此时,我们已经整合了数据集,并深入了解了数据的关键特征。接下来,根据我们在第 2 步中收集的指标,我们应该考虑应该使用哪种分类模型。这意味着您可以提出如下问题:
- 如何将文本数据呈现给需要数字输入的算法? (这称为数据预处理和矢量化。)
- 您应使用哪种模型?
- 您应该为模型使用哪些配置参数?
经过数十年的研究,我们可以使用大量数据预处理和模型配置选项。但是,有大量可行选项可供选择,可能会极大地增加特定问题的复杂性和范围。鉴于最佳选项可能并不明显,一个简单的解决方案是详尽尝试每个可能的选项,通过直觉删减一些选项。不过,费用非常高昂。
在本指南中,我们尝试显著简化选择文本分类模型的过程。对于给定的数据集,我们的目标是找到一种算法,在最大程度减少训练所需的计算时间的同时,实现接近最高准确率。我们使用了 12 个数据集,针对不同类型的问题(尤其是情感分析和主题分类问题)运行了大量(约 45 万)实验,并在不同的数据预处理技术和不同的模型架构之间交替处理每个数据集。这帮助我们确定了影响最佳选择的数据集参数。
下面的模型选择算法和流程图是我们的实验的摘要。如果您还不了解其中使用的所有术语,别担心;本指南的以下部分将对这些术语进行深入解释。
数据准备和模型构建算法
- 计算每种采样率的样本数/字词数。
- 如果此比率小于 1500,请将文本标记化为 n 元语法,并使用简单的多层感知机 (MLP) 模型对其进行分类(以下流程图中的左分支):
- 将样本拆分为字词 n 元语法;将 n 元语法转换为向量。
- 为向量的重要性评分,然后使用得分选择前 20K。
- 构建 MLP 模型。
- 如果比率大于 1500,请将文本标记化为序列,并使用 sepCNN 模型对其进行分类(以下流程图中的右分支):
- 将样本拆分为字词;根据出现频率选择前 2 万个字词。
- 将样本转换为字词序列向量。
- 如果原始样本数/每个采样率的单词数小于 15, 000,则将经过微调的预训练嵌入与 sepCNN 模型搭配使用可能会提供最佳结果。
- 使用不同的超参数值衡量模型性能,以找到数据集的最佳模型配置。
在下面的流程图中,黄色框表示数据和模型准备过程。灰色框和绿色框表示我们已考虑为每个流程选择的选项。绿色框表示我们为每个流程推荐的选项。
您可以使用此流程图作为构建第一个实验的起点,因为它能够以较低的计算成本获得良好的准确性。然后,您可以在后续迭代中继续改进初始模型。
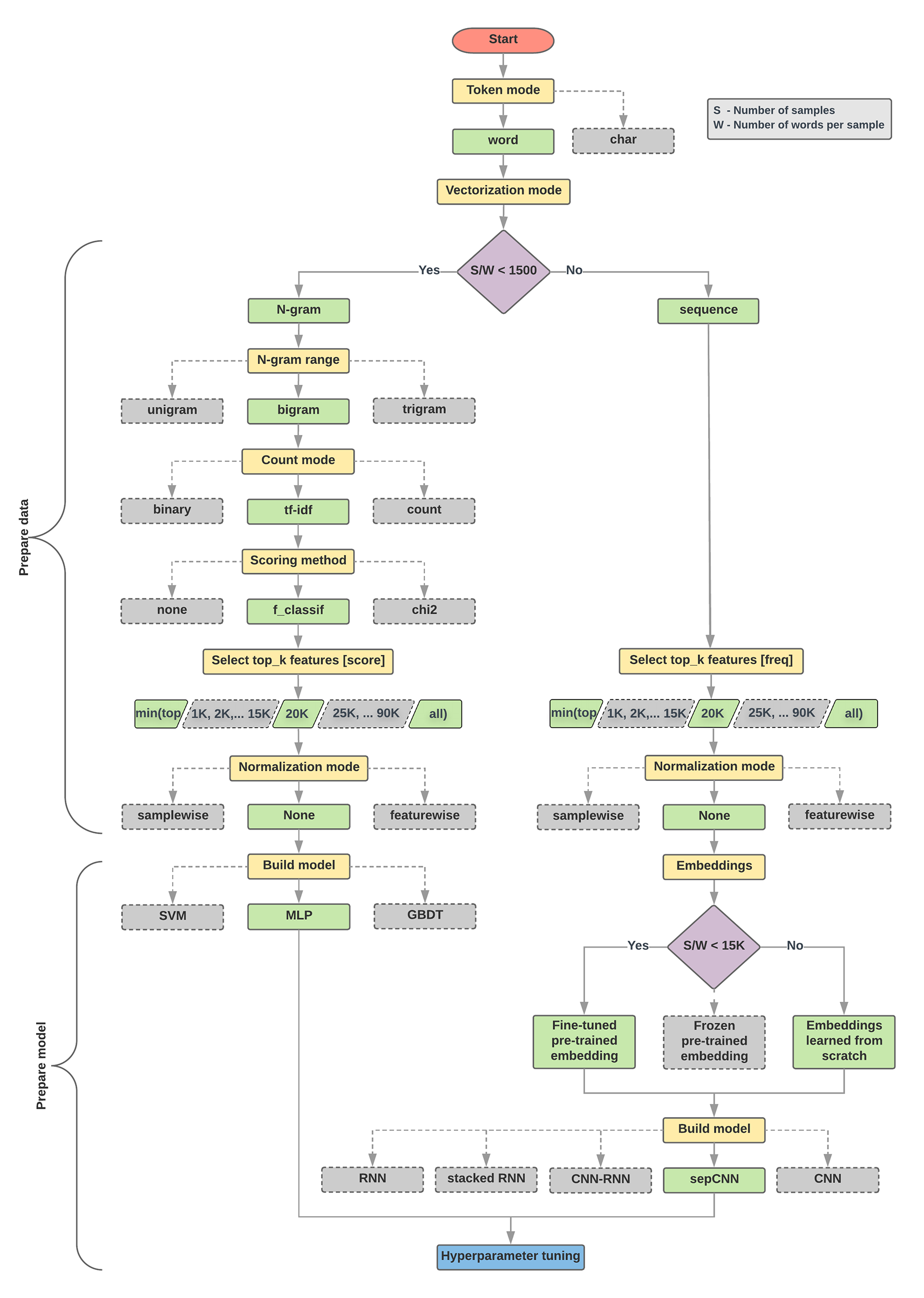
图 5:文本分类流程图
该流程图回答了两个关键问题:
- 您应该使用哪种学习算法或模型?
- 您应如何准备数据才能高效地学习文本与标签之间的关系?
第二个问题的答案取决于第一个问题的答案;我们预处理要馈送到模型的数据的方式取决于我们选择的模型。模型可以大致分为两类:使用字词排序信息的模型(序列模型),以及仅将文本视为字词“包”(集)的模型(n 元语法模型)。序列模型的类型包括卷积神经网络 (CNN)、循环神经网络 (RNN) 及其变体。N 元语法模型的类型包括:
从实验中,我们观察到“样本数”(S) 与“每个样本的字数” (W) 的比率与哪个模型的表现良好相关。
当该比率的值较小 (<1500) 时,将 n-gram 作为输入的小型多层感知器(我们称为“选项 A”)的表现更好或至少与序列模型相同。MLP 易于定义和理解,并且与序列模型相比,占用的计算时间要少得多。如果此比率的值较大 (>= 1500),请使用序列模型(选项 B)。在以下步骤中,您可以根据样本/字词/样本比率,跳到所选模型类型对应的相关子部分(标记为 A 或 B)。
以 IMDb 评价数据集为例,样本/字词/样本的比率约为 144。这意味着,我们将创建一个 MLP 模型。