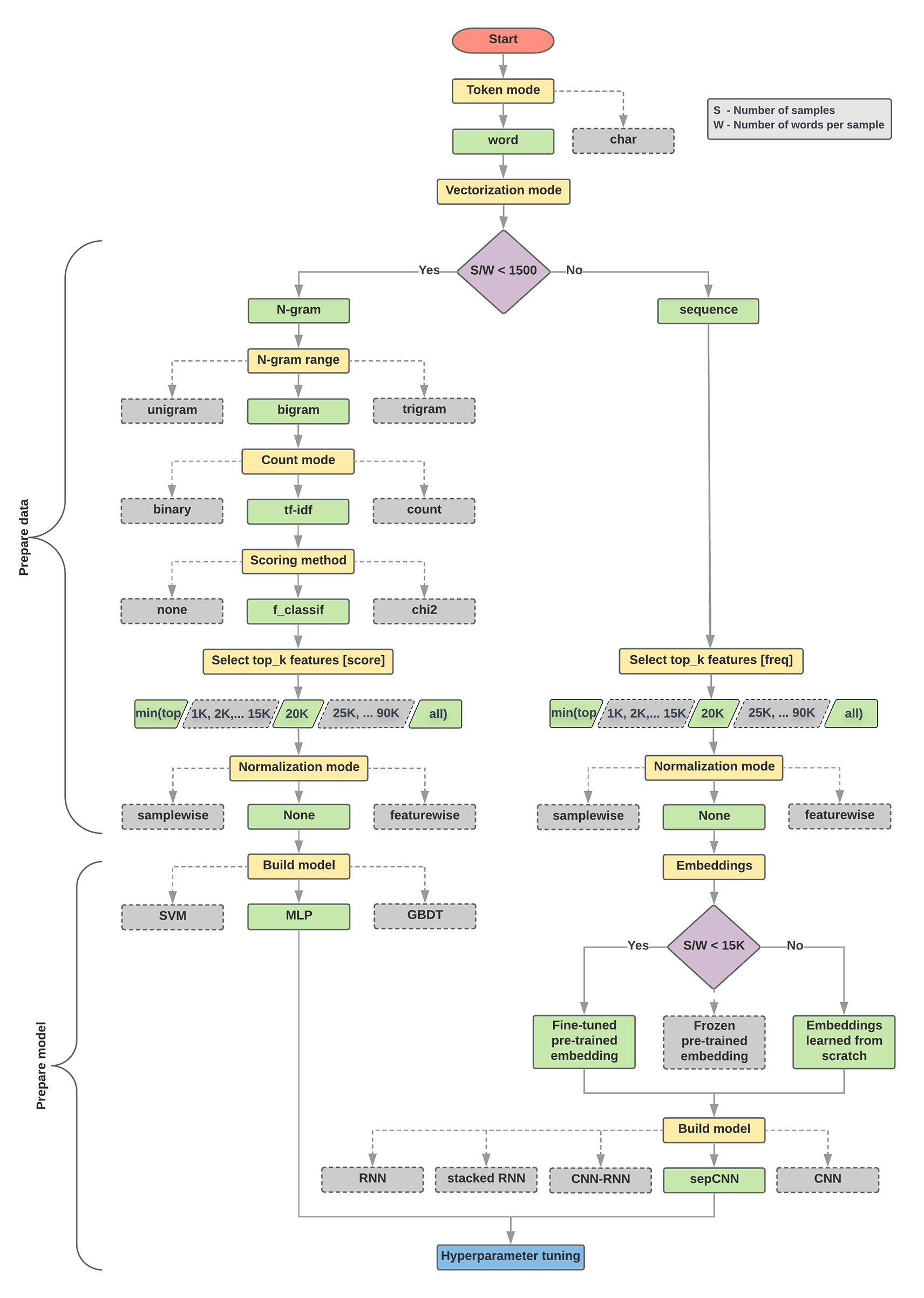
Hình 5: Sơ đồ quy trình phân loại văn bản
Sơ đồ quy trình này trả lời hai câu hỏi chính:
- Bạn nên sử dụng thuật toán hoặc mô hình học tập nào?
- Bạn nên chuẩn bị dữ liệu như thế nào để tìm hiểu hiệu quả mối quan hệ giữa văn bản và nhãn?
Câu trả lời cho câu hỏi thứ hai phụ thuộc vào câu trả lời cho câu hỏi đầu tiên; cách chúng tôi xử lý trước dữ liệu để đưa vào một mô hình sẽ phụ thuộc vào mô hình mà chúng tôi chọn. Các mô hình có thể được phân loại rộng thành hai danh mục: loại sử dụng thông tin sắp xếp thứ tự từ (mô hình trình tự) và loại chỉ xem văn bản dưới dạng "túi" (tập hợp) các từ (mô hình n-gram). Các loại mô hình trình tự bao gồm mạng nơron tích chập (CNN), mạng nơron lặp lại (RNN) và các biến thể của chúng. Sau đây là các loại mô hình n-gram:
- hồi quy logistic
- perceptron nhiều lớp đơn giản (MLP, hoặc mạng nơron kết nối đầy đủ)
- cây được tăng độ dốc
- hỗ trợ máy vectơ
Từ các thử nghiệm của mình, chúng tôi quan sát thấy tỷ lệ giữa “số mẫu” (S) và “số từ trên mỗi mẫu” (W) tương quan với mô hình hoạt động tốt.
Khi giá trị của tỷ lệ này nhỏ (<1500), các perceptron nhỏ nhiều lớp lấy n-gram làm dữ liệu đầu vào (chúng tôi sẽ gọi Tuỳ chọn A) sẽ hoạt động tốt hơn hoặc ít nhất là các mô hình trình tự. MLP rất dễ định nghĩa và dễ hiểu, đồng thời mất ít thời gian tính toán hơn nhiều so với mô hình trình tự. Khi giá trị của tỷ lệ này lớn (>= 1500), hãy sử dụng mô hình trình tự (Lựa chọn B). Trong các bước tiếp theo, bạn có thể chuyển đến các phần phụ có liên quan (được gắn nhãn là A hoặc B) cho loại mô hình mà bạn đã chọn dựa trên tỷ lệ mẫu/từ trên mỗi mẫu.
Trong trường hợp tập dữ liệu đánh giá IMDb của chúng tôi, tỷ lệ mẫu/từ trên mỗi mẫu là ~144. Điều này có nghĩa là chúng ta sẽ tạo một mô hình MLP.