בשלב הזה אספנו את מערך הנתונים שלנו וקיבלנו תובנות לגבי המאפיינים המרכזיים של הנתונים. בשלב הבא, על סמך המדדים שאספנו בשלב 2, צריך להחליט באיזה מודל סיווג להשתמש. כלומר, כדאי לשאול שאלות כמו:
- איך מציגים את נתוני הטקסט לאלגוריתם שמצפה לקלט מספרי? (תהליך זה נקרא 'עיבוד מראש של נתונים' ו'יצירת וקטורים').
- באיזה סוג מודל כדאי לך להשתמש?
- באילו פרמטרים של הגדרות כדאי להשתמש במודל שלכם?
בזכות עשרות שנים של מחקר, יש לנו גישה למגוון רחב של אפשרויות לעיבוד מראש של נתונים ולהגדרת מודלים. עם זאת, הזמינות של מגוון גדול מאוד של אפשרויות מעשיות לבחירה יכולה להגדיל משמעותית את המורכבות וההיקף של בעיה מסוימת. בגלל שהאפשרויות הטובות ביותר לא ברורות מאליהן, פתרון תמים הוא לנסות את כל האפשרויות בצורה ממצה ולקצץ כמה אפשרויות באמצעות אינטואיציה. עם זאת, זה יהיה יקר מאוד.
במדריך הזה אנחנו מנסים לפשט באופן משמעותי את תהליך בחירת המודל לסיווג טקסט. בכל מערך נתונים המטרה שלנו היא למצוא את האלגוריתם שמשיג את רמת הדיוק הגבוהה ביותר, תוך צמצום זמן החישוב שנדרש לאימון. ערכנו מספר גדול (כ-450,000) של ניסויים על בעיות מסוגים שונים (במיוחד ניתוח סנטימנטים ובעיות בסיווג נושאים), באמצעות 12 מערכי נתונים, שעברו לסירוגין בכל מערך נתונים בין שיטות שונות לעיבוד מראש של נתונים וארכיטקטורות מודל שונות. כך הצלחנו לזהות פרמטרים של מערכי נתונים שמשפיעים על הבחירות האופטימליות.
האלגוריתם של בחירת המודל ותרשים הזרימה שבהמשך הם סיכום של הניסוי שלנו. אל דאגה אם עדיין לא הבנתם את כל המונחים שמופיעים בהם. הקטעים הבאים במדריך הזה יסבירו אותם לעומק.
אלגוריתם להכנת נתונים ולבניית מודלים
- חשבו את מספר הדגימות/מספר המילים לכל יחס דגימה.
- אם היחס הזה קטן מ-1,500, צריך להמיר את הטקסט לאסימונים כ-n-gram ולהשתמש במודל פשוט של פרספקטרון רב-שכבתי (MLP) כדי לסווג אותם (הסתעפות שמאלית בתרשים הזרימה שבהמשך):
- מפצלים את הדגימות ל-n-grams וממירים את ה-n-gram לווקטורים.
- מציינים את מידת החשיבות של הווקטורים ואז בוחרים את 20,000 הווקטורים המובילים באמצעות הציונים.
- פיתוח מודל MLP.
- אם היחס גדול מ-1,500, אפשר להפוך את הטקסט לרצפים ולהשתמש במודל sepCNN כדי לסווג אותם (הסתעפות ימנית בתרשים הזרימה שבהמשך):
- מפצלים את המדגמים למילים. בוחרים את 20,000 המילים המובילות בהתאם לתדירות שלהן.
- ממירים את הדוגמאות לווקטורים של רצף מילים.
- אם המספר המקורי של דגימות/מספר מילים ביחס לדגימה קטן מ-15,000, סביר להניח ששימוש בהטמעה שמותאמת מראש עם מודל sepCNN יניב את התוצאות הטובות ביותר.
- כדאי למדוד את ביצועי המודל עם ערכי היפר-פרמטרים שונים כדי למצוא את תצורת המודל הטובה ביותר למערך הנתונים.
בתרשים הזרימה שבהמשך, התיבות הצהובות מציינות נתונים ותהליכי הכנת המודל. תיבות אפורות ותיבות ירוקות מציינות את האפשרויות ששקלנו בכל תהליך. תיבות ירוקות מציינות את הבחירה המומלצת שלנו לכל תהליך.
תוכלו להשתמש בתרשים הזרימה הזה כנקודת התחלה לבניית הניסוי הראשון שלכם, מכיוון שהוא יספק לכם רמת דיוק גבוהה בעלויות חישוב נמוכות. לאחר מכן תוכלו להמשיך לשפר את המודל הראשוני שלכם באיטרציות הבאות.
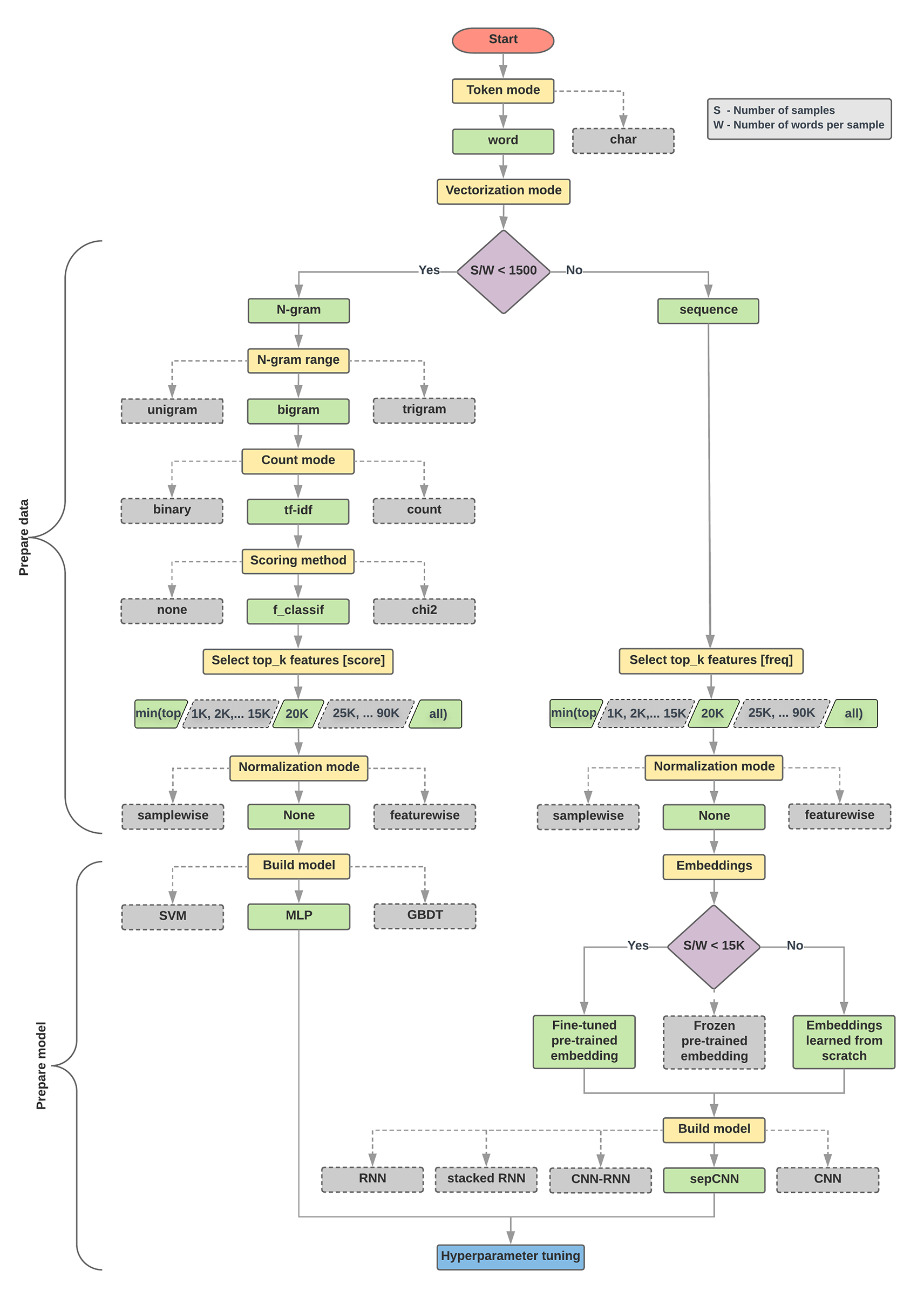
איור 5: תרשים זרימה של סיווג טקסטים
תרשים הזרימה הזה עונה על שתי שאלות מפתח:
- באיזה אלגוריתם או מודל למידה כדאי לך להשתמש?
- איך מכינים את הנתונים כדי ללמוד ביעילות על הקשר בין טקסט לתווית?
התשובה לשאלה השנייה תלויה בתשובה לשאלה הראשונה. האופן שבו אנחנו מעבדים מראש נתונים כדי להזין למודל תלוי במודל שנבחר. אפשר לסווג מודלים באופן כללי לשתי קטגוריות: מודלים שנעשה בהם שימוש במידע על סדר המילים (מודלים של רצפים), ומודלים שבהם הטקסט מוצג רק בתור "תיקים" (קבוצות של מילים) (מודלים של n-gram). סוגי המודלים של רצף כוללים רשתות נוירונים מלאכותיות (CNN), רשתות נוירונים חוזרות (RNN) ואת הווריאציות שלהן. סוגי המודלים של n-gram כוללים:
- רגרסיה לוגיסטית
- פרצנטרונים פשוטים מרובי שכבות (MLP או רשתות נוירונים מחוברות באופן מלא)
- עצים מוגברים הדרגתיים
- תמיכה במכונות וקטוריות
מהניסויים שלנו, שמנו לב שהיחס בין 'מספר הדגימות' (S) ל'מספר המילים לדגימה' (W) תואם לאופן שבו המודל מניב ביצועים טובים.
כשהערך של היחס הזה קטן (פחות מ-1,500), הביצועים של תקליטים קטנים מרובי-שכבות שמקבלים n גרם כקלט (נקראים אפשרות א') מניבים ביצועים טובים יותר או לפחות מודלים של רצף. קל להגדיר ולהבין את מודלים של MLP, ונדרש להם הרבה פחות זמן מחשוב מאשר מודלים של רצף. כאשר הערך של היחס הזה גדול (>= 1500), צריך להשתמש במודל רצף (אפשרות ב'). בשלבים הבאים תוכלו לדלג לקטעי המשנה הרלוונטיים (מסומנים A או B) לסוג המודל שבחרתם, על סמך יחס הדגימות/המילים לכל דגימה.
במקרה של מערך הנתונים של הביקורות מ-IMDb, יחס הדגימה/המילים לכל דגימה הוא בערך 144. המשמעות היא שניצור מודל MLP.